第一部分 CMS介绍
CMS英文全称是“Concurrent Mark-Sweep”,是一款低延时的Java垃圾收集器。通常使用在对Java堆中老年代的对象收集中。CMS得优点是低延时,缺点是长时间运行的话会产生内存碎片,当碎片达到阀值,会引发一起Serial Old的Full GC.对应用造成严重的停顿、卡死现象。
何时触发CMS呢?其实是可以通过设定一些参数来影响CMS触发的时机的。通常的参数包括:
CMSInitiatingOccupancyFraction:这个参数是老年代使用率阀值设定参数,当老年代对象超过这个阀值时,会引发一次CMS。默认是92%,但实际应用会将阀值调整到70~80%之内。为什么要调整?想象一下,阀值过高会造成的后果可能因为需要回收的对象过多,处理时间过长而造成回收不及,从而触发灾难性的Full GC.阀值过低,CMS过于频繁,对应用性能同样会有影响。
CMSInitiatingPermOccupancyFraction:针对永久代设定的阀值。(在JDK 1.8应该不存在了吧?)
除了以上阀值外,当新生代对象晋升担保失败下,也会触发一次CMS GC的哦。
第二部分 图文并茂介绍CMS
CMS为了最大限度得降低暂停的时间,将原本一个完成的对象收集过程进行了拆分(分拆法),总共分拆出5个子过程
初始化标记 ——> 并发标记 ——> 预处理 ——> 重新标记 ——> 并发清理 —> 重置
1.初始化标记
这个过程会暂停应用,然后对老年代对象进行可达性标示。主要从根对象和新生代对象中寻找可达的对象进行标记,标记过的对象会被标记成灰色。如下图(本图来自博文中)
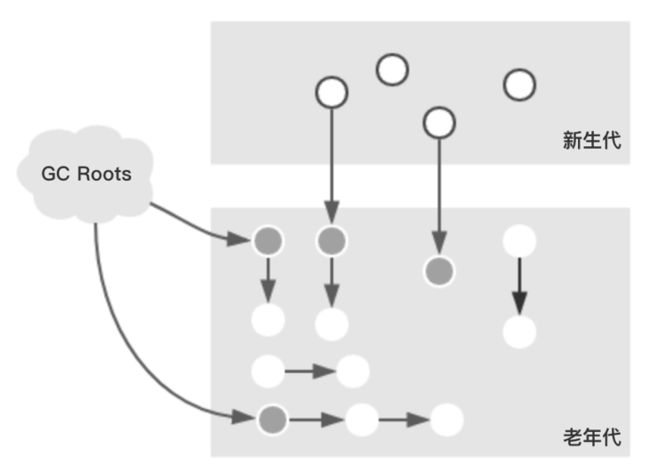
完成了第一个过程后,进行过程二,并发标记
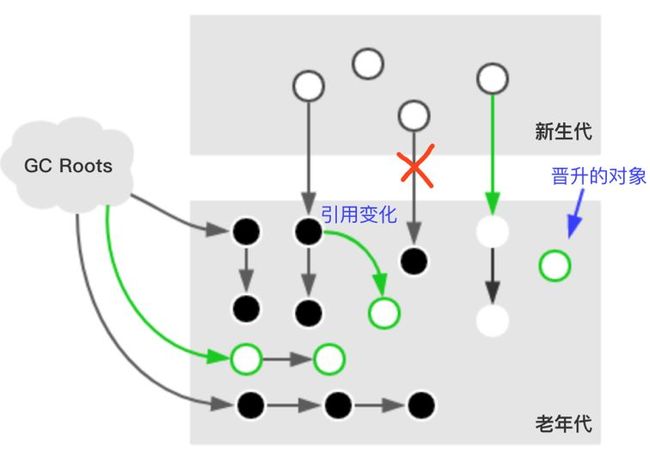
2.并发标记
顾名思义,这个过程标记和应用是可以同时运行的。标记过程会基于第一个过程中已经被标识出可达的对象进行递归标识,完成标识的对象会被标记为黑色。但由于应用仍然在运行中,这个过程可能会导致对象引用发生变化,变化包括新生代对象晋升的老年代、直接在老年代分配对象、老年代对象引用更新。下图标记为绿色的就是发生变化的对象,这些对象所存在的card table会被标识为dirty。这样在后续过程中仅扫描dirty card,避免对整个老年代进行扫描,大大提高remark的效率。
3.重新标记前的预清理阶段
预清理阶段是希望在进行重新标记前,尽可能得处理掉一些在并发标记过程中发生过变化的引用关系,从而来降低remark过程的停顿。 这个阶段又可以再细分为2个子阶段。
预清理阶段:这个阶段会处理在并发标记过程中eden区发生变化的引用(特指eden指向old gen的引用变化),此外还会处理dirty card中的引用。
可中断预清理阶段:这个阶段主要处理from和to区域对象引用old gen的变化,同样也会继续处理dirty card的对象引用。这个阶段默认设置的时间是5s,如果执行逻辑超过5s,会自动终止这个阶段,或者当eden区使用内存值小于CMSScheduleRemarkEdenPenetration,默认50%时,也会退出这个阶段。
如果这个阶段能处理掉一大半的对象引用的话,会大大降低下个阶段remark得停顿时间。有一种对降低remark时延非常有效的方式,就是在可中断预清理阶段碰上young gc。经过young gc后remark就能大大降低时延,为什么? 原因就是因为remark需要对整个young gen进行一次扫描,如果之前发生过一次young gc,那对remark阶段来说,就省了扫描大量对象引用的时间。
4.重新标记
重新标记阶段会处理在并发标记过程发生变化的对象引用,为了找到这些变化的对象,重新标记需要扫描的区域包括
a.扫描根节点的引用
b.扫描整个young gen
c.遍历在预清理阶段剩余的dirty card。
有什么原因会造成remark停顿时间过长?
remark扫描的3个区域中,最有可能影响时延的就是young gen的内存大小。想象一下,young gen对象越多,势必扫描需要的时间就会越长。
有什么方法可以减少remark停顿时间?
方法:在remark之前遇到一次young gc
可以通过设定参数CMSScavengeBeforeRemark,这个参数会在执行remark前执行一次young gc。设定这个参数也会带来一些些小得副作用,就是如果young gen内存使用率不高,或在预清理阶段执行过一次young gc的话,那remark前的这次young gc就形同鸡肋了。 所以,是否开启这个参数,需要在实践中逐渐探索处理。
来一个CMS日志分析
前提-JVM参数设定
堆大小设定:7804M
新生代内存:2926M
CMS触发阀值:75%(CMSInitiatingOccupancyFraction)
1.初始化标记(STW)
[GC [1 CMS-initial-mark: 3746947K(4995072K)] 3767067K(7691712K), 0.0340870 secs] [Times: user=0.04 sys=0.00, real=0.03 secs]
从日志里面可以提取的信息
a.old gen内存占用:3746947K,old gen内存总大小:4995072K ==> 3746947K / 4995072K = 0.7501,因为达到了CMS设定的阀值,所以启动CMS
b.user=0.04,real=0.03。用户耗时基本上等于实际耗时,这里能说明这个阶段应用是暂停的,只有GC线程在执行,而且是单线程的。
2.并发标记
[CMS-concurrent-mark: 0.683/0.683 secs] [Times: user=3.32 sys=0.18, real=0.69 secs]
从日志里面可以提取的信息
并发标记使用了0.683秒,该阶段是并发执行的
3.预清理
[CMS-concurrent-preclean: 0.031/0.032 secs] [Times: user=0.07 sys=0.00, real=0.03 secs]
预清理阶段作用回顾:这个阶段会扫描在并发标记过程中,eden区晋升到old gen的对象、直接分配到old gen的对象或den->old gen(dirty card)等几个对象区域,降低remark阶段暂停时间。
3.1可中断预清理
[CMS-concurrent-abortable-preclean: 5.076/5.132 secs] [Times: user=12.94 sys=1.00, real=5.13 secs]
触发的条件:Eden的占用量>CMSScheduleRemarkEdenSizeThreshold(默认为2M)
中断的条件:Eden区占用量>CMSScheduleRemarkEdenPenetration(默认50%),或达到5秒钟。
4.重新标记(STW)
[GC[YG occupancy: 2103894 K (2696640 K)][Rescan (parallel) , 1.5680650 secs][weak refs processing, 0.8144200 secs]
[1 CMS-remark: 3746947K(4995072K)] 5850842K(7691712K), 2.4045340 secs] [Times: user=17.41 sys=0.00, real=2.40 secs]
这个阶段是多线程并发执行的,也是整个CMS暂停时间最长的。原因就是因为需要扫整个young gen。上面显示用了2.4s。
5.并发清除
[CMS-concurrent-sweep: 4.452/4.853 secs] [Times: user=16.20 sys=1.31, real=4.86 secs]
并发清理未标识的对象
6.重置
[CMS-concurrent-reset: 0.013/0.013 secs] [Times: user=0.03 sys=0.00, real=0.01 secs]
为下一次CMS需要的数据结构重新初始化
原文:
CMS 图解:https://mp.weixin.qq.com/s?__biz=MzIwMzY1OTU1NQ==&mid=2247483849&idx=1&sn=2d7716152f3465e86e1d2db0d9a0fe78&chksm=96cd4185a1bac8932004ac43f4dcab7bc9c2b809f22f1507f48fd26ddaa434b6f22471a59c8d&scene=21#wechat_redirect
CMS日志:https://blog.csdn.net/a417930422/article/details/16948933