AI算法模型线上部署方法总结
AI算法模型线上部署方法总结
- (推荐)PMML介绍及使用
- 一、机器学习算法线上部署方法
-
- 1.1 三种场景
- 1.2 如何转换PMML,并封装PMML
- 1.3 接下来说一下各个算法工具的工程实践
-
- 1.3.1 python模型上线:我们目前使用了模型转换成PMML上线方法。
- 1.3.2 R模型上线-这块我们用的多,可以用R model转换PMML的方式来实现。
- 1.3.3 Spark模型上线-好处是脱离了环境,速度快。
- 1.4 只用Linux的Shell来调度模型的实现方法—简单粗暴
- 1.5 说完了部署上线,说一下模型数据流转的注意事项
- 二、机器学习算法的部署
-
- 实时小规模
- 实时大规模
- 离线计算
- 三、谈一谈AI算法部署的一些经验
- 四、老潘的AI部署以及工业落地学习之路(深度学习)
-
- 4.1 AI部署
- 4.2 聊聊AI部署
- 4.3 需要什么技术呢?
- 4.4 需要的深度学习基础知识
- 4.5 常用的框架
- Caffe
- Libtorch (torchscript)
- TensorRT
- OpenVINO
- NCNN/MNN/TNN/TVM
- PaddlePaddle
- 还有很多框架
- 4.6 AI部署中的提速方法
-
- 4.6.1 模型结构
- 4.6.2 剪枝
- 4.6.3 蒸馏
- 4.6.4 稀疏化
- 4.6.4 量化训练
- 4.7 常见部署流程
- 4.8 后记
- 五、算法模型在服务端的部署
-
- 谈谈算法模型在服务端的部署
- 5.1 关于模型部署框架的两大类型
- 5.2 关于两种类型的成因思考
- 5.3 那么请问……
- 5.4 关于我们目前的解决方案
- 5.5 为啥不上Kubeflow
flask
https://dormousehole.readthedocs.io/en/latest/
fastApi
https://fastapi.tiangolo.com/zh/
django
https://docs.djangoproject.com/zh-hans/2.0/
pmml
https://zhuanlan.zhihu.com/p/73245462
https://www.freesion.com/article/10901383197/
(推荐)PMML介绍及使用
PMML 介绍:
https://zhuanlan.zhihu.com/p/73245462
xgboost为例导出模型到本地:
from sklearn2pmml import PMMLPipeline
from sklearn_pandas import DataFrameMapper
from sklearn2pmml import sklearn2pmml
import pickle
clf = xgb.XGBRegressor()
clf.fit(df_train[column_list], df_train[[y_name]])
# method1:存储为PMML形式
pipeline = PMMLPipeline([("regression", clf)])
pipeline.fit(df_train[column_list], df_train[[y_name]])
sklearn2pmml(pipeline, "models/%s.pmml" % clf_str, with_repr=True)
# method2:pickle保存模型 .dat
# save model to file
pickle.dump(clf, open("models/%s.pickle.dat" % clf_str, "wb"))
xgb_model = pickle.load(open("models/XGBRegressor().pickle.dat", "rb"))
column_list = ['c1', 'c2', 'c3']
result = xgb_model.predict(df[column_list])
xgboost-pmml,java调用pmml参考资料:
https://www.cnblogs.com/pinard/p/9220199.html
https://www.freesion.com/article/10901383197/
https://blog.csdn.net/Katherine_hsr/article/details/84951324
一、机器学习算法线上部署方法
来自:机器学习算法线上部署方法
我们经常会碰到一个问题:用了复杂的GBDT或者xgboost大大提升了模型效果,可是在上线的时候又犯难了,工程师说这个模型太复杂了,我没法上线,满足不了工程的要求,你帮我转换成LR吧,直接套用一个公式就好了,速度飞速,肯定满足工程要求。这个时候你又屁颠屁颠用回了LR,重新训练了一下模型,心里默骂千百遍:工程能力真弱。
这些疑问,我们以前碰到过,通过不断的摸索,试验出了不同的复杂机器学习的上线方法,来满足不同场景的需求。在这里把实践经验整理分享,希望对大家有所帮助。(我们的实践经验更多是倾向于业务模型的上线流程,广告和推荐级别的部署请自行绕道)。
首先在训练模型的工具上,一般三个模型训练工具,Spark、R、Python。这三种工具各有千秋,以后有时间,我写一下三种工具的使用心得。针对不同的模型使用场景,为了满足不同的线上应用的要求,会用不同的上线方法。
1.1 三种场景
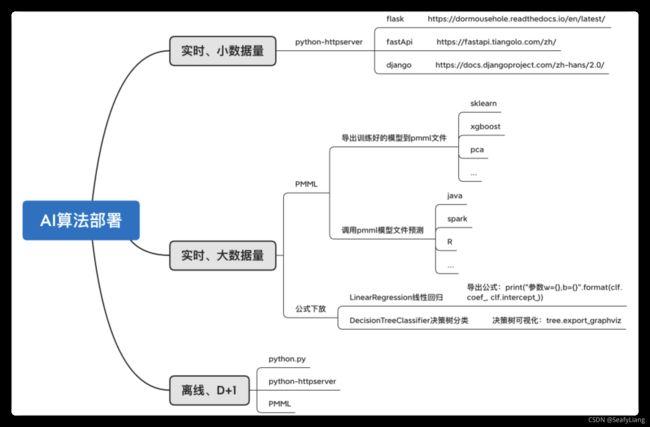
- 如果是实时的、小数据量的预测应用,则采用的SOA调用Rserve或者python-httpserve来进行应用;这种应用方式有个缺点是需要启用服务来进行预测,也就是需要跨环境,从Java跨到R或者Python环境。对于性能,基本上我们用Rserver方式,针对一次1000条或者更少请求的预测,可以控制95%的结果在100ms内返回结果,100ms可以满足工程上的实践要求。更大的数据量,比如10000/次,100000/次的预测,我们目前评估下来满足不了100ms的要求,建议分批进行调用或者采用多线程请求的方式来实现。
- 如果是实时、大数据量的预测应用,则会采用SOA,训练好的模型转换成PMML(关于如何转换,我在下面会详细描述),然后把模型封装成一个类,用Java调用这个类来预测。用这种方式的好处是SOA不依赖于任何环境,任何计算和开销都是在Java内部里面消耗掉了,所以这种工程级别应用速度很快、很稳定。用此种方法也是要提供两个东西,模型文件和预测主类;
- 如果是Offline(离线)预测的,D+1天的预测,则可以不用考虑第1、2种方式,可以简单的使用Rscript x.R或者python x.py的方式来进行预测。使用这种方式需要一个调度工具,如果公司没有统一的调度工具,你用shell的crontab做定时调用就可以了。
以上三种做法,都会用SOA里面进行数据处理和变换,只有部分变换会在提供的Function或者类进行处理,一般性都建议在SOA里面处理好,否则性能会变慢。
大概场景罗列完毕,简要介绍一下各不同工具的线上应用的实现方式。
1.2 如何转换PMML,并封装PMML
大部分模型都可以用PMML的方式实现,PMML的使用方法调用范例见:
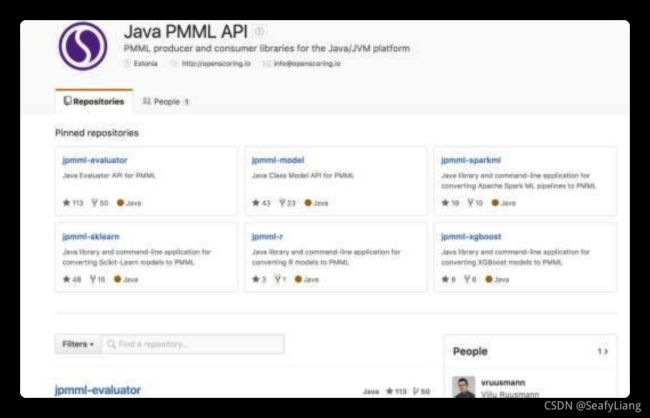
- jpmml的说明文档:GitHub - jpmml/jpmml-evaluator: Java Evaluator API for PMML;
- Java调用PMML的范例(PPJUtils/java/pmml at master · pjpan/PPJUtils · GitHub),此案例是我们的工程师写的范例,大家可以根据此案例进行修改即可;
- Jpmml支持的转换语言,主流的机器学习语言都支持了,深度学习类除外;
- 从下图可以看到,它支持R、python和spark、xgboost等模型的转换,用起来非常方便。
1.3 接下来说一下各个算法工具的工程实践
1.3.1 python模型上线:我们目前使用了模型转换成PMML上线方法。
- python-sklearn里面的模型都支持,也支持xgboost,并且PCA,归一化可以封装成preprocess转换成PMML,所以调用起来很方便;
- 特别需要注意的是:缺失值的处理会影响到预测结果,大家可以可以看一下;
- 用PMML方式预测,模型预测一条记录速度是1ms,可以用这个预测来预估一下根据你的数据量,整体的速度有多少。
1.3.2 R模型上线-这块我们用的多,可以用R model转换PMML的方式来实现。
这里我介绍另一种的上线方式:Rserve。具体实现方式是:用SOA调用Rserve的方式去实现,我们会在服务器上部署好R环境和安装好Rserve,然后用JAVA写好SOA接口,调用Rserve来进行预测;
- Java调用Rserve方式见网页链接:Rserve - Binary R server;
- centos的Rserve搭建方法见:centos -Rserve的搭建,这里详细描述了Rserve的搭建方式。
Rserve方式可以批量预测,跟PMML的单个预测方式相比,在少数据量的时候,PMML速度更快,但是如果是1000一次一批的效率上看,Rserve的方式会更快;用Rserve上线的文件只需要提供两个:
- 模型结果文件(XX.Rdata);
- 预测函数(Pred.R)。
Rserve_1启动把模型结果(XX.Rdata)常驻内存。预测需要的输入Feature都在Java里定义好不同的变量,然后你用Java访问Rserve_1,调用Pred.R进行预测,获取返回的List应用在线上。最后把相关的输入输出存成log进行数据核对。
Pred.R <- function(x1,x2,x3){data <- cbind(x1,x2,x3)# feature engineeringscore <- predict(modelname, data, type = 'prob')return(list(score))
}
1.3.3 Spark模型上线-好处是脱离了环境,速度快。
Spark模型的上线就相对简单一些,我们用scala训练好模型(一般性我们都用xgboost训练模型)然后写一个Java Class,直接在JAVA中先获取数据,数据处理,把处理好的数据存成一个数组,然后调用模型Class进行预测。模型文件也会提前load在内存里面,存在一个进程里面,然后我们去调用这个进程来进行预测。所以速度蛮快的。
- Spark模型上线,放在spark集群,不脱离spark环境,方便,需要自己打jar包;
- 我们这里目前还没有尝试过,有一篇博客写到了如果把spark模型导出PMML,然后提交到spark集群上来调用,大家可以参考一下:Spark加载PMML进行预测。
1.4 只用Linux的Shell来调度模型的实现方法—简单粗暴
因为有些算法工程师想快速迭代,把模型模拟线上线看一下效果,所以针对离线预测的模型形式,还有一种最简单粗暴的方法,这种方法开发快速方便,具体做法如下:
- 写一下R的预测脚本,比如predict.R,是你的主预测的模型;
- 然后用shell封装成xx.sh,比如predict.sh,shell里面调用模型,存储数据;
predict.sh的写法如下:
# 数据导出data_filename = xxx
file_date = xxx
result = xxx
updatedt = xxx
cd path
hive -e "USE tmp_xxxdb;SELECT * FROM db.table1;" > ${data_filname};
# R脚本预测
Rscript path/predict.R $file_date
if [ $? -ne 0 ]
then
echo "Running RScript Failure"
fi
# R预测的结果导入Hive表
list1="use tmp_htlbidb;
load data local inpath 'path/$result'
overwrite into table table2 partition(dt='${updatedt}');"
hive -e "$list1"
- 最后用Crontab来进行调度,很简单,如何设置crontab,度娘一下就好了。
>crontab -e
-------------------------### 每天5点进行预测模型;
0 5 * * * sh predict.sh
1.5 说完了部署上线,说一下模型数据流转的注意事项
- 区分offline和realtime数据,不管哪种数据,我们根据key和不同的更新频次,把数据放在redis里面去,设置不同的key和不同的过期时间;
- 大部分redis数据都会存放两个批次的数据,用来预防无法取到最新的数据,则用上一批次的数据来进行填充;
- 针对offline数据,用调度工具做好依赖,每天跑数据,并生成信号文件让redis来进行读取;
- 针对realtime数据,我们区分两种类型,一种是历史+实时,比如最近30天的累计订单量,则我们会做两步,第一部分是D+1之前的数据,存成A表,今天产生的实时数据,存储B表,A和B表表结构相同,时效性不同;我们分别把A表和B表的数据放在Redis上去,然后在SOA里面对这两部分数据实时进行计算;
- 模型的输入输出数据进行埋点,进行数据跟踪,一是用来校验数据,二来是用来监控API接口的稳定性,一般性我们会用ES来进行log的查看和性能方面的监控;
- 任何接口都需要有容灾机制,如果接口超时,前端需要进行容灾,立即放弃接口调用数据,返回一个默认安全的数值,这点对于工程上非常重要。
二、机器学习算法的部署
来自:机器学习算法的部署
‘
算法工程师和业务开发工程师掌握的技术集和工具是不同的,特别是当两者运用的语言不同的时候更严重。算法辛苦作出的模型业务开发用不了会极大影响很多事情的落地。
常见的合作模式如下算法负责模型训练和导出模型,业务开发导入模型并且做预测。一般算法使用python,R等,而业务开发使用java。可选的部署方法有以下几种:
实时小规模
可以简单点直接用Rserver或者python-httpserver,这种需要额外的服务,也存在调用问题,即引入了网络超时,重试等问题。性能上的话小数量可以保证95%在100ms返回,但是数据量大了就需要仔细控制。
实时大规模
这种情况考虑到基础设施的情况,特别是RPC框架等情况,同时要考虑水平扩展,最好使用PMML。这种额外依赖外部环境的方式可以提供较高的工程稳定性,但是PMML必然导致一些算法精度的损耗。
离线计算
对于T+1的计算和产出,部署上无疑最简单,直接使用脚本搭配一个监控和调度平台就可以获得较好的收益。
对于PMML,java中的选择是https://github.com/jpmml,对于各种语言和模型都有较好的支持。当然由于较高的通用性,PMML会丧失特殊模型的特殊优化,例如上线XGBoost模型,也可以使用XGBoost4J,该包会链接一个本地环境编译的 .so 文件,C++实现的核心代码效率很高。不过PMML格式通用性,在效率要求不高的场景可以发挥很大作用。
三、谈一谈AI算法部署的一些经验
来自:谈一谈AI算法部署的一些经验
- 再次强调一下训练集、验证集和测试集在训练模型中实际的角色:训练集相当于老师布置的作业,验证集相当于模拟试卷,测试集相当于考试试卷,做完家庭作业直接上考卷估计大概率考不好,但是做完作业之后,再做一做模拟卷就知道大体考哪些、重点在哪里,然后调整一下参数啥的,最后真正考试的时候就能考好;训练集中拆分出一部分可以做验证集、但是测试集千万不要再取自训练集,因为我们要保证测试集的”未知“性;验证集虽然不会直接参与训练,但我们依然会根据验证集的表现情况去调整模型的一些超参数,其实这里也算是”学习了“验证集的知识;千万不要把测试集搞成和验证集一样,”以各种形式“参与训练,要不然就是信息泄露。我们使用测试集作为泛化误差的近似,所以不到最后是不能将测试集的信息泄露出去的。
- 数据好坏直接影响模型好坏;在数据量初步阶段的情况下,模型精度一开始可以通过改模型结构来提升,加点注意力、加点DCN、增强点backbone、或者用点其他巧妙的结构可以增加最终的精度。但是在后期想要提升模型泛化能力就需要增加训练数据了,为什么呢?因为此时你的badcase大部分训练集中是没有的,模型没有见过badcase肯定学不会的,此时需要针对性地补充badcase;那假如badcase不好补充呢?此时图像生成就很重要了,如何生成badcase场景的训练集图,生成数据的质量好坏直接影响到模型的最终效果;另外图像增强也非常非常重要,我们要做的就是尽可能让数据在图像增强后的分布接近测试集的分布,说白了就是通过图像生成和图像增强两大技术模拟实际中的场景。
- 当有两个数据集A和B,A有类别a和b,但只有a的GT框;B也有类别a和b,但只有b的GT框,显然这个数据集不能直接拿来用(没有GT框的a和b在训练时会被当成背景),而你的模型要训练成一个可以同时检测a和b框,怎么办?四种方式:1、训练分别检测a和检测b的模型,然后分别在对方数据集上进行预测帮忙打标签,控制好分数阈值,制作好新的数据集后训练模型;2、使用蒸馏的方式,同样训练分别检测a和检测b的模型,然后利用这两个模型的soft-label去训练新模型;3、修改一下loss,一般来说,我们的loss函数也会对负样本(也就是背景)进行反向传播,也是有损失回传的,这里我们修改为,如果当前图片没有类别a的GT框,我们关于a的损失直接置为0,让这个类别通道不进行反向传播,这样就可以对没有a框的图片进行训练,模型不会将a当成背景,因为模型“看都不看a一眼,也不知道a是什么东东”,大家可以想一下最终训练后的模型是什么样的呢?4、在模型的最后部分将head头分开,一个负责检测a一个负责检测b,此时模型的backbone就变成了特征提取器。
- 工作中,有很多场景,你需要通过旧模型去给需要训练的新模型筛选数据,比如通过已经训练好的检测模型A去挑选有类别a的图给新模型去训练,这时就需要搭建一个小服务去实现这个过程;当然你也可以打开你之前的旧模型python库代码,然后回忆一番去找之前的demo.py和对应的一些参数;显然这样是比较麻烦的,最好是将之前模型总结起来随时搭个小服务供内部使用,因为别人也可能需要使用你的模型去挑数据,小服务怎么搭建呢?直接使用flask+Pytorch就行,不过这个qps请求大的时候会假死,不过毕竟只是筛选数据么,可以适当降低一些qps,离线请求一晚上搞定。
- 目前比较好使的目标检测框架,无非还是那些经典的、用的人多的、资源多的、部署方便的。毕竟咱们训练模型最终的目的还是上线嘛;单阶段有SSD、yolov2-v5系列、FCOS、CenterNet系列,Cornernet等等单阶段系列,双阶段的faster-rcnn已经被实现了好多次了,还有mask-rcnn,也被很多人实现过了;以及最新的DETR使用transformer结构的检测框架,上述这些都可以使用TensorRT部署;其实用什么无非也就是看速度和精度怎么样,是否支持动态尺寸;不过跑分最好的不一定在你的数据上好,千万千万要根据数据集特点选模型,对于自己的数据集可能效果又不一样,这个需要自己拉下来跑一下;相关模型TensorRT部署资源:https://github.com/grimoire/mmdetection-to-tensorrt 和 https://github.com/wang-xinyu/tensorrtx
- 再扯一句,其实很多模型最终想要部署,首要难点在于这个模型是否已经有人搞过;如果有人已经搞过并且开源,那直接复制粘贴修改一下就可以,有坑别人已经帮你踩了;如果没有开源代码可借鉴,那么就需要自个儿来了!首先看这个模型的backbone是否有特殊的op(比如dcn、比如senet,当然这两个已经支持了),结构是否特殊(不仅仅是普通的卷积组合,有各种reshape、roll、window-shift等特殊操作)、后处理是否复杂?我转换过最复杂的模型,backbone有自定义op,需要自己实现、另外,这个模型有相当多的后处理,后处理还有一部分会参与训练,也就是有学习到的参数,但是这个后处理有些操作是无法转换为trt或者其他框架的(部分操作不支持),因此只能把这个模型拆成两部分,一部分用TensorRT实现另一部分使用libtorc实现;其实大部分的模型都可以部署,只不过难度不一样,只要肯多想,法子总是有的。
- 转换后的模型,不论是从Pytorch->onnx还是onnx->TensorRT还是tensorflow->TFLITE,转换前和转换后的模型,虽然参数一样结构一样,但同样的输入,输出不可能是完全一样的。当然如果你输出精度卡到小数点后4位那应该是一样的,但是小数点后5、6、7位那是不可能完全一模一样的,转换本身不可能是无损的;举个例子,一个检测模型A使用Pytorch训练,然后还有一个转换为TensorRT的模型A`,这俩是同一个模型,而且转换后的TensorRT也是FP32精度,你可以输入一个随机数,发现这两个模型的输出对比,绝对误差和相对误差在1e-4的基准下为0,但是你拿这两个模型去检测的时候,保持所有的一致(输入、后处理等),最终产生的检测框,分数高的基本完全一致,分数低的(比如小于0.1或者0.2)会有一些不一样的地方,而且处于边缘的hardcase也会不一致;当然这种情况一般来说影响不大,但也需要留一个心眼。
- 模型的理论flops和实际模型执行的速度关系不大,要看具体执行的平台,不要一味的以为flops低的模型速度就快。很多开源的检测库都是直接在Pytorch上运行进行比较,虽然都是GPU,但这个其实是没有任何优化的,因为Pytorch是动态图;一般的模型部署都会涉及到大大小小的优化,比如算子融合和计算图优化,最简单的例子就是CONV+BN的优化,很多基于Pytorch的模型速度比较是忽略这一点的,我们比较两个模型的速度,最好还是在实际要部署的框架和平台去比较;不过如果这个模型参数比较多的话,那模型大概率快不了,理由很简单,大部分的参数一般都是卷积核参数、全连接参数,这些参数多了自然代表这些op操作多,自然会慢。
- 同一个TensorRT模型(或者Pytorch、或者其他利用GPU跑的模型)在同一个型号卡上跑,可能会因为cuda、cudnn、驱动等版本不同、或者显卡的硬件功耗墙设置(P0、P1、P2)不同、或者所处系统版本/内核版本不同而导致速度方面有差异,这种差异有大有小,我见过最大的,有70%的速度差异,所以不知道为什么模型速度不一致的情况下,不妨考虑考虑这些原因。
- 转换好要部署的模型后,一般需要测试这个模型的速度以及吞吐量;速度可以直接for循环推理跑取平均值,不过实际的吞吐量的话要模拟数据传输、模型执行以及排队的时间;一般来说模型的吞吐量可以简单地通过1000/xx计算,xx为模型执行的毫秒,不过有些任务假如输入图像特别大,那么这样算是不行的,我们需要考虑实际图像传输的时间,是否本机、是否跨网段等等。
四、老潘的AI部署以及工业落地学习之路(深度学习)
来自:老潘的AI部署以及工业落地学习之路
Hello我是老潘,好久不见各位。
最近在复盘今年上半年做的一些事情,不管是训练模型、部署模型搭建服务,还是写一些组件代码,零零散散是有一些产出。
虽然有了一点点成果,但仍觉着缺点什么。作为深度学习算法工程师,训练模型和部署模型是最基本的要求,每天都在重复着这个工作,但偶尔静下心来想一想,还是有很多事情需要做的:
- 模型的结构,因为上线业务需要,更趋向于稳定有经验的,而不是探索一些新的结构
- 模型的加速仍然不够,还没有压榨完GPU的全部潜力
深感还有很多很多需要学习的地方啊。
既然要学习,那么学习路线就显得比较重要了。
本文重点谈谈学习AI部署的一些基础和需要提升的地方。这也是老潘之前学习、或者未来需要学习的一些点,这里抛砖引玉下,也希望大家能够提出一点意见。
4.1 AI部署
AI部署这个词儿大家肯定不陌生,可能有些小伙伴还不是很清楚这个是干嘛的,但总归是耳熟能详了。
近些年来,在深度学习算法已经足够卷卷卷之后,深度学习的另一个偏向于工程的方向–部署工业落地,才开始被谈论的多了起来。当然这也是大势所趋,毕竟AI算法那么多,如果用不着,只在学术圈搞研究的话没有意义。因此很多AI部署相关行业和AI芯片相关行业也在迅速发展,现在虽然已经2021年了,但我认为AI部署相关的行业还未到头,AI也远远没有普及。
简单收集了一下知乎关于“部署”话题去年和今年的一些提问:

提问的都是明白人,随着人工智能逐渐普及,使用神经网络处理各种任务的需求越来越多,如何在生产环境中快速、稳定、高效地运行模型,成为很多公司不得不考虑的问题。不论是通过提升模型速度降低latency提高用户的使用感受,还是加速模型降低服务器预算,都是很有用的,公司也需要这样的人才。
在经历了算法的神仙打架、诸神黄昏、灰飞烟灭等等这些知乎热搜后。AI部署工业落地这块似乎还没有那么卷…相比AI算法来说,AI部署的入坑机会更多些。
当然,AI落地部署和神经网络深度学习的关系是分不开的,就算你是AI算法工程师,也是有必要学习这块知识的。并不是所有人都是纯正的AI算法研究员。
4.2 聊聊AI部署
AI部署的基本步骤:
- 训练一个模型,也可以是拿一个别人训练好的模型
- 针对不同平台对生成的模型进行转换,也就是俗称的parse、convert,即前端解释器
- 针对转化后的模型进行优化,这一步很重要,涉及到很多优化的步骤
- 在特定的平台(嵌入端或者服务端)成功运行已经转化好的模型
- 在模型可以运行的基础上,保证模型的速度、精度和稳定性
就这样,虽然看起来没什么,但需要的知识和经验还是很多的。
因为实际场景中我们使用的模型远远比ResNet50要复杂,我们部署的环境也远远比实验室的环境条件更苛刻,对模型的速度精度需求也比一般demo要高。
对于硬件公司来说,需要将深度学习算法部署到性能低到离谱的开发板上,因为成本能省就省。在算法层面优化模型是一方面,但更重要的是从底层优化这个模型,这就涉及到部署落地方面的各个知识(手写汇编算子加速、算子融合等等);对于软件公司来说,我们往往需要将算法运行到服务器上,当然服务器可以是布满2080TI的高性能CPU机器,但是如果QPS请求足够高的话,需要的服务器数量也是相当之大的。这个要紧关头,如果我们的模型运行的足够快,可以省机器又可以腾一些buffer上新模型岂不很爽,这个时候也就需要优化模型了,其实优化手段也都差不多,只不过平台从arm等嵌入式端变为gpu等桌面端了。
作为AI算法部署工程师,你要做的就是将训练好的模型部署到线上,根据任务需求,速度提升2-10倍不等,还需要保证模型的稳定性。
是不是很有挑战性?
4.3 需要什么技术呢?
需要一些算法知识以及扎实的工程能力。
老潘认为算法部署落地这个方向是比较踏实务实的方向,相比_设计模型提出新算法_,对于咱们这种并不天赋异禀来说,只要肯付出,收获是肯定有的(不像设计模型,那些巧妙的结果设计不出来就是设计不出来你气不气)。
其实算法部署也算是开发了,不仅需要和训练好的模型打交道,有时候也会干一些粗活累活(也就是dirty work),自己用C++、cuda写算子(预处理、op、后处理等等)去实现一些独特的算子。也需要经常调bug、联合编译、动态静态库混搭等等。
算法部署最常用的语言是啥,当然是C++了。如果想搞深度学习AI部署这块,C++是逃离不了的。
所以,学好C++很重要,起码能看懂各种关于部署精巧设计的框架(再列一遍:Caffe、libtorch、ncnn、mnn、tvm、OpenVino、TensorRT,不完全统计,我就列过我用过的)。当然并行计算编程语言也可以学一个,针对不同的平台而不同,可以先学学CUDA,资料更多一些,熟悉熟悉并行计算的原理,对以后学习其他并行语言都有帮助。
系统的知识嘛,还在整理,还是建议实际中用到啥再看啥,或者有项目在push你,这样学习的更快一些。
可以选择上手的项目:
- 好用的开源推理框架:Caffe、NCNN、MNN、TVM、OpenVino
- 好用的半开源推理框架:TensorRT
- 好用的开源服务器框架:triton-inference-server
- 基础知识:计算机原理、编译原理等
4.4 需要的深度学习基础知识
AI部署当然也需要深度学习的基础知识,也需要知道怎么训练模型,怎么优化模型,模型是怎么设计的等等。不然你怎会理解这个模型的具体op细节以及运行细节,有些模型结构比较复杂,也需要对原始模型进行debug。
关于深度学习的基础知识,可以看这篇:
- 2021年了,我们还可以入门深度学习吗(含资源)
4.5 常用的框架
这里介绍一些部署常用到的框架,也是老潘使用过的,毕竟对于某些任务来说,自己造轮子不如用别人造好的轮子。
哦嘻嘻嘻嘻。
并且大部分大厂的轮子都有很多我们可以学习的地方,因为开源我们也可以和其他开发者一同讨论相关问题;同样,虽然开源,但用于生产环境也几乎没有问题,我们也可以根据自身需求进行魔改。
这里老潘介绍一些值得学习的推理框架,不瞒你说,这些推理框架已经被很多公司使用于生成环境了。
Caffe
Caffe有多经典就不必说了,闲着无聊的时候看看Caffe源码也是受益匪浅。我感觉Caffe是前些年工业界使用最多的框架(还有一个与其媲美的就是darknet,C实现)没有之一,纯C++实现非常方便部署于各种环境。
适合入门,整体构架并不是很复杂。当然光看代码是不行的,直接拿项目来练手、跑起来是最好的。
第一次使用可以先配配环境,要亲手来体验体验。
至于项目,建议拿SSD来练手!官方的SSD就是拿Caffe实现的,改写了一些Caffe的层和组件,我们可以尝试用SSD训练自己的数据集,然后部署推理一下,这样才有意思!
相关资料:
- Caffe-SSD
- 封藏的SSD(Single Shot MultiBox Detector)笔记
- 利用Caffe推理CenterNet(上篇)
- 利用Caffe推理CenterNet(下篇)
Libtorch (torchscript)
libtorch是Pytorch的C++版,有着前端API和与Pytorch一样的自动求导功能,可以用于训练或者推理。

Pytorch训练出来的模型经过torch.jit.trace或者torch.jit.scrpit可以导出为.pt格式,随后可以通过libtorch中的API加载然后运行,因为libtorch是纯C++实现的,因此libtorch可以集成在各种生产环境中,也就实现了部署(不过libtorch有一个不能忽视但影响不是很大的缺点,限于篇幅暂时不详说)。
libtorch是从1.0版本开始正式支持的,如今是1.9版本。从1.0版本我就开始用了,1.9版本也在用,总的来说,绝大部分API和之前变化基本不大,ABI稳定性保持的不错!
libtorch适合Pytorch模型快速C++部署的场景,libtorch相比于pytorch的python端其实快不了多少(大部分时候会提速,小部分情况会减速)。在老潘的使用场景中,一般都是结合TensorRT来部署,TensorRT负责简单卷积层等操作部分,libtorch复杂后处理等细小复杂op部分。
基本的入门教程:
- 利用Pytorch的C++前端(libtorch)读取预训练权重并进行预测
- Pytorch的C++端(libtorch)在Windows中的使用
官方资料以及API:
- USING THE PYTORCH C++ FRONTEND
- PYTORCH C++ API
libtorch的官方资料比较匮乏,建议多搜搜github或者Pytorch官方issue,要善于寻找。
一些libtorch使用规范附:
- Load tensor from file in C++
TensorRT
TensorRT是可以在NVIDIA各种GPU硬件平台下运行的一个C++推理框架。我们利用Pytorch、TF或者其他框架训练好的模型,可以转化为TensorRT的格式,然后利用TensorRT推理引擎去运行我们这个模型,从而提升这个模型在英伟达GPU上运行的速度。速度提升的比例是比较可观的。
在GPU服务器上部署的话,TensorRT是首选!
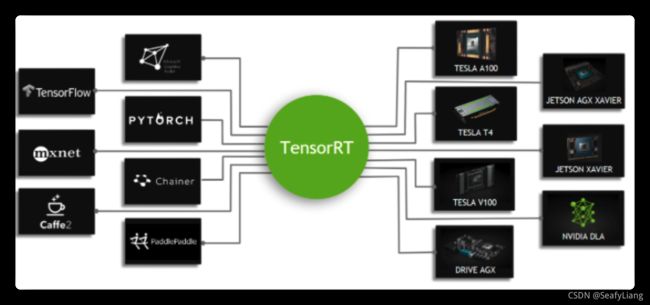
TensorRT老潘有单独详细的教程,可以看这里:
- TensorRT?超详细入门指北,来看看吧!
OpenVINO
在英特尔CPU端(也就是我们常用的x86处理器)部署首选它!开源且速度很快,文档也很丰富,更新很频繁,代码风格也不错,很值得学习。

在我这边CPU端场景不是很多,毕竟相比于服务器来说,CPU场景下,很多用户的硬件型号各异,不是很好兼容。另外神经网络CPU端使用场景在我这边不是很多,所以搞得不是很多。
哦对了,OpenVino也可以搭配英特尔的计算棒,亲测速度飞快。
详细介绍可以看这里:
- OpenVino初探(实际体验)
NCNN/MNN/TNN/TVM
有移动端部署需求的,即模型需要运行在手机或者嵌入式设备上的需求可以考虑这些框架。这里只列举了一部分,还有很多其他优秀的框架没有列出来…是不是不好选?
- NCNN
- MNN
- TNN
- TVM
- Tengine
个人认为性价比比较高的是NCNN,易用性比较高,很容易上手,用了会让你感觉没有那么卷。而且相对于其他框架来说,NCNN的设计比较直观明了,与Caffe和OpenCV有很多相似之处,使用起来也很简单。可以比较快速地编译链接和集成到我们的项目中。

TVM和Tengine比较复杂些,不过性能天花板也相比前几个要高些,可以根据取舍尝试。
相关链接:
- 一步一步解读神经网络编译器TVM(一)——一个简单的例子
- 一步一步解读神经网络编译器TVM(二)——利用TVM完成C++端的部署
PaddlePaddle
PaddlePaddle作为国内唯一一个用户最多的深度学习框架,真的不是盖。
很多任务都有与训练模型可以使用,不论是GPU端还是移动端,大部分的模型都很优秀很好用。
如果想快速上手深度学习,飞浆是不错的选择,官方提供的示例代码都很详细,一步一步教你教到你会为止。
最后说一句,国产牛逼。
还有很多框架
当然除了老潘这里介绍的这些,还有很多更加优秀的框架,只不过我没有使用过,这里也就不多评论了。
4.6 AI部署中的提速方法
老潘这一年除了训练模型,也部署了不少模型。虽然模型速度有提升,但仍然不够快,仍然还有很多空间去提升。
我的看法是,部署不光是从研究环境到生产环境的转换,更多的是模型速度的提升和稳定性的提升。稳定性这个可能要与服务器框架有关了,网络传输、负载均衡等等,老潘不是很熟悉,也就不献丑了。不过速度的话,从模型训练出来,到部署推理这一步,有什么优化空间呢?
上到模型层面,下到底层硬件层面,其实能做的有很多。如果我们将各种方法都用一遍(大力出奇迹),最终模型提升10倍多真的不是梦!
有哪些能做的呢?
- 模型结构
- 剪枝
- 蒸馏
- 稀疏化训练
- 量化训练
- 算子融合、计算图优化、底层优化
简单说说吧!
4.6.1 模型结构
模型结构当然就是探索更快更强的网络结构,就比如ResNet相比比VGG,在精度提升的同时也提升了模型的推理速度。又比如CenterNet相比YOLOv3,把anchor去掉的同时也提升了精度和速度。
模型层面的探索需要有大量的实验支撑,以及,脑子,我脑子不够,就不参与啦。喜欢白嫖,能白嫖最新的结构最好啦,不过不是所有最新结构都能用上,还是那句话,部署友好最好。
哦,还有提一点,最近发现另一种改变模型结构的思路,结构重参化。还是蛮有搞头的,这个方向与落地部署关系密切,最终的目的都是提升模型速度的同时不降低模型的精度。
之前有个比较火的RepVgg——Making VGG-style ConvNets Great Again就是用了这个想法,是工业届一个非常solid的工作。部分思想与很多深度学习推理框架的算子融合有异曲同工之处。
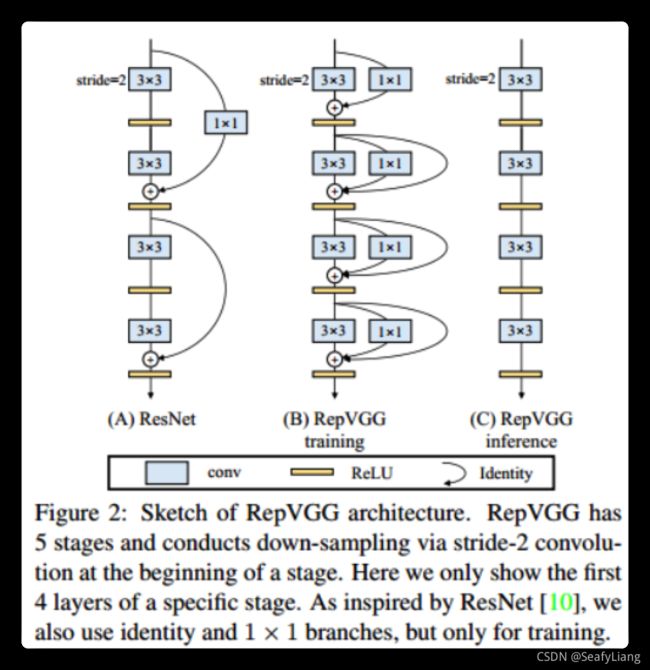
老潘也在项目中使用了repvgg,在某些任务的时候,相对于ResNet来说,repvgg可以在相同精度上有更高的速度,还是有一定效果的。
4.6.2 剪枝
剪枝很早就想尝试了,奈何一直没有时间啊啊啊。
我理解的剪枝,就是在大模型的基础上,对模型通道或者模型结构进行有目的地修剪,剪掉对模型推理贡献不是很重要的地方。经过剪枝,大模型可以剪成小模型的样子,但是精度几乎不变或者下降很少,最起码要高于小模型直接训练的精度。
积攒了一些比较优秀的开源剪枝代码,还咩有时间细看:
- yolov3-channel-and-layer-pruning
- YOLOv3-model-pruning
- centernet_prune
- ResRep
4.6.3 蒸馏
我理解的蒸馏就是大网络教小网络,之后小网络会有接近大网络的精度,同时也有小网络的速度。
再具体点,两个网络分别可以称之为老师网络和学生网络,老师网络通常比较大(ResNet50),学生网络通常比较小(ResNet18)。训练好的老师网络利用soft label去教学生网络,可使小网络达到接近大网络的精度。
印象中蒸馏的作用不仅于此,还可以做一些更实用的东西,之前比较火的centerX,将蒸馏用出了花,感兴趣的可以试试。
4.6.4 稀疏化
稀疏化就是随机将Tensor的部分元素置为0,类似于我们常见的dropout,附带正则化作用的同时也减少了模型的容量,从而加快了模型的推理速度。
稀疏化操作其实很简单,Pytorch官方已经有支持,我们只需要写几行代码就可以:
def prune(model, amount=0.3): # Prune model to requested global sparsity import torch.nn.utils.prune as prune print(‘Pruning model… ‘, end=’’) for name, m in model.named_modules(): if isinstance(m, nn.Conv2d): prune.l1_unstructured(m, name=‘weight’, amount=amount) # prune prune.remove(m, ‘weight’) # make permanent print(’ %.3g global sparsity’ % sparsity(model))
上述代码来自于Pruning/Sparsity Tutorial。这样,通过Pytorch官方的torch.nn.utils.prune模块就可以对模型的卷积层tensor随机置0。置0后可以简单测试一下模型的精度…精度当然是降了哈哈!所以需要finetune来将精度还原,这种操作其实和量化、剪枝是一样的,目的是在去除冗余结构后重新恢复模型的精度。
那还原精度后呢?这样模型就加速了吗?当然不是,稀疏化操作并不是什么平台都支持,如果硬件平台不支持,就算模型稀疏了模型的推理速度也并不会变快。因为即使我们将模型中的元素置为0,但是计算的时候依然还会参与计算,和之前的并无区别。我们需要有支持稀疏计算的平台才可以。
英伟达部分显卡是支持稀疏化推理的,英伟达的A100 GPU显卡在运行bert的时候,稀疏化后的网络相比之前的dense网络要快50%。我们的显卡支持么?只要是Ampere architecture架构的显卡都是支持的(例如30XX显卡)。
- Exploiting NVIDIA Ampere Structured Sparsity with cuSPARSELt
- How Sparsity Adds Umph to AI Inference
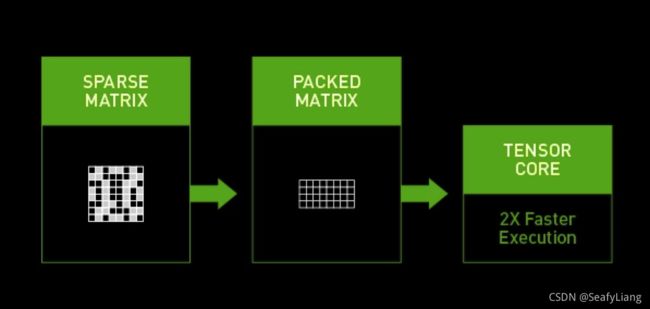
最近的TensorRT8是支持直接导入稀疏化模型的,目前支持Structured Sparsity结构。如果有30系列卡和TensorRT8的童鞋可以尝试尝试~
并且英伟达官方提供了基于Pytorch的自动稀疏化工具——Automatic SParsity,总的流程来说就是:
- 先拿一个完整的模型(dense),然后以一定的稀疏化系数稀疏化这个模型
- 然后基于这个稀疏化后的模型进行训练
- 将训练后的模型导出来即可
是不是很简单?
相关讨论:
- NVIDIA’s Tensor-TFLOPS values for their newest GPUs include sparsity
- Pruning BERT to accelerate inference
- Which GPU(s) to Get for Deep Learning: My Experience and Advice for Using GPUs in Deep Learning
- NVIDIA RTX 3080: Performance Test
4.6.4 量化训练
这里指的量化训练是在INT8精度的基础上对模型进行量化。简称QTA(Quantization Aware Training)。
量化后的模型在特定CPU或者GPU上相比FP32、FP16有更高的速度和吞吐,也是部署提速方法之一。
PS:FP16量化一般都是直接转换模型权重从FP32->FP16,不需要校准或者finetune。
量化训练是在模型训练中量化的,与PTQ(训练后量化)不同,这种量化方式对模型的精度影响不大,量化后的模型速度基本与量化前的相同(另一种量化方式PTQ,TensorRT或者NCNN中使用交叉熵进行校准量化的方式,在一些结构中会对模型的精度造成比较大的影响)。
举个例子,我个人CenterNet训练的一个网络,使用ResNet-34作为backbone,利用TensorRT进行转换后,使用1024×1024作为测试图像大小的指标:
| 精度/指标 | FP32 | INT8(PTQ) | INT8(QTA) |
|---|---|---|---|
| AP | 0.93 | 0.83 | 0.94 |
| 速度 | 13ms | 3.6ms | 3.6ms |
精度不降反升(可以由于之前FP32的模型训练不够彻底,finetune后精度又提了一些),还是值得一试的。
目前我们常用的Pytorch当然也是支持QTA量化的。
不过Pytorch量化训练出来的模型,官方目前只支持CPU。即X86和Arm,具有INT8指令集的CPU可以使用:
- x86 CPUs with AVX2 support or higher (without AVX2 some operations have inefficient implementations)
- ARM CPUs (typically found in mobile/embedded devices)
已有很多例子。
相关文章:
- PyTorch Quantization Aware Training
- Pytorch QUANTIZATION
那么GPU支持吗?
Pytorch官方不支持,但是NVIDIA支持。
NVIDIA官方提供了Pytorch的量化训练框架包,目前虽然不是很完善,但是已经可以正常使用:
- NVIDIA官方提供的pytorch-quantization-toolkit
利用这个量化训练后的模型可以导出为ONNX(需要设置opset为13),导出的ONNX会有QuantizeLinear和DequantizeLinear两个算子:
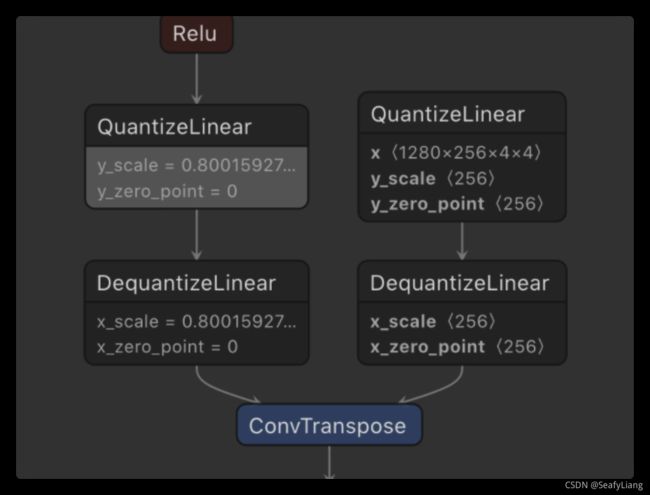
带有QuantizeLinear和DequantizeLinear算子的ONNX可以通过TensorRT8加载,然后就可以进行量化推理:
Added two new layers to the API: IQuantizeLayer and IDequantizeLayer which can be used to explicitly specify the precision of operations and data buffers. ONNX’s QuantizeLinear and DequantizeLinear operators are mapped to these new layers which enables the support for networks trained using Quantization-Aware Training (QAT) methodology. For more information, refer to the Explicit-Quantization, IQuantizeLayer, and IDequantizeLayer sections in the TensorRT Developer Guide and Q/DQ Fusion in the Best Practices For TensorRT Performance guide.
而TensorRT8版本以下的不支持直接载入,需要手动去赋值MAX阈值。
相关例子:
- ResNet-50 v1.5 for TensorFlow
- BERT Inference Using TensorRT
- Questions about int8 inference procedure
4.7 常见部署流程
假设我们的模型是使用Pytorch训练的,部署的平台是英伟达的GPU服务器。
训练好的模型通过以下几种方式转换:
- Pytorch->ONNX->trt onnx2trt
- Pytorch->trt torch2trt
- Pytorch->torchscipt->trt trtorch
其中onnx2trt最成熟,torch2trt比较灵活,而trtorch不是很好用。三种转化方式各有利弊,基本可以覆盖90%常见的主流模型。
遇到不支持的操作,首先考虑是否可以通过其他pytorch算子代替。如果不行,可以考虑TensorRT插件、或者模型拆分为TensorRT+libtorch的结构互相弥补。trtorch最新的commit支持了部分op运行在TensorRT部分op运行在libtorch,但还不是很完善,感兴趣的小伙伴可以关注一下。
常见的服务部署搭配:
- triton server + TensorRT/libtorch
- flask + Pytorch
- Tensorflow Server
4.8 后记
来北京工作快一年了,做了比较久的AI相关的训练部署工作,一直处于快速学习快速输出的状态,没有好好总结一下这段时间的工作内容和复盘自己的不足。所以趁着休息时间,也回顾一下自己之前所做的东西,总结一些内容和一些经验罢。同时也是抛砖引玉,看看大家对于部署有没有更好的想法。
AI部署的内容还是有很多,这里仅仅是展示其中的冰山一角,对于更多相关的内容,可以关注老潘一起交流哈。
看了上述介绍,如果不确定自己的方向的,可以先打打基础,先看看C++/python等,基础工具熟悉了,之后学习起来会更快。
先这样,我是老潘,我们下期见~
五、算法模型在服务端的部署
来自:算法模型在服务端的部署
title: 谈谈算法模型在服务端的部署 excerpt_separator: categories: - 工程杂谈 tag: - 推理部署 - 工程实践 date: 2021-01-04
谈谈算法模型在服务端的部署
弄算法模型在服务端部署方面的东西,最近有点思考,先随便记录一下,以后再做进一步的整理。
5.1 关于模型部署框架的两大类型
算法模型的部署主要可以分成两个方面。一是在移动端/设备端的部署,比较偏嵌入式。另一个是云端/服务端,和其他云端服务的部署比较相似(但也有自己的特点),这里我们主要聊聊后者
关于模型的云端部署,业界也有许多开源的解决方案,但目前为止来看,还没有一种真的可以一统业界,或者说称得上是绝对主流的方案。
针对云端部署的框架里,我们可以大致分为两类,一种是主要着力于解决推理性能,提高推理速度的框架,这一类里有诸如tensorflow的tensorflow serving、NVIDIA基于他们tensorRt的Triton(原TensorRt Serving),onnx-runtime等,这一类框架基本都是基于C++, 将模型转化为某一特定形式(转化的过程中可能伴有一些优化的操作), 再以C++载入,并对外提供服务,以此来获得相对较高的性能。
另一类框架主要着眼于结合模型整个生命周期,对模型部署进行管理,比如mlflow、seldon、bentoml、cortex等等,这些框架的设计与思路其实五花八门,有的为了和训练部分接轨,把模型文件管理也纳入了。有的则是只管到容器编排的部分,用户需要自己做好容器,它帮你发到k8s上之类的(这种情况甚至能和第一类框架连起来用)。当然也有专注于模型推理这一小块的。
5.2 关于两种类型的成因思考
我个人觉得之所以业界会出现这两类设计思路完全不同,但都自称是“模型推理服务框架”的工具,主要原因是因为我们在模型推理服务这个问题上,主要有两个不同的需求/问题:
- 从模型训练到模型服务部署过程中的工作量问题。
- 模型推理服务的性能问题
这两个问题有时候会互相牵制,假设我们要优化模型训练到服务部署的过程,最简便的方式无疑是仍旧使用python加载模型,和算法同学在训练部分写的代码保持一致,但python作为http或者grpc服务的性能就需要想办法解决。
而如果全部转成用c++提供服务,对训练好的模型进行转化,使其能被c++服务的使用又成为额外的一步。tensorflow serving就是这里有优势,只要是tf的模型,它都可以直接使用。但对于大量的pytorch使用者来说,这里并没有如tensorflow serving 一样简易的解决方案。
5.3 那么请问……
那么请问有没有一种既能够照顾到使用的简易性,又能够获得很好服务性能的框架呢!?
……很抱歉,目前看来是真的还没有,不过我个人经过这段时间的思考,我想出来的解决方案是这样的。就是通过区分不同的场景,分别处理模型的服务端部署。
对性能要求不高的模型,我们可以直接使用python框架部署,便于模型训练与部署之间的对接(当然性能优化也要做,这块的性能优化做的好了,能够减轻很多工作量,bentoml等框架也是有对模型的python部署做优化的)。而对性能要求高的,我们再进入模型转化的流程。
5.4 关于我们目前的解决方案
目前我的解决方案也比较类似,我们是基于k8s进行容器化的模型部署的。对于直接使用python部署的模型来说,我们通过集群训练之后,注册保存模型文件,需要部署时直接通过k8s将模型文件挂载到推理服务的容器中,进行加载。
对于另一类需要额外转换操作的模型,我们则是提供了转换任务,将已有的模型挂载到转换任务中,执行转化操作,再将结果保存为新模型,然后用于其他方式的部署(主要是移动端的部署)
目前整个系统里我们主要做的是基于集群的训练任务(这块跟模型部署关系不大,不过我们本来就打算做),模型管理服务,以及可自定义的模型Http服务。
5.5 为啥不上Kubeflow
有的同学可能会问,你整这么一整套下来,为啥不直接用kubeflow呢?问的好,一个原因是我开始整这玩意的时候kubeflow还没到1.0,我当时尝试过用它,但简直就是地狱,根本搞不到文档,还要去找他们藏在不知道哪个讨论组里的开发规划来看才知道到底他们在想什么。
当然更重要的一个原因是kubeflow我用下来觉得实在太重型,它一下子囊括太多东西了,而且还不好拆分。假设你对istio等部分有自己的想法,或者有定制化的需求的话,其实会弄得很麻烦很痛苦。
而我开发现在这套东西的时候一个想法就是,可以把它们凑在一起用,这样能获得最好的联动效果,熟悉之后会非常便利,但是假如有的部分不需要,或者自己有其他的替代品,也可以完全拆分开来使用。就算没有训练、没有模型管理,依然可以上传文件直接部署,或者提交一个镜像来部署。做到尽可能低的依赖。
其实我理想里是甚至可以不需要k8s都可以跑,但是从开发时间上考虑还是优先解决k8s的版本。