python机器学习模块
关于ML (All About ML)
Python is one of the best programming choices for data science, machine learning, and deep learning. Python presents a wide array of choices for the completion of each task. It is highly accessible and one of the best ways to get started with programming because it is fairly simple to use as well as quite easy to learn. It also has a great community with constant updates and upgrades. At the writing of this article, the most recent version of python is 3.8.
P ython是数据科学,机器学习和深度学习的最佳编程选择之一。 Python为完成每个任务提供了多种选择。 它非常易于访问,并且是使用入门的最佳方法之一,因为它使用起来既简单又容易学习。 它还拥有一个不断更新和升级的强大社区。 在撰写本文时,python的最新版本是3.8。
This article assumes the viewers have slight or modest programming knowledge as well as understand a bit of python. If you have no prior programming knowledge then don’t worry. Python is extremely easy to get started with and there are tons of free videos available on YouTube as well as lots of interesting tutorials on the web. Feel free to let me know if you guys want me to make a python basics tutorial from scratch. With just a basic understanding of python, we can continue to understand more about this amazing language along with all the extensions and libraries beneficial for machine learning.
本文假定查看者具有一点或一点点的编程知识,并且了解一些python。 如果您没有任何编程知识,那就不用担心。 Python非常容易上手,YouTube上提供了许多免费视频以及网络上许多有趣的教程。 如果您希望我从头开始编写python基础教程,请随时告诉我。 仅对python有一个基本的了解,我们就可以继续对这种令人惊叹的语言以及有益于机器学习的所有扩展和库有更多了解。
Note: This will be part-2 of my “All About Machine Learning” course. However, each subsequent parts will be standalone parts. You can read the series in any order as per your convenience. I will try to cover the basics and most of the machine learning algorithms in the upcoming articles. To view other parts of the series you can click here. Check out the previous article from the below link if you haven’t already.
注意:这将是我的“关于机器学习的全部”课程的第2部分。 但是,每个后续部分将是独立的部分。 您可以根据需要以任何顺序阅读该系列。 在接下来的文章中,我将尝试介绍基础知识和大多数机器学习算法。 要查看系列的其他部分,请单击此处 。 如果还没有,请从下面的链接中查看上一篇文章。
You can download python from the link below.
您可以从下面的链接下载python。
您对本文有什么期待? (What can you expect from this article?)
Today, we will be looking into all the essential basic concepts of python required for machine learning. We will understand the various data structures of python and then proceed to dig deeper into the basics of all the libraries which are required for machine learning. We will cover all these concepts with some simple code snippets to gain a better grasping of these libraries and features. So, without further ado, let us get our hands dirty with some coding!
今天,我们将研究机器学习所需的所有python基本概念。 我们将了解python的各种数据结构,然后继续更深入地研究机器学习所需的所有库的基础。 我们将通过一些简单的代码片段覆盖所有这些概念,以更好地理解这些库和功能。 因此,事不宜迟,让我们开始编写一些代码吧!

Python中的数据结构: (Data Structures in Python:)
Data Structures are a collection of data elements that are structured in some way. There are many built-in data structures in python. Let us explore each of these individually.
数据结构是以某种方式结构化的数据元素的集合。 python中有许多内置数据结构。 让我们分别探讨每个。
1.清单— (1. Lists —)
A list is a mutable ordered sequence of elements. Mutable means that the list can be modified or changed. Lists are enclosed within Square Brackets ‘[ ]’. The important functions which we use for the list in python for machine learning are — ‘append’ which is used to add elements to the list, the ‘len’ function to find the length of the lists, and the ‘sort’ function to arrange the elements in the list in ascending order. These 3 are usually the most common functions which will be used for lists. List slicing is another concept that is very useful to understand. The list elements can be addressed by their index numbers. The 0th index consists of the first element, the 1st index consists of the second element, and so on.
列表是元素的可变有序序列。 可变意味着可以修改或更改列表。 列表包含在方括号“ []”中。 我们在python中用于机器学习的列表中使用的重要函数是-“ append”(用于向列表中添加元素),“ len”函数(用于查找列表的长度)和“ sort(排序)”函数以进行排列列表中的元素以升序排列。 这3个通常是最常用的功能,将用于列表。 列表切片是另一个非常有用的概念。 列表元素可以通过其索引号进行寻址。 第0个索引由第一个元素组成,第一个索引由第二个元素组成,依此类推。
The other important concept concerning lists is the list comprehension. This is used to simplify code by providing a concise way to create the lists. An example of creating the squares up to 10 can be done as follows:
关于列表的另一个重要概念是列表理解 。 通过提供创建列表的简洁方法,此代码可用于简化代码。 可以创建一个最多10个正方形的示例,如下所示:
squares = [i**2 for i in range(10)]
print(squares)You can also create a list within a list called nested lists. These are usually helpful for matrix operations in machine learning.
您还可以在称为嵌套列表的列表中创建列表 。 这些通常有助于机器学习中的矩阵运算。
2.字典— (2. Dictionary —)
A dictionary is an unordered collection of items. Unlike lists and other data structures like tuples or sets, the dictionary data structure has a pair of elements referred to as key and value. The dict() function can be used to assign a dictionary to a variable. An alternative approach is to use the curly braces ‘{}’ to assign a variable as a dictionary. After defining a dictionary, we have mainly three functions — The items function to view both the keys and the values of the dictionary, the keys function to access the keys of the dictionary and the values function to access all the values of the respective keys. The dictionary function can be even used to build data frames for the pandas library. It is one of the more important data structures alongside lists. The below example shows how to declare a dictionary and access all the variables in the dictionary.
字典是项目的无序集合。 与列表和其他数据结构(如元组或集合)不同,字典数据结构具有一对称为键和值的元素。 dict()函数可用于将字典分配给变量。 另一种方法是使用大括号“ {}”将变量分配为字典。 定义字典后,我们主要具有三个功能- 项目功能可同时查看键和字典的值, 键功能可访问字典的键,而值功能可访问相应键的所有值。 词典功能甚至可以用于为熊猫库构建数据框。 它是列表旁边最重要的数据结构之一。 下面的示例显示如何声明字典并访问字典中的所有变量。
dictionary = {'1': 'Apple',
'2': 'Oranges',
'3': 'Grapes'}
print("The items are: ", dictionary.items())
print("The keys are: ", dictionary.keys())
print("The values are: ", dictionary.values())
3.元组— (3. Tuples —)
The tuple data structure is similar to the list data structure where you can define a tuple with a fixed number of elements. The only difference is that tuples are immutable. This prevents any modification of the elements within a tuple as more elements can’t be appended or removed from the specific tuple that is created. The tuples can be created either by specifying the tuple function or by using the normal brackets ‘()’. The procedure of accessing an element in a tuple can be done by accessing its specific index position similar to a list. It is also possible to create a nested tuple i.e. a tuple of elements within a tuple. The main advantage of the tuple data structure is that it can be suited to define (X, Y) points on a graph such that those points remain consistent throughout the program and cannot be altered. Let us look at an example of nested tuples, with the main tuple containing two more tuples in the form of ((x1, y1)) and (x2, y2). Let us look at how exactly we can access the y1 element of the tuple as shown from the below code block.
元组数据结构类似于列表数据结构,在列表数据结构中,您可以定义具有固定数量元素的元组。 唯一的区别是元组是不可变的。 这样可以防止对元组中的元素进行任何修改,因为无法从创建的特定元组中追加或删除更多元素。 可以通过指定元组函数或使用常规方括号'()'创建元组。 访问元组中元素的过程可以通过访问类似于列表的特定索引位置来完成。 也可以创建嵌套的元组,即元组内的元素元组。 元组数据结构的主要优点在于,它适合于在图形上定义(X,Y)点,以使这些点在整个程序中保持一致,并且不能更改。 让我们看一个嵌套元组的示例,主元组包含另外两个((x1,y1))和(x2,y2)形式的元组。 让我们看看如何精确地访问元组的y1元素,如下面的代码块所示。
tuples = ((1,2), (3,4))
# Consider this as (X1, Y1) and (X2, Y2).
# To Access Y1 you can perfrom the below indexing
tuples[0][1]The output for the above code block would be 2 which is y1 and the element we want to access.
上面的代码块的输出为2,即y1和我们要访问的元素。
4.套装- (4. Sets —)
A set is a collection of unordered elements. These elements are not indexed as well. Sets can be defined by using the set function or by using the curly braces ‘{}’ with only one element. The set data structures are mutable as elements can be added or removed but the sets only contain one of each element. Duplicates of elements cannot be repeated in a set and a set is always in sorted order. The sorting is done from the smallest to biggest meaning i.e. in ascending order. Sets can be used to perform mathematical set operations like union, intersection, symmetric difference, etc. Below is a code block showing the simple working of a set.
集合是无序元素的集合。 这些元素也未索引。 可以通过使用set函数或仅使用一个元素的大括号“ {}”来定义集合。 集合数据结构是可变的,因为可以添加或删除元素,但是集合仅包含每个元素之一。 元素的重复项不能在集合中重复,并且集合始终按排序顺序。 排序从最小到最大(即升序)进行。 集合可用于执行数学集合操作,例如并集,交集,对称差等。下面的代码块显示了集合的简单工作。
s = set([1, 5, 3, 6, 2])
print(s)The other data structures are strings and frozen sets. Most viewers would have learned about strings while learning the basics of python. I will cover strings briefly but I have personally not used frozen sets a lot in my machine learning projects as I do not find it that useful. If you are interested in knowing more about these then please feel free to learn about them as well.
其他数据结构是字符串和冻结集 。 大多数观众在学习python的基础知识的同时也会了解字符串。 我将简要介绍字符串,但是我个人没有在我的机器学习项目中经常使用冻结集,因为我认为它没有用。 如果您有兴趣进一步了解这些内容,请随时学习它们。
Strings can be defined in single quotes ‘ ’ or double quotes “ ”. Strings are an immutable sequence of characters. Computers do not deal with characters. Instead, they deal with numbers, especially in binary. Even though you may see characters on your screen, internally it is stored and manipulated as a combination of 0’s and 1’s. This conversion of character to a number is called encoding, and the reverse process is decoding. American Standard Code for Information Interchange (ASCII) and Unicode are some of the popular encoding used. In Python, the string is a sequence of Unicode characters. The usual formatting technique that is used by strings for the encoding is the UTF-8 standard which is represented with bytes.
字符串可以用单引号“”或双引号“”定义。 字符串是字符的不可变序列。 计算机不处理字符。 相反,它们处理数字,尤其是二进制数字。 即使您可能在屏幕上看到字符,它在内部也被存储和处理为0和1的组合。 字符到数字的这种转换称为编码,相反的过程是解码。 美国信息交换标准码(ASCII)和Unicode是一些常用的编码。 在Python中,字符串是Unicode字符序列。 字符串用于编码的常用格式设置技术是UTF-8标准,以字节表示。

python中用于机器学习的基本重要库: (Basic important libraries in python for machine learning:)
1.熊猫- (1. Pandas —)
The Pandas module is an open-source library in python to create data frames which is extremely useful for organizing the data. Pandas is used extensively in the field of data science, machine learning, and deep learning for the structured arrangement of the data. The data frame created in pandas is a 2-dimensional representation of the data. After importing the pandas library as pd you can visualize the tabular data of your liking. An example of this is as shown below:
Pandas模块是python中的一个开放源代码库,用于创建数据框,这对于组织数据非常有用。 Pandas在数据科学,机器学习和深度学习领域中广泛用于数据的结构化安排。 用熊猫创建的数据框是数据的二维表示。 将pandas库导入为pd之后,您可以可视化自己喜欢的表格数据。 一个示例如下所示:
data = pd.read_csv("fer2013.csv")
data.head()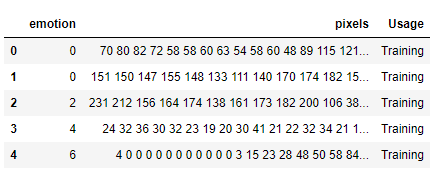
Overall, the pandas module is a fantastic library for systematic viewing of the data and it also allows a wide variety of operations that can be performed.
总体而言,pandas模块是一个出色的库,用于系统地查看数据,它还允许执行多种操作。
2. Matplotlib — (2. Matplotlib —)
The Matplotlib module is one of the best tools for the visualization of the data frames or any other form of data. Matplotlib is used to visualize the data for exploratory data analysis in data science. It is extremely useful to understand the kind of data we are dealing with and to determine what is the next action that must be performed. The library offers an extensive variety of visualization functions such as scatter plot, bar plot, histograms, pie chart, and many other similar functions. Import matplotlib.pyplot module as plt for performing visualization tasks using matplotlib. An example of these can be seen below —
Matplotlib模块是用于可视化数据框或任何其他形式的数据的最佳工具之一。 Matplotlib用于可视化数据,以进行数据科学中的探索性数据分析。 了解我们正在处理的数据种类并确定下一步必须执行的操作非常有用。 该库提供了广泛的可视化功能,例如散点图,条形图,直方图,饼图和许多其他类似功能。 将matplotlib.pyplot模块导入为plt,以便使用matplotlib执行可视化任务。 下面是这些示例:
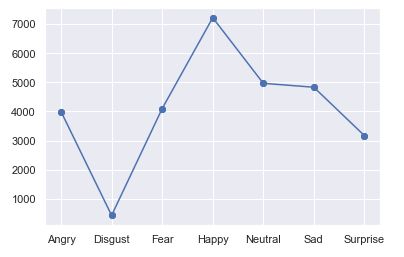
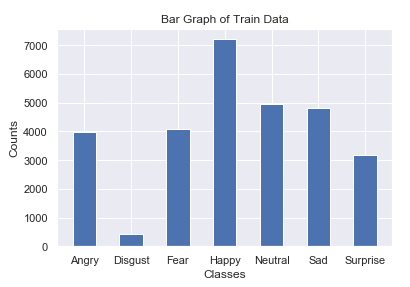
The scatter plots and bar graph plotted using matplotlib is shown in the figures. An advantage of the module is that it is very simple to use and efficient at providing visualizations. It can also be combined with the seaborn library for a more visual and aesthetic appeal.
图中显示了使用matplotlib绘制的散点图和条形图。 该模块的优势在于,它非常易于使用,并且在提供可视化效果方面非常有效。 它也可以与seaborn库结合使用,以提供更多的视觉和美学吸引力。
3. NumPy — (3. NumPy —)
The NumPy library stands for Numerical Python. The numpy library is one of the best options for performing computations on matrix operations. It supports multi-dimensional arrays. An extensive amount of mathematical and logical operations can be performed on arrays. By converting lists into numpy arrays, we can perform computations like addition, subtraction, dot product, among many others. The use cases of numpy are applicable in both computer vision and natural language processing projects. In computer vision, you can use numpy arrays for visualizing the RGB or grayscale images in a numpy array and converting them accordingly. In natural language processing projects, you usually prefer to convert the text data into the form of vectors and numbers for optimized computation. Import numpy as np and you can convert the text data into categorical data as shown below:
NumPy库代表数值Python 。 numpy库是对矩阵运算执行计算的最佳选择之一。 它支持多维数组。 可以对数组执行大量的数学和逻辑运算。 通过将列表转换为numpy数组,我们可以执行诸如加,减,点积之类的计算。 numpy的用例适用于计算机视觉和自然语言处理项目。 在计算机视觉中,您可以使用numpy数组来可视化numpy数组中的RGB或灰度图像,并进行相应的转换。 在自然语言处理项目中,您通常更喜欢将文本数据转换为矢量和数字形式,以优化计算。 将numpy导入为np,您可以将文本数据转换为分类数据,如下所示:
X = np.array(X)
y = np.array(y)
y = to_categorical(y, num_classes=vocab_size)4. Scikit学习- (4. Scikit-learn —)
The scikit-learn module is one of the best tools for machine learning and predictive data analysis. It offers a wide range of pre-built algorithms such as logistic regression, support vector machines (SVM’s), classification algorithms like K-means clustering, and a ton more operations. This is the best way for beginners to get started with machine learning algorithms because of the simple and efficient tools that this module grants access to. It is open-source and commercially usable while granting accessibility to almost anyone. It is reusable and supported by libraries such as NumPy, SciPy, and Matplotlib. import the sklearn module to run scikit-learn code. Below is a code example for splitting the dataset we have into a form of train and test or validation data. This is useful for training and evaluation of the models.
scikit-learn模块是用于机器学习和预测数据分析的最佳工具之一。 它提供了广泛的预构建算法,例如逻辑回归,支持向量机(SVM),分类算法(例如K-means聚类)以及更多的操作。 这是初学者入门机器学习算法的最佳方法,因为该模块允许其使用简单有效的工具。 它是开源的,可商业使用,同时几乎可以授予任何人访问权限。 它可重用,并受到NumPy,SciPy和Matplotlib等库的支持。 导入sklearn模块以运行scikit-learn代码。 下面是一个代码示例,用于将我们拥有的数据集分为训练和测试或验证数据的形式。 这对于训练和评估模型很有用。
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(questions, response, test_size=0.20)5. NLTK- (5. NLTK —)
The NLTK library stands for the natural language toolkit platform which is one of the best libraries for machine learning of natural language processing data. Natural Language Processing (NLP) is a branch of AI that helps computers to understand, interpret, and manipulate human language. The NLTK library is very well suited for linguistic-based tasks. It offers a wide range of options for tasks such as classification, tokenization, stemming, tagging, parsing, and semantic reasoning. It allows the user to chunk the data into entities that can be grouped together to produce a more organized meaning. The library can be imported as nltk and below is an example code for the tokenization of a sentence.
NLTK库代表自然语言工具包平台,它是用于自然语言处理数据的机器学习的最佳库之一。 自然语言处理(NLP)是AI的一个分支,可以帮助计算机理解,解释和操纵人类语言。 NLTK库非常适合基于语言的任务。 它为分类,标记化,词干,加标签,解析和语义推理等任务提供了广泛的选择。 它允许用户将数据分块为多个实体,这些实体可以组合在一起以产生更有条理的含义。 可以将库导入为nltk,下面是用于句子标记化的示例代码。
import nltk
sentence = "Hello! Good morning."
tokens = nltk.word_tokenize(sentence)Note: This is just a brief introduction to all the libraries. If you haven’t completely understood all of them that is totally fine. We will be looking at each of these in much more detail in the upcoming parts of the series with actual examples and how exactly they are used in machine learning algorithms and problems.
注意:这只是所有库的简要介绍。 如果您还没有完全理解所有这些内容,那完全可以。 我们将在本系列的后续部分中通过实际示例更详细地研究其中的每一个,以及它们在机器学习算法和问题中的使用情况。
结论: (Conclusion:)
We were able to achieve a brief understanding of the various data structures and what exactly are the tasks they perform along with an intuitive understanding of the various libraries available in python that provide flexibility for machine learning. With this basic knowledge of python and its respective library modules for machine learning, we are ready to dive deeper into exploring the various territories and algorithms of machine learning. We will be focusing on the exploratory data analysis and the math behind machine learning in the upcoming articles. Once that is done we will look at each algorithm individually with a complete break down of them and their particular use cases.
我们能够对各种数据结构及其执行的任务有一个简短的了解,并能直观地了解python中可用的各种库,这些库为机器学习提供了灵活性。 有了python的基础知识以及用于机器学习的相应库模块,我们就可以更深入地探索机器学习的各个领域和算法。 在接下来的文章中,我们将重点研究探索性数据分析和机器学习背后的数学。 完成后,我们将分别查看每种算法,并对其及其特定用例进行完整细分。
For some of the code, screenshots, and images used in this article are referred to from some of my previous articles. Feel free to check the references below.
对于本文中使用的某些代码,屏幕快照和图像,请参阅我以前的一些文章。 请随时检查以下参考。
Check out all the articles related to this series from the following link:
从以下链接中查看与此系列相关的所有文章:
Thank you all for sticking on till the end and wish you all a wonderful day!
谢谢大家坚持到底,并祝大家有美好的一天!
翻译自: https://towardsdatascience.com/basics-of-python-and-its-library-modules-required-for-machine-learning-51c9d26026b8
python机器学习模块