来源:Zohaib Sibte Hassan from Doordash and RedisConf 2020 (redisconf.com/) organized by Redis Labs (redislabs.com)
翻译:Wen Hui
转载:中间件小哥
1. Cache stampede问题:
Cache stampede问题又叫做cache miss storm,是指在高并发场景中,缓存同时失效导致大量请求透过缓存同时访问数据库的问题。

如上图所示:
服务器a,b 访问数据的前两次请求因为redis缓存中的键还没有过期,所以会直接通过缓存获取并返回(如上图绿箭头所示),但当缓存中的键过期后,大量请求会直接访问数据库来获取数据,导致在没有来得及更新缓存的情况下重复进行数据库读请求 (如上图的蓝箭头),从而导致系统比较大的时延。另外,因为缓存需要被应用程序更新,在这种情况下,如果同时有多个并发请求,会重复更新缓存,导致重复的写请求。

针对以上问题,作者提出一下第一种比较简单的解决方案,主要思路是通过在客户端中,通过给每个键的过期时间引入随机因子来避免大量的客户端请求在同一时间检测到缓存过期并向数据库发送读数据请求。在之前,我们定义键过期的条件为:
Timestamp+ttl > now()
现在我们定义一个gap值,表示每个客户端键最大的提前过期时间,并通过随机化将每个客户端的提前过期时间映射到 0 到gap之间的一个值, 这样以来,新的过期条件为:
Timestamp+ttl +(rand()*gap)> now()
通过这种方式,由于不同客户端请求拿到的键过期时间不一样,在缓存没有被更新的情况下,可以在一定程度上避免同时有很多请求访问数据库。从而导致比较大的系统延时。
客户端的实例程序如下:

另一种更好的方法是将提前过期时间做一个小的更改,通过取随机函数的对数来将每个客户端检查的键提前过期时间更均匀的分布在0到gap的区间内(因为随机函数取对数为负值,所以整个提前过期的时间也需要取反),从而获得更好的性能提升(具体的数学证明在Optimal Probabilistic Cache Stampede Prevention https://cseweb.ucsd.edu/~avattani/papers/cache_stampede.pdf 这篇文章中)。

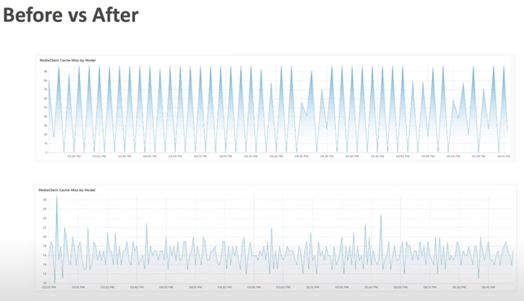
通过应用以上键的提前过期机制,我们看到整体的cache miss现象有明显的缓解。
2. Debouncing
Debouncing在这里指的是在较短时间内如果有多个相同key的数据读请求,可以合并成一个来处理,并同时等待数据的读请求完成。作者在这里介绍了可以使用类似javascript 的promise机制来处理请求,具体的步骤如下:
每个读请求提供一个L1 Cache Miss函数并返回一个promise,这个promise会去读相应的L2 Cache或数据库(如果L2 Cache也Miss的话)
当多个读请求使用debouncer访问相同Key id时,只有第一个请求会调用L1 Cache Miss函数,并立即返回一个promise。
当剩下的读请求到达并且Promise没有返回时,函数会立即返回第一个读请求L1 Cache Miss函数所返回的promise。
所有读请求都会等待这个Promise完成。
如果当前的Promise完成并返回,接下来的读请求将重复这个过程。
整体流程如下图程序所示:

在Java中,Caffeine Cache()缓存库也用到类似的设计来实现。
作者通过使用benchmark tool进行比较,通过使用debouncing的设计使得系统吞吐量有了较大的提高。如下图所示:

3. Big Key
Big Key是指包含数据量很大的键,在具体应用中,有如下几个例子:
缓存过的编译前的元数据(例如前端使用的试图,菜单等)
机器学习模型。
消息队列和具体消息。
更多的关于Redis流(stream)的例子。
在这种情况下,我们可以通过使用数据压缩算法来解决big key的问题。选择压缩算法的时候我们需要考虑以下几点:
压缩率(compress ratio)
是否轻量,不能耗费过多的资源
稳定性,是否进行过详尽的测试,以及社区支持等。
在选择算法的时候我们需要平衡上述几点,例如不能为了提高1% 的压缩率而使用额外20%资源。
在比较压缩算法的时候,可以使用lzbench(https://github.com/inikep/lzbench)来比较各类压缩算法的性能(https://morotti.github.io/lzbench-web/)。另外压缩算法的性能和具体的数据有直接的关系,所以建议大家自己动手尝试来比较各类压缩算法的性能差异。
具体的例子(doordash):
Chick-Fil-A 的菜单: 64220 bytes(序列化json)
起司公司产品清单: 350333 bytes(序列化json)
即使单独拿出来这些数据进行传输不会有太大问题,但如果有大量类似的公司需要多次传输,那么对网络和CPU负载是相当高的。
在具体选择压缩算法过程中,作者比较了LZ4和Snappy,并得到了以下结论:
在平均情况下,LZ4比Snappy的压缩率要高一点,但作者使用自己的数据作比较发现结论正好相反,LZ4 38.54% 和Snappy 39.71%
压缩速率相比两者差不多,LZ4会比Snappy慢一点点。
再解压方面,LZ4比Snappy快得多,在一些测试场景下会有两倍的差距。
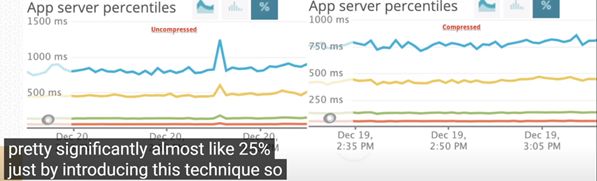
通过以上结论作者选择LZ4 作为菜单传输的压缩算法,并进行Redis Benchmark测试,使用压缩算法可以对Redis的读写吞吐量有很大提高,具体如下:

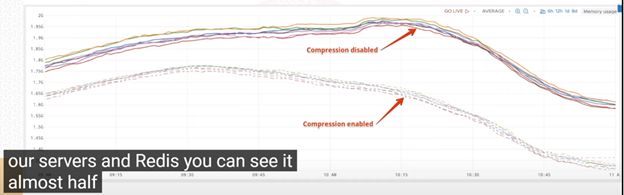
另外整个系统的网络流量使用和系统延时也有比较明显的降低:
所以作者建议如果使用Redis存储Big Key时,可以使用压缩算法来提高系统吞吐量和降低网络负载。
4. Hot Key
Hot Key(热键)问题指的是在系统中有多个分区(partition),但因为某一个特定的键频繁的被访问,导致所有的请求都会转到某一个特定的分区中,从而导致某个特定分区资源耗尽而其他分区闲置的问题。在一些情况下不能使用L1缓存来解决这个问题,因为在这些场景下你需要不断地从L2 cache或数据库中获取最新的数据。Hot Key问题主要出现在Read Intensive的应用当中。
解决Redis 的 Hot Key问题的一个潜在方案是可以通过主从复制的方式来将读请求分散到多个replica中。如下图:

但是这种设计没有从根本解决hot key的问题,所以我们设计系统的目标是尽量使每个请求都分散到不同的cluster nodes中,如下图所示:

所以作者提出了如下针对Redis Hot key的解决方案,主要是通过Redis特有的Key Hash Tag来实现的。我们知道, 在Redis集群模式下,Redis会对每个键使用CRC16 算法并取模来决定这个键写在哪个Key Slot中,并存入相应的分区,但如果我们在键的名字中使用大括号{},则只有大括号里面的字符会用来计算键的槽和相应的分区,而不是整个键。举个例子,如果我们有个键:doordash,在正常情况下redis会使用doordash来计算相应的key slot和分区,但如果我们有另外一个键:{copy:0} doordash,我们则只会使用copy:0来计算key slot和分区。以此为基础,我们可以对Hot key做相应的copy如下:

Hot Key doordash现在有三个副本,我们可以把这三个副本均匀分布在redis cluster中。然后在写入数据的时候同时写入这三个副本到每一个分区中,在客户端读取过程中,通过生成从0-2随机值然后生成特定的副本key,再去相应的分区中读取值。示例程序如下:

在这种方式中相同的键值需要被复制多次在不同的分区中,但因为这个键值会被访问多次,所以这个复制操作也是值得的。
Future
在redis 6中,可以使用RESP3协议和Redis服务器端对客户端缓存的支持,来提高L1缓存的提前逐出时间,并减少使用网络资源。另外,使用proxy可以使客户端请求路由变得更直接。第三点作者提到的是redis 6.0中引入了多线程io,可以显著提高cpu利用率和提高系统吞吐量。