1. 学习文本时的维度
Learning from text
很多线上数据都是文本数据,比如网页、邮件等
文本学习的基本问题与输入特征相关
支持向量机的最佳输入大小是什么?
hard to tell
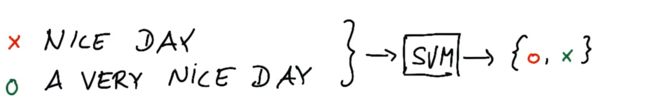
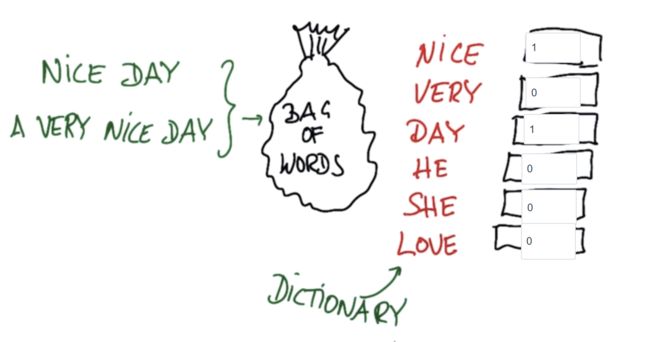
2. 词袋
文本学习中的一个基本问题是,我们学习的每个文件,每封邮件或每个书名,它的长度都是不标准的,所以不能将某个单独的词作为输入特征,因为长的邮件与短的邮件所需输入空间不同
文本的机器学习有一个很棒的功能,词袋,它可以分析所有这些方式
词袋的一个基本理念就是选定某一个文本,然后计算文本的频率
词袋的诀窍就是利用字典,字典里有所有你知道的单词
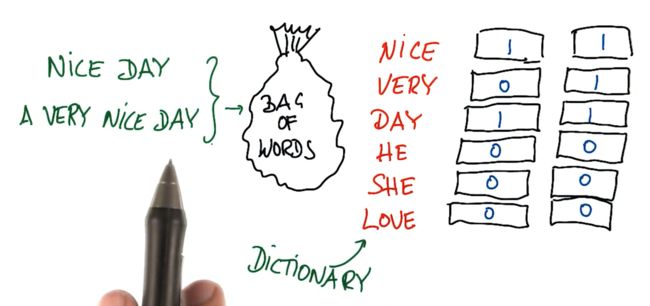
针对nice day,填写所有词的频率
4.Day 先生热爱美好的一天
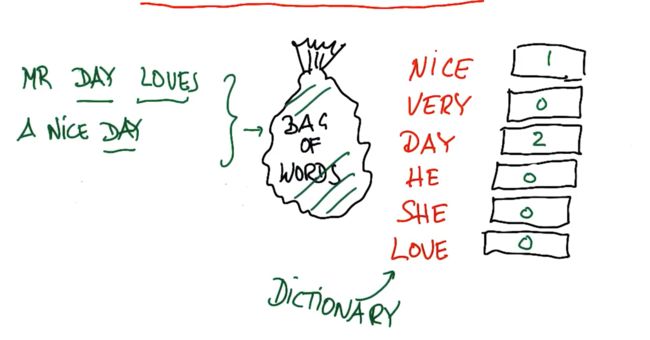
词袋的高级功能,是它一般关注词干
5. 词袋属性
- 短语的单词顺序没有影响
- 如果将同一封邮件复制一份,并将两封同样的邮件放入同一个文本,那么文本的输入向量会不同,因为所有的量都变成了原来的两倍
- 无法处理多个单词组成的复合短语,比如'chicago bulls',这个短语代表NBA球队,但这两个单词分开时分别代表地名和动物名,不过google的处理方式是在字典中添加这一短语
6. Sklearn 中的词袋
在Sklearn 中,词袋被称为Count Vectorizer ,其字面意思是计算不同单词在语料库中出现的次数
from sklearn.feature_extraction.text import CountVectorizer
vectorizer = CountVectorizer()
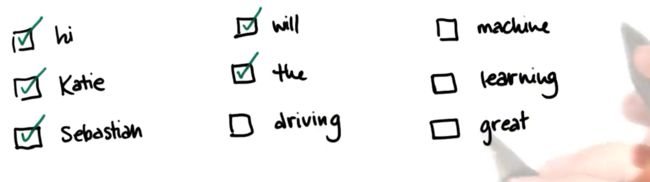
string1 = "hi Katie the self driving car will be late Best Sebastian"
string2 = "Hi Sebastian the machine learning class will be great great great Best Katie"
string3 = "Hi Katie the machine learning class will be most excellent"
email_list = [string1,string2,string3]
bag_of_words = vectorizer.fit(email_list)
bag_of_words = vectorizer.transform(email_list)
print bag_of_words
bag_of_words 输出类似 (1,7) 1
可以如此解读:
1号文件,第7个单词,出现了1次
索引从0开始,因此一号文件指的是string2
词袋的一个属性叫做vocabulary_,对该属性调用函数get,让后将词汇“great”作为参数传递给函数get,可得到该词汇在词袋中的特征数
print vectorizer.vocabulary_.get('great')
7. 低信息的单词
在词汇表中,不是所有的单词都是平等的
有些单词比其他单词包含更多的信息
低信息单词:不是很能帮助你理解当前发生了什么的单词,不过名字是你需要长期保留的词
8. 停止词
将不含有特别多信息的单词移出你的语料库,不让它们成为你数据集中的噪音,具体来说这里讲的是停止词
停止词的具体定义可能会各有不同,但一般来说,就是出现非常频繁的低信息单词,比如and,the,in,for,I,you,have,will,be
在文本分析前,一个非常常见的预处理步骤就是在处理数据前,去除停止词
9. 从 NLTK 中获取停止词
NLTK natural language tool kit
import nltk
nltk.download() #选择all-corpora 下载语料库
nltk.download('stopwords') #也可以只下载stopwords
from nltk.corpus import stopwords
sw = stopwords.words('english') #停止词清单
print sw[0] #停止词清单中的第一个停止词
根据你的设置,(像我一样)下载带有 GUI 的语料库可能会很慢,而且十分痛苦。此StackOverFlow页面与如何通过命令行进行下载有关:http://stackoverflow.com/questions/5843817/programmatically-install-nltk-corpora-models-i-e-without-the-gui-downloader
如果你只需完成本练习,那么只下载本练习涉及的数据库可以帮助你大量减少下载时间,可以参考这篇论坛贴子。
停止词清单中有多少停止词?
print len(sw)
10. 词干化以合并词汇
不是所有的单词意思都是不同的,或者说它们的意思区别不大
比如语料库中有不同版本的respond这个词responsive response responsivity responsiveness respond,虽然是在不同的语境下使用这些词,但是它们的意思区别不大,基本上讲的是同一件事情,即一些人对某人或某事作出反应,如果我只是简单地将它们放入词袋,那它们会表现为不同的特征,虽然它们的意思基本上一样,在许多语言中都会出现相似的情况,即有很多不同的表达,但描述的是几乎无差别的东西,幸运的是我们可以把这些词绑在一起,然后用一个词来代表
这里用到的算法是:词干提取
把这些所有的词打包放进词干提取stemmer,对这些词调用函数,把这些词分拆开来,找到它们相同的词根,比如respon,所以不是说一定要用一个单独的词,respon就不是一个词,而是可以在分类器或回归中使用的词干或者说词根,我们现在将这个五维数输入空间,转化为一维数,而且不会损失任何真正的信息
自行执行词干提取函数会比较难,在机器学习中,我们会直接从NLTK或其他一些相似的文字处理包获取词干提取函数,完成词干提取后,我们的词汇表就清爽很多了,方便使用
11. 使用 NLTK 进行词干化
from nltk.stem.snowball import SnowballStemmer #导入词干提取函数,这里以snowball词干提取函数为例
stemmer = SnowballStemmer('english') #创建词干提取器,需说明想要提取词干的语言
stemmer.stem('responsiveness') #使用词干提取器提取需要的单词的词干
stemmer.stem('responsivity')
stemmer.stem('unresponsive') #unrespons 这个词干提取器有一些限制,它没有拆分掉unresponsive的前缀un
使用词干提取器后,能够很大程度地清理语料库的词汇表,它可以把一些非常复杂的东西变得紧凑
12, 文本处理中的运算符顺序
我们之前讨论过,做文字处理时,经常采用两个步骤:
- 词袋
- 词干提取
假设你要对文本进行这两种操作,那么我们应该先进行词干提取,再将词放入词袋中
假设我们正在讨论“responsibility is responsive to responsible people”这一段文字(这句话不合语法,但你知道我的意思……)
如果你直接将这段文字放入词袋,你得到的就是:
[is:1
people: 1
responsibility: 1
responsive: 1
responsible:1]
然后再运用词干化,你会得到
[is:1
people:1
respon:1
respon:1
respon:1]
(如果你可以找到方法在 sklearn 中词干化计数向量器的对象,这种尝试最有可能的结果就是你的代码会崩溃……)
那样,你就需要再进行一次后处理来得到以下词袋,如果你一开始就进行词干化,你就会直接获得这个词袋了:
[is:1
people:1
respon:3]
显然,第二个词袋很可能是你想要的
13. 由词频确定的权重
TfIdf Representation
Tf term frequency
like bag of words
每个术语、每个单词,会根据其在一个文件中出现的次数加重权重,比如一个出现10次的词,它的权重比一个出现1次的词重10倍Idf inverse document frequency
逆向文件频率
weighting by how often words occurs in corpus
单词会根据其在整个语料库、所有文件中出现的频率得到加权
问题:如果你想要从单词中摘取信息,那么是给出现频率高的单词以更重的权重,还是给出现频率低的单词以更重的权重?
would you weight common words higher,or rare words?
rare
因为较罕见的单词经常能够帮助你分辨不同的消息
14.为何要向上加权少见单词
正是那些很少出现的词能告知你最重要的信息,让你知道信息内容大概是什么,某条消息的作者可能是谁
通过单词在整个语料库中出现的频率,进行逆向加权
15. 文本学习迷你项目简介
根据邮件作者在发送的邮件中使用的单词,来判断邮件的作者是谁
16. 文本学习迷你项目
本节课开始,你使用大量监督式分类算法,根据作者来识别邮件。 在这些项目中,我们为你做了预处理,将输入邮件转换到 TfIdf 中,这样你就能向算法提供这些邮件了。 现在,你将自行完成预处理工作,以便你能从原始数据直接得到经过处理的特征。
你将得到两个文本文件:一个包含来自 Sara 的所有邮件,一个包含 Chris 的邮件。 你还将访问 parseOutText() 函数,该函数接受作为参数的已读邮件,并且返回包含邮件中所有(被词干化的)单词的字符串。
17. parseOutText() 热身
你将从热身习题开始了解 parseOutText()。 前往工具目录并运行 parse_out_email_text.py,该程序包含 parseOutText() 和一封测试邮件,用以运行此函数。
parseOutText() 获得被打开的邮件,然后仅返回文字部分,除去了可能出现在邮件开头的元数据,接下来就是邮件正文了。 我们现在已经设置好了这一脚本,这样它就能将邮件正文打印到屏幕上,你运行 parseOutText() 时会得到怎样的正文?
Hi Everyone If you can read this message youre properly using parseOutText Please proceed to the next part of the project
18. 部署词干化
在 parseOutText() 中,将下面语句变成注释:
words = text_string
增强 parseOutText(),这样返回的字符串就有了所有因使用 SnowballStemmer(使用 nltk 包,可在 http://www.nltk.org/howto/stem.html 找到我发现有用的一些示例)而获得的词干化单词。
重新运行 parse_out_email_text.py,该程序将使用你更新的 parseOutText() 函数。你现在的输出是什么?
提示:你需要将字符串分解成单个单词,词干化每个单词,然后再将所有单词重新组合成一个字符串。
#!/usr/bin/python
from nltk.stem.snowball import SnowballStemmer
import string
def parseOutText(f):
""" given an opened email file f, parse out all text below the
metadata block at the top
(in Part 2, you will also add stemming capabilities)
and return a string that contains all the words
in the email (space-separated)
example use case:
f = open("email_file_name.txt", "r")
text = parseOutText(f)
"""
f.seek(0) ### go back to beginning of file (annoying)
all_text = f.read()
### split off metadata
content = all_text.split("X-FileName:")
words = ""
if len(content) > 1:
### remove punctuation
text_string = content[1].translate(string.maketrans("", ""), string.punctuation)
### project part 2: comment out the line below
# words = text_string
### split the text string into individual words, stem each word,
### and append the stemmed word to words (make sure there's a single
### space between each stemmed word)
words = text_string.split()
from nltk.stem.snowball import SnowballStemmer
stemmer = SnowballStemmer("english")
answ = []
for w in words:
s = stemmer.stem(w)
if s:
answ.append(s.rstrip()) rstrip() 删除 string 字符串末尾的指定字符(默认为空格)
answ = ' '.join(answ)
return answ
def main():
ff = open("../text_learning/test_email.txt", "r")
text = parseOutText(ff)
print text
if __name__ == '__main__':
main()
答案:
hi everyon if you can read this messag your proper use parseouttext pleas proceed to the next part of the project
19. 清除“签名文字”
在 vectorize_text.py 中,你将迭代所有来自 Chris 和 Sara 的邮件。 将每封已读邮件提供给 parseOutText() 并返回词干化的文本字符串。然后做以下两件事:
- 删除签名文字(“sara”、“shackleton”、“chris”、“germani”——如果你知道为什么是“germani”而不是“germany”,你将获得加分)* 向 word_data 添加更新的文本字符串——如果邮件来自 Sara,向 from_data 添加 0(零),如果是 Chris 写的邮件,则添加 1。
完成此步骤后,你应该有两个列表:一个包含了每封邮件被词干化的正文,第二个应该包含用来编码(通过 0 或 1)谁是邮件作者的标签。
对所有邮件运行程序需要花一些时间(5 分钟或更长时间),所以我们添加了一个 temp_counter,将第 200 封之后的邮件切割掉。 当然,一切就绪后,你会希望对整个数据集运行程序。
在以下方框中,放入你得到的 word_data[152] 字符串。
开始练习
vectorize_text.py 可以在 text_learning 目录中找到。
#!/usr/bin/python
import os
import pickle
import re
import sys
sys.path.append( "../tools/" )
from parse_out_email_text import parseOutText
"""
Starter code to process the emails from Sara and Chris to extract
the features and get the documents ready for classification.
The list of all the emails from Sara are in the from_sara list
likewise for emails from Chris (from_chris)
The actual documents are in the Enron email dataset, which
you downloaded/unpacked in Part 0 of the first mini-project. If you have
not obtained the Enron email corpus, run startup.py in the tools folder.
The data is stored in lists and packed away in pickle files at the end.
"""
from_sara = open("from_sara.txt", "r")
from_chris = open("from_chris.txt", "r")
from_data = []
word_data = []
### temp_counter is a way to speed up the development--there are
### thousands of emails from Sara and Chris, so running over all of them
### can take a long time
### temp_counter helps you only look at the first 200 emails in the list so you
### can iterate your modifications quicker
temp_counter = 0
for name, from_person in [("sara", from_sara), ("chris", from_chris)]:
for path in from_person:
### only look at first 200 emails when developing
### once everything is working, remove this line to run over full dataset
temp_counter += 1
if temp_counter < 200:
path = os.path.join('..', path[:-1])
print path
email = open(path, "r")
### use parseOutText to extract the text from the opened email
words = parseOutText(email)
### use str.replace() to remove any instances of the words
### ["sara", "shackleton", "chris", "germani"]
words = words.replace("sara",'').replace("shackleton",'').replace("chris",'').replace("germani",'')
words = ' '.join(words.split())
### append the text to word_data
word_data.append(words)
### append a 0 to from_data if email is from Sara, and 1 if email is from Chris
if name == 'sara':
from_data.append(0)
elif name == 'chris':
from_data.append(1)
email.close()
print "emails processed"
print word_data[152] #tjonesnsf stephani and sam need nymex calendar
from_sara.close()
from_chris.close()
pickle.dump( word_data, open("your_word_data.pkl", "w") )
pickle.dump( from_data, open("your_email_authors.pkl", "w") )
### in Part 4, do TfIdf vectorization here
20. 进行 TfIdf
使用 sklearn TfIdf 转换将 word_data 转换为 tf-idf 矩阵。删除英文停止词。
你可以使用 get_feature_names() 访问单词和特征数字之间的映射,该函数返回一个包含词汇表所有单词的列表。有多少不同的单词?
确保使用 tf-idf 向量器类来转换词数据。
切记在你设置向量器时删除英文停止词。
from sklearn.feature_extraction.text import TfidfVectorizer
vectorizer = TfidfVectorizer(stop_words="english")
vectorizer.fit_transform(word_data)
feature_names = vectorizer.get_feature_names()
print len(feature_names) #38757
21.访问 TfIdf 特征
你 TfId 中的单词编号 34597 是什么?
(需要说明的是,如果问题是“单词编号 100 是什么”,我们肯定会查找对应 vocab_list[100] 的单词。有时候,零索引数组谈论起来非常不好理解。)
from sklearn.feature_extraction.text import TfidfVectorizer
vectorizer = TfidfVectorizer(stop_words="english")
vectorizer.fit_transform(word_data)
feature_names = vectorizer.get_feature_names()
print len(feature_names)
print feature_names[34597] #stephaniethank