这篇文章主要目的是:
1. OpenMP的编译命令和执行命令
2. SGE的qrsh提交任务执行命令
3. 观察在OpenMP环境中,parallel region 和 sequential region 的区域 (but how to observe ?)
4. 通过打印 my thread number 和 total thread number 观察 parallel region 和 sequential region 区域
代码如下:

编译和运行 // Compile and Run
我这里使用intel编译器icc, 使用前不要忘记调用icc,调用命令: module load intel
OpenMP 编译命令: icc -qopenmp filename.c
OpenMP 运行命令:(第一条命令指定线程数量 ): export OMP_NUM_THREADS=3
(第二条命令执行运行结果) : ./a.out
或者提交作业给SGE去执行,命令为:
qrsh -V -cwd -l h_rt=00:02:00,cputype=sandybridge -pe smp 3 -now no ./a.out
各flag意思说明,更多内容点击这里:
qrsh:与qsub相比,qrsh是交互式投递任务,其参数为-now yes|no,默认为yes,若设置为yes,立即调度作业,如果没有可用资源,则拒绝作业,任务投递失败,任务状态为Eqw;若设置为no,调度时如果没有可用资源,则将作业排如队列,等待调度。
-V: 传递当前命令的所有环境变量
-cwd:在当前目录运行
-l h_rt=00:02:00:( l : limit,注意这个是小写的L,不是1 ; h : hold ; rt: run time ) 限制执行时间,若2分钟内都未执行,则任务失败
-pe smp 3:(parallel_environment)定义并行环境,(shared memory parallel)共享内存并行 在3个core上执行
-now no:qrsh的参数
./a.out:运行结果文件
运行结果:
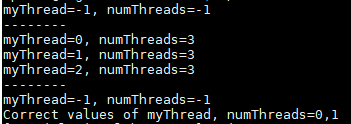
运行结果解析:
1. 第一个print 不在parallel region,所以 myThread =-1,numThreads=-1
2.第二个print在parallel region,每个thread打印自己的线程数和总线程数,所以
第一个线程打印 myThread =1,numThreads=3 ;
第二个线程打印 myThread =2,numThreads=3 ;
第三个线程打印 myThread =3,numThreads=3 ;
多执行几次,会发现这里每个线程的打印是无序的
3. 从并行区域退出后,myThread 和 numThreads 保留原始值,而在并行结构的private中, myThread 和 numThreads 的值被修改,所以 myThread =-1,numThreads=-1
详情查看OMP官方资料,219页
4. 第四个print,输出的是 omp_get_thread_num() 和 omp_get_num_threads() 的值,此时为sequential region,所以 myThread =0,numThreads=1
编译器指令说明
#pragma omp parallel for default(none) shared(num, a, stepsize) private(i, x) reduction(+:sum)
> parallel :( 并行域的产生)用在一个结构块之前,表示这段代码将被多个线程并行执行;
举例: #pragma omp parallel
> for:(for 循环任务的产生)用于for循环语句之前,表示将循环计算任务分配到多个线程中并行执 行,以实现任务分担,必须由编程人员自己保证每次循环之间无数据相关性;
举例: #pragma omp for
> parallel for :parallel和for指令的结合,也是用在for循环语句之前,表示for循环体的代码将被多个线程并行执行,它同时具有并行域的产生和任务分担两个功能
举例: #pragma omp parallel for
> default指定并行区域内变量的属性, C++的OpenMP中default的参数只能为shared或none
default(shared):表示并行区域内的共享变量在不指定的情况下都是shared属性
default(none):表示必须显式指定所有共享变量的数据属性,否则会报错,除非变量有明确的属性定义(比如循环并行区域的循环迭代变量只能是私有的)
如果一个并行区域,没有使用default子句,那么其默认行为为default(shared) , 表达式省略为: #pragma omp parallel for
> shared:指定一个或多个变量为多个线程间的共享变量, 这里是 num,a, stepsize 三个变量共享, 功能如同MPI的Broadcast, 只不过在OMP中,线程共享进程中的数据
> private:指定一个或多个变量在每个线程中都有它自己的私有副本, 这里是i 和 x ,功能如同MPI的Scatter,将数据split and allocate 给各个线程
> reduction:用来指定一个或多个变量是私有的,并且在并行处理结束后这些变量要执行指定的归约运算,并将结果返回给主线程同名变量,功能如同MPI的Reduce
关于其他:
const关键字及其作用:
1.是只读变量,即非常量又非变量,所以又称为 常变量
2.是非常量(比如,Pi = 3,14 是固定值),而const定义的不是pi这种常量
3.是非变量,不允许重新赋值,即使是赋相同的值也不可以
4.生存周期都是程序运行的整个过程
————————————————
版权所有,请勿转载!!!
Reference:
https://www.openmp.org/wp-content/uploads/openmp-examples-4.5.0.pdf
https://www.openmp.org/wp-content/uploads/OpenMP-4.5-1115-CPP-web.pdf
https://blog.csdn.net/ArrowYL/article/details/81094837