本文目录
- 背景知识
- 大数据时代的构架演进
- RocketMQ Connector&Stream
- Apache Hudi
- 构建Lakehouse实操
本文标题包含三个关键词:Lakehouse、RocketMQ、Hudi。我们先从整体Lakehouse架构入手,随后逐步分析架构产生的原因、架构组件特点以及构建Lakehouse架构的实操部分。
背景知识
1、Lakehouse架构
Lakehouse最初由Databrick提出,并对Lakehouse架构特征有如下要求:
(1)事务支持
企业内部许多数据管道通常会并发读写数据。对ACID事务的支持确保了多方并发读写数据时的一致性问题;
(2)Schema enforcement and governance
Lakehouse应该有一种方式可以支持模式执行和演进、支持DW schema的范式(如星星或雪花模型),能够对数据完整性进行推理,并且具有健壮的治理和审计机制;
(3)开放性
使用的存储格式是开放式和标准化的(如parquet),并且为各类工具和引擎,包括机器学习和Python/R库,提供API,以便它们可以直接有效地访问数据;
(4)BI支持
Lakehouse可以直接在源数据上使用BI工具。这样可以提高数据新鲜度、减少延迟,并且降低了在数据池和数据仓库中操作两个数据副本的成本;
(5)存储与计算分离
在实践中,这意味着存储和计算使用单独的集群,因此这些系统能够扩展到支持更大的用户并发和数据量。一些现代数仓也具有此属性;
(6)支持从非结构化数据到结构化数据的多种数据类型
Lakehouse可用于存储、优化、分析和访问许多数据应用所需的包括image、video、audio、text以及半结构化数据;
(7)支持各种工作负载
包括数据科学、机器学习以及SQL和分析。可能需要多种工具来支持这些工作负载,但它们底层都依赖同一数据存储库;
(8)端到端流
实时报表是许多企业中的标准应用。对流的支持消除了需要构建单独系统来专门用于服务实时数据应用的需求。
从上述对Lakehouse架构的特点描述我们可以看出,针对单一功能,我们可以利用某些开源产品组合构建出一套解决方案。但对于全部功能的支持,目前好像没有一个通用的解决方案。接下来,我们先了解大数据时代主流的数据处理架构是怎样的。
大数据时代的架构演进
1、大数据时代的开源产品
大数据时代的开源产品种类繁多,消息领域的RocketMQ、Kafka;计算领域的flink、spark、storm;存储领域的HDFS、Hbase、Redis、ElasticSearch、Hudi、DeltaLake等等。
为什么会产生这么多开源产品呢?首先在大数据时代数据量越来越大,而且每个业务的需求也各不相同,因此就产生出各种类型的产品供架构师选择,用于支持各类场景。然而众多的品类产品也给架构师们带来一些困扰,比如选型困难、试错成本高、学习成本高、架构复杂等等。

2、当前主流的多层架构
大数据领域的处理处理场景包含数据分析、BI、科学计算、机器学习、指标监控等场景,针对不同场景,业务方会根据业务特点选择不同的计算引擎和存储引擎;例如交易指标可以采用binlog + CDC+ RocketMQ + Flink + Hbase + ELK组合,用于BI和Metric可视化。
(1)多层架构的优点:支持广泛的业务场景;
(2)多层架构的缺点:
- 处理链路长,延迟高;
- 数据副本多,成本翻倍;
- 学习成本高;
造成多层架构缺点主要原因是存储链路和计算链路太长。
- 我们真的需要如此多的解决方案来支持广泛的业务场景吗?Lakehouse架构是否可以统一解决方案?
- 多层架构的存储层是否可以合并?Hudi产品是否能够支持多种存储需求?
- 多层架构的计算层是否可以合并?RocketMQ stream是否能够融合消息层和计算层?
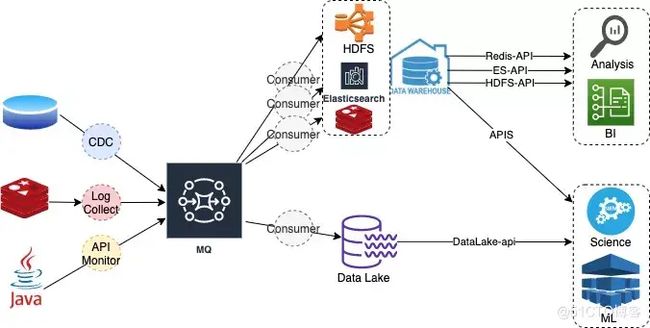
当前主流的多层架构
3、Lakehouse架构产生
Lakehouse架构是多层架构的升级版本,将存储层复杂度继续降低到一层。再进一步压缩计算层,将消息层和计算层融合,RocketMQ stream充当计算的角色。我们得到如下图所示的新架构。新架构中,消息出入口通过RocketMQ connector实现,消息计算层由RocketMQ stream实现,在RocketMQ内部完成消息计算中间态的流转;计算结果通过RocketMQ-Hudi-connector收口落库Hudi,Hudi支持多种索引,并提供统一的API输出给不同产品。

Lakehouse架构
下面我们分析下该架构的特点。
(1)Lakehouse架构的优点:
- 链路更短,更适合实时场景,数据新鲜感高;
- 成本可控,降低了存储成本;
- 学习成本低,对程序员友好;
- 运维复杂度大幅降低;
(2)Lakehouse架构的缺点
对消息产品和数据湖产品的稳定性、易用性等要求高,同时消息产品需要支持计算场景,数据湖产品需要提供强大的索引功能。
(3)选择
在Lakehouse架构中我们选择消息产品RocketMQ和数据湖产品Hudi。
同时,可以利用RocketMQ stream在RocketMQ集群上将计算层放在其中集成,这样就将计算层降低到一层,能够满足绝大部分中小型大数据处理场景。
接下来我们逐步分析RocketMQ和Hudi两款产品的特点。
RocketMQ Connector & Stream

RocketMQ 发展历程图
RocketMQ从2017年开始进入Apache孵化,2018年RocketMQ 4.0发布完成云原生化,2021年RocketMQ 5.0发布全面融合消息、事件、流。
1、业务消息领域首选
RocketMQ作为一款“让人睡得着觉的消息产品”成为业务消息领域的首选,这主要源于产品的以下特点:
(1)金融级高可靠
经历了阿里巴巴双十一的洪峰检验;
(2)极简架构
如下图所示, RocketMQ的架构主要包含两部分包括:源数据集群NameServer Cluster和计算存储集群Broker Cluster。

RocketMQ 构架图
NameServer节点无状态,可以非常简单的进行横向扩容。Broker节点采用主备方式保证数据高可靠性,支持一主多备的场景,配置灵活。
搭建方式:只需要简单的代码就可以搭建RocketMQ集群:
Jar:
nohup sh bin/mqnamesrv &
nohup sh bin/mqbroker -n localhost:9876 &On K8S:
kubectl apply -f example/rocketmq_cluster.yaml(3)极低运维成本
RocketMQ的运维成本很低,提供了很好的CLI工具MQAdmin,MQAdmin提供了丰富的命令支持,覆盖集群健康状态检查、集群进出流量管控等多个方面。例如,mqadmin clusterList一条命令可以获取到当前集群全部节点状态(生产消费流量、延迟、排队长度、磁盘水位等);mqadmin updateBrokerConfig命令可以实时设置broker节点或topic的可读可写状态,从而可以动态摘除临时不可用节点,达到生产消费的流量迁移效果。
(4)丰富的消息类型
RocketMQ支持的消息类型包括:普通消息、事务消息、延迟消息、定时消息、顺序消息等。能够轻松支持大数据场景和业务场景。
(5)高吞吐、低延迟
压测场景主备同步复制模式,每台Broker节点都可以将磁盘利用率打满,同时可以将p99延迟控制在毫秒级别。
2、RocketMQ 5.0概况

RocketMQ 5.0是生于云、长于云的云原生消息、事件、流超融合平台,它具有以下特点:
(1)轻量级SDK
- 全面支持云原生通信标准 gRPC 协议;
- 无状态 Pop 消费模式,多语言友好,易集成;
(2)极简架构
- 无外部依赖,降低运维负担;
- 节点间松散耦合,任意服务节点可随时迁移;
(3)可分可合的存储计算分离
- Broker 升级为真正的无状态服务节点,无 binding;
- Broker 和 Store节点分离部署、独立扩缩;
- 多协议标准支持,无厂商锁定;
- 可分可合,适应多种业务场景,降低运维负担;
如下图所示,计算集群(Broker)主要包括抽象模型和相对应的协议适配,以及消费能力和治理能力。存储集群(Store)主要分为消息存储CommitLog(多类型消息存储、多模态存储)和索引存储Index(多元索引)两部分,如果可以充分发挥云上存储的能力,将CommitLog和Index配置在云端的文件系统就可以天然的实现存储和计算分离。

(4)多模存储支持
- 满足不同基础场景下的高可用诉求;
- 充分利用云上基础设施,降低成本;
(5)云原生基础设施:
- 可观测性能力云原生化,OpenTelemetry 标准化;
- Kubernetes 一键式部署扩容交付。

RocketMQ 5.02021年度大事件及未来规划
3、 RocketMQConnector
a、传统数据流

(1)传统数据流的弊端
- 生产者消费者代码需要自己实现,成本高;
- 数据同步的任务没有统一管理;
- 重复开发,代码质量参差不齐;
(2)解决方案:RocketMQ Connector
- 合作共建,复用数据同步任务代码;
- 统一的管理调度,提高资源利用率;
b、RocketMQ Connector数据同步流程

相比传统数据流,RocketMQ connector数据流的不同在于将 source 和 sink 进行统一管理,同时它开放源码,社区也很活跃。
4、RocketMQ Connector架构
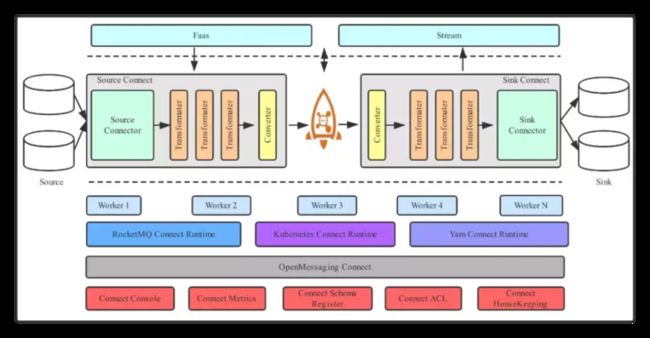
如上图所示,RocketMQ Connector架构主要包含Runtime和Worker两部分,另外还有生态Source&Sink。
(1)标准:OpenMessaging
(2)生态:支持ActiveMQ、Cassandra、ES、JDBC、JMS、MongoDB、Kafka、RabbitMQ、Mysql、Flume、Hbase、Redis等大数据领域的大部分产品;
(3)组件:Manager统一管理调度,如果有多个任务可以将所有任务统一进行负载均衡,均匀的分配到不同Worker上,同时Worker可以进行横向扩容。
5、RocketMQ Stream
RocketMQ Stream是一款将计算层压缩到一层的产品。它支持一些常见的算子如window、join、维表,兼容Flink SQL、UDF/UDAF/UDTF。

Apache Hudi
Hudi 是一个流式数据湖平台,支持对海量数据快速更新。内置表格式,支持事务的存储层、一系列表服务、数据服务(开箱即用的摄取工具)以及完善的运维监控工具。Hudi 可以将存储卸载到阿里云上的 OSS、AWS 的S3这些存储上。
Hudi的特性包括:
- 事务性写入,MVCC/OCC并发控制;
- 对记录级别的更新、删除的原生支持;
- 面向查询优化:小文件自动管理,针对增量拉取优化的设计,自动压缩、聚类以优化文件布局;

Apache Hudi是一套完整的数据湖平台。它的特点有:
- 各模块紧密集成,自我管理;
- 使用 Spark、Flink、Java 写入;
- 使用 Spark、Flink、Hive、Presto、Trino、Impala、
AWS Athena/Redshift等进行查询; - 进行数据操作的开箱即用工具/服务。
Apache Hudi主要针对以下三类场景进行优化:
1、流式处理栈
(1) 增量处理;
(2) 快速、高效;
(3) 面向行;
(4) 未优化扫描;
2、批处理栈
(1) 批量处理;
(2) 低效;
(3) 扫描、列存格式;
3、增量处理栈
(1) 增量处理;
(2) 快速、高效;
(3) 扫描、列存格式。
构建 Lakehouse 实操
该部分只介绍主流程和实操配置项,本机搭建的实操细节可以参考附录部分。
1、准备工作
RocketMQ version:4.9.0
rocketmq-connect-hudi version:0.0.1-SNAPSHOTHudi version:0.8.0
2、构建RocketMQ-Hudi-connector
(1) 下载:
git clone https://github.com/apache/roc...
(2) 配置:
/data/lakehouse/rocketmq-externals/rocketmq-connect/rocketmq-connect-runtime/target/distribution/conf/connect.conf 中connector-plugin 路径(3) 编译:
cd rocketmq-externals/rocketmq-connect-hudi
mvn clean install -DskipTest -Urocketmq-connect-hudi-0.0.1-SNAPSHOT-jar-with-dependencies.jar就是我们需要使用的rocketmq-hudi-connector
3、运行
(1) 启动或使用现有的RocketMQ集群,并初始化元数据Topic:
connector-cluster-topic (集群信息) connector-config-topic (配置信息)
connector-offset-topic (sink消费进度) connector-position-topic (source数据处理进度 并且为了保证消息有序,每个topic可以只建一个queue)
(2) 启动RocketMQ connector运行时
cd /data/lakehouse/rocketmq-externals/rocketmq-connect/rocketmq-connect-runtime
sh ./run_worker.sh ## Worker可以启动多个(3) 配置并启动RocketMQ-hudi-connector任务
请求RocketMQ connector runtime创建任务
curl http://${runtime-ip}:${runtime-port}/connectors/${rocketmq-hudi-sink-connector-name} ?config='{"connector-class":"org.apache.rocketmq.connect.hudi.connector.HudiSinkConnector","topicNames":"topicc","tablePath":"file:///tmp/hudi_connector_test","tableName":"hudi_connector_test_table","insertShuffleParallelism":"2","upsertShuffleParallelism":"2","deleteParallelism":"2","source-record-converter":"org.apache.rocketmq.connect.runtime.converter.RocketMQConverter","source-rocketmq":"127.0.0.1:9876","src-cluster":"DefaultCluster","refresh-interval":"10000","schemaPath":"/data/lakehouse/config/user.avsc"}’
启动成功会打印如下日志:
2021-09-06 16:23:14 INFO pool-2-thread-1 - Open HoodieJavaWriteClient successfully(4) 此时向source topic生产的数据会自动写入到1Hudi对应的table中,可以通过Hudi的api进行查询。
4、配置解析
(1) RocketMQ connector需要配置RocketMQ集群信息和connector插件位置,包含:connect工作节点id标识workerid、connect服务命令接收端口httpPort、rocketmq集群namesrvAddr、connect本地配置储存目录storePathRootDir、connector插件目录pluginPaths 。

RocketMQ connector配置表
(2) Hudi任务需要配置Hudi表路径tablePath和表名称tableName,以及Hudi使用的Schema文件。

Hudi任务配置表
点击此处即可查看Lakehouse构建实操视频
附录:在本地Mac系统构建Lakehouse demo
涉及到的组件:rocketmq、rocketmq-connector-runtime、rocketmq-connect-hudi、hudi、hdfs、avro、spark-shell0、启动hdfs
下载hadoop包
https://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-2.10.1/hadoop-2.10.1.tar.gz
cd /Users/osgoo/Documents/hadoop-2.10.1
vi core-site.xml
fs.defaultFS
hdfs://localhost:9000
vi hdfs-site.xml
dfs.replication
1
./bin/hdfs namenode -format
./sbin/start-dfs.sh
jps 看下namenode,datanode
lsof -i:9000
./bin/hdfs dfs -mkdir -p /Users/osgoo/Downloads
1、启动rocketmq集群,创建rocketmq-connector内置topic
QickStart:https://rocketmq.apache.org/docs/quick-start/
sh mqadmin updatetopic -t connector-cluster-topic -n localhost:9876 -c DefaultCluster
sh mqadmin updatetopic -t connector-config-topic -n localhost:9876 -c DefaultCluster
sh mqadmin updatetopic -t connector-offset-topic -n localhost:9876 -c DefaultCluster
sh mqadmin updatetopic -t connector-position-topic -n localhost:9876 -c DefaultCluster
2、创建数据入湖的源端topic,testhudi1
sh mqadmin updatetopic -t testhudi1 -n localhost:9876 -c DefaultCluster
3、编译rocketmq-connect-hudi-0.0.1-SNAPSHOT-jar-with-dependencies.jar
cd rocketmq-connect-hudi
mvn clean install -DskipTest -U
4、启动rocketmq-connector runtime
配置connect.conf
--------------
workerId=DEFAULT_WORKER_1
storePathRootDir=/Users/osgoo/Downloads/storeRoot
## Http port for user to access REST API
httpPort=8082
# Rocketmq namesrvAddr
namesrvAddr=localhost:9876
# Source or sink connector jar file dir,The default value is rocketmq-connect-sample
pluginPaths=/Users/osgoo/Downloads/connector-plugins
---------------
拷贝 rocketmq-hudi-connector.jar 到 pluginPaths=/Users/osgoo/Downloads/connector-plugins
sh run_worker.sh
5、配置入湖config
curl http://localhost:8082/connectors/rocketmq-connect-hudi?config='{"connector-class":"org.apache.rocketmq.connect.hudi.connector.HudiSinkConnector","topicNames":"testhudi1","tablePath":"hdfs://localhost:9000/Users/osgoo/Documents/base-path7","tableName":"t7","insertShuffleParallelism":"2","upsertShuffleParallelism":"2","deleteParallelism":"2","source-record-converter":"org.apache.rocketmq.connect.runtime.converter.RocketMQConverter","source-rocketmq":"127.0.0.1:9876","source-cluster":"DefaultCluster","refresh-interval":"10000","schemaPath":"/Users/osgoo/Downloads/user.avsc"}'
6、发送消息到testhudi1
7、## 利用spark读取
cd /Users/osgoo/Downloads/spark-3.1.2-bin-hadoop3.2/bin
./spark-shell \
--packages org.apache.hudi:hudi-spark3-bundle_2.12:0.9.0,org.apache.spark:spark-avro_2.12:3.0.1 \
--conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer'
import org.apache.hudi.QuickstartUtils._
import scala.collection.JavaConversions._
import org.apache.spark.sql.SaveMode._
import org.apache.hudi.DataSourceReadOptions._
import org.apache.hudi.DataSourceWriteOptions._
import org.apache.hudi.config.HoodieWriteConfig._
val tableName = "t7"
val basePath = "hdfs://localhost:9000/Users/osgoo/Documents/base-path7"
val tripsSnapshotDF = spark.
read.
format("hudi").
load(basePath + "/*")
tripsSnapshotDF.createOrReplaceTempView("hudi_trips_snapshot")
spark.sql("select * from hudi_trips_snapshot").show()欢迎加入钉钉群与 Rocketmq 爱好者讨论交流:

钉钉扫码加群