前言
Spring Data JPA是Spring Data的一个子项目,通过提供基于JPA的Repository极大的减少了JPA作为数据访问方案的代码量,你仅仅需要编写一个接口集成下SpringDataJPA内部定义的接口即可完成简单的CRUD操作。
本文从构建项目到对JPA的详细使用,争取能够尽量全的演示JPA的相关应用,大体内容如下:
- JPA环境搭建、配置
- 表关系配置演示:多对多、多对一、一对多
- 基本CRUD操作
- JPA实体对象的4种状态详解
- Example查询
- 接口规范方法名查询
- @Query注解使用
- Criteria查询
- 性能问题解决(循环引用、N+1查询)
一、构建项目
引入依赖
新建springboot项目,在pom文件中引入jpa的相关依赖,如下:
org.springframework.boot
spring-boot-starter-data-jpa
另外我们在引入另外的web及数据库连接相关的依赖:
org.springframework.boot
spring-boot-starter-jdbc
org.springframework.boot
spring-boot-starter-web
com.alibaba
druid-spring-boot-starter
1.1.10
mysql
mysql-connector-java
runtime
数据源及jpa配置
在application.yml文件中加入如下配置:
server:
port: 8080
spring:
datasource:
name: mysql_test
#基本属性
url: jdbc:mysql://localhost:3306/test?useSSL=false&useUnicode=true&characterEncoding=utf8&autoReconnect=true&rewriteBatchedStatements=TRUE&serverTimezone=UTC&allowMultiQueries=true
username: root
password: root
type: com.alibaba.druid.pool.DruidDataSource
#druid相关配置
druid:
#监控统计拦截的filters
filters: stat
#配置初始化大小/最小/最大
initial-size: 1
min-idle: 1
max-active: 20
#获取连接等待超时时间
max-wait: 60000
#间隔多久进行一次检测,检测需要关闭的空闲连接
time-between-eviction-runs-millis: 60000
#一个连接在池中最小生存的时间
min-evictable-idle-time-millis: 300000
validation-query: SELECT 'x'
test-while-idle: true
test-on-borrow: false
test-on-return: false
#打开PSCache,并指定每个连接上PSCache的大小。oracle设为true,mysql设为false。分库分表较多推荐设置为false
pool-prepared-statements: false
max-pool-prepared-statement-per-connection-size: 20
jpa:
show-sql: true
# 指定生成表名的存储引擎为InnoDBD
database-platform: org.hibernate.dialect.MySQL5InnoDBDialect
hibernate:
# 自动创建|更新|验证数据库表结构配置
ddl-auto: update
jackson:
date-format: yyyy-MM-dd HH:mm:ss
logging:
level:
com.along: debug
jpa相关的配置跟简单,这里特别要说明spring.jpa.hibernate.ddl-auto这个配置,该配置有四个可选值,下面是详细说明:
- create:每次运行该程序,没有表格会新建表格,表内有数据会清空
- create-drop:每次程序结束的时候会清空表
- update:每次运行程序,没有表格会新建表格,表内有数据不会清空,只会更新
- validate:运行程序会校验数据与数据库的字段类型是否相同,不同会报错
线上环境我们validate,开发环境一般用update
定义实体类
为了后面演示多表关系操作,这里设计了三张表,分别是用户表(User)、权限表(Role)和文章表(Article),用户与权限是多对多关系,用户与文章是一对多关系。
为了代码的简洁,我们先创建一个基类BaseData,在这个类里写每个表的共了有字段,继承Serializable、主键id、创建时间、更新时间,后面三个表都继承这个类,内容如下:
@MappedSuperclass
public abstract class BaseData implements Serializable {
private static final long serialVersionUID = -3013776712039356819L;
@Id
@GeneratedValue(generator = "uuid")
@GenericGenerator(name = "uuid", strategy = "uuid2")
private String id;
@Temporal(TemporalType.TIMESTAMP)
private Date createTime;
@Temporal(javax.persistence.TemporalType.TIMESTAMP)
private Date updateTime;
@PrePersist
void createdAt() {
this.createTime = this.updateTime = new Date();
}
@PreUpdate
void updatedAt() {
this.updateTime = new Date();
}
// getter setter...
}
下面定义用户表(User.class)
package com.along.model.entity;
import com.fasterxml.jackson.annotation.JsonFormat;
import com.fasterxml.jackson.annotation.JsonIgnoreProperties;
import javax.persistence.*;
import java.util.Date;
import java.util.List;
import java.util.Set;
/**
* @Description: 用户实体类
* @Author along
* @Date 2019/1/8 16:50
*/
@Entity
@Table(name = "user") //对应数据库中的表名
public class User extends BaseData {
private static final long serialVersionUID = -5103936306962248929L;
private String name;
private String password;
private Integer sex; // 1:男;0:女
private Integer status = 1; //-1:删除;0 禁用 1启用
private String email;
@Temporal(TemporalType.DATE)
@JsonFormat(pattern = "yyyy-MM-dd")
private Date birthday;
/**
* 一对多配置演示
* 级联保存、更新、删除、刷新;延迟加载。当删除用户,会级联删除该用户的所有文章
* 拥有mappedBy注解的实体类为关系被维护端
* mappedBy="user"中的user是Article中的user属性
*/
@OneToMany(mappedBy = "user", cascade = CascadeType.ALL, fetch = FetchType.LAZY)
private List articleList; // 文章
/**
* 多对多配置演示
*/
@ManyToMany(cascade = CascadeType.MERGE, fetch = FetchType.LAZY)
@JoinTable(
name = "user_role", // 定义中间表的名称
joinColumns = {@JoinColumn(name = "user_id", referencedColumnName = "id")}, // 定义中间表中关联User表的外键名
inverseJoinColumns = {@JoinColumn(name = "role_id", referencedColumnName = "id")} // 定义中间表中关联role表的外键名
)
private Set roles; // 角色外键
// getter and setter...
配置说明:这里采用实实体类自动生成数据库表,字段名会和数据库字列名一样,这样就可以省略@Column(name = "")注解,默认每个字段都是可以为空的,如果需要不能为空,就加@Column(nullable = false)注解。同时上面代码改做了多对多和一对多的配置,有详细的注解说明。
下面定义权限表(Role.class)
package com.along.model.entity;
import com.fasterxml.jackson.annotation.JsonIgnoreProperties;
import javax.persistence.*;
import java.util.Set;
/**
* @Description: 角色实体类
* @Author along
* @Date 2019/1/8 16:56
*/
@Entity
@Table(name = "role")
public class Role extends BaseData {
private static final long serialVersionUID = 5012235295240129244L;
private String roleName; // 角色名
private Integer roleType; // 1: 超级管理员 2: 系统管理员 3:一般用户
private Integer state; // 0禁用 1 启用
@ManyToMany(cascade = CascadeType.MERGE, fetch = FetchType.LAZY)
@JoinTable(
name = "user_role",
joinColumns = {@JoinColumn(name = "role_id", referencedColumnName = "id")},
inverseJoinColumns = {@JoinColumn(name = "user_id", referencedColumnName = "id")}
)
private Set users; // 与用户多对多
// getter and setter ...
}
下面是文章表(Article.class)
package com.along.model.entity;
import com.fasterxml.jackson.annotation.JsonIgnoreProperties;
import javax.persistence.*;
import javax.validation.constraints.NotEmpty;
import javax.validation.constraints.Size;
/**
* @Description: 文章实体类
* @Author along
* @Date 2019/1/8 17:38
*/
@Entity
@Table(name = "article")
public class Article extends BaseData{
private static final long serialVersionUID = -4817984675096952797L;
@NotEmpty(message = "标题不能为空")
@Column(nullable = false, length = 50)
private String title;
@Lob // 大对象,映射 MySQL 的 Long Text 类型
@Basic(fetch = FetchType.LAZY) // 懒加载
@Column(nullable = false) // 映射为字段,值不能为空
private String content; // 文章全文内容
/**
* 多对一配置演示:
* 可选属性optional=false,表示sysUser不能为空
* 配置了级联更新(合并)和刷新,删除文章,不影响用户
*/
@ManyToOne(cascade = {CascadeType.MERGE, CascadeType.REFRESH}, optional = false)
@JoinColumn(name = "user_id") // 设置在article表中的关联字段(外键)名
private User user; // 所属用户
// getter and setter ...
}
写到这里我们就可以启动项目了,运行启动类就能在数据库中生成和实体类对应的表。
DAO层编写,使用JpaRepository接口
我们创建Dao接口继承JpaRepository接口,JpaRepository需要泛型接口参数,第一个参数是实体,第二则是主键的类型,也可以是Serializable。下面只给出UserDao的代码,剩下两个类似
/**
* @Description: 用户表dao
* @Author along
* @Date 2019/1/9 14:07
*/
public interface UserDao extends JpaRepository {
}
继承了JpaRepository后会自动被spring注册成为bean,这样用户表的dao层就编写好了,可以进行基本的crud操作。
JpaRepository为我们做了什么?来看下JpaRepository的源码
@NoRepositoryBean
public interface JpaRepository extends PagingAndSortingRepository, QueryByExampleExecutor {
List findAll(); // 查询所有
List findAll(Sort sort); // 查询所有,带排序
List findAllById(Iterable ids); // 根据id列表查询
List saveAll(Iterable entities); // 批量保存
void flush(); // 立即写入数据库,正常情况下在事务提交的时候,JPA会自动执行flush()一次性保存所有数据。
S saveAndFlush(S entity); // 插入数据并且立即将更改写入数据库
void deleteInBatch(Iterable entities); // 批量删除
void deleteAllInBatch(); // 删除批量调用中的所有实体(清空表)
T getOne(ID id); // 根据id得到一个对象
@Override
List findAll(Example example); // 实例查询
@Override
List findAll(Example example, Sort sort); // 实例查询,排序
}
可以看到JpaRepository实现了基本的crud操作,JpaRepository同时继承了PagingAndSortingRepository和QueryByExampleExecutor接口
PagingAndSortingRepository接口包含了全表查询时的分页查询和排序,源码如下:
@NoRepositoryBean
public interface PagingAndSortingRepository extends CrudRepository {
Iterable findAll(Sort sort); // 查询多有,带排序
Page findAll(Pageable pageable); // 分页查询多有
}
QueryByExampleExecutor接口是用来做复杂查询的,十分好用,会在下文详细介绍,下面是该接口的源码:
public interface QueryByExampleExecutor {
Optional findOne(Example example); // 根据实例查询一个实体
Iterable findAll(Example example); // 查询所有符合给定实例的实体
Iterable findAll(Example example, Sort sort); // 查询所有符合给定实例的实体,带排序
Page findAll(Example example, Pageable pageable); // 分页查询所有符合给定实例的实体
long count(Example example); // 得到符合给定实例的数量
boolean exists(Example example); // 判断是否存在
}
现在我们对继承了JpaRepository的UserDao可以做到多少数据库操作已经有了大概的认识。
二、JPA的使用
1. 基本CRUD操作
下面我们编写UserService来演示基本的crud操作,代码如下:
@Service(value = "userService")
@Transactional
public class UserService {
private UserDao userDao;
@Autowired
public UserServiceImpl(UserDao userDao) {
this.userDao = userDao;
}
/**
* 保存
*/
public User save(User user) {
return userDao.save(user);
}
/**
* 批量添加
*/
public List saveAll(List list) {
return userDao.saveAll(list);
}
/**
* 分页查询所有,带排序功能
*/
public Page findAll() {
//分页+排序查询演示:
//Pageable pageable = new PageRequest(page, size);//2.0版本后,该方法以过时
Sort sort = new Sort(Sort.Direction.DESC, "updateTime","createTime");
Pageable pageable = PageRequest.of(page, size, sort);
Page users = userService.findAll(pageable);
return userDao.findAll(pageable);
}
/**
* 更新
*/
public Boolean update(User user) {
Optional u = userDao.findById(user.getId());
if (u.isPresent()) {
User oldUser = u.get();
oldUser.setName(user.getName());
oldUser.setRoles(user.getRoles());
oldUser.setBirthday(user.getBirthday());
oldUser.setEmail(user.getEmail());
oldUser.setUpdateTime(new Date());
userDao.save(oldUser);
return Boolean.TRUE;
}
return Boolean.FALSE;
}
/**
* 删除
*/
@Override
public void delete(String id) {
userDao.deleteById(id);
}
}
上面代码举例了简单的几个crud操作,这里要对分页查询和更新操作做特别的说明:
分页查询:
分页查询的关键在于创建Pageable对象,一般通过实现类PageRequest创建,早先的版本我们同伙new的方式创建Pageable对象,如下
Pageable pageable = new PageRequest(page, size)
但是在2.0版本后该方法已经过时,我们转而使用PageRequest的of方法创建Pageable实例,下面是源码片段:
/**
* 不带排序
*/
public static PageRequest of(int page, int size) {
return of(page, size, Sort.unsorted());
}
/**
* 带排序
*/
public static PageRequest of(int page, int size, Sort sort) {
return new PageRequest(page, size, sort);
}
/**
* 带排序信息
*/
public static PageRequest of(int page, int size, Direction direction, String... properties) {
return of(page, size, Sort.by(direction, properties));
}
下面是几个模拟场景举例:
- 第1页每页显示20条
Pageable pageable = PageRequest.of(0, 20);
- 第1页显示20条,倒序排序,按创建时间字段排序,如果创建时间相同,按更新时间排序
方式一:构建Sort对象方式创建
Sort sort = new Sort(Sort.Direction.DESC, "updateTime","createTime");
Pageable pageable = PageRequest.of(page, size, sort);
方式二:直接传入排序信息
Pageable pageable =
PageRequest.of(page, size, Sort.Direction.DESC, "updateTime","createTime");
更新:
JpaRepository并没有提供专门的update方法,而是将更新操作放在save中完成了,下面是save方法的源码实现:
@Transactional
public S save(S entity) {
if (entityInformation.isNew(entity)) {
em.persist(entity);
return entity;
} else {
return em.merge(entity);
}
}
我们看到调用save方法传入一个实例,首先会通过entityInformation.isNew(entity)来判断该实体是否是一个新的对象,具体的是先判断有无id,如果有就通过id在数据库中查找是否存在对应的数据,如果存在就是更新操作,会调用EntityManager的merge()方法执行更新,如果不存在就说明是插入操作,会调用EntityManager的persist()方法执行插入。
EntityManager管理器
通过源码我们可以看到save方法实质上是调用的EntityManager的方法完成的数据库操作,所以这里有必要介绍下EntityManager接口,在此之前得了解jpa中实体对象拥有的四种状态:
- 瞬时状态(new/transient):没有主键,不与持久化上下文关联,即 new 出的对象(但不能指定id的值,若指定则是游离态而非瞬时态)
- 托管状态(persistent):使用EntityManager进行find或者persist操作返回的对象即处于托管状态,此时该对象已经处于持久化上下文中(被EntityManager监控),任何对该实体的修改都会在提交事务时同步到数据库中。
- 游离状态(detached):有主键,但是没有跟持久化上下文关联的实体对象。
- 删除状态 (deleted):当调用EntityManger对实体进行remove后,该实体对象就处于删除状态。其本质也就是一个瞬时状态的对象。
下面的图清晰的表示了各个状态间的转化关系:
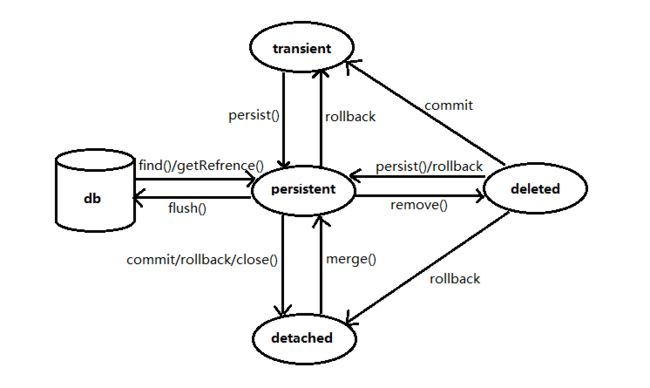
下面介绍下EntityManager接口的几个常用方法:
- persist():将临时状态(无主键)的对象转化为托管状态。由于涉及数据库增删改,执行该语句前需启用事务
entityManager.persist(modelObject);
- merge():将游离状态(有主键)的对象转化为托管托管状态,不同于persist(),merger()对于操作的对象,如果对象存在于数据库则对对象进行修改,如果对象在数据库中不存在,则将该对象作为一条新记录插入数据库。
entityManager.merge(modelObject);
- find()与getReference():从数据库中查找对象。不同点:当对象不存在时,find()会返回null,getReference()则会抛出javax.persistence.EntityNotFoundException异常。
// 参数一:实体类的class,参数二:实体主键值
entityManager.find(Class ModelObject.class , int key);
- remove():将托管状态的对象转化为删除状态。由于涉及数据库增删改,执行该语句前需启用事务
entityManager.remove(entityManager.getReference(ModelObject.class, key));
- refresh(Object obj):重新从数据库中读取数据。可以保证当前的实例与数据库中的实例的内容一致。该方法用来操作托管状态的对象。
- contains(Object obj):判断对象在持久化上下文(不是数据库)中是否存在,返回true/false。
- flush():立即将对托管状态对象所做的修改(包括删除)写入数据库。
从上面内容我们发现通过EntityManager对实体对象所做的操作实质是让对象在不同的状态间转换,而这些修改是在执行flush()后才会真正的写入数据库。正常情况下不需要手动执行flash(),在事务提交的时候,JPA会自动执行flush()一次性保存所有数据。
如果要立即保存修改,可以手动执行flush()。
同时我们可以通过setFlushModel()方法修改EntityManager的刷新模式。默认为AUTO,这种模式下,会在执行查询(指使用JPQL语句查询前,不包括find()和getReference()查询)前或事务提交时自动执行flush()。通过entityManager.setFlushMode(FlushModeType.COMMIT)设置为COMMIT模式,该模式下只有在事务提交时才会执行flush()。 - clear():把实体管理器中所有的实体对象(托管状态)变成游离状态,clear()之后,对实体类所做的修改也会丢失。
现在我们再回到更新方法,为了方便查看,我们摘取出上面写好的更新方法实现
public Boolean update(User user) {
Optional u = userDao.findById(user.getId());
if (u.isPresent()) {
User oldUser = u.get();
oldUser.setName(user.getName());
oldUser.setRoles(user.getRoles());
oldUser.setBirthday(user.getBirthday());
oldUser.setEmail(user.getEmail());
oldUser.setUpdateTime(new Date());
userDao.save(oldUser);
return Boolean.TRUE;
}
return Boolean.FALSE;
}
如果你已经理解了上文中的JPA的四种状态,那你应该就能看出这段代码存在的问题,oldUser是从数据库中查出来的,是托管状态对象,受EntityManager管理,我们后面对该对象所做的修改会在事务提交时自动调用flush()将修改写入数据库完成更新,所以并不需要再调用save()方法执行更新,这样显得多此一举。当然还要注意这样实现更新需要在方法上加@Transactional启动事务。
下面是修改后的代码实现:
@Transactional
public Boolean update(User user) {
Optional u = userDao.findById(user.getId());
if (u.isPresent()) {
User oldUser = u.get();
oldUser.setName(user.getName());
oldUser.setRoles(user.getRoles());
oldUser.setBirthday(user.getBirthday());
oldUser.setEmail(user.getEmail());
oldUser.setUpdateTime(new Date());
return Boolean.TRUE;
}
return Boolean.FALSE;
}
2. Example查询
上文中说到JpaRepository继承了QueryByExampleExecutor接口,利用该接口可以实现相对复杂的实例查询,下面再来看看QueryByExampleExecutor接口的源码:
public interface QueryByExampleExecutor {
Optional findOne(Example example); // 根据实例查询一个实体
Iterable findAll(Example example); // 查询所有符合给定实例的实体
Iterable findAll(Example example, Sort sort); // 查询所有符合给定实例的实体,带排序
Page findAll(Example example, Pageable pageable); // 分页查询所有符合给定实例的实体
long count(Example example); // 得到符合给定实例的数量
boolean exists(Example example); // 判断是否存在
}
可以看到所有api都需要传入Example对象,下面是Example api的组成:
- Probe:实体对象,比如我们要查询User表,那User对象就是可以作为Probe。
- ExampleMatcher:匹配器,用来详细描述实体对象中的内容的查询方式,如规定某个属性为模糊查询。
- Example:实例,代表的是完整的查询条件,由Probe和ExampleMatcher共同创建。
写一个简单的测试方法来感受下实例查询
模拟需求:查询姓名为along和性别为男的用户
@Autowired
private UserDao userDao;
@Test
public void test() {
// 创建查询条件数据对象
User user = new User();
user.setName("along");
user.setSex(1);
// 创建实例
Example example = Example.of(user);
// 查询
List users = userDao.findAll(example);
//输出结果
System.out.println("数量:" + users.size());
for (User u : users) {
System.out.println(u);
}
}
先创建实体对象user,因为我们是根据姓名和性别查询,所以为user对象的姓名和性别属性复制内容,然后同通过Example.of()方法创建Example实例最后执行查询。这里我们调用Example.of()只传入了一个实体对象user,这样jpa会在处理时默认传入一个默认的ExampleMatcher。
下面是默认ExampleMatcher规定的查询方式:
- 忽略空值,只将实体对象中中不为空的字段作为查询条件
- 所有查询条件都采用精确匹配
- 查询条件大小写敏感
运行测试,控制台输出如下内容:
Hibernate: select
user0_.id as id1_2_,
user0_.create_time as create_t2_2_,
user0_.update_time as update_t3_2_,
user0_.birthday as birthday4_2_,
user0_.email as email5_2_,
user0_.name as name6_2_,
user0_.password as password7_2_,
user0_.sex as sex8_2_,
user0_.status as status9_2_
from
user user0_
where
user0_.sex=1 and user0_.name=? and user0_.status=1
数量:4
along
along
along
along
成功查询出了4条数据,我们接下来观察打印出来的sql,查询条件正是name、sex和status,而且都是精确查询,这时候发现多了一个查询条件status,因为实例查询默认会将实例中不为空的内容作为查询条件,而我们在定义User实体类的时候为status属性设了默认值1。
如果我们需要查询条件只有name和sex,这时候就要定义ExampleMatcher来忽略status属性。我们修改测试代码如下
@Autowired
private UserDao userDao;
@Test
public void test() {
// 创建查询条件数据对象
User user = new User();
user.setName("along");
user.setSex(1);
// 创建匹配器,即规定如何使用查询条件
ExampleMatcher matcher = ExampleMatcher.matching() // 构建对象
.withIgnorePaths("status"); // 忽略status属性
// 创建实例
Example example = Example.of(user, matcher);
// 查询
List users = userDao.findAll(example);
//输出结果
System.out.println("数量:" + users.size());
for (User u : users) {
System.out.println(u.getName());
}
}
运行测试,控制带输出sql如下,可以看到查询条件已经没有status了
select
user0_.id as id1_2_,
user0_.create_time as create_t2_2_,
user0_.update_time as update_t3_2_,
user0_.birthday as birthday4_2_,
user0_.email as email5_2_,
user0_.name as name6_2_,
user0_.password as password7_2_,
user0_.sex as sex8_2_,
user0_.status as status9_2_
from
user user0_
where
user0_.sex=1 and user0_.name=?
理解ExampleMatcher
我们可以通过下面代码创建一个默认的ExampleMatcher对象
ExampleMatcher matcher = ExampleMatcher.matching();
下面是ExampleMatcher的实现类的部分源码,展示了 ExampleMatcher的六个配置项
class TypedExampleMatcher implements ExampleMatcher {
private final NullHandler nullHandler; // Null值处理方式
private final StringMatcher defaultStringMatcher; // 默认字符串匹配方式
private final PropertySpecifiers propertySpecifiers; // 各个属性特定查询方式
private final Set ignoredPaths; // 忽略属性列表
private final boolean defaultIgnoreCase; // 默认大小写忽略方式
private final MatchMode mode; // 默认为all,目前没看出有什么特别的作用
/**
* 空参构造,为上面的属性设置默认值
* null处理方式为忽略
* 默认字符串匹配方式为default(精确匹配)
* 各属性特定查询方式默认为空
* 忽略属性列表默认为空列表
* 默认大小写忽略方式为false,不忽略
* MatchMode默认为all
*/
TypedExampleMatcher() {
this(NullHandler.IGNORE, StringMatcher.DEFAULT, new PropertySpecifiers(), Collections.emptySet(), false, MatchMode.ALL);
}
......
}
从源码我们可以看出ExampleMatcher的默认配置如下:
- nullHandler:IGNORE。Null值处理方式:忽略
- defaultStringMatcher:DEFAULT。默认字符串匹配方式:默认(相等)
- defaultIgnoreCase:false。默认大小写忽略方式:不忽略
- propertySpecifiers:空。各属性特定查询方式,空。
- ignoredPaths:空列表。忽略属性列表,空列表。
但是只创建一个默认的ExampleMatcher没有什么意义,上文说到就算你创建Example实例时不传ExampleMatcher对象,jpa也会自动加上默认的ExampleMatcher。
下面对每个配置项进行详细讲解
- nullHandler:null值处理方式,枚举类型,两个可选值:
INCLUDE(包括)和IGNORE(忽略),默认为IGNORE。
通过下面代码改变默认的null值处理方式:
// 默认就是忽略,所以再设置为忽略就没有意义了,下面设置为不忽略
ExampleMatcher matcher = ExampleMatcher.matching()
.withNullHandler(ExampleMatcher.NullHandler.INCLUDE) // 方式一
.withIncludeNullValues(); // 方式二
- defaultStringMatcher:默认字符串匹配方式,枚举类型,六个可选值:
DEFAULT(默认,效果同EXACT),EXACT(精确匹配,即 = ),STARTING(开始匹配,即 ?% ),ENDING(结束匹配,即 %? ),CONTAINING(包含,模糊匹配,即 %?% ),REGEX(正则表达式匹配)
下面是改变默认字符串匹配方式的代码示例:
ExampleMatcher matcher = ExampleMatcher.matching()
//下面只用配置一个
.withStringMatcher(ExampleMatcher.StringMatcher.STARTING) // 开始匹配 %?
.withStringMatcher(ExampleMatcher.StringMatcher.ENDING) // 结束匹配 ?%
.withStringMatcher(ExampleMatcher.StringMatcher.CONTAINING) // 包含,模糊匹配 %?%
.withStringMatcher(ExampleMatcher.StringMatcher.REGEX); // 正则匹配
- propertySpecifiers:各属性特定查询方式,描述了各个属性单独定义的查询方式,每个查询方式中包含4个元素:属性名、字符串匹配方式、大小写忽略方式、属性转换器。如果属性未单独定义查询方式,或单独查询方式中,某个元素未定义(如:字符串匹配方式),则采用 ExampleMatcher 中定义的默认值,即上面介绍的 defaultStringMatcher 和 defaultIgnoreCase 的值。
一个属性的特定查询方式,包含了3个信息:字符串匹配方式、大小写忽略方式、属性转换器,存储在 propertySpecifiers 中,操作时用 GenericPropertyMatcher 类来传递配置信息。
下面是该属性配置的代码示例:
ExampleMatcher matcher = ExampleMatcher.matching()
//方式一:单独设置name字段为模糊查询方式
.withMatcher("name", ExampleMatcher.GenericPropertyMatcher.of(ExampleMatcher.StringMatcher.CONTAINING))
//方式二:设置name字段为模糊查询,忽略大小写
.withMatcher("name", ExampleMatcher.GenericPropertyMatcher.of(ExampleMatcher.StringMatcher.CONTAINING, true))
//方式三(推荐):链式设置
.withMatcher("name", ExampleMatcher.GenericPropertyMatchers.contains().ignoreCase());
- ignoredPaths:忽略属性列表,忽略的属性不参与查询过滤。
下面是添加忽略属性的代码示例:
ExampleMatcher matcher = ExampleMatcher.matching()
.withIgnorePaths("status", "sex");
- defaultIgnoreCase:默认大小写忽略方式,布尔型,当值为false时,即不忽略,大小不相等。该配置对所有字符串属性过滤有效,除非该属性在 propertySpecifiers 中单独定义自己的忽略大小写方式。
下面是改变默认大小写忽略方式的代码示例:
ExampleMatcher matcher = ExampleMatcher.matching()
// 下面两个等价
.withIgnoreCase()
.withIgnoreCase(true)
// 单独为name属性设置忽略大小写,可设置多个值
.withIgnoreCase("name")
实例查询的限制
- 不支持过滤条件分组。即不支持过滤条件用 or(或) 来连接,所有的过滤查件,都是简单一层的用 and(并且) 连接。
- 灵活匹配只支持字符串类型,其他类型只支持精确匹配
参考文章:https://blog.csdn.net/zhao_tuo/article/details/78604324
3. 接口规范方法名查询(最让我惊喜的查询方式)
根据可读性极强的方法名就能创建查询,初次接触时会让你觉得很不可思议
说明:按照Spring data 定义的规则,查询方法以find|read|get开头,涉及条件查询时,条件的属性用条件关键字连接,整个查询方法名按驼峰式命名。
我们来看下面代码
/**
* @Description: 接口规范方法名查询示例
* @Author along
* @Date 2019/1/9 14:07
*/
public interface UserDao extends JpaRepository, JpaSpecificationExecutor {
/**
* and条件查询
* 对应sql:select u from User u where u.name = ?1 and u.email = ?2
* 参数名大写,条件名首字母大写,并且接口名中参数出现的顺序必须和参数列表中的参数顺序一致
*/
User findByNameAndEmail(String name, String email);
/**
* or条件查询
* 对应sql:select u from User u where u.name = ?1 or u.password = ?2
*/
List findByNameOrPassword(String name, String password);
/**
* between查询
* 对应sql:select u from User u where u.id between ?1 and ?2
*/
List findByCreateTimeBetween(Date startTime, Date endTime);
/**
* less查询
* 对应sql:select u from User u where u.id < ?1
*/
List findByCreateTimeLessThan(Date time);
/**
* greater查询
* 对应sql:select u from User u where u.id > ?1
*/
List findByCreateTimeGreaterThan(Date time);
/**
* is null查询
* 对应sql:select u from User u where u.name is null
*/
List findByNameIsNull();
/**
* Is Not Null查询
* 对应sql:select u from User u where u.name is not null
*/
List findByNameIsNotNull();
/**
* like模糊查询
* 这里的模糊查询并不会自动在name两边加"%",需要手动对参数加"%"
* 对应sql:select u from User u where u.name like ?1
*/
List findByNameLike(String name);
/**
* Not Like模糊查询
* 对应sql:select u from User u where u.name not like ?1
*/
List findByNameNotLike(String name);
/**
* 倒序排序查询
* 对应sql:select u from User u where u.password = ?1 order by u.id desc
*/
List findByPasswordOrderByCreateTimeDesc(String password);
/**
* <>查询
* 对应sql:select u from User u where u.name <> ?1
*/
List findByNameNot(String name);
/**
* in 查询,方法的参数可以是 Collection 类型,也可以是数组或者不定长参数
* 对应sql:select u from User u where u.id in ?1
*/
List findByIdIn(List ids);
/**
* not in 查询,方法的参数可以是 Collection 类型,也可以是数组或者不定长参数
* 对应sql:select u from User u where u.id not in ?1
*/
List findByIdNotIn(List ids);
/**
* 分页查询,方法的参数可以是 Collection 类型,也可以是数组或者不定长参数
* 对应sql:select u from User u where u.id not in ?1 limit ?
*/
Page findByIdNotIn(List ids, Pageable pageable);
}
dao编写完毕,只需在service中调用即可,是不是感觉比上面的Example要优雅很多!而且可以应付大多数的查询需求。如果你用idea,idea还会在你编写方法是提供智能提示,简直不要太贴心。
这里简单地介绍下原理:jpa框架在进行方法名解析时,如果遇到以 find、findBy、read、readBy、get、getBy为前缀的方法名,会忽略前缀,对剩下部分进行解析,再后面会识别如And、Or这样的关键字,来判断以何种方式连接查询关键字。而且如果方法的最后一个参数是 Sort 或 Pageable 类型,就会提取相关的信息,以便按规则进行排序或者分页查询。
4. @Query创建查询
比起接口规范方法名查询,@Query显得稍微麻烦一点,需要自己写JPQL查询语句,但是却更加强大,对方法名没有要求,可以准确控制JPQL语句,而且不局限于查询,还可以和@Modifying一起使用实现跟新操作,你甚至可以使用@Query来指定本地查询,写真正的sql语句,只要设置nativeQuery=true(但是个人建议不要用本地查询,这样就失去了JPA的优势,如果喜欢写sql,为什么不直接用mybatis呢?)
下面是示例代码
/**
* @Description: @Query示例
* @Author along
* @Date 2019/1/9 14:07
*/
public interface UserDao extends JpaRepository {
/**
* 根据name查询,支持命名参数
*/
@Query("select u from User u where u.name = :mame")
List findUserByName(@Param("name")String name);
/**
* 根据sex查询,缩影参数
*/
@Query("select u from User u where u.sex = ?1")
List findUsersBySex(Integer sex);
/**
* 模糊查询
*/
@Query("select u from User u where name like concat('%',?1,'%') ")
List findByName(String name);
/**
* 本地查询
*/
@Query(value = "select * from user where name like CONCAT('%',?1,'%')", nativeQuery = true)
List findByNameLocal(String name);
/**
* 跟新密码,需要加@Modifying
*/
@Modifying
@Query("update user u set u.password = ?1 where u.id = ?2")
Integer updatePasswordById(String password, String id);
}
注意模糊查询的 JPQL 写法,不要写成like '%?1%',这样是查不出来东西的。
用命名参数需要在参数前面用@Param()注解制定参数名,不然会查询失败。
跟新需要加上@Modifying,而且Modifying queries的返回值只能为void或者是int/Integer,调用更新方法前需要开启事务,否则会跟新失败。
5. Criteria查询
上文介绍的查询方法面简单的查询需求已经足够了,但是如果给定的查询条件是不固定的,需要动态的创建查询语句,那上文的方法都就都不适用了,这里可以用Criteria查询解决。
Criteria API查询是通过面向对象的方式构建查询,相比于传统的基于字符串的JPQL查询,优势是类型安全,更加的面向对象。
这里推荐一篇文章,对 Criteria API 讲解的十分详细:详解JPA 2.0动态查询机制:Criteria API
下面我们先用 Criteria API 写一个service方法来实现一个简单的查询需求
@Autoware
private EntityManager entityManager;
public List findUserByNameAndSex0(String name, Integer sex) {
// 1. 利用entityManager构建出CriteriaQuery类型的参数
CriteriaBuilder builder = entityManager.getCriteriaBuilder();
CriteriaQuery query = builder.createQuery(User.class);
// 2. 获取User的Root,也就是包装对象
Root root = query.from(User.class);
// 3. 构建查询条件,这里相当于where user.id = id;
Predicate predicate = builder.and(
builder.like(root.get("name").as(String.class), "%" + name+ "%"),
builder.equal(root.get("sex").as(Integer.class), sex)
);
query.where(predicate); // 到这里一个完整的动态查询就构建完成了
// 指定查询结果集,相当于“select id,name...”,如果不设置,默认查询root中所有字段
query.select(root);
// 4. 执行查询,获取查询结果
TypedQuery typeQuery = entityManager.createQuery(query);
List resultList = typeQuery.getResultList();
return resultList;
}
上面代码完整的实现了一次通过Criteria API查询的过程,下面编写的测试方法测试下查询结果
@Test
public void queryTest() {
List userList = userService.findUserByNameAndSex0("along", 1);
System.out.println(userList.size());
for (User user : userList) {
System.out.println(user.getName());
}
}
下面是运行后控制台打印出来的查询sql
select
user0_.id as id1_2_,
user0_.create_time as create_t2_2_,
user0_.update_time as update_t3_2_,
user0_.birthday as birthday4_2_,
user0_.email as email5_2_,
user0_.name as name6_2_,
user0_.password as password7_2_,
user0_.sex as sex8_2_,
user0_.status as status9_2_
from
user user0_
where
(user0_.name like ?) and user0_.sex=1
sql中结果集并不包括articleList和roles,原因是我们再User实体中做表关联配置时将这两个字段定义为了懒加载(fetch = FetchType.LAZY)。
尽管这达到了我们的目的,但这未免太麻烦了,创建一个查询需要这么多步骤,完全可以利用JPQL语句实现相同的需求,如下:
@Query("select u from User u where u.name like concat('%',:name,'%') and u.sex=:sex")
List findUserByNameAndSex(@Param("name")String name,@Param("sex")Integer sex);
幸运的是JPA为我们考虑到了这一点,我们可以发现上面完成一次查询一共有四个步骤,其中除了第3步构建查询条件,其他的都是固定的代码,JPA提供了JpaSpecificationExecutor接口帮我们实现了步骤1、2、4,我们在编写代码时只需要实现第3步即可。
接下来我们重新实现下上面的需求。
首先是要让UserDao继承JpaSpecificationExecutor接口,如下:
public interface UserDao extends JpaRepository, JpaSpecificationExecutor {
}
JpaSpecificationExecutor接口并不在JpaRepository接口体系中,需要额外继承,而且Spring data JPA不会自动扫描识别,所以要和任意一个Repository的子接口一起使用。
接下来我们在UserService中编写实现方法,如下
@Autowired
private UserDao userDao;
public List findUserByNameAndSex(String name, Integer sex) {
return userDao.findAll(new Specification() {
@Override
public Predicate toPredicate(Root root, CriteriaQuery query, CriteriaBuilder criteriaBuilder) {
// 构建查询条件并返回
return criteriaBuilder.and(
criteriaBuilder.equal(root.get("name"), name),
criteriaBuilder.equal(root.get("sex"), sex)
);
}
});
}
我们只需要重写Sepcfication接口的toPredicate方法,而toPredicate方法自动携带了我们需要的三个参数,这都是JPA提前为我们创建好的,不需要我们手动创建,我们只需要在方法中构建一个Predicate即可,也就是我们自开始的实现的第3步的代码。是不是简洁了很多?
下面深入源码看看JPA是怎么帮我们实现的,首先要看JpaSpecificationExecutor接口的源码
public interface JpaSpecificationExecutor {
Optional findOne(@Nullable Specification spec);
List findAll(@Nullable Specification spec);
Page findAll(@Nullable Specification spec, Pageable pageable);
List findAll(@Nullable Specification spec, Sort sort);
long count(@Nullable Specification spec);
}
可以看出改接口都是围绕着Specification构建的,每个方法的功能也一目了然,接下来看看Specification的源码
@SuppressWarnings("deprecation")
public interface Specification extends Serializable {
long serialVersionUID = 1L;
/**
* 否定给定的{@link Specification}。
*/
static Specification not(Specification spec) {
return Specifications.negated(spec);
}
/**
* 简单的静态工厂方法,在{@link Specification}周围添加一些语法糖。
*/
static Specification where(Specification spec) {
return Specifications.where(spec);
}
/**
* 将给定的{@link Specification}与当前的一个进行对比。
*
* @param other can be {@literal null}.
* @return The conjunction of the specifications
* @since 2.0
*/
default Specification and(Specification other) {
return Specifications.composed(this, other, AND);
}
/**
* 将给定的规范与当前规范进行或运算。
*/
default Specification or(Specification other) {
return Specifications.composed(this, other, OR);
}
/**
* 为给定的{@link Predicate}形式的被引用实体的查询创建WHERE子句
*/
@Nullable
Predicate toPredicate(Root root, CriteriaQuery query, CriteriaBuilder criteriaBuilder);
}
我们只需要把关注点放到最下面的toPredicate方法上,这也是唯一需要我们手动实现的方法。
我们再来看findAll()方法的具体实现:
public List findAll(@Nullable Specification spec) {
return getQuery(spec, Sort.unsorted()).getResultList();
}
因为我们没有传入排序对象Sort,这里生成了一个默认的空的排序对象。再进入getQuery方法
protected TypedQuery getQuery(@Nullable Specification spec, Sort sort) {
return getQuery(spec, getDomainClass(), sort);
}
这里通过getDomainClass()方法得到了当前要查询的User实体的字节码类型,下面再进入getQuery()方法
protected TypedQuery getQuery(
@Nullable Specification spec, Class domainClass, Sort sort) {
// 1. 构建出CriteriaQuery类型的参数
CriteriaBuilder builder = em.getCriteriaBuilder();
CriteriaQuery query = builder.createQuery(domainClass);
// 2. 获取User的Root,也就是包装对象
Root root = applySpecificationToCriteria(spec, domainClass, query);
// 指定查询结果集
query.select(root);
if (sort.isSorted()) {
query.orderBy(toOrders(sort, root, builder));
}
// 4. 执行查询,获取查询结果
return applyRepositoryMethodMetadata(em.createQuery(query));
}
注意我在源码中加的1、2、4注释,再进入applySpecificationToCriteria方法
private Root applySpecificationToCriteria(
@Nullable Specification spec, Class domainClass, CriteriaQuery query) {
Assert.notNull(domainClass, "Domain class must not be null!");
Assert.notNull(query, "CriteriaQuery must not be null!");
// 2. 获取User的Root,也就是包装对象
Root root = query.from(domainClass);
if (spec == null) {
return root;
}
CriteriaBuilder builder = em.getCriteriaBuilder();
// 重点!!!!在这里执行我们实现的toPredicate()方法
Predicate predicate = spec.toPredicate(root, query, builder);
if (predicate != null) {
// 到这里一个完整的动态查询就构建完成了
query.where(predicate);
}
return root;
}
看到这你会发现我们最开始的原始实现中的1、2、4步JPA都做了实现,并且源码中spec参数调用了toPredicate方法,也就是我们自己在service中做的实现,而且在调动toPredicate方法之前Root、CriteriaQuery和CriteriaBuilder都已经创建好了。
到这里我们已经知道JpaSpecificationExecutor底层是如何实现的封装,下面我们来探究下具体的使用。
动态语句查询
下面我们利用JpaSpecificationExecutor实现一个动态语句查询,并实现分页排序功能
public Page findUser(User user, int page, int size) {
Sort sort = new Sort(Sort.Direction.DESC, "updateTime","createTime");
Pageable pageable = PageRequest.of(page, size, sort);
return userDao.findAll(new Specification() {
@Override
public Predicate toPredicate(Root root, CriteriaQuery query, CriteriaBuilder criteriaBuilder) {
List predicateList = new ArrayList<>();
if (!StringUtils.isEmpty(user.getId())) {
predicateList.add(criteriaBuilder.equal(root.get("id"), user.getId()));
}
if (!StringUtils.isEmpty(user.getName())) {
predicateList.add(criteriaBuilder.like(root.get("name"), user.getName()));
}
if (null != user.getCreateTime()) {
predicateList.add(criteriaBuilder.greaterThan(root.get("createTime"), user.getCreateTime()));
}
if (null != user.getUpdateTime()) {
predicateList.add(criteriaBuilder.lessThanOrEqualTo(root.get("updateTime"), user.getUpdateTime()));
}
Predicate[] predicateArr = new Predicate[predicateList.size()];
return criteriaBuilder.and(predicateList.toArray(predicateArr));
}
}, pageable);
}
效果是不是跟mybatis的xml实现的动态查询有些类似?
多表关联查询
User表关联了两张表,分别是Article表和Role表,和Article表是一对多关系,和Role表是多对多关系。下面是关联查询代码示例
/**
* 表关联查询
* @param articleId
* @param roleId
* @return
*/
public List findUserByArticleAndRole(String articleId, String roleId) {
return userDao.findAll(new Specification() {
@Override
public Predicate toPredicate(Root root, CriteriaQuery query, CriteriaBuilder criteriaBuilder) {
// 方式1
ListJoin articleJoin = root.join(root.getModel().getList("articleList", Article.class), JoinType.LEFT);
SetJoin roleJoin = root.join(root.getModel().getSet("roles", Role.class), JoinType.LEFT);
// 方式2
//Join articleJoin = root.join("articleList", JoinType.LEFT);
//Join roleJoin = root.join("roles", JoinType.LEFT);
Predicate predicate = criteriaBuilder.or(
criteriaBuilder.equal(articleJoin.get("id"), articleId),
criteriaBuilder.equal(roleJoin.get("id"), roleId)
);
return predicate;
}
});
}
下面是运行结果生成的sql
select
user0_.id as id1_2_,
user0_.create_time as create_t2_2_,
user0_.update_time as update_t3_2_,
user0_.birthday as birthday4_2_,
user0_.email as email5_2_,
user0_.name as name6_2_,
user0_.password as password7_2_,
user0_.sex as sex8_2_,
user0_.status as status9_2_
from
user user0_
left outer join
article articlelis1_ // 关联article
on
user0_.id=articlelis1_.user_id
left outer join
user_role roles2_ // 关联中间表user_role
on
user0_.id=roles2_.user_id
left outer join
role role3_ // 关联role
on
roles2_.role_id=role3_.id
where
articlelis1_.id=? or role3_.id=?
Criteria查询到这里也就介绍完了,能力有限,介绍的比较粗略。
如果你熟练地掌握了 Criteria API 的使用,你几乎可以使用该方式来应对所有的查询需求,但是面对简单的查询需求,还是建议使用更加简洁的规范方法名查询,只有在其他方式不方便解决时再考虑用 Criteria API 来解决。具体实际开发中如何选择,还要根据实际开发情况而定。
三、性能问题解决
上文为了单纯地介绍jpa的用法,隐藏了很多问题,在这一节中集中介绍并处理。
循环引用问题
再来回顾下User、Role、Article的关系,User与Role是多对多关系,User与Article是一对多关系。因为文章较长,再往上翻回顾比较麻烦,这里再放上这三个类的源码,如下
/**
* 用户实体类
*/
@Entity
@Table(name = "user") //对应数据库中的表名
public class User extends BaseData {
private static final long serialVersionUID = -5103936306962248929L;
private String name;
private String password;
private Integer sex; // 1:男;0:女
private Integer status = 1; //-1:删除;0 禁用 1启用
private String email;
@Temporal(TemporalType.DATE)
@JsonFormat(pattern = "yyyy-MM-dd")
private Date birthday;
@OneToMany(mappedBy = "user", cascade = CascadeType.ALL, fetch = FetchType.LAZY)
private List articleList; // 文章
@ManyToMany(cascade = CascadeType.MERGE, fetch = FetchType.LAZY)
@JoinTable(
name = "user_role", // 定义中间表的名称
joinColumns = {@JoinColumn(name = "user_id", referencedColumnName = "id")}, // 定义中间表中关联User表的外键名
inverseJoinColumns = {@JoinColumn(name = "role_id", referencedColumnName = "id")} // 定义中间表中关联role表的外键名
)
private Set roles; // 角色外键
// getter and setter...
}
/**
* 角色实体类
*/
@Entity
@Table(name = "role")
public class Role extends BaseData {
private static final long serialVersionUID = 5012235295240129244L;
private String roleName; // 角色名
private Integer roleType; // 1: 超级管理员 2: 系统管理员 3:一般用户
private Integer state; // 0禁用 1 启用
@ManyToMany(cascade = CascadeType.MERGE, fetch = FetchType.LAZY)
@JoinTable(
name = "user_role",
joinColumns = {@JoinColumn(name = "role_id", referencedColumnName = "id")},
inverseJoinColumns = {@JoinColumn(name = "user_id", referencedColumnName = "id")}
)
private Set users; // 与用户多对多
// getter and setter ...
}
/**
* 文章实体类
*/
@Entity
@Table(name = "article")
public class Article extends BaseData{
private static final long serialVersionUID = -4817984675096952797L;
@NotEmpty(message = "标题不能为空")
@Column(nullable = false, length = 50)
private String title;
@Lob // 大对象,映射 MySQL 的 Long Text 类型
@Basic(fetch = FetchType.LAZY) // 懒加载
@Column(nullable = false) // 映射为字段,值不能为空
private String content; // 文章全文内容
@ManyToOne(cascade = {CascadeType.MERGE, CascadeType.REFRESH}, optional = false)
@JoinColumn(name = "user_id") // 设置在article表中的关联字段(外键)名
private User user; // 所属用户
// getter and setter ...
}
现在我们编写查询代码来看看这样存在什么问题,在userDao中编写查询方法
List findByName(String name);
下面是UserService中的实现方法
public List findByName(String name) {
List users = userDao.findByName(name);
return users;
}
在编写UserController
@GetMapping("/findByName/{name}")
public ResultMapper findByName(@PathVariable String name) {
List users = userService.findByName(name);
return ResultMapperUtil.success(users);
}
最后在浏览器输入http://localhost:8080/user/findByName/along 发起查询请求。
虽然查询出了结果,但是结果集非常巨大,并且控制台会报两个异常,分别是IllegalStateException和StackOverflowError,第一个是无效状态异常,重点是第二个异常,栈溢出,数据库中名字为along的用户只有几条,结果却发生了栈溢出,为什么会这样?
我们再看看打印的sql日志
Hibernate:
select
user0_.id as id1_2_,
user0_.create_time as create_t2_2_,
user0_.update_time as update_t3_2_,
user0_.birthday as birthday4_2_,
user0_.email as email5_2_,
user0_.name as name6_2_,
user0_.password as password7_2_,
user0_.sex as sex8_2_,
user0_.status as status9_2_
from
user user0_ where user0_.name=?
Hibernate:
select
articlelis0_.user_id as user_id6_0_0_,
articlelis0_.id as id1_0_0_,
articlelis0_.id as id1_0_1_,
articlelis0_.create_time as create_t2_0_1_,
articlelis0_.update_time as update_t3_0_1_,
articlelis0_.content as content4_0_1_,
articlelis0_.title as title5_0_1_,
articlelis0_.user_id as user_id6_0_1_
from
article articlelis0_
where
articlelis0_.user_id=?
共打印了两条sql,第一条sql正是我们所希望的,根据name查询user,由于user关联了article,jpa于是再发起sql,去查询article,又由于article中又关联着user,于是又会再查一遍user,如此循环反复,根本停不下来,很快就栈溢出了。
按这样说,你可能还会有疑问,这样的话不是应该打印3条sql吗?应该该有一条sql去查询role,为什么只有两条呢?原因是第二条sql查询article时就已经进入了死循环并报了异常,所以也就不会再发起第三条sql去查询role了。
解决方案一:使用@JsonIgnore注解
@JsonIgnore是Jackson提供的注解,在实体类的属性上加上该注解,这样在json序列化时会将java bean中的对应的属性忽略掉,同样jpa在查询时也会忽略对应的属性,如此便可以解决循环查询的问题。
@JsonIgnore的使用十分灵活,你可以只在User中使用,这样在查询User时结果集中就不会包含添加了改注解的属性,你也可以只在Role和Article实体中与User关联的属性上加@JsonIgnore,这样在查询User时还是会关联查询Role和Article,但是不会发生循环查询。
这里只在User中加上@JsonIgnore注解,改造后的User类代码如下
/**
* 用户实体类
*/
@Entity
@Table(name = "user") //对应数据库中的表名
public class User extends BaseData {
private static final long serialVersionUID = -5103936306962248929L;
private String name;
private String password;
private Integer sex; // 1:男;0:女
private Integer status = 1; //-1:删除;0 禁用 1启用
private String email;
@Temporal(TemporalType.DATE)
@JsonFormat(pattern = "yyyy-MM-dd")
private Date birthday;
@JsonIgnore
@OneToMany(mappedBy = "user", cascade = CascadeType.ALL, fetch = FetchType.LAZY)
private List articleList; // 文章
@JsonIgnore
@ManyToMany(cascade = CascadeType.MERGE, fetch = FetchType.LAZY)
@JoinTable(
name = "user_role", // 定义中间表的名称
joinColumns = {@JoinColumn(name = "user_id", referencedColumnName = "id")}, // 定义中间表中关联User表的外键名
inverseJoinColumns = {@JoinColumn(name = "role_id", referencedColumnName = "id")} // 定义中间表中关联role表的外键名
)
private Set roles; // 角色外键
// getter and setter...
}
再次查询,成功查询出结果,结果中不包含article和role,控制台也只打印出了一条查询user的sql。
解决方案二:使用@JsonIgnoreProperties注解
同样是Jackson提供的注解,@JsonIgnoreProperties和@JsonIgnore用法差不多,@JsonIgnoreProperties可以更加细粒度的选择忽略关联实体中的属性。也就是说如果你需要关联查询,但是又想控制关联查询的类的属性,那么可以使用该注解。
改造后的User类如下
/**
* 用户实体类
*/
@Entity
@Table(name = "user") //对应数据库中的表名
public class User extends BaseData {
private static final long serialVersionUID = -5103936306962248929L;
private String name;
private String password;
private Integer sex; // 1:男;0:女
private Integer status = 1; //-1:删除;0 禁用 1启用
private String email;
@Temporal(TemporalType.DATE)
@JsonFormat(pattern = "yyyy-MM-dd")
private Date birthday;
@JsonIgnoreProperties(value = {"user", "content"}) //解决循环引用问题,content内容大,不加载
@OneToMany(mappedBy = "user", cascade = CascadeType.ALL, fetch = FetchType.LAZY)
private List articleList; // 文章
@JsonIgnoreProperties(value = {"users"}) //解决循环引用问题
@ManyToMany(cascade = CascadeType.MERGE, fetch = FetchType.LAZY)
@JoinTable(
name = "user_role", // 定义中间表的名称
joinColumns = {@JoinColumn(name = "user_id", referencedColumnName = "id")}, // 定义中间表中关联User表的外键名
inverseJoinColumns = {@JoinColumn(name = "role_id", referencedColumnName = "id")} // 定义中间表中关联role表的外键名
)
private Set roles; // 角色外键
// getter and setter...
}
上面我在关联属性aritcleList和roles上加上@JsonIgnoreProperties注解忽略了会引发循环引用的属性,article中的content是大文本,也将其忽略。
再次发起查询,没有发生循环查询,控制台打印的sql如下:
Hibernate: select user0_.id as id1_2_, user0_.create_time as create_t2_2_, user0_.update_time as update_t3_2_, user0_.birthday as birthday4_2_, user0_.email as email5_2_, user0_.name as name6_2_, user0_.password as password7_2_, user0_.sex as sex8_2_, user0_.status as status9_2_ from user user0_ where user0_.name=?
Hibernate: select articlelis0_.user_id as user_id6_0_0_, articlelis0_.id as id1_0_0_, articlelis0_.id as id1_0_1_, articlelis0_.create_time as create_t2_0_1_, articlelis0_.update_time as update_t3_0_1_, articlelis0_.content as content4_0_1_, articlelis0_.title as title5_0_1_, articlelis0_.user_id as user_id6_0_1_ from article articlelis0_ where articlelis0_.user_id=?
Hibernate: select roles0_.user_id as user_id2_3_0_, roles0_.role_id as role_id1_3_0_, role1_.id as id1_1_1_, role1_.create_time as create_t2_1_1_, role1_.update_time as update_t3_1_1_, role1_.role_name as role_nam4_1_1_, role1_.role_type as role_typ5_1_1_, role1_.state as state6_1_1_ from user_role roles0_ inner join role role1_ on roles0_.role_id=role1_.id where roles0_.user_id=?
共打印了3条sql,分别查询对应的三个表。
解决方案三:返回自定义包装类
上面我们的查询接口都是直接用实体类来接收查询结果并返回,但是更加规范的是创建一个Vo类来接收查询结果,Vo中的属性名跟实体类相同,这样我们可以实现不改变实体类就能决定返回结果的内容。
下面我们定义一个Vo
/**
* @Description: 返回前端的类,vo可以控制返回的字段,也是解决循环引用的一种方案
* @Author along
* @Date 2019/1/10 13:29
*/
public interface UserVo {
String getId();
String getName();
String getPassword();
Integer getSex(); // 1:男;0:女
Integer getStatus(); //-1:删除;0 禁用 1启用
String getEmail();
Date getBirthday();
//@JsonIgnoreProperties(value = {"user", "content"}) //解决循环引用问题
//List getArticleList(); // 文章列表
//@JsonIgnoreProperties(value = {"users"}) //解决循环引用问题
//Set getRoles(); // 角色外键
}
注意该 UserVo 是一个接口,里面的属性是实体类中对应属性的 get 方法。使用Vo可以灵活决定返回结果的字段。
下面我们改造userDao中的查询方法,改用UserVo来接收
List findByName(String name);
下面是UserService中的实现方法,同样改用UserVo来接收
public List findByName(String name) {
List userVos = userDao.findByName(name);
return userVos;
}
再下面是UserController接口
@GetMapping("/findByName/{name}")
public ResultMapper findByName(@PathVariable String name) {
List userVos = userService.findByName(name);
return ResultMapperUtil.success(userVos);
}
调用查询,可以实现与方案一和方案二相同的效果,使用也更加灵活简单,个人最推荐该方案。
N+1查询问题
上面虽然解决了循环引用的问题,但随后又出现一个更加头疼的问题,也是Jpa使用了表关联属性后出现的N+1查询问题,具体这是个什么现象呢,项目中会有很多的实体类,实体类之间通常又会有一对多、多对多的关联,通常我们会将多的一方设置成懒加载,这样我们在查询一个实体时只会查询出该实体的基本属性(不包括被设置为懒加载的属性),然后当我们需要关联对象的某些属性时,ORM就会再次发出sql语句查询关联的属性。这也就解释了为什么上文中查询一个user,结果却发出了三条sql语句。
数据小时不会有明显的问题,可当查询的数据量变大时,查询发出的sql数量也会非常大,会引发严重的性能问题。
如下面的例子,我们调用userDao.findAll()方法查询所有用户数据,并且设置了分页,查询20条,结果控制台打印的sql日志如下
Hibernate: select user0_.id as id1_2_, user0_.create_time as create_t2_2_, user0_.update_time as update_t3_2_, user0_.birthday as birthday4_2_, user0_.email as email5_2_, user0_.name as name6_2_, user0_.password as password7_2_, user0_.sex as sex8_2_, user0_.status as status9_2_ from user user0_ order by user0_.update_time desc, user0_.create_time desc limit ?
Hibernate: select articlelis0_.user_id as user_id6_0_0_, articlelis0_.id as id1_0_0_, articlelis0_.id as id1_0_1_, articlelis0_.create_time as create_t2_0_1_, articlelis0_.update_time as update_t3_0_1_, articlelis0_.content as content4_0_1_, articlelis0_.title as title5_0_1_, articlelis0_.user_id as user_id6_0_1_ from article articlelis0_ where articlelis0_.user_id=?
Hibernate: select roles0_.user_id as user_id2_3_0_, roles0_.role_id as role_id1_3_0_, role1_.id as id1_1_1_, role1_.create_time as create_t2_1_1_, role1_.update_time as update_t3_1_1_, role1_.role_name as role_nam4_1_1_, role1_.role_type as role_typ5_1_1_, role1_.state as state6_1_1_ from user_role roles0_ inner join role role1_ on roles0_.role_id=role1_.id where roles0_.user_id=?
Hibernate: select articlelis0_.user_id as user_id6_0_0_, articlelis0_.id as id1_0_0_, articlelis0_.id as id1_0_1_, articlelis0_.create_time as create_t2_0_1_, articlelis0_.update_time as update_t3_0_1_, articlelis0_.content as content4_0_1_, articlelis0_.title as title5_0_1_, articlelis0_.user_id as user_id6_0_1_ from article articlelis0_ where articlelis0_.user_id=?
Hibernate: select roles0_.user_id as user_id2_3_0_, roles0_.role_id as role_id1_3_0_, role1_.id as id1_1_1_, role1_.create_time as create_t2_1_1_, role1_.update_time as update_t3_1_1_, role1_.role_name as role_nam4_1_1_, role1_.role_type as role_typ5_1_1_, role1_.state as state6_1_1_ from user_role roles0_ inner join role role1_ on roles0_.role_id=role1_.id where roles0_.user_id=?
Hibernate: select articlelis0_.user_id as user_id6_0_0_, articlelis0_.id as id1_0_0_, articlelis0_.id as id1_0_1_, articlelis0_.create_time as create_t2_0_1_, articlelis0_.update_time as update_t3_0_1_, articlelis0_.content as content4_0_1_, articlelis0_.title as title5_0_1_, articlelis0_.user_id as user_id6_0_1_ from article articlelis0_ where articlelis0_.user_id=?
Hibernate: select roles0_.user_id as user_id2_3_0_, roles0_.role_id as role_id1_3_0_, role1_.id as id1_1_1_, role1_.create_time as create_t2_1_1_, role1_.update_time as update_t3_1_1_, role1_.role_name as role_nam4_1_1_, role1_.role_type as role_typ5_1_1_, role1_.state as state6_1_1_ from user_role roles0_ inner join role role1_ on roles0_.role_id=role1_.id where roles0_.user_id=?
Hibernate: select articlelis0_.user_id as user_id6_0_0_, articlelis0_.id as id1_0_0_, articlelis0_.id as id1_0_1_, articlelis0_.create_time as create_t2_0_1_, articlelis0_.update_time as update_t3_0_1_, articlelis0_.content as content4_0_1_, articlelis0_.title as title5_0_1_, articlelis0_.user_id as user_id6_0_1_ from article articlelis0_ where articlelis0_.user_id=?
Hibernate: select roles0_.user_id as user_id2_3_0_, roles0_.role_id as role_id1_3_0_, role1_.id as id1_1_1_, role1_.create_time as create_t2_1_1_, role1_.update_time as update_t3_1_1_, role1_.role_name as role_nam4_1_1_, role1_.role_type as role_typ5_1_1_, role1_.state as state6_1_1_ from user_role roles0_ inner join role role1_ on roles0_.role_id=role1_.id where roles0_.user_id=?
Hibernate: select articlelis0_.user_id as user_id6_0_0_, articlelis0_.id as id1_0_0_, articlelis0_.id as id1_0_1_, articlelis0_.create_time as create_t2_0_1_, articlelis0_.update_time as update_t3_0_1_, articlelis0_.content as content4_0_1_, articlelis0_.title as title5_0_1_, articlelis0_.user_id as user_id6_0_1_ from article articlelis0_ where articlelis0_.user_id=?
Hibernate: select roles0_.user_id as user_id2_3_0_, roles0_.role_id as role_id1_3_0_, role1_.id as id1_1_1_, role1_.create_time as create_t2_1_1_, role1_.update_time as update_t3_1_1_, role1_.role_name as role_nam4_1_1_, role1_.role_type as role_typ5_1_1_, role1_.state as state6_1_1_ from user_role roles0_ inner join role role1_ on roles0_.role_id=role1_.id where roles0_.user_id=?
Hibernate: select articlelis0_.user_id as user_id6_0_0_, articlelis0_.id as id1_0_0_, articlelis0_.id as id1_0_1_, articlelis0_.create_time as create_t2_0_1_, articlelis0_.update_time as update_t3_0_1_, articlelis0_.content as content4_0_1_, articlelis0_.title as title5_0_1_, articlelis0_.user_id as user_id6_0_1_ from article articlelis0_ where articlelis0_.user_id=?
Hibernate: select roles0_.user_id as user_id2_3_0_, roles0_.role_id as role_id1_3_0_, role1_.id as id1_1_1_, role1_.create_time as create_t2_1_1_, role1_.update_time as update_t3_1_1_, role1_.role_name as role_nam4_1_1_, role1_.role_type as role_typ5_1_1_, role1_.state as state6_1_1_ from user_role roles0_ inner join role role1_ on roles0_.role_id=role1_.id where roles0_.user_id=?
Hibernate: select articlelis0_.user_id as user_id6_0_0_, articlelis0_.id as id1_0_0_, articlelis0_.id as id1_0_1_, articlelis0_.create_time as create_t2_0_1_, articlelis0_.update_time as update_t3_0_1_, articlelis0_.content as content4_0_1_, articlelis0_.title as title5_0_1_, articlelis0_.user_id as user_id6_0_1_ from article articlelis0_ where articlelis0_.user_id=?
Hibernate: select roles0_.user_id as user_id2_3_0_, roles0_.role_id as role_id1_3_0_, role1_.id as id1_1_1_, role1_.create_time as create_t2_1_1_, role1_.update_time as update_t3_1_1_, role1_.role_name as role_nam4_1_1_, role1_.role_type as role_typ5_1_1_, role1_.state as state6_1_1_ from user_role roles0_ inner join role role1_ on roles0_.role_id=role1_.id where roles0_.user_id=?
虽然只用分页控制了结果集,但是sql的量还是非常大的。
JPA2.1提供了新的特性来解决N+1查询的问题,就是实体图(EntityGraph),由于实体间的关系错综复杂,如果实体间存在关系那么就用线将实体进行连接,那么实体间将形成一个网状的图,而实体图技术就是对这个关系图的操作,它允许开发者指定某个实体及其发展出来的关系网中的某些节点,这些节点间形成一条路径,当调用查询方法时,查询方法会按照实体图中的路径将路径中的这些节点立即加载,而绕过延迟加载,从而更高效的实现数据的检索。
下面是实体图的应用,我们在User表上使用@NamedEntityGraphs注解定义实体图,你可以定义多个实体图,如下
/**
* 用户实体类
*/
@Entity
@Table(name = "user") //对应数据库中的表名
//EntityGraph(实体图)使用演示,解决查询N+1问题
@NamedEntityGraphs({
@NamedEntityGraph(name = "user.all",
attributeNodes = { // attributeNodes 用来定义需要立即加载的属性
@NamedAttributeNode("articleList"), // 无延伸
@NamedAttributeNode("roles"), // 无延伸
}
),
})
public class User extends BaseData {
...
}
@NamedEntityGraph代表着一个实体图,通过name属性设置实体图的名字,通过attributeNodes属性来定义需要立即加载的属性,如果role还关联了另外一张表,并且设置为了懒加载,那如果想要立即加载改表,就通过subgraphs属性来进行描述,下面是在Role实体中定义的实体图
@Entity
@Table(name = "role")
// EntityGraph(实体图)使用演示,解决查询N+1问题
@NamedEntityGraphs({
@NamedEntityGraph(name = "role.all",
attributeNodes = { // attributeNodes 用来指定要立即加载的节点,节点用 @NamedAttributeNode 定义
@NamedAttributeNode(value = "users", subgraph = "userWithArticleList"), // 要立即加载users属性中的articleList元素
},
subgraphs = { // subgraphs 用来定义关联对象的属性,也就是对上面的 userWithArticleList 进行描述
@NamedSubgraph(name = "userWithArticleList", attributeNodes = @NamedAttributeNode("articleList")), // 一层延伸
}
),
})
public class Role extends BaseData {
...
}
光是定义了实体图还不够,我们需要在查询时指定使用哪一个实体图进行查询,如下,重写findAll()方法,使用@EntityGraph注解指定通过名为user.all的实体图查询
public interface UserDao extends JpaRepository, JpaSpecificationExecutor {
//重写findAll(Pageable pageable)方法,用实体图查询
@EntityGraph(value = "user.all", type = EntityGraph.EntityGraphType.FETCH)
@Override
Page findAll(Pageable pageable);
}
执行查询,打印出的sql日志如下,为了方便阅读将其格式化输出
Hibernate:
select
user0_.id as id1_2_0_,
articlelis1_.id as id1_0_1_,
role3_.id as id1_1_2_,
user0_.create_time as create_t2_2_0_,
user0_.update_time as update_t3_2_0_,
user0_.birthday as birthday4_2_0_,
user0_.email as email5_2_0_,
user0_.name as name6_2_0_,
user0_.password as password7_2_0_,
user0_.sex as sex8_2_0_,
user0_.status as status9_2_0_,
articlelis1_.create_time as create_t2_0_1_,
articlelis1_.update_time as update_t3_0_1_,
articlelis1_.content as content4_0_1_,
articlelis1_.title as title5_0_1_,
articlelis1_.user_id as user_id6_0_1_,
articlelis1_.user_id as user_id6_0_0__,
articlelis1_.id as id1_0_0__,
role3_.create_time as create_t2_1_2_,
role3_.update_time as update_t3_1_2_,
role3_.role_name as role_nam4_1_2_,
role3_.role_type as role_typ5_1_2_,
role3_.state as state6_1_2_,
roles2_.user_id as user_id2_3_1__,
roles2_.role_id as role_id1_3_1__
from user user0_
left outer join
article articlelis1_
on
user0_.id=articlelis1_.user_id
left outer join
user_role roles2_
on
user0_.id=roles2_.user_id
left outer join
role role3_
on
roles2_.role_id=role3_.id
order by
user0_.update_time desc, user0_.create_time desc
可以看到只打印了一条sql语句。
本文相关源码地址
https://github.com/alonglong/spring-boot-all/tree/master/spring-boot-jpa