老年人记忆力了, 刷过的题也不会了。 所以再来一遍, 顺便记录一下。
- (279). Perfect Squares. 第一眼看上去像找规律, 写了下感觉会有数学规律, 不过看上去很像一个递归问题。 考虑用dp解决,问题:找出最少的平方数使得和为N,可以变为将(一次操作为,选择所有比它小的平方值)【1. 抽象出问题的状态, 2.总结一次能做的操作,3. 考虑通过一次操作能否将问题变成子问题? 4. 如果不够明显,考虑这个问题是否能由一系列决策得到问题的解。5.接四,通过决策 利用操作将问题由子问题表示】。
- (114). Flatten Binary Tree to Linked List. 一眼看上去像是递归, 定义一个递归方法为 helper(node)返回为尾node,然后递归解决就可以了, 不过要注意下递归结束条件(和边界条件)。
- (11). Container With Most Water. 这题已凉, 而且感觉还是二凉。 第一眼看上去像DP,看半天发现貌似没什么递归的样子。看了TIPS发现是TWO POINTER,其实感觉是个GREEDY。 考虑任意两点, 它们的面积为S, 如果左>右, 显然 右边所有比该点小的值都不可能考虑了, 如果左<右, 同理。 这样的话, 让l, r 分别从左右两个端点开始往里收缩, 只要o(n)就能得到解了, 我好菜。
- (207). Course Schedule. 考察图中有无环, DFS和BFS懒得想了。直接考虑DAG比较简单, 记录每个点 对应的 边, 记录每个点的入度。 用一个队列来记录入度为0的所有点, 不断将点对应的边删去,如果导致边对应点的入度为0则加入队列。当队列为空时,说明已经没有能删去的先导了,此时遍历所有的点的入度,如果还有不为0的,说明形成环啦。
- (SQL)197. Rising Temperature. 这题不难, 不过考察到一个逻辑点, 时间相隔一天在SQL中如何表示呢? 可以直接相减吗? 不行! 比如 1999-01-01 和 1998-12-31 两个是差一天, 但是直接相减会变成INT比较,显然不对。 那么在sql中可以通过2种方式。
- to_days(W1.RecordDate)-to_days(W2.RecordDate)=1【to_days给出一个日期date,返回一个天数(从0年的天数)。】
- W1.recorddate = W2.recorddate + INTERVAL 1 DAY 【INTERVAL 1 DAY 表示MYSQL中的一天,是固定搭配 INTERVAL EXPR TYPE】
- W1.recorddate=DATE_ADD(W2.recorddate,INTERVAL 1 DAY)
- (SQL) 196. Delete Duplicate Emails. 删除一个表中重复的EMAIL记录(删ID大的)
- DELETE p2 FROM Person p1, Person p2 WHERE p1.Email = p2.Email AND p1.Id < p2.Id(FROM后面接的是多表查询然后把要删的结果返回给DELETE)
- DELETE FROM Person WHERE Id in (SELECT a.id FROM (SELECT p1.id FROM Person p1, Person p2 WHERE p1.Id > p2.Id and p1.Email = p2.Email) a) 【直接在表里删除, 注意DELETE的FROM子句里 表和 子查询不能是同一张表】
- (SQL) 176. Second Highest Salary. 烦,这题都没做出来。 找第二大的数, select max(number) from table where number < (select max(number) from table)
- (SQL) 626. Exchange Seats 要求奇数的行和偶数行的ID互换,如果是奇数个记录,最后一行不变。 我的想法是利用case when,把奇数和偶数行+1 -1,这个作为一个过滤结果,再进行一次过滤 将最大的数-1并且排序。 答案区利用Union(
)利用if
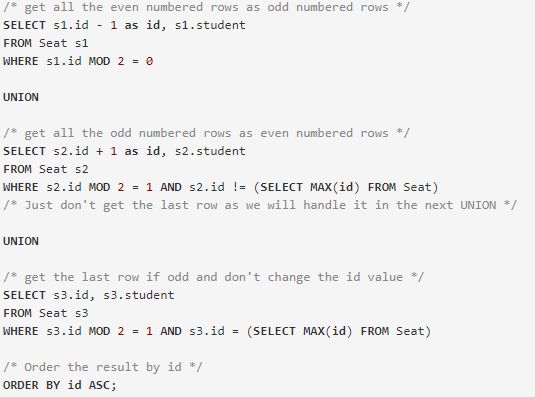 union和我类似的if想法
union和我类似的if想法 if
if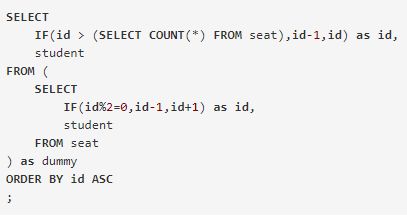 if2
if2 - (SQL) 178. Rank Scores 把一个表按score排序,思路:一个变量从1开始一直往上涨、先找出逆序score表,然后对其加变量,最后join表打印。
 178
178,涉及到的一些盲区(用@id:=来给变量赋值,赋值位置应处于第一次使用的from处,参考sql执行过程【from->on->join->where->groupby->having->select->distinct->orderby->limit】)
- (139)Word Break 整体word break =》 是否有一个尾巴在word dict 中 , 使得 前面一部分word break成立=》 在word dict中确立尾巴,前面一部分成立? or 前面一部分成立, 尾巴在word dict中?
- (SQL)180. Consecutive Numbers 朴素想法没什么难度, 非朴素不想想了, 有一个注意点是 多次用到同一张表,一定要起别名,别偷懒, 不然莫名奇妙就not work了。【1, 三表连接, 条件是 a.id = b.id+1 , b.id = c.id+1,a.num=b.num=c.num,然后distinct a.num。 2, 单表遍历 满足条件 id 不是最后2个, num 和后两个都相等】
- (33)Search in Rotated Sorted Array 是该好好归纳一下二分了, 先二分出起点, 然后根据值所在的区域, 二分某一边。
- (34)Find First and Last Position of Element in Sorted Array 还是二分哦, 思路是先二分出最左边的索引,然后二分出最右边的索引, 咋二分呢?想啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊(二分的时候判断一下左/右是否为target).
- (SQL)184. Department Highest Salary 找每个部门salary最多的 人和部门信息,简单啦,天天做, 其实就是先找出每个部门最多的钱, 连接上人, 然后再连接上部门信息。
- (148)Sort List。写起来是真的醉。 主要思路 数组和 链表都一样,细节注意一下, 链表递归版本, 是得截断 成两个链表, 然后再递归。非递归版本,各自有各自的实现细节, 写起来很蛋疼, 反正就是自底向上的合并合并合并, 从合并长度为1开始,合并长度 >= 链表长度时候结束。合并的过程涉及到截断为两个list,然后再放回去balabala...实在太麻烦了懒得写了,这辈子都不想写了。(总之就是模拟合并的过程呗)
- (SQL)601. Human Traffic of Stadium 查找连续3个及以上people超过100的记录。 实际上等价于 对每个记录进行判断, 如果(自己及后两超过100 、 自己及前后超过100、 自己及前两超过100)则满足。三表连接,需要去重~【小结论:需要对每个进行前后比较的, 还是多表连接把。】
- (SQL)185. Department Top Three Salaries 寻找每个部门中前3薪资的人。 对employee每个记录进行判断(当前部门超过它薪资的人数<3)成立,则筛出来, 然后跟部门连接即可。【每个部门 第一个想法是group by , 然而除非是要聚合, 否则没软用,还是子查询把。】
- (236)Lowest Common Ancestor of a Binary Tree 以前写的遍历出两个串,然后比较, 还有判断点在左右,然后递归,都是啥玩意= =?正解:其实也是递归,但是人家巧妙! 递归定义 func ,返回的是lca。如果不存在返回null, 如果根为p或q返回根。func(root, p, q) -> left = func(root.left, p, q), right = func(root.right, p, q) 如果 left 和 right 都不为null ,显然p,q在两边(可能左右同时有p,q吗?)。否则,必然左右有一个为null,返回另外一个。
- (SQL)262. Trips and Users 寻找某个日期区间的订单取消率, 有思路就好写。 最后要做的实际就是聚合操作, 根据题意先过滤无用信息、然后group by,最后利用条件语句进行聚合。
- (55)Jump Game 起始在index 0, 一个array包含int值(表示最大能跳的步数), 问你能否跳到index last。我自己的思路啊~判断某一个地方能否到达尾巴, 关键之处就在判断这个点的值 是否大于它后面连续不可达尾巴的个数。(贪心)
- (2)Add Two Numbers 链表相加, 这题证明了 对于一个模拟题来说, 先动手, 不如先动脑。 把问题想清楚了再动手!先把两个链表加起来, 再从尾巴一直推到最后一个(最后一个不能推, 因为这样就null了),然后根据进位是否大于等于0(初始为0,这是某个边界), 在里面进行推,根据进位是否大于0,判断是否继续,关键还是边界。
- (221)Maximal Square
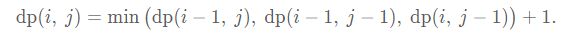 DP转移
DP转移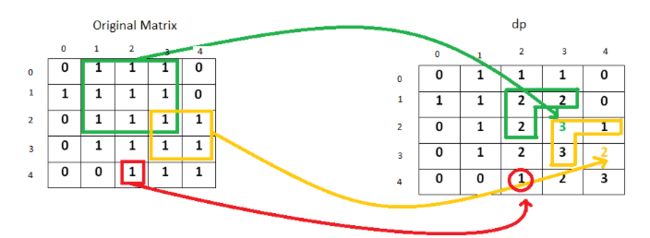 过程图
过程图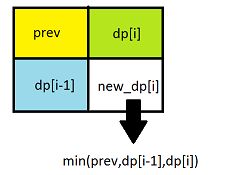 降维
降维这题凭感觉蒙, 另dp[i][j]为 以i,j为结尾的最大square边数, 能递推得到转移方程。至于为啥会那么想, 其实就是试吧。因为跟状态有关的就是某个位置,这样。至于降维,不是很懂, 大概意思就是说, 原本取决于(i-1,j)(i,j-1)(i-1,j-1)那么实际上如果只有一维,因为在第i层迭代, 那么(i-1,j)相当于dp[j]、(i,j-1)相当于dp[j-1]、(i-1,j-1)相当于未修改的dp[j-1]。改天再理解吧。
- (142)Linked List Cycle II. 判断一个链表是否有环, 及其环点。一个一次走一步,一个一次走两步,假设相遇点为x,画个图一目了然。
- (152)Maximum Product Subarray. 求数组中连续乘积最大值 。 DP问题哈 ,首先 连续, 一般前后关系。 凭感觉, 应该定义dp[i]为以i为结尾的最大值, 然后求所有位置的最大为最大。 关键就是 ~ 如何定义递归关系了。数有正有负嘛, 那假设我要得到当前结尾的最大值, 如果是正数, 那就得知道前面的最大值, 如果是负数, 就得得到前面的最小值, 那就引申出另一个问题。最小值如何得到, 其实和最大值一样,是另外一个递归关系, 可以同时得到, 问题FIX。
- (98) Validate Binary Search Tree. 判断一棵树是不是二叉搜索树。写一个递归, 不过得思考下状态。 根据定义, 一棵树是二叉搜索树的等价说法是 对于任何一个节点, 大于其左子树的任何节点值,小于...。用递归的定义说法就是, 根大于左子树的任何节点,小于右子树的任何节点, 左右子树也满足。 这样其实没啥搞头。换种思路, 假设一颗树是二叉搜索树=》 dfs( root, left, right) left,right是树的上下界。 那么dfs(root, left, right) = root(fix) && dfs(root.left,..) && dfs(root.right,..)。