title: Cache 常见问题
tags:
- cache
categories:
- Tech
comments: true
date: 2018-06-18 22:00:00
去年的时候在做系统性能优化的工作中,花费了大量的精力为业务定制化缓存方案,当时感觉尽善尽美了,但前些天不经意再聊起缓存时发现在一些细节上还欠考虑。在这里总结一下做 cache 需要考虑的问题。
大纲如下:
- 缓存模式(Cache Pattern)
- 缓存置换(Cache Replacement)
- 缓存穿透(Cache Penetration)
- 缓存雪崩(Cache Avalanche)
缓存模式/Cache Pattern
比较常见的模式有分为两大类: Cache-aside 以及 Cache-as-SoR。其中 Cache-as-SoR(System of Record, 即直接存储数据的DB) 又包括 Read-through、Write-through、Write-behind。
Cache-aside
Cache-aside 是比较通用的缓存模式,在这种模式,读数据的流程可以概括:
- 读 cache,如果 cache 存在,直接返回。如果不存在,则执行2
- 读 SoR,然后更新 cache,返回
代码如下:
# 读 v1
def get(key):
value = cache.get(key)
if value is None:
value = db.get(key)
cache.set(key, value)
return value
写数的流程为:
- 写 SoR
- 写 cache
代码如下:
# 写 v1
def set(key, value):
db.set(key, value)
cache.set(key, value)
逻辑看似很简单,但是如果在高并发的分布式场景下,其实还有很多惊喜的。
Cache-as-SoR
在 Cache-aside 模式下,cache 的维护逻辑要业务端自己实现和维护,而 Cache-as-SoR 则是将 cache 的逻辑放在存储端,即 SoR + cache 对于业务调用方而言是透明的一个整体,业务无须关心实现细节,只需 get/set 即可。Cache-as-SoR 模式常见的有 Read Through、Write Through、Write Behind。
- Read Through: 发生读操作时,查询 cache,如果 Miss,则由 cache 查询 SoR 并更新,下次访问 cache 即可直接访问(即在存储端实现 cacha-aside)
- Write Through:发生写操作时,查询 cache,如果 Hit,则更新 cache,然后交由 cache model 去更新 SoR
- Write Behind:发生写操作时,不立即更新 SoR,只更新缓存,然后立即返回,同时异步的更新 SoR(最终一致)
Read/Write Through 模式比较好理解,就是同步的更新 cache 和 SoR,读取得场景也是 cache 优先,miss 后才读 SoR。 这类模式主要意义在意缓解读操作的场景下 SoR 的压力以及提升整体响应速度,对写操作并没有什么优化,适用于读多写少的场景。Write Behind 的的 cache 和 SoR 的更新是异步,可以在异步的时候通过 batch、merge 的方式优化写操作,所以能提升写操作的性能。
下面两图是取自 wikipedia 的 Write Through 和 Write Behind 的流程图:
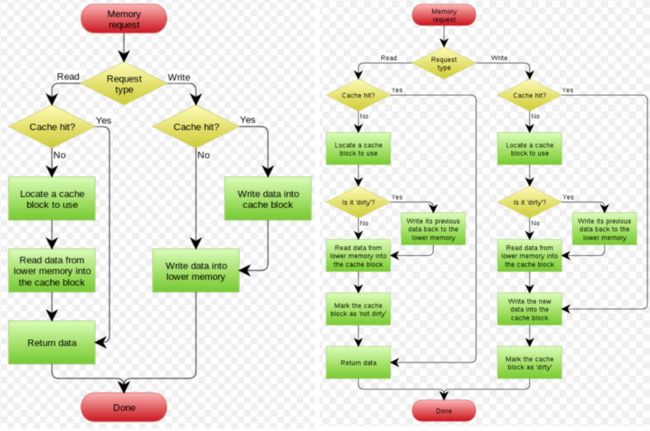
小结
当前很多 DB 都自带基于内存的 cache ,能更快的响应请求,比如 Hbase 以 Block 为单位的 cache,mongo 的高性能也一定程度依托于其占用大量的系统内存做 cache 。不过在程序本地再做一层 local cache 效果会更加明显,省去了大量的网络I/O,会使系统的处理延时大幅提升,同时降低下游 cache + db 的压力。
缓存置换/ Cache Replacement
缓存淘汰算是比较老的一个话题,常用的缓存策略也就那么几个,比如 FIFO、LFU、LRU。而且 LRU 算是缓存淘汰策略的标配了,当然在根据不同的的业务场景,也可能其他策略更合适。
FIFO 的淘汰策略通常使用 Queue + Dict, 毕竟 Queue 先天就是 FIFO 的,新的缓存对象放在队尾,而当队列满时将队首的对象出队过期。
LFU (Least Frequently Used)的核心思想是最近最少被使用的数据最先被淘汰,即统计每个对象的使用次数,当需要淘汰时,选择被使用次数最少的淘汰。所以通常基于最小堆 + Dict 实现 LFU。因为最小堆每次变化的复杂度为 O(logn),所以LFU算法效率为 O(logn),相比 FIFO、LRU O(1) 的效率略低。
LRU(Least recently Used),基于局部性原理,即如果数据最近被使用,那么它在未来也极有可能被使用,反之,如果数据很久未使用,那么未来被使用的概率也较低。
LRU 过期通常使用双端链表 + Dict
实现(在生产环境使用链表一般都是双链表),将最近被访问的数据从原位置移动到链表首部,这样在链首位置的数据都是最近被使用过的,而链尾都是最久未使用的,在 O(1) 的时间复杂度内即可找到要被删除的数据。
# LRU 缓存过期概要逻辑, 无锁版
data_dict = dict()
link = DoubleLink() # 双端队列
def get(key):
node = data_dict.get(key)
if node is not None:
link.MoveToFront(node)
return node
def add(key, value):
link.PushFront(Node(key,value))
if link.size()>max_size:
node = link.back()
del(data_dict[node.key])
link.remove_back()
Ps:
- py3 functools 中 lru_cache 的实现
- golang 实现 lru cache
缓存穿透/Penetration
当请求访问的数据是一条并不存在的数据时,一般这种不存在的数据是不会写入 cache,所以访问这种数据的请求都会直接落地到下游 SoR,当这种请求量很大时,同样会给下游 db 带来风险。
解决方法:
可以考虑适当的缓存这种数据一小段时间,将这种空数据缓存为一段特殊的值。
另一种更严谨的做法是使用 BloomFilter, BloomFilter 的特点在检测 key 是否存在时,不会漏报(BloomFilter 不存在时,一定不存在),但有可能误报(BloomFilter 存在时,有可能不存在)。Hbase 内部即使用 BloomFilter 来快速查找不存在的行。
基于 BloomFilter 的预防穿透:
# 读 v3
r = redis.StrictRedis()
def get(key, retry=3):
def _get(k):
value = cache.get(k)
if value is None:
if not Bloomfilter.get(k):
# cache miss 时先查 Bloomfilter
# Bloomfilter 需要在 Db 写时同步事务更新
return None, true
if r.set(k,1,ex=1,nx=true):
value = db.get(k)
cache.set(k, value)
return true, value
else:
return None, false
else:
return value, true
while retry:
value, flag = _get(key)
if flag == True:
return value
time.sleep(1)
retry -= 1
raise Exception("获取失败")
以上两种通用的方法对于不同的场景,各有优劣。缓存空数据的方案,在应对恶意的穿透攻击时效果会很差,因为恶意请求的一般特点是 key 随机伪造,请求量巨大,所以此时缓存空数据的方案会大量缓存无意义的数据,这些数据往往不会被二次访问,因此对恶意攻击不会产生任何效果,此时使用 bloomfilter 的方案更优。相反的,如果不存的 key 是可预估的,或者有限的的,比如是通过一定规则生成的,难以伪造,此时缓存空数据的方案较优。
缓存雪崩/Avalanches
雪崩,即在某些场景下,缓存宕机、失效、过期等等因素会导致大量的请求直接落到下游的 DB,对 DB 造成极大的压力,甚至一波打死 DB 业务挂掉。
不同场景下,导致雪崩的原因各不相同。
Case 1
在高并发场景下(比如秒杀),如果某一时间一个 key 失效了,但同时又有大量的请求访问这个 key,此时会发生大量的 cache miss,可能引发雪崩。
这种情况下比较通用的保护下游的方法是通过互斥锁访问下游 DB,获得锁的线程/进程负责读取 DB 并更新 cache,而其他 acquire lock 失败的进程则重试整个 get的逻辑。
以 redis 的 set 方法实现此逻辑如下:
# 读 v2
r = redis.StrictRedis()
def get(key, retry=3):
def _get(k):
value = cache.get(k)
if value is None:
if r.set(k,1,ex=1,nx=true): # 加锁
value = db.get(k)
cache.set(k, value)
return true, value
else:
return None, false
else:
return value, true
while retry:
value, flag = _get(key)
if flag == True:
return value
time.sleep(1) # 获取锁失败,sleep 后重新访问
retry -= 1
raise Exception("获取失败")
Case 2
大量 key 同时过期,导致大量 cache miss。冷启动或流量突增等都有可能导致在极短时间内有大量的数据写入缓存,如果它们的过期时间相同,则很可能在相似的时间内过期。
解决方法:
一个比较简单的方法是
随机过期,即每条 data 的过期时间可以设置为expire + random。另一个比较好的方案是可以做一个二级缓存,比如之前做缓存时设计的一套
local_cache + redis的存储方案,或者redis + redis的模式。
另外,就是合理的降级方案。在高并发场景下,当检测到过高的并发可能或已经对资源造成影响后,通过限流降级的方案保护下游资源,避免整个资源被打垮而不可用,在限流期间逐步构建缓存,当缓存逐渐恢复后取消限流,恢复降级。
参考
https://medium.com/@mena.meseha/3-major-problems-and-solutions-in-the-cache-world-155ecae41d4f
http://www.ehcache.org/documentation/3.5/caching-patterns.html
https://docs.microsoft.com/en-us/azure/architecture/patterns/cache-aside
https://coolshell.cn/articles/17416.html
https://en.wikipedia.org/wiki/Cache_(computing)
https://docs.oracle.com/cd/E13924_01/coh.340/e13819/readthrough.htm