本文是学习廖雪峰《Python基础》的学习笔记。
基本概念
Python程序是大小写敏感的。
缩进
以#开头的语句是注释,其他每一行都是一个语句。
当语句以冒号:结尾时,缩进的语句视为代码块。缩进有利有弊。
好处1 强迫你写出格式化的代码。
但没有规定缩进是几个空格还是Tab。
按照约定俗成的管理,应该始终坚持使用4个空格的缩进。好处2 强迫你写出缩进较少的代码。
你会倾向于把一段很长的代码拆分成若干函数,从而得到缩进较少的代码。缩进的坏处
缩进的坏处就是“复制-粘贴”功能失效了,这是最坑爹的地方。
当你重构代码时,粘贴过去的代码必须重新检查缩进是否正确。
此外,IDE很难像格式化Java代码那样格式化Python代码。
- 赋值
在Python中,等号=是赋值语句,可以把任意数据类型赋值给变量,同一个变量可以反复赋值,而且可以是不同类型的变量。
这种变量本身类型不固定的语言称之为动态语言,与之对应的是静态语言。
静态语言在定义变量时必须指定变量类型,如果赋值的时候类型不匹配,就会报错。
数据类型和变量
- a = 'ABC'
理解变量在计算机内存中的表示也非常重要。当我们写:
a = 'ABC'时,Python解释器干了两件事情:
(1) 在内存中创建了一个'ABC'的字符串;
(2) 在内存中创建了一个名为a的变量,并把它指向'ABC'。
- 除法
/ 除法计算结果是浮点数,即使是两个整数恰好整除,结果也是浮点数:
9 / 3
3.0
还有一种除法是//,称为地板除,两个整数的除法仍然是整数:
10 // 3
3
- 整数和浮点数
Python的整数没有大小限制。
而某些语言的整数根据其存储长度是有大小限制的,例如Java对32位整数的范围限制在-2147483648-2147483647。
Python的浮点数也没有大小限制。
但是超出一定范围就直接表示为inf(无限大)。
字符串和编码
计算机系统通用的字符编码工作方式:
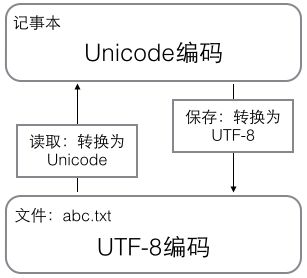
在计算机内存中,统一使用Unicode编码。
当需要保存到硬盘或者需要传输的时候,就转换为UTF-8编码。用记事本编辑的时候,从文件读取的UTF-8字符被转换为Unicode字符到内存里,编辑完成后,保存的时候再把Unicode转换为UTF-8保存到文件
 编码
编码
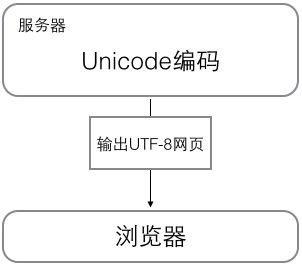
浏览网页的时候,服务器会把动态生成的Unicode内容转换为UTF-8再传输到浏览器:
 web-utf-8
web-utf-8
所以你看到很多网页的源码上会有类似的信息,表示该网页正是用的UTF-8编码。
Python需要设置文件按照utf-8读取
由于Python源代码也是一个文本文件,所以,当你的源代码中包含中文的时候,在保存源代码时,就需要务必指定保存为UTF-8编码。
当Python解释器读取源代码时,为了让它按UTF-8编码读取,我们通常在文件开头写上这两行:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
第一行注释是为了告诉Linux/OS X系统,这是一个Python可执行程序,Windows系统会忽略这个注释;
第二行注释是为了告诉Python解释器,按照UTF-8编码读取源代码,否则,你在源代码中写的中文输出可能会有乱码。
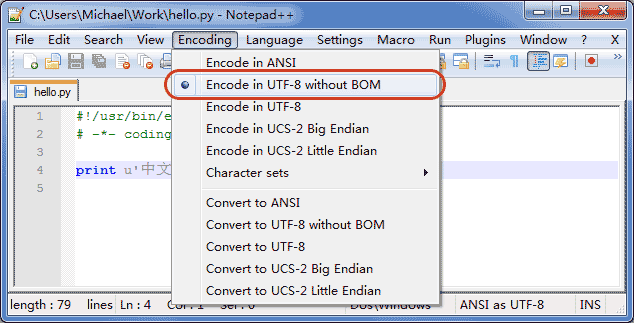
申明了UTF-8编码并不意味着你的.py文件就是UTF-8编码的,必须并且要确保文本编辑器正在使用UTF-8 without BOM编码:
 set-encoding-in-notepad++
set-encoding-in-notepad++
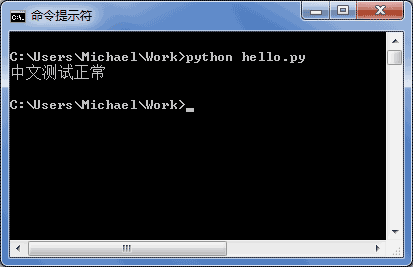
如果.py文件本身使用UTF-8编码,并且也申明了# -*- coding: utf-8 -*-,打开命令提示符测试就可以正常显示中文:
 py-chinese-test-in-cmd
py-chinese-test-in-cmd
复杂数据类型
- list
# list
lst = ['a', 'c', 'd']
print(lst)
print("len:%d" % (len(lst)))
lst.append('e')
print(lst)
lst.insert(1, 'b')
print(lst)
print("lst[-1]:%s" % (lst[-1]))
lst.pop()
print(lst)
print("lst[0]:%s" % (lst[0]))
运行结果:
['a', 'c', 'd']
len:3
['a', 'c', 'd', 'e']
['a', 'b', 'c', 'd', 'e']
lst[-1]:e
['a', 'b', 'c', 'd']
lst[0]:a
- dict
d = {"Jim" : 80, "Kate" : 100}
print(d["Jim"])
为什么dict查找速度这么快?因为dict的实现原理和查字典是一样的。
假设字典包含了1万个汉字,我们要查某一个字,一个办法是把字典从第一页往后翻,直到找到我们想要的字为止,这种方法就是在list中查找元素的方法,list越大,查找越慢。
dict先在字典的索引表里(比如部首表)查这个字对应的页码,然后直接翻到该页,找到这个字。无论找哪个字,这种查找速度都非常快,不会随着字典大小的增加而变慢。
对dict来说,给定一个名字,比如'Michael',dict在内部就可以直接计算出Michael对应的存放成绩的“页码”,也就是95这个数字存放的内存地址,直接取出来,所以速度非常快。
你可以猜到,这种key-value存储方式,在放进去的时候,必须根据key算出value的存放位置,这样,取的时候才能根据key直接拿到value。
list 与 dict优缺点
和list比较,dict有以下几个特点:
- 查找和插入的速度极快,不会随着key的增加而变慢;
- 需要占用大量的内存,内存浪费多。
而list相反:
- 查找和插入的时间随着元素的增加而增加;
- 占用空间小,浪费内存很少。
所以,dict是用空间来换取时间的一种方法。
# dict
print("\ndict test")
d = {"Jim" : 80, "Kate" : 100}
# 判断是否存在
name = "Jim"
if name in d:
print("using in. The score of %s: %d" % (name, d[name]))
else:
print("using in. %s no exist." % (name))
name = "Jack"
if (None != d.get(name)):
print("using get(). The score of %s: %d" % (name, d[name]))
else:
print("using get(). %s no exist." % (name))
# 删除数据
d.pop("Kate")
print("After delete Kate...")
print(d)
运行结果:
dict test
using in. The score of Jim: 80
using get(). Jack no exist.
After delete Kate...
{'Jim': 80}
如何查询某个函数的用法
在CPython中用help()函数可以查询函数的用法。
>>> help(range)
查询结果如下:
Help on built-in function range in module __builtin__:
range(...)
range(stop) -> list of integers
range(start, stop[, step]) -> list of integers
Return a list containing an arithmetic progression of integers.
range(i, j) returns [i, i+1, i+2, ..., j-1]; start (!) defaults to 0.
When step is given, it specifies the increment (or decrement).
For example, range(4) returns [0, 1, 2, 3]. The end point is omitted!
These are exactly the valid indices for a list of 4 elements.
(END)
按q即可返回到CPython交互界面。
localhost:~ Private$ python
Python 2.7.10 (default, Oct 6 2017, 22:29:07)
[GCC 4.2.1 Compatible Apple LLVM 9.0.0 (clang-900.0.31)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> help(range)
>>>
References:
https://www.liaoxuefeng.com/wiki/0014316089557264a6b348958f449949df42a6d3a2e542c000/001431658427513eef3d9dd9f7c48599116735806328e81000