__ getattr __ 和 __ getattribute __ 魔法函数
- __ getattr __ :是当传入的值不存在的时候才会调用getattr魔法方法,传入的值item就是你这个不存在的值
class User(object):
def __init__(self, name, info):
self.name = name
self.info = info
def __getattr__(self, item):
return self.info[item]
u = User('zhangsan', {'age': 18})
print(u.age)
-
__ getattribute __:无条件优先执行,所以不是特殊请款不要使用 __ getattribute __
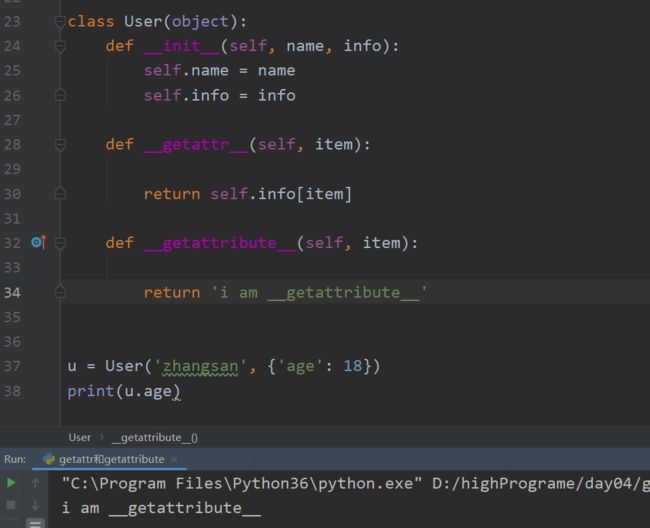 image.png
image.png
属性描述符
介绍
属性描述符是一个通用协议。他是properties、class methods、static methods、super()的调用原理
属性描述符协议
属性描述符是实现特定类的协议,只要实现了 __ set __ __ get __ __ delete __其中一个就是属性描述符,他能实现对多个属性运用相同的存取逻辑的方式,简而言之一个类的实例是另一个类的属性
- 注意
- 一个类中定义了__ set __ 和 __ get __ 方法称作数据描述符
- 一个类中只定义了 __ get __ 方法称作非数据描述符
使用类方法创建描述符
- 定义一个IntField类为描述符类
- 创建IntField类的实例,作为另一个User类的属性
class IntField(object):
def __set__(self, instance, value):
print('i am set')
def __get__(self, instance, owner):
print('i am get')
class User(object):
IF = IntField()
u = User()
u.age = 30
print(u.age)
使用属性类型创建描述符
除了使用类方法创建属性描述符,我们还可以使用属性类型property()创建描述符。语法是property(fget = None, fset = None, fdel = None, doc = None)
描述符查找顺序
- 当为数据描述符时,get优先级高于dict
- 当为非数据描述符时,dict优先级高于get
元类
元类介绍
元类实际上是创建类的类
实现如下:
- 定义创建类的函数create_class
- 如果传入的是user就创建User类
type()创建元类
- 第一个参数:name表示类名,字符串类型
- 第二个参数:bases表示继承对象,元组类型
- 第三个参数:attr表示属性,可以是类属性、类方法、静态方法,字典格式
def __init__(self, name):
self.name = name
User = type('User', (), {'age':18, '__init__':__init__})
obj = User('zhangsan')
print(obj.name)
metaclass属性
- 如果一个类中定义了 __ metaclass __ = xxx 属性,Python就会用元类的方式创建类,控制类的创建行为
例如已下代码,在不改变类属性书写情况下,将属性名规定大写访问
class Myclass(object):
name = 'ls'
mc = Myclass()
print(mc.name)
# 2.创建upper_attr函数
def upper_attr(cls_name, cls_parents, cls_attr):
# print(cls_name) # MyClass
# print(cls_parents) # (,)
# print(cls_attr) # {'__module__': '__main__', '__qualname__': 'MyClass', 'name': 'ls'}
"""
4.将属性名规定为大写访问
- 遍历取出属性
- 如果属性是非_开头的
- 将其转为大写
"""
new_attr = {}
for name, value in cls_attr.items():
# print(name)
# print(value)
if not name.startswith("_"):
new_attr[name.upper()] = value.upper()
# 5.返回type创建的类
return type(cls_name, cls_parents, new_attr)
# # 3.返回type创建的类
# return type(cls_name, cls_parents, cls_attr)
# 1.创建MyClass类,指定metaclass=upper_attr
class MyClass(object, metaclass=upper_attr):
name = "ls"
mc = MyClass()
print(mc.NAME)
Python迭代器
迭代器是指迭代取值的工具,迭代是一个重复的过程,每一个重复都是基于上一次结果而来,迭代提供了一种通用的不依赖索引的迭代取值方式
可迭代对象
可以用for循环遍历的都是可迭代对象
- str list tuple dict set都是可迭代对象
- generator,生成器包括带yield的生成器函数
判断是否可以迭代
除了看内置是否含有 __ iter __方法来判断该对象是否是一个可迭代对象以外,还可以用isinstance()判断一个对象是否是iterable对象
from collections import Iterable,Iterator
print(isinstance('abc',Iterable)) # True
print(isinstance([1,2,3,4],Iterable)) # True
print(isinstance(123,Iterable)) # False
迭代器对象
- 有内置的 __ next __()方法的对象,执行该方法可以不依赖索引取值
- 有内置的 __ iter __()方法的对象,执行该方法得到的仍是迭代器对象
需要注意的是可迭代对象,不一定是迭代器
iter()
- 可以被next()调用,并不断返回下一个值的对象叫做迭代器:Iterator
那我们可以通过iter方法将可迭代对象转换成迭代器
li = [1,2,3,4]
lis = iter(li)
print(type(lis)) #
注意迭代器不可以用下表取值,而是使用__ next __()或者next()超出范围就会报错
可迭代对象与迭代器的区别
- 可用于for循环的都是可迭代对象
- 作用于next()都是迭代器类型
- str list dict等都是可迭代的但不是迭代器,因为next()函数无法调用他们。可以通过iter()函数将他们转换为迭代器
- python的for循环本质就是不断的调用next()函数实现的
生成器
定义
在Python中一边循环一边计算的机制称为生成器:generator
为什么要有生成器
列表中所有数据都在内存中,如果有海量数据就会占用非常多的内存,如果我们只需要前几个元素,如果将所有元素都掉出来就会非常消耗内存
生成器就是在循环过程中根据算法不断推算后面的元素,这样不用创建整个完整的列表,比较节省空间。
总而言之,如果我们想要使用庞大的数据,又要节省空间,就可以使用生成器。
如何创建生成器
生成器表达式
生成器表达式来自于迭代器和列表解析的结合,生成器和列表解析类似,但是它使用()而不是[]
g = (x for x in range(5))
print(g) # generator object
print(next(g))
print(next(g))
print(next(g))
print(next(g))
print(next(g))
# 超出报错
print(next(g))
for i in g:
print(i)
生成器函数
当一个函数中包含yield关键字,那么这个函数就是一个generator。调用函数就是创建一个生成器对象。其工作原理就是重复调用next()或者 __ next __(),直到捕获一个异常
比如:
实现斐波那契数列,除第一个和第二个数外,任何一个数都可以由前两个相加得到:
1,1,2,3,5,8,12,21,34.....
def createNums():
print("-----func start-----")
a,b = 0,1
for i in range(5):
# print(b)
print("--1--")
yield b
print("--2--")
a,b = b,a+b
print("--3--")
print("-----func end-----")
g = createNums()
print(next(g))
print(next(g))
print(next(g))
print(next(g))
print(next(g))
迭代器与生成器
- 生成器能做到迭代器能做的所有事
- 而且因为生成器自动创建了iter()和next()方法,生成器显得简洁,而且高效。
读取大文件,文件300G,一行分隔符{|}
def readlines(f,newline):
buf = ""
while True:
while newline in buf:
pos = buf.index(newline)
yield buf[:pos]
buf = buf[pos + len(newline):]
chunk = f.read(4096*10)
if not chunk:
yield buf
break
buf += chunk
with open('demo.txt') as f:
for line in readlines(f,"{|}"):
print(line)