简介
什么是MyBatis-Plus?
MyBatis-Plus(以下简称MP),为简化开发而生。
MP是一个MyBatis的增强工具,在MyBatis的基础上只做增强不做改变。
MP的特性
- 无侵入:只做增强不做改变,引入它不会对现有工程产生影响,如丝般顺滑
- 损耗小:启动即会自动注入基本 CURD,性能基本无损耗,直接面向对象操作
- 强大的 CRUD 操作:内置通用 Mapper、通用 Service,仅仅通过少量配置即可实现单表大部分 CRUD 操作,更有强大的条件构造器,满足各类使用需求
- 支持 Lambda 形式调用:通过 Lambda 表达式,方便的编写各类查询条件,无需再担心字段写错
- 支持主键自动生成:支持多达 4 种主键策略(内含分布式唯一 ID 生成器 - Sequence),可自由配置,完美解决主键问题
- 支持 ActiveRecord 模式:支持 ActiveRecord 形式调用,实体类只需继承 Model 类即可进行强大的 CRUD 操作
- 支持自定义全局通用操作:支持全局通用方法注入(Write once, use anywhere)
- 内置代码生成器:采用代码或者 Maven 插件可快速生成 Mapper 、 Model 、 Service 、 Controller 层代码,支持模板引擎,更有超多自定义配置等您来使用
- 内置分页插件:基于 MyBatis 物理分页,开发者无需关心具体操作,配置好插件之后,写分页等同于普通 List 查询
- 分页插件支持多种数据库:支持 MySQL、MariaDB、Oracle、DB2、H2、HSQL、SQLite、Postgre、SQLServer 等多种数据库
- 内置性能分析插件:可输出 Sql 语句以及其执行时间,建议开发测试时启用该功能,能快速揪出慢查询
- 内置全局拦截插件:提供全表 delete 、 update 操作智能分析阻断,也可自定义拦截规则,预防误操作
支持数据库
- mysql 、 mariadb 、 oracle 、 db2 、 h2 、 hsql 、 sqlite 、 postgresql 、 sqlserver
- 达梦数据库 、虚谷数据库 、人大金仓数据库
快速体验
1、建立数据库mybatis-plus,导入数据。
DROP TABLE IF EXISTS user;
CREATE TABLE user
(
id BIGINT(20) NOT NULL COMMENT '主键ID',
name VARCHAR(30) NULL DEFAULT NULL COMMENT '姓名',
age INT(11) NULL DEFAULT NULL COMMENT '年龄',
email VARCHAR(50) NULL DEFAULT NULL COMMENT '邮箱',
PRIMARY KEY (id)
);
DELETE FROM user;
INSERT INTO user (id, name, age, email) VALUES
(1, 'Jone', 18, '[email protected]'),
(2, 'Jack', 20, '[email protected]'),
(3, 'Tom', 28, '[email protected]'),
(4, 'Sandy', 21, '[email protected]'),
(5, 'Billie', 24, '[email protected]');
2、创建SpringBoot项目,导入对应的依赖。
com.baomidou
mybatis-plus-boot-starter
3.0.5
mysql
mysql-connector-java
runtime
3、编写项目。
- 配置数据库连接。
# DataSource Config
spring:
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/mybatis-plus?useSSL=false&useUnicode=true&characterEncoding=utf-8&serverTimezone=GMT%2B8
username: root
password: 123456
- 编写实体类(这里使用了lombok插件)。
@Data
@AllArgsConstructor
@NoArgsConstructor
public class User {
private Long id;
private String name;
private Integer age;
private String email;
}
- 编写mapper接口继承BaseMapper即可。至此所有基本的CRUD都已经完成了。
//使用了MP之后,我们就不用编写CRUD了,只需要继承一个接口即可
//BaseMapper,泛型T就是表示你要操作的类
@Repository
public interface UserMapper extends BaseMapper {
//这里几乎内置了所有的查询,除了十分特殊的查询之外
//MP,对于复杂的SQL依旧要自己编写
}
4、在测试类中测试使用即可。
@SpringBootTest
class SpringbootMpApplicationTests {
@Autowired
private UserMapper userMapper;
@Test
void testMP(){
//参数Wrapper是一个复杂的条件构造器
//查询所有的用户
List users = userMapper.selectList(null);
users.forEach(System.out::println);
//70%以上的业务都可以在这里自动实现,抛开了底层dao层
//这个时候你就可以专心的写Controller了
}
}
BaseMapper
所有的CRUD操作,BaseMapper都已经帮我们封装好了,我们拿来即用就可以了。
BaseMapper中的所有接口方法如下:
int insert(T var1);
int deleteById(Serializable var1);
int deleteByMap(@Param("cm") Map var1);
int delete(@Param("ew") Wrapper var1);
int deleteBatchIds(@Param("coll") Collection var1);
int updateById(@Param("et") T var1);
int update(@Param("et") T var1, @Param("ew") Wrapper var2);
T selectById(Serializable var1);
List selectBatchIds(@Param("coll") Collection var1);
List selectByMap(@Param("cm") Map var1);
T selectOne(@Param("ew") Wrapper var1);
Integer selectCount(@Param("ew") Wrapper var1);
List selectList(@Param("ew") Wrapper var1);
List> selectMaps(@Param("ew") Wrapper var1);
List T就是我们要操作的数据对象。
另外我们还需要在配置文件中开启日志功能。
#配置日志
mybatis-plus.configuration.log-impl=org.apache.ibatis.logging.stdout.StdOutImpl
插入策略
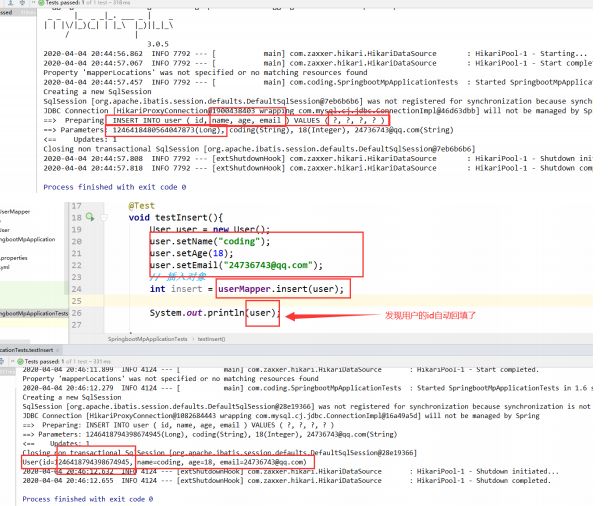
往数据库中插入一条记录只需要直接调用mapper对象的insert方法进行插入即可。
@Test
void testInsert(){
User user=new User();
user.setName("coding");
user.setAge(18);
user.setEmail("[email protected]");
//插入对象
int insert=userMapper.insert(user);
//id自动回填了,这个对象直接使用
//这个id是什么 1251036873686134785(雪花算法)
System.out.println(user);
}
默认情况下,id会自动回填,查看控制台会发现系统自动帮我们生成了一串随机数字作为id填入SQL参数中。
主键生成策略
MP中主键默认生成策略是雪花算法(snowflake)。
snowflake是Twitter开源的分布式ID生成算法,结果是一个long型的ID。其核心思想是:使用41bit作为毫秒数,10bit作为机器的ID(5个bit是数据中心,5个bit的机器ID),12bit作为毫秒内的流水号(意味着每个节点在每毫秒可以产生4096个ID),最后还有一个符号位,永远是0。
关于id生成策略的更多内容,可以参考这篇博客:https://www.cnblogs.com/haoxinyue/p/5208136.html
在MP中,主要有以下几种主键生成策略,我们可以结合IdType这个枚举类的代码来分析:
- 自增(需保证数据库中的主键字段是自增的)
- 手动输入
- uuid
- 雪花算法
......
public enum IdType {
AUTO(0),// 自增
NONE(1),//不使用策略
INPUT(2),// 手动输入
ID_WORKER(3),//唯一id生成器(默认)
UUID(4),//uuid
ID_WORKER_STR(5);//唯一id生成器(字符串类型)
}
更新策略
MP在更新对象时会自动帮我们匹配动态SQL。测试更新user表中的一条记录。
@Test
void testUpdate(){
//MP在更新对象时自动帮我们匹配动态sql
User user=new User();
user.setId(1L);
user.setAge(100);
//更新一个用户
//updateById这里面传递的是一个user对象
userMapper.updateById(user);
}
自动填充策略(扩展)
在阿里巴巴代码规范中,id、gmt_create、gmt_update是每张表中必备的三个字段。

因此,我们给user表增加两个字段:create_time和update_time,分别表示创建时间和修改时间,然后进行测试。这时我们发现这两个字段默认值被填充为NULL了。
自动更新策略分为两种级别:数据库级别和代码级别。
数据库级别(不建议使用)
1、设置create_time和update_time字段的默认值为CURRENT_TIMESTAMP即可。

2、进行记录更新测试,可以看到这条记录更新后create_time和update_time的值被设置为记录更新的时间。

datetime字段设置默认值会极大的降低数据库的执行效率,因此不建议使用这种自动更新策略。
代码级别(建议使用)
1、删除create_time和update_time字段的默认值。

2、编写代码。
- 编写实体类对应的注解。
//时间的操作(自动更新)
@TableField(fill = FieldFill.INSERT) //插入时更新
private Date createTime;
@TableField(fill = FieldFill.INSERT_UPDATE) //插入或更新时更新
private Date updateTime;
- 编写元对象处理器。
//自定义元对象处理器
@Component
public class MyMetaObjectHandler implements MetaObjectHandler {
//插入的策略
@Override
public void insertFill(MetaObject metaObject) {
//设置当前字段的值
//以后只要是插入操作就会自动控制createTime、updateTime使用new Date()进行自动填充
this.setFieldValByName("createTime",new Date(),metaObject);
this.setFieldValByName("updateTime",new Date(),metaObject);
}
//更新策略
@Override
public void updateFill(MetaObject metaObject) {
this.setFieldValByName("updateTime",new Date(),metaObject);
}
}
乐观锁
什么是乐观锁?什么又是悲观锁?
乐观锁:非常乐观,无论什么操作都不加锁。乐观锁的通常实现方式是在表中增加一个乐观锁字段(version)即可。当要更新一条记录时,希望这条记录没有被别人更新,一旦记录抢先被别人更新,那么当前更新就会失败。
悲观锁:非常悲观,无论什么操作都加锁。我们一旦加锁,那它就一定是悲观锁。
乐观锁的实现方式
乐观锁的实现方式如下:
- 取出记录时,获取当前version。
- 更新时,在条件中会带上这个version。
- 执行更新时,set version=newVersion where version=oldVersion,其中oldVersion就是我们一开始获取的version。
- 如果version不对,就会更新失败。
//乐观锁失败
@Test
void testOptimisticLocker2(){
//线程一查询原来的数据
User user = userMapper.selectById(1L);
//线程一修改当前数据
user.setName("Jack2");
//线程二抢先更新了
User user2 = userMapper.selectById(1L);
user2.setName("Jack3 ");
userMapper.updateById(user2);
//线程一执行修改
userMapper.updateById(user);
}
MP中如何配置乐观锁
1、在数据库表中添加version字段,将@Version注解添加到字段上。
@Version
private Integer version;
2、添加乐观锁插件。
@Configuration
public class MPConfig {
//乐观锁插件 本质是一个拦截器
@Bean
public OptimisticLockerInterceptor optimisticLockerInterceptor() {
return new OptimisticLockerInterceptor();
}
}
3、测试后发现更新SQL中自动带上了版本号。
查询策略
MP为我们提供了单条记录、多条记录、指定数量、分页等多种查询方法,测试方法如下:
//查询(使用的最多 ,单个,多个,指定数量,分页查询)
@Test
void testSelectById(){
User user=userMapper.selectById(1L);
System.out.println(user);
}
@Test
void testSelectByIds(){
//批量查询
List users = userMapper.selectBatchIds(Arrays.asList(1, 2, 3));
users.forEach(System.out::println);
}
@Test
void testSelectByCount(){
//查询数据量
Integer count= userMapper.selectCount(null);
System.out.println(count);
}
@Test
void testSelectByMap(){
//简单条件查询
Map map=new HashMap<>();
map.put("name","wunian");
map.put("age",3);
List users = userMapper.selectByMap(map);
users.forEach(System.out::println);
}
分页查询
MP的分页插件支持 MySQL、MariaDB、Oracle、DB2、H2、HSQL、SQLite、Postgre、SQLServer 等多种数据库。
测试代码如下:
//分页查询 limit(sql) MP内置了分页插件,导入即可
@Test
void testPage(){
//1、先查询总数
//2、本质还是limit 0,10(默认的)
//参数(当前页,每个页面的大小)
Page page=new Page<>(2,5);
IPage users = userMapper.selectPage(page, null);
System.out.println(page.getTotal());//总数
System.out.println(page.hasNext());//是否有下一页
System.out.println(page.hasPrevious());//是否有上一页
page.getRecords().forEach(System.out::println);//遍历数据
System.out.println(page.getSize());//获取当前页的记录数
}
删除策略
MP提供了删除单条记录和多条记录的方法。测试代码如下:
//删除(单个,多个)
@Test
void testDeleteById(){
userMapper.deleteById(1251036873686134785L);
}
@Test
void testDeleteByIds(){
userMapper.deleteBatchIds(Arrays.asList(1251036873686134785L,1251045724569370626L));
}
//简单的条件删除
@Test
void testDeletMap(){
Map map=new HashMap<>();
map.put("name","wunian");
map.put("age",3);
userMapper.deleteByMap(map);
}
逻辑删除
先来了解下逻辑删除和物理删除的概念:
- 逻辑删除:并不是真的从数据库中删除了,只是加了一个条件判断而已。
- 物理删除:直接从数据库中删除了。
业务场景:管理员在后台可以看到被删除的记录,使用逻辑删除可以保证项目的安全性和健壮性。
使用方法:
1、在数据库中添加逻辑删除字段deleted
2、在实体类字段中添加逻辑删除注解@TableLogic
@TableLogic //逻辑删除字段
private Integer deleted;
3、在配置类中添加处理逻辑删除的插件。
//逻辑删除插件
@Bean
public ISqlInjector sqlInjector() {
return new LogicSqlInjector();
}
4、在配置文件中配置逻辑删除。
#配置逻辑删除 删除:1 不删除:0
mybatis-plus.global-config.db-config.logic-delete-value=1
mybatis-plus.global-config.db-config.logic-not-delete-value=0
5、只要配置了逻辑删除,以后的查询都会带上逻辑删除字段,这样能够保证程序效率和结果正常。
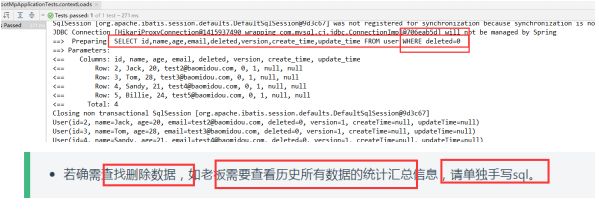
6、查询被删除的数据,请单独手写SQL。
SELECT * FROM user WHERE deleted=1
性能分析
MP提供了性能分析插件,它能在开发中帮助我们排除慢SQL。
如果要使用性能分析插件,只需要在配置类中配置即可。
//SQL执行效率插件
@Bean
@Profile({"dev","test"})// 设置 dev test 环境开启
public PerformanceInterceptor performanceInterceptor() {
PerformanceInterceptor interceptor=new PerformanceInterceptor();
//允许执行的sql的最长时间,默认的单位是毫秒
//超过这个时间sql会报错
interceptor.setMaxTime(100);
//格式化sql代码
interceptor.setFormat(true);
return interceptor;
}
正常开发时可以在控制台查看到SQL的执行效率。
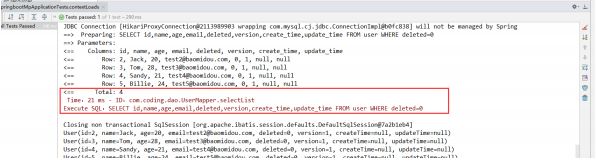
如果SQL的执行时间,超过了我们设置的最长时间范围,控制台就会报错。
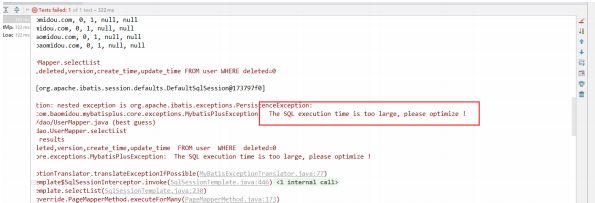
一般解决慢SQL的方法无非就是优化SQL语句,建立索引,分库分表这些。
条件构造器
我们平时编写SQL,一般使用的最多的就是一些查询条件,MP为我们提供了条件构造器来动态构造SQL语句。测试代码如下:
@SpringBootTest
public class WrapperTest {
@Autowired
private UserMapper userMapper;
//条件查询器
@Test
void testWrapper(){
QueryWrapper wrapper = new QueryWrapper<>();
//链式编程,可以构造多个条件,会自动拼接SQL
wrapper
.isNotNull("name")
.ge("age",28); //大于等于
//.eq("age",100)
userMapper.delete(wrapper);
}
//边界查询
@Test
void testWrapper2(){
QueryWrapper wrapper = new QueryWrapper<>();
wrapper.between("age",20,28);
userMapper.selectCount(wrapper);
}
//精准匹配
@Test
void testWrapper3(){
QueryWrapper wrapper = new QueryWrapper<>();
Map map=new HashMap<>();
map.put("name","Jack");
map.put("age",20);
wrapper.allEq(map);
userMapper.selectList(wrapper);
}
//模糊查询
@Test
void testWrapper4(){
QueryWrapper wrapper = new QueryWrapper<>();
wrapper.notLike("name","j") //like '%j%'
.likeRight("email","t"); // like 't%'
userMapper.selectMaps(wrapper);
}
//子查询(in)
@Test
void testWrapper5(){
QueryWrapper wrapper = new QueryWrapper<>();
//wrapper.in("id",1,2,3,4);
//子查询
wrapper.inSql("id","select id from user where id<3");
userMapper.selectObjs(wrapper);
}
// and or
@Test
void testWrapper6(){
User user=new User();
user.setAge(100);
user.setName("Jack");
UpdateWrapper updateWrapper = new UpdateWrapper<>();
//在一些新的框架中,链式编程,lambda表达式,函数式接口用的非常多
updateWrapper
.like("name","k")
.or(i->i.eq("name","wunian").ne("age",0));
userMapper.update(user,updateWrapper);
}
//排序
@Test
void testWrapper7(){
QueryWrapper wrapper=new QueryWrapper();
wrapper.orderByAsc("id");
userMapper.selectList(wrapper);
}
//多表查询解决方案 last(不建议使用)
//一般大公司会设计冗余字段,很少用到多表查询
//如果要多表查询,没有简便办法,自己扩展即可
@Test
void testWrapper8(){
QueryWrapper wrapper=new QueryWrapper();
wrapper.last("limit 1");
userMapper.selectList(wrapper);
}
}
注意:last方法只能调用一次,多次调用以最后一次为准,并且有SQL注入的风险,请谨慎使用。