引言
对于序列化概念,如果是学习过Java的人,相信一定不会陌生,序列化就是将对象的数据、状态转换成能够存储或者传输的过程。目前常用的有Json、Protobuf、Thrift等。然而,skynet对于服务之间的通讯,数据序列化采用的是 skynet.pack,反序列化 skynet.unpack。
skynet.pack和skynet.unpack
那么skynet.pack 是以什么方式来序列化的呢?我们可以通过 skynet.lua 这个文件里面看到,skynet.pack 其实是指向 c.pack,其中的 c 就是 c 语言层的调用。 那么这个 c 又是由哪个文件提供的接口呢, 通过 lualib-src/lua-skynet.c 文件,我们看到了 pack 接口对应于 lualib-src/lua-seri.c 的 luaseri_pack 函数。好了,现在我们终于知道了 skynet.pack 是由 luaseri_pack 实现的。
对于 luaseri_pack 实现序列化的思路也比较简单。就是 对要进行序列化的数据先一个一个取出来,根据每个数据的类型type,将其写到一个连续的内存块中。而 luaseri_unpack 函数就是对其反序列化,将内存块中的数据按照类型type依次压人lua 栈中,最后将数据返回给 lua 层,这样就实现了一次序列化和反序列化操作。skynet 服务与服务之间的消息传递,也是要经过 skynet.pack 序列化和 skynet.unpack 反序列化。这个序列化过程与 protobuf 类似,每个 lua 类型存储格式如下:
- nil 类型(TYPE_NIL:0):

- boolean 类型(TYPE_BOOLEAN:1):
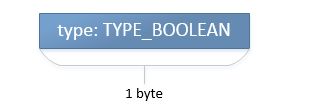
- string类型:
- 短string类型(TYPE_SHORT_STRING:4):
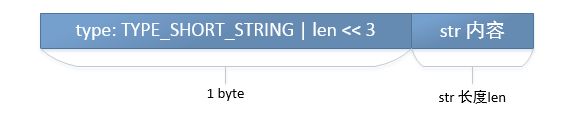
2. 长string类型(TYPE_LONG_STRING:4):

-
number类型(TYPE_NUMBER:2):
- 值:0

- 值为8个字节

3. 值为负数

4. 值小于2个字节

5. 值小于3个字节

6. 值为其他情况

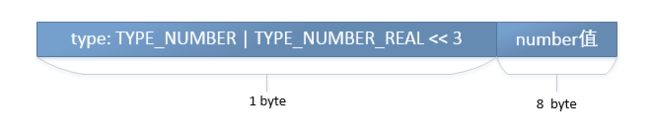
- 浮点数类型(TYPE_NUMBER_REAL: 8):
- 用户自定义类型(TYPE_USERDATA: 3):

-
table类型(TYPE_TABLE:6):
-
数组类型
 图13 array_size 会采用之前讲到的 number 类型来存储,所以存几个字节要按array_size大小决定
图13 array_size 会采用之前讲到的 number 类型来存储,所以存几个字节要按array_size大小决定 -
key-value类型
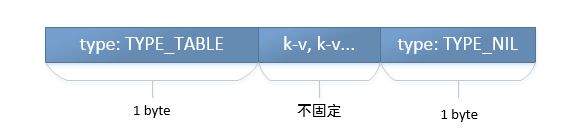 图14 加上 1个字节的 nil 类型标识结束
图14 加上 1个字节的 nil 类型标识结束
-
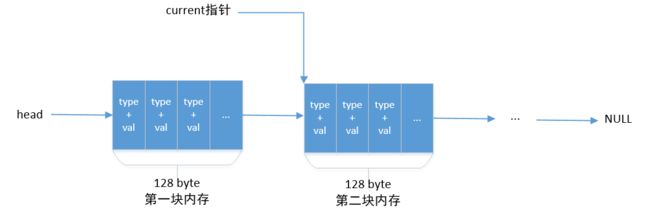
通过以上的分析,大概知道了缓存区域是怎么存储 lua 的各种数据类型。但缓存区在初始化时应该分配多大好呢,我们可以从源代码中看到,缓存区结构体 buffer 域只有 128 byte大小,那么在数据过大时,buffer 势必会不够存储,它又应该如何处理呢。我们接着看下一个结构体 struct write_block ,它的head 域和 current 域都指向了 struct block,可以猜测出,head 应该是一个链表的头节点,current 应该是指向当前要写入链表的哪一块 block。它会先通过 malloc 申请一块内存出来。如果超过了 128,那么就会再申请一块内存,current就指向新的内存块,然后继续往里面写数据。再写完了之后,它不是返回这个 head 指针给 lua 调用者, 而是再进行一次复制操作。将链表里的所有数据写到一块新的缓冲区 newbuffer 中。申请缓冲区的大小 sz 可以根据 struct write_block 结构体中的 len 域获取(在每次写数据时,这个 len 就记录了数据的总长度)。最终返回的是这个新的内存块 newbuffer 及大小 sz。
至于为什么还要重新复制一次,没有直接返回 head 指针给 lua 层调用者,然后根据 head 指向的链表来反序列化呢。我想主要是为了集群等其他模块的需要。比如说集群,你不可能通过 socket 发送一个链表给对方吧,所以只返回一个内存块地址和大小,可以为其他模块减少不必要的麻烦。
对于 number 和 string 的序列化也做到了尽可能的节省内存,如果你在 lua 层对一个number变量赋值0,那么它在序列化时,只用了一个字节的 type 来标识。没有造成内存块的过多浪费。可以说,这个思想,值得我们学习。
#define BLOCK_SIZE 128
//对应于图15 的一块内存
struct block {
struct block * next; //指向下一个内存块
char buffer[BLOCK_SIZE];
};
struct write_block {
struct block * head;
struct block * current;
int len;
int ptr;
};
struct read_block {
char * buffer;
int len;
int ptr;
};
至于反序列化部分,就简单了,用 struct read_block 中的 buffer 域指向 newbuffer,len 指向 sz,然后先从buffer指向的内存中取出一个字节,这个字节就是type, 根据 type 类型读取值(有值的情况下),将其压人lua 栈中,如此反复,直到读取完,最后返回给 lua 层,这样就完成了一次反序列化操作了。
如果还是不怎么懂,那接下来再看看代码是如何实现的吧,为了简单点,就以序列化 一个 字符串为例吧。
local msg, sz = skynet.pack("hello")
skynet.unpack(msg, sz)
根据图3,我们可以画出hello在内存块中的简单存储结构。

接下来再看看代码的实现,skynet.pack 的调用最终会进入 c 层:
下面引用到的代码都在 lualib-src/lua-seri.c 文件中。
LUAMOD_API int
luaseri_pack(lua_State *L) {
struct block temp;
temp.next = NULL;
struct write_block wb;
wb_init(&wb, &temp); //初始化结构体 wb
pack_from(L,&wb,0); //开始序列化
assert(wb.head == &temp);
seri(L, &temp, wb.len); //将head 指向的链表重新放到一个缓冲区中,并返回,加上大小sz
wb_free(&wb);
return 2;
}
再看看 pack_from 的实现:
static void
pack_from(lua_State *L, struct write_block *b, int from) {
int n = lua_gettop(L) - from; //获取要序列化的个数,目前只有 hello 一个数据,所以 n 为 1
int i;
for (i=1;i<=n;i++) {
pack_one(L, b , from + i, 0); // 对 "hello" 数据进行序列化
}
}
那么 pack_one 又做了哪些事呢
static void
pack_one(lua_State *L, struct write_block *b, int index, int depth) {
...
int type = lua_type(L,index); // 根据 index 获取数据类型,按照我之前的设定,只有一个数据,index 为 0
switch(type) {
case LUA_TNIL:
...
case LUA_TNUMBER: {
...
}
case LUA_TBOOLEAN:
...
case LUA_TSTRING: { // 由于 "hello" 是字符串类型,所以来到这里,如果是 lua 层判断数据类型,应该是用 type(data) == "string"
size_t sz = 0;
const char *str = lua_tolstring(L,index,&sz);
wb_string(b, str, (int)sz);
break;
}
case LUA_TLIGHTUSERDATA:
...
case LUA_TTABLE: {
...
}
default:
...
}
}
到了这里,大家应该可以看出,序列化 lua 数据都是根据其数据类型,依依写入到buffer缓冲区当中。再接着看看 wb_string 的实现吧。
static inline void
wb_string(struct write_block *wb, const char *str, int len) {
if (len < MAX_COOKIE) { //这里由于 "hello" 字符串长度不会超过 MAX_COOKIE(32),所以代码会执行到 if 里面
// TYPE_SHORT_STRING | len << 3,一个字节 8 bit,由于 len 小于 MAX_COOKIE,左移 3 位不会有数据溢出情况,TYPE_SHORT_STRING 就保留在低 3 位中
uint8_t n = COMBINE_TYPE(TYPE_SHORT_STRING, len);
//这里就是通过 wb_push 这个函数, 将 type 和 len 一起写入到缓冲区链表中,只写入 1 个字节
//由于 len 小于 MAX_COOKIE,所以一个字节足够存储 type 和 len 内容
wb_push(wb, &n, 1);
if (len > 0) {
//*** 这里就是 将 "hello" 写入到缓冲区链表中,只写入 len 个字节,跟我们之前画的数据存入buffer 图相对应
wb_push(wb, str, len);
}
} else {
uint8_t n;
if (len < 0x10000) {
n = COMBINE_TYPE(TYPE_LONG_STRING, 2);
wb_push(wb, &n, 1);
uint16_t x = (uint16_t) len;
wb_push(wb, &x, 2);
} else {
n = COMBINE_TYPE(TYPE_LONG_STRING, 4);
wb_push(wb, &n, 1);
uint32_t x = (uint32_t) len;
wb_push(wb, &x, 4);
}
wb_push(wb, str, len);
}
}
接着就是 wb_push 的实现了
inline static void
wb_push(struct write_block *b, const void *buf, int sz) {
const char * buffer = buf; // buf 是 void* 类型,因为buf 可能指向的是int 类型地址、char类型地址等,所以只用这个任意类型指针了
if (b->ptr == BLOCK_SIZE) {
_again:
b->current = b->current->next = blk_alloc(); //重新申请一块内存
b->ptr = 0; //指针偏移的地方,每次要写入数据时,就是根据它来确定写入的起始地址
}
if (b->ptr <= BLOCK_SIZE - sz) { // 当要写入内容的长度还足够时,不超过这个内存块大小时,直接复制数据,保存到 b->current 指向的内存块中
memcpy(b->current->buffer + b->ptr, buffer, sz);
b->ptr+=sz; //指向的位置偏移
b->len+=sz; // len 总大小要加上 sz
} else {
// 来到这里,表明一块内存 128 k不够用了。但我们可以先把 buf 部分内容写入到这个内存块中,不够存的那部分就留到下一个新的内存块中。
//也就是说,这次要写入的数据分两次或多次写,先把一部分写到当前的内存中,剩下的部分写到下一块内存中。
int copy = BLOCK_SIZE - b->ptr;
memcpy(b->current->buffer + b->ptr, buffer, copy);
buffer += copy;
b->len += copy;
sz -= copy;
goto _again; // 这里就是跳到前面的 _again: 中,重新申请内存块,继续写入剩余的数据。
}
}
好了,到这里,"hello",这个字符串也就写完了,再看看它是如何返回给 lua 层的吧。
static void
seri(lua_State *L, struct block *b, int len) {
uint8_t * buffer = skynet_malloc(len);
uint8_t * ptr = buffer;
int sz = len;
while(len>0) {
if (len >= BLOCK_SIZE) {
memcpy(ptr, b->buffer, BLOCK_SIZE);
ptr += BLOCK_SIZE;
len -= BLOCK_SIZE;
b = b->next;
} else {
memcpy(ptr, b->buffer, len);
break;
}
}
lua_pushlightuserdata(L, buffer); // 为了好区分buffer是指哪个,我暂时将这个叫 new_buffer
lua_pushinteger(L, sz); //返回所有数据的总大小
}
还记得 luaseri_pack(lua_State *L) 函数里面有个 seri(L, &temp, wb.len); 调用吗,这里就是将整个链表重新复制一份,放到 new_buffer 中,最后和 sz 一起返回给 lua 层。
我们再看看反序列化 skynet.unpack 的接口调用:
local msg, sz = skynet.pack("hello")
skynet.unpack(msg, sz)
到了这里,反序列化需要调用的 c 层接口 luaseri_unpack 。
int
luaseri_unpack(lua_State *L) {
...
void * buffer;
int len;
...
buffer = lua_touserdata(L,1);
len = luaL_checkinteger(L,2);
...
lua_settop(L,1);
struct read_block rb;
rball_init(&rb, buffer, len); //初始化 rb,让 rb 的 buffer 指向这个 new_buffer,rb 的 len 指向这个 sz
int i;
for (i=0;;i++) {
if (i%8==7) {
luaL_checkstack(L,LUA_MINSTACK,NULL);
}
uint8_t type = 0;
uint8_t *t = rb_read(&rb, sizeof(type)); //这个就是先读取数据类型type,1个字节(uint8_t大小占一个字节)
if (t==NULL) //如果读取不到,证明已经读取完所有的数据了,可以跳出循环,返回了
break;
type = *t;
push_value(L, &rb, type & 0x7, type>>3); //这里就是读取数据的总入口函数,读完数据,就将其压人 lua 栈中
}
// Need not free buffer 这个意思是 unpack 的调用不用释放内存,至于内存的释放,主要放到
// skynet_server.c 的 dispatch_message 函数中释放
/*
if (!reserve_msg) {
skynet_free(msg->data);
}
*/
return lua_gettop(L) - 1;
}
接着,再看看 push_value 的实现
static void
push_value(lua_State *L, struct read_block *rb, int type, int cookie) {
switch(type) {
case TYPE_NIL:
...
case TYPE_BOOLEAN:
...
case TYPE_NUMBER:
...
case TYPE_USERDATA:
...
case TYPE_SHORT_STRING: //到这里面取出 buffer 的数据
get_buffer(L,rb,cookie);
break;
case TYPE_LONG_STRING: {
...
}
case TYPE_TABLE: {
...
}
default: {
...
}
}
}
其中,get_buffer 的实现也比较简单,就是根据 len 长度,从 buffer 中读取数据。并将其压入 lua 栈中,返回给 lua 层的调用者。
static void *
rb_read(struct read_block *rb, int sz) {
if (rb->len < sz) {
return NULL;
}
int ptr = rb->ptr;
rb->ptr += sz;
rb->len -= sz;
return rb->buffer + ptr;
}
static void
get_buffer(lua_State *L, struct read_block *rb, int len) {
char * p = rb_read(rb,len); // 根据 len 长度,从 rb 的 buffer 域中读取数据
if (p == NULL) {
invalid_stream(L,rb); // 读数据出现异常,这是异常错误处理函数,可以先不理会
}
lua_pushlstring(L,p,len); //返回数据给 lua 层,到了这里,就可以在 lua 层获取到 "hello" 字符串了,反序列化结束了
}
通过一个简单的例子,我们可以看出,skynet.pack 和 skynet.unpack 的实现过程。