r语言task01笔记
数据结构和数据集
算术
计算符号包括加+、减-、乘*、除/、求幂^以及求余数%%等。值得一提的是开平方根有他自己单独的函数sqrt

赋值
将数字42赋予名叫x的变量
x <- 42
在r中运行一个物体的名字
r将会打印出物体的值
x
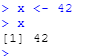
- 基础赋值的符号
- 一个向左的箭头
<-表示将箭头右方的值取名叫做箭头左侧的名字,或者将箭头右侧的值存储在箭头左侧的名字里; - 一个向右的箭头
->表示将箭头左侧的值储存在箭头右侧的名字里; - 一个等号
=表示将箭头右侧的值存储在箭头左侧的名字里
大多数情况下都推荐使用箭头
原因如下
- 箭头明确了赋值方向,这是等号做不到的;
- 等号用在顶层环境中的时候是赋值,用在函数中则是设参(或者叫做在函数层面赋值)。这种二义性不小心区分则可能会引发错误。而等号即使用在函数中也是赋值;
- 箭头可以做到多次赋值(
a <- b <- 42)甚至是不同方向上多次赋值(a <- 42 -> b)(尽量避免!); - 虽然这次组队学习中不会学到,但是更高级的赋值工具包括
<<-和->>对应向左或向右的箭头; - 同时使用
=与==(判断是否相等)会降低可读性(a <- 1 == 2vsa = 1 == 2)。
凡是赋值都用<-,凡是设参都用=。

函数
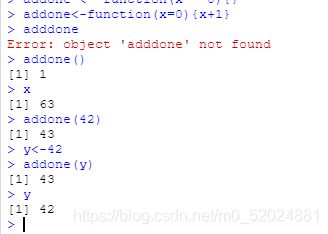
如你可见,调用函数的方法就是在函数的名字后边加小括号,再在小括号中输入参数(arguments)。当函数有多个可选参数的时候,建议输入参数的时候使用等号=明确函数名称。这便是之前提到过的等号的设参用法。

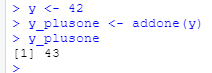
tidyverse也包含了管道符号
library(tidyverse)
x %>%
addone() %>%
addtwo() %>%
addthree()
等价于
addthree(addtwo(addone(x)))
%>%这个符号函数进行方法链(method chain)的操作。你可以把这个符号叫做管道。

-
在R中有五种基础数据类型,包括三个数值型、一个逻辑型和一个字符型。
-
数值型数据包括三种,分别是默认的实数数值型数据(double)、整数类型(integer)和复数类型(complex)
-
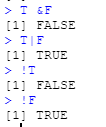
说到逻辑型数据,就不得不说到逻辑算符。这里我们只考虑三个,分别是“和”(and)
&、“或”(or)|、“否”(not)!。 -
判断一个数值是什么类型,可以用
typeof():


-
即使是数字或者逻辑型的
TRUE和FALSE,只要加上了引号,他们就变成了字符型的数据,而不再带有数值型或逻辑型的特性。要注意区分 -
任何其他的数据类型也可以转化为字符型数据
-
推荐大多数情况下使用双引号,只有在引号内有双引号的时候使用单引号去引双引号
向量

- 向量是由一组相同类型的值组成的一维序列。根据值的类型不同,我们会有不同类型的向量。
- 向量类型便是因子,可以使用函数
factor和c组合来创建
也有相应的作用于向量上的函数,可以计算相应的统计量。比如求和的sum、求方差的var、平均值的mean等

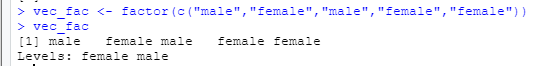
数ordered或者factor里的ordered = TRUE参数(argument)创造一个有内在顺序的因子向量,内在顺序可以用levels参数来手动设定

- 用因子向量替代字符向量可以剩下很多字节
数值之间的转换
自由程度排序(取决于复杂度)
字符>数值>逻辑
复数>实数>整数
自由度低的类型可以(随意)转化为同层或自由度更高的类型
vec_loc <- c(TRUE, FALSE, TRUE)
从逻辑型到数值型
vec_num <- as.numeric(vec_loc)
vec_num
从数值型到字符型
vec_cha <- as.character(vec_num)
vec_cha
从逻辑型到字符型
vec_cha2 <- as.character(vec_loc)
vec_cha2
从字符型到数值型
as.numeric(vec_cha)
从字符型到逻辑型
as.logical(vec_cha2)
从数值型到逻辑型
as.logical(vec_num)
因子型是一个相对特殊的类型,它可以和数值型与字符型相互转
vec_fac <- factor(c(“male”, “female”, “male”, “female”, “female”))
从因子型到数值型
vec_num <- as.numeric(vec_fac)
vec_num
从因子型到字符型
vec_cha <- as.character(vec_fac)
vec_cha
从字符型到因子型
as.factor(vec_cha)
从整数型到字符型
as.factor(vec_num)
一个低自由的类型可以随便转化到高自由的类型
一个高自由的类型要转化到一个低自由的类型必须要符合一些特定值
- 从字符型转化到数值型的时候,字符的值一定要符合数字的格式;
- 从数值型转化到逻辑型,0会转化为
FALSE,其他数值会转化为TRUE; - 从字符型转化到逻辑型,字符的值只能是
TRUE和FALSE。
不符合这个规则的话,会得到NA(缺失值)
- 因子向量变成字符向量会丢失独特值的信息;
- 因子向量变成数值型的时候会丢失字面信息,只会保留独特值的编码,即根据独特值排序的正整数。
可以给向量里的每个元素一个名字
- 先命名向量
再命名向量的元素
vec <- c(1, 2, 3)
names(vec) <- c(“A”, “B”, “C”)
vec
2.创造向量的时候命名向量的元素
vec <- c(A = 1, B = 2, C = 3)
vec
访问向量的子集
三种截取子集的符号:[、[[ 和 $(其中$不能用在基础向量上)
- 正整数:根据元素的序号提取元素;
- 负整数:根据元素的序号去除元素;
- 和向量长度一样的逻辑向量:将逻辑向量的元素与向量元素一一对应,
TRUE选择该元素,FALSE去除该元素; - Nothing:选择原向量;
- 零(0):什么都不选择;
- 字符向量:选择根据元素名字选择元素。

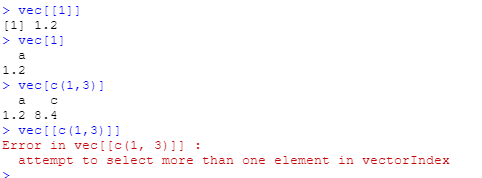
[[ 在向量的场景里只能选择一个元素,而不是像[ 一样选择一个子集:
# 可以
vec[[1]]
vec[1]
vec[c(1, 3)]
# 不可以
vec[[c(1, 3)]]
特殊数据类型
日期(date)
日期处理的包lubridate
library(lubridate)
载入程辑包:‘lubridate’
The following objects are masked from ‘package:base’:
date, intersect, setdiff, union
日期的特殊类型Date,有日期-时间类型的POSIXct和POSIXlt
年月日ymd函数:把输入的字符串自动识别并输出日期格式的数值
> sevenseven <- ymd("2021-07-07")
> sevenseven
[1] "2021-07-07"
> typeof(sevenseven)
[1] "double"
/*可以把这个日期当作一个单纯的数来计算*/
> sevenseven + 1
[1] "2021-07-08"
> class(sevenseven)
[1] "Date"
- additional
lubridate也提供相应的 月年日myd,日月年dmy,月日年mdy,日年月dym,甚至是 年季yq的函数
(https://lubridate.tidyverse.org/)
时间序列(ts)
制造时间序列的函数叫做ts,( time series)
# 起始日期
start(xts)
# 结束日期
end(xts)
# 周期性
frequency(xts)
> xts <- ts(rnorm(12),start = c(2021,1),frequency = 4)
> xts
Qtr1 Qtr2 Qtr3 Qtr4
2021 -0.65013780 -0.03025394 -0.14425341 -0.33057728
2022 -0.18676210 0.34422483 -1.21659117 -0.10421384
2023 -2.25556947 1.82235835 -0.22406460 0.77173738
example
使用forecast包来用一个 ARIMA 模型对澳大利亚燃气月生产量进行预测
library(forecast)
gas %>%
auto.arima() %>%
forecast(36) %>%
autoplot()
时间序列的分析与预测的更多信息可见tidyverts系列包
矩阵是一个按照长方阵列排列的、有着固定行数和列数的、包含同一类型数据的集合
- 要求包含的数据从属于同一类型
> matrix(1:9, nrow = 3)
[,1] [,2] [,3]
[1,] 1 4 7
[2,] 2 5 8
[3,] 3 6 9
> mat_month <- matrix(month.name, nrow = 4, byrow = TRUE)
> mat_month
[,1] [,2] [,3]
[1,] "January" "February" "March"
[2,] "April" "May" "June"
[3,] "July" "August" "September"
[4,] "October" "November" "December"
# 矩阵命名
#对于一个矩阵来说,主要的命名集中于行名`rownames`和列名`colnames`
> rownames(mat_month) <- c("Quarter1", "Quarter2", "Quarter3", "Quarter4")
> colnames(mat_month) <- c("Month1", "Month2", "Month3")
> mat_month
Month1 Month2 Month3
Quarter1 "January" "February" "March"
Quarter2 "April" "May" "June"
Quarter3 "July" "August" "September"
Quarter4 "October" "November" "December"
> **rownames**(mat_month)
[1] "Quarter1" "Quarter2" "Quarter3" "Quarter4"
> **colnames**(mat_month)
[1] "Month1" "Month2" "Month3"
> **dimnames**(mat_month)
[[1]]
[1] "Quarter1" "Quarter2" "Quarter3" "Quarter4"
[[2]]
[1] "Month1" "Month2" "Month3"
#访问矩阵子集
> mat_month[[1, 2]]
[1] "February"
> mat_month[1, 2]
[1] "February"
> mat_month[,2]
Quarter1 Quarter2 Quarter3 Quarter4
"February" "May" "August" "November"
> mat_month[1,]
Month1 Month2 Month3
"January" "February" "March"
> mat_month[["Quarter1", "Month3"]]
[1] "March"
> mat_month["Quarter1", "Month3"]
[1] "March"
list列表
在一个列表中可以储存各种不同的基本数据类型
列表甚至可以储存列表本身
> list(1, 2, 3)
[[1]]
[1] 1
[[2]]
[1] 2
[[3]]
[1] 3
> list(1, "lol", TRUE)
[[1]]
[1] 1
[[2]]
[1] "lol"
[[3]]
[1] TRUE
## 列表存取列表本身
stuff <- list(
+ list(
+ 1:12,
+ "To be or not to be",
+ c(TRUE, FALSE)),
+ 42,
+ list(
+ list(
+ ymd("2021-07-07"),
+ "remembrance"),
+ 2L+3i)
+ )
> stuff
[[1]]
[[1]][[1]]
[1] 1 2 3 4 5 6 7 8 9 10 11 12
[[1]][[2]]
[1] "To be or not to be"
[[1]][[3]]
[1] TRUE FALSE
[[2]]
[1] 42
[[3]]
[[3]][[1]]
[[3]][[1]][[1]]
[1] "2021-07-07"
[[3]][[1]][[2]]
[1] "remembrance"
[[3]][[2]]
[1] 2+3i
列表同样可以用中括号来访问子列表
单个中括号返回的列表元素类型还是列表,双中括号返回的列表元素是它本身的类型
返回多个子列表,只能用单括号
> # 返回前两个子列表
> stuff[1:2]
[[1]]
[[1]][[1]]
[1] 1 2 3 4 5 6 7 8 9 10 11 12
[[1]][[2]]
[1] "To be or not to be"
[[1]][[3]]
[1] TRUE FALSE
[[2]]
[1] 42
> # 返回第一个子列表中的第二个子列表
> stuff[[1]][[2]]
[1] "To be or not to be"
列表命名
> # 返回第一个子列表中的第二个子列表
> stuff[[1]][[2]]
[1] "To be or not to be"
> # 给列表的顶层三个列表命名
> names(stuff) <- c("I", "II", "III")
> # 给列表的第一个列表里的三个子列表命名
> names(stuff[[1]]) <- c("I", "II", "III")
> stuff
$I
$I$I
[1] 1 2 3 4 5 6 7 8 9 10 11 12
$I$II
[1] "To be or not to be"
$I$III
[1] TRUE FALSE
$II
[1] 42
$III
$III[[1]]
$III[[1]][[1]]
[1] "2021-07-07"
$III[[1]][[2]]
[1] "remembrance"
$III[[2]]
[1] 2+3i
> stuff[["I"]][["II"]]
[1] "To be or not to be"
>stuff$I$II
[1] "To be or not to be"
#两种方法都可以用
> stuff[["II"]][["II"]]
Error in stuff[["II"]][["II"]] : subscript out of bounds
> stuff[["III"]][["II"]]
NULL
数据表
一个数据表(data frame)的本质是一个列表(list),但是采取了矩阵(matrix)的展示形式
> df <- data.frame(x = 1:12, y = month.abb(缩写), z = month.name(名字))
> df
x y z
1 1 Jan January
2 2 Feb February
3 3 Mar March
4 4 Apr April
5 5 May May
6 6 Jun June
7 7 Jul July
8 8 Aug August
9 9 Sep September
10 10 Oct October
11 11 Nov November
tibble是tidyverse系列包中的tibble包提供的一种数据形式。使用tibble好处是,当你把tibble打印在控制台里的时候,它有直观的打印方式。与 data frame 打印所有的行,tibble 默认只会打印前几行数据,每一列的数据的类型
> tb <- tibble(a = 1:100, b = 101:200)
> tb
# A tibble: 100 x 2
a b
<int> <int>
1 1 101
2 2 102
3 3 103
4 4 104
5 5 105
6 6 106
7 7 107
8 8 108
9 9 109
10 10 110
# ... with 90 more rows
- 可以用适用于矩阵和列表的方法访问数据表元素
> df[["x"]]
[1] 1 2 3 4 5 6 7 8 9 10 11 12
> df$x
[1] 1 2 3 4 5 6 7 8 9 10 11 12
> df[1, 2]
[1] "Jan"
>
> tb[, 2]
# A tibble: 100 x 1
b
<int>
1 101
2 102
3 103
4 104
5 105
6 106
7 107
8 108
9 109
10 110
# ... with 90 more rows
> tb[1, 2]
# A tibble: 1 x 1
b
<int>
1 101
> tb$a
[1] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
[18] 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34
[35] 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51
[52] 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68
[69] 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85
[86] 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100
- tibble 其访问的子列表也是
tibble类型的数据表,即使用单引号返回一个格子的元素。
内置数据集
data()命令查看
data(package = “dplyr”)某一R包自带的数据集
载入AirPassengers数据集
data(“AirPassengers”)
glimpse(AirPassengers)
结果: Time-Series [1:144] from 1949 to 1961: 112 118 132 129 121 135 148 148 136 119 …
不建议在R中直接编辑 excel 文件,csv 文件应该满足日常所需了。如果有编辑 excel 文件的需求,可以看看openxlsx包
读取csv文件
library(readr)
h1n1_flu <- read_csv(“h1n1_flu.csv”)
保存csv文件
write_csv(h1n1_flu, “h1n1_flu.csv”)
读取excel文件
library(readxl)
自动识别文件后缀
h1n1_flu <- read_excel(“h1n1_flu.xls”)
读取xls文件
h1n1_flu <- read_xls(“h1n1_flu.xls”)
读取xlsx文件
h1n1_flu <- read_xlsx(“h1n1_flu.xlsx”)
特有的数据类型
这里讨论两类。一类是 rds 文件,一类是 RData 文件。
- rds 文件储存一个R中的对象。这个对象不一定是四四方方的数据表,而可以是任何形式,包括复杂的列表等。因为他储存的是一个对象,所以读取的时候也是读取出来一个对象,需要被保存在一个名字下。
- RData 储存的是一个或多个、任意结构的、带有自己名字的对象。读取的时候会将储存的对象直接载入当前的环境中,使用的是对象自己的名字,所以不需要再额外起名字。
读取rds
h1n1_flu <- read_rds(“h1n1_flu.rds”)
存储rds
write_rds(h1n1_flu, “h1n1_flu.rds”)
读取rdata
load(“h1n1_flu.RData”)
存储rdata
save(h1n1_flu, file = “h1n1_flu.RData”)
R也可以直接读取其他软件的数据类型。这里列举使用haven包读写 SPSS 的 sav 和 zsav、 Stata 的 dta、SAS 的 sas7bdat 和 sas7bcat。
library(haven)
# SPSS
read_spss()
write_spss()
# Stata
read_dta()
write_dta()
# SAS
read_sas()
write_sas()