CUDA中的头文件
#include "cuda_runtime.h" //提供了时间计算的功能函数
#include "device_launch_parameters.h"
#include "device_functions.h"
#include
#include
#include
#include
CUDA中的函数(存储管理函数)
存储管理函数
cudaMalloc((void**)&dev_Ptr, size_t size)
cudaMalloc( )是用来分配内存的,这个函数调用的行为非常类似于标准C函数malloc( ),
但该函数的作用是告诉CUDA运行时在设备上分配内存。
第一个参数是一个指针,指向用于保存新分配内存地址的变量;
第二个参数是分配内存的大小。
除了分配内存的指针不是作为函数的返回值外,这个函数的行为与malloc( )是相同的,并且返回类型为void*。
要求:
可以将cudaMalloc( )分配的指针传递给在设备上执行的函数;
可以在设备代码中使用cudaMalloc( )分配的指针进行内存读/写操作;
可以将cudaMalloc( )分配的指针传递给在主机上执行的函数;
不能在主机代码中使用cudaMalloc( )分配的指针进行内存读/写操作。
存储管理函数
cudaFree(void* dev_Ptr)
cudaFree( )用来释放cudaMalloc( )分配的内存,这个函数的行为和free( )的行为非常类似。
CUDA中的函数(数据传输函数)
数据传输函数
cudaMemcpy(void* dst , const void* src , size_t size , cudaMemcpyDeviceToHost)
如果想要实现主机和设备之间的互相访问,则必须通过cudaMemcpy( )函数来进行数据的传输。
这个函数的调用行为类似于标准C中的memcpy(),只不过多了一个参数来指定设备内存指针究竟是源指针还是目标指针。
cudaMemcpy( )的最后一个参数可以为:cudaMemcpyDeviceToHost,
这个参数将告诉运行时源指针是一个设备指针,而目标指针是一个主机指针。
cudaMemcpyHostToDevice——将告诉运行时源指针位于主机上,而目标指针是位于设备上的。
CUDA程序中的同步函数__syncthreads()
CUDA程序中的同步
利用共享内存想要真正实现线程之间的通信,还需要一种机制来实现线程之间的同步。
例如,如果线程A将一个值写入到共享内存中,并且我们希望线程B对这个值进行一些操作,那么只有当线程A的写入
操作完成之后,线程B才能执行它的操作。如果没有同步,那么将会发生竞态条件(Race Condition),在这种情况下,
代码执行结果的正确性将取决于硬件的不确定性。
__syncthreads()这个函数调用将确保线程块中的每个线程都执行完__syncthreads()前面的语句后,才会执行下一条
语句。
最常用的同步函数__syncthreads()
同步函数__syncthreads()功能:等待block内的所有线程执行完前面的指令,到达后继续执行,一般用来保证block
内共享存储数据的一致性。
__syncthreads( ):维持block内共享存储数据的一致性;
栅栏同步__threadfence( ): 维持block内共享存储和全局存储数据的一致性.
CUDA中的Wrap
GPU线程执行时以warp为单位进行调度,每个warp(32个线程)执行同一条指令,存在着硬件同步机制,无须再调用
__syncthreads( )函数进行同步。
同步操作可以实现共享的存储单元的数据交互,其作用对象是warp而非具体的thread。
GPU仅支持block中的所有warp同步。
CUDA中的核函数Kernel
核函数只能在主机端调用,调用时必须申明执行参数。调用形式如下:
Kernel<<>>(paramlist);
• <<< >>>内是核函数的执行参数,告诉编译器运行时如何启动核函数,用于说明内核函数中的线程数量,以及线程是
如何组织的。
• 参数Dg用于定义整个grid的维度和尺寸,即一个grid有多少个block, 为dim3类型
Dim3 Dg(Dg.x, Dg.y, 1)表示grid中每行有Dg.x个block,每列有Dg.y个block,第三维一般为1.
(目前一个核函数对应一个grid), 这样整个grid中共有Dg.x*Dg.y个block。
• 参数Db用于定义一个block的维度和尺寸,即一个block有多少个thread,为dim3类型。
Dim3 Db(Db.x, Db.y, Db.z)表示整个block中每行有Db.x个thread,每列有Db.y个thread,高度为Db.z。
Db.x 和 Db.y最大值为1024,Db.z最大值为64。一个block中共有Db.x*Db.y*Db.z个thread。
• 参数Ns是一个可选参数,用于设置每个block除了静态分配的shared Memory以外,最多能动态分配的shared memory
大小,单位为byte。不需要动态分配时该值为0或省略不写。
• 参数S是一个cudaStream_t类型的可选参数,初始值为零,表示该核函数处在哪个流之中。
CUDA中的thread
CUDA不仅提供了Thread,还提供了Grid和Block以及Share Memory这些非常重要的机制,每个block中Thread极限是1024,但是通过block和Grid,线程的数量还能成倍增长,甚至用几万个线程。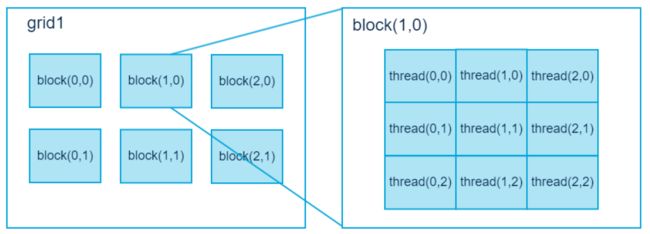
• 在CUDA 架构下,执行时的最小单位是thread。若干个thread 可以组成一个block。一个block 中的thread 能存取同一块共享内存,而且可以快速进行同步的动作。
• 每一个block 所能包含的thread 数目是有限的。不过,执行相同程序的block,可以组成grid。
• 不同block 中的thread 无法存取同一个共享内存,因此无法直接互通或进行同步。因此,不同block 中的thread 能合作的程度是比较低的。
• 利用这个模式,可以让程序员不用担心显示芯片实际上能同时执行的thread 数目的限制。
• 例如,一个具有很少量执行单元的显示芯片,可能会把各个block 中的thread 顺序执行,而非同时执行。
• 不同的grid 可以执行不同的kernel函数。
• 每个thread 都有自己的一份register 和local memory 的空间。同一个block 中的每个thread 则有共享的一份share memory。此外,所有的thread(包括不同block 的thread)都共享一份global memory、constant memory、和texture memory。线程数量多,每个线程的资源少。
• 不同的 grid 则有各自的global memory、constant memory 和texture memory。
• 不同的block之间是无法进行同步工作的。在求立方和程序中,其实不太需要进行thread 的同步动作,因此可以使用多个 block 来进一步增加thread 的数目
CUDA中的函数
cudaGetDeviceCount 返回具有计算能力的设备的数量
函数原型:
cudaError_t cudaGetDeviceCount( int* count )
以 *count 形式返回可用于执行的计算能力大于等于 1.0 的设备数量。如果不存在此类设备,将返回 1
cudaGetDeviceProperties 返回关于计算设备的信息
函数原型:cudaError_t cudaGetDeviceProperties( struct cudaDeviceProp* prop,int dev )
以*prop形式返回设备dev的属性。
cudaSetDevice 设置设备以供GPU执行使用。
函数原型:
cudaError_t cudaSetDevice(int dev)
将dev记录为活动主线程将执行设备码的设备。
配置好编写CUDA C代码的开发环境
- 支持CUDA的图形处理器;
- NVIDIV设备驱动程序;
- CUDA开发工具箱;
- 标准C编译器。
CUDA中并行模块
- CUDA程序中是指定了多个并行线程块来执行函数kernel.
比如,有很多点,但每个点都需要进行一个公式的计算,此时,每个点的计算又是独立的,因此可以为每个需要计算的点执行函数的副本,也就是用多个并行线程块来执行。又比如,在进行矢量加法的时候,也就是[a1,a2,......an]+[b1,b2.......bn],对应位置上的数值相加,是为每个元素都启动一个线程块block的,此时每个线程块block是对应一个线程thread的。- 如何利用线程(threads)来编程呢,对于上述矢量加法的案例,如果用N个线程块,每个线程块一个线程可以完成;也可以用一个线程块,这一个线程块里面含有N个线程。但是每一台电脑或者设备都有硬件上面的限制,比如每个block中threads数量最大为1024,而block的最多数量为65535.
- 使用线程的初衷就是为了解决硬件不足的问题,即线程块数量的硬件设置,动机很简单。但是共享内存也需要利用到threads。利用共享内存的时候一定要使用 __syncthreads(); 这一语句是加在写入共享内存和读入共享内存之间的一条语句,保证每个block中的threads全都操作完毕了。
总之,建议学习《GPU高性能编程CUDA实战》这本书籍,Jason Sanders Edward Kandrot 著作