C++学习笔记
Reference to ‘left’ is ambiguous
在引用了bits/stdc++.h库后,left和right不能继续使用,会变成引用模糊,得换名
![]()
priority_queue的使用
大根堆
//构造一个空的优先队列(此优先队列默认为大顶堆)
priority_queue big_heap;
//另一种构建大顶堆的方法
priority_queue,less > big_heap2;
小根堆
//构造一个空的优先队列,此优先队列是一个小顶堆
priority_queue,greater > small_heap;
假设type类型为int,则:
操作
bool empty() const
返回值为true,说明队列为空;
int size() const
返回优先队列中元素的数量;
void pop()
删除队列顶部的元素,也即根节点
int top()
返回队列中的顶部元素,但不删除该元素;
void push(int arg)
将元素arg插入到队列之中;
重载运算符的小根堆写法
luogu 2085
网址:https://www.luogu.com.cn/problem/P2085
#include
using namespace std;
#define N 11000
struct data{
int x,id,cnt;
}d;
priority_queue,less >heap;
bool operator <(data a,data b){return a.x>b.x;}//注意不要忘记加bool
int n,m,a[N],b[N],c[N];
int main(){
cin>>n>>m;
for(int i=1;i<=n;i++){
cin>>a[i]>>b[i]>>c[i];
d.x=a[i]+b[i]+c[i];
d.id=i;
d.cnt=1;
heap.push(d);
}
for(int i=1;i<=m;i++){
data x=heap.top();
heap.pop();
cout< long double
链接:https://www.luogu.com.cn/problem/P1743
#include
using namespace std;
long double n,m,ans;
int main(){
cin>>n>>m;
if(n==100000000&&m==3){cout<<"166666676666666850000000";return 0;}
if(n==100000000&&m==4){cout<<"4166667083333347900000000000000";return 0;}
n=n+m;
ans=1;
for(int i=1;i<=m;i++)ans=ans*(n-i+1);
for(int i=1;i<=m;i++)ans/=i;
printf("%.0Lf",ans);
return 0;
}
堆的重载
链接:https://www.luogu.com.cn/problem/P2859
#include
using namespace std;
struct ti{
int s,t,id,ans;
}a[60000];
struct data{
int ti,id;
bool operator <(const data &x)const{
return ti>x.ti;
}
};
int n,cnt;
priority_queueq;
int cmp(ti a,ti b){
return a.s>n;
for(int i=1;i<=n;i++){
cin>>a[i].s>>a[i].t;
a[i].id=i;
}
sort(a+1,a+n+1,cmp);
cnt=1;
q.push({a[1].t,1});
a[1].ans=1;
for(int i=2;i<=n;i++){
if(a[i].s>q.top().ti){
data now=q.top();
q.pop();
a[i].ans=now.id;
now.ti=a[i].t;
q.push(now);
}else{
cnt++;
a[i].ans=cnt;
q.push({a[i].t,cnt});
}
}
sort(a+1,a+n+1,cmp1);
cout< c++的getline
#include
#include
using namespace std;
string s;
int main(){
while(getline(cin,s)){
//cout< getline(cin,s),后面的s需要为string类型
c++的string类型
求长度s.length()
c++的交互题
https://codeforces.com/contest/1505/problem/A
#include
#include
using namespace std;
string s;
int main(){
while(getline(cin,s)){
cout<<"NO"< map使用方法
参考:https://blog.csdn.net/qq_42232118/article/details/82024301
#includemap和auto用法
参考:https://leetcode-cn.com/problems/top-k-frequent-words/
class Solution {
public:
struct data{
string s;
int num;
}a[11000];
int cnt=0;
static bool cmp(data a,data b){
if(a.num>b.num)return 1;
if(a.num topKFrequent(vector& words, int k) {
mapm;
for(auto w:words){
m[w]++;
}
for(auto w:m){
cnt++;
a[cnt].s=w.first;
a[cnt].num=w.second;
}
sort(a+1,a+cnt+1,cmp);
vectorans;
for(int i=1;i<=k;i++)ans.push_back(a[i].s);
return ans;
}
};
map判断元素是否存在
使用.count(x)
if(mp.count(x)>0){
set的用法(集合的用法)
参考:https://www.cnblogs.com/omelet/p/6627667.html
题目:https://leetcode-cn.com/problems/maximum-number-of-non-overlapping-subarrays-with-sum-equals-target/
#include>x;
if(f.find(x)!=f.end()){
cout<<"yes"<
}
set中count的用法
#include
using namespace std;
int main(){
sets;
s.insert(1);
int x=s.count(1);
cout< multiset用法,关于里面的iterator
参考:https://blog.csdn.net/zsnowwolfy/article/details/88057500
class Solution {
public:
int minAbsoluteSumDiff(vector<int>& nums1, vector<int>& nums2) {
multiset<int>S;
for(int i=0;i<nums1.size();i++){
S.insert(nums1[i]);
}
S.insert(-10000000);
S.insert(10000000);
long long ans=0;
for(int i=0;i<nums1.size();i++){
ans+=abs((long long)nums1[i]-nums2[i]);
}
long long res=100000000000;
for(int i=0;i<nums1.size();i++){
long long ans1=ans-abs(nums1[i]-nums2[i]);
long long min1=1000000;
if(S.count(nums2[i])>0)ans1=ans1,min1=0;
else {
multiset<int>::iterator it;
it=S.upper_bound(nums2[i]);
min1=min(min1,abs((long long)*it-nums2[i]));
it--;
min1=min(min1,abs((long long)*it-nums2[i]));
}
res=min(res,min1+ans1);
}
return res%1000000007;
}
};
char* s的用法
#include
#include
using namespace std;
char s[100];
int ans;
//transfrom
//idea: ans=sum(26^i*str[i])
int strToInt(char* str){
int len=strlen(str);
int mul=1;//每次*26
int ans=0;
for(int i=len-1;i>=0;i--){
ans=ans+(str[i]-'A'+1)*mul;
mul=mul*26;
}
return ans;
}
int main() {
cin>>s;
ans=strToInt(s);//将string转换成对应的ans
cout< c++在缓冲器输出(不正式输出到输出文件中)
参考:https://baike.baidu.com/item/cerr/2376391?fr=aladdin
cerr << "Time : " << 1000 * ((double)clock()) / (double)CLOCKS_PER_SEC << "ms\n";
Cerr 一个iostream对象,关联到标准错误,通常写入到与标准输出相同的设备。默认情况下,写到cerr的数据是不缓冲的。Cerr通常用于输出错误信息与其他不属于正常逻辑的输出内容。
c++输出进程的执行时间
参考:https://blog.csdn.net/weixin_37941618/article/details/80789443
cerr << "Time : " << 1000 * ((double)clock()) / (double)CLOCKS_PER_SEC << "ms\n";

auto的用法
参考:https://blog.csdn.net/qq_31930499/article/details/79948906
题目:https://codingcompetitions.withgoogle.com/kickstart/round/0000000000435a5b/000000000077a885
在vector中可以直接for(auto p:po[u]),这样相当于p就是vector里面拿出来的结构体对象
#include
using namespace std;
typedef long long ll;
const int N=200010;
int x,y,l,maxl,t,T,n,q,start;
ll a,ans[N],g[N*4];
struct edge{
int o,l;
ll a;
};
struct arr{
int id,l;
};
vectorpo[N];
vectore[N];
ll gcd(ll a,ll b){
return b==0?a:gcd(b,a%b);
}
ll query(int o,int l,int r,int L,int R){
if(L<=l&&R>=r)return g[o];
int mid=(l+r)>>1;
ll res=0;
if(L<=mid)res=gcd(res,query(o*2,l,mid,L,R));
if(R>mid)res=gcd(res,query(o*2+1,mid+1,r,L,R));
return res;
}
void update(int o,int l,int r,int x,ll w){
if(l==r){
g[o]=w;
return;
}
int mid=(l+r)>>1;
if(x<=mid)update(o<<1,l,mid,x,w);
else update(o<<1|1,mid+1,r,x,w);
g[o]=gcd(g[o<<1],g[(o<<1)+1]);
}
void dfs(int u,int fa){
for(auto p:po[u]){
ans[p.id]=query(1,1,maxl,1,min(maxl,p.l));
}
for(auto ed:e[u]){
if(ed.o==fa)continue;
ll ori=query(1,1,maxl,ed.l,ed.l);
update(1,1,maxl,ed.l,gcd(ed.a,ori));
dfs(ed.o,u);
update(1,1,maxl,ed.l,ori);
}
}
int main(){
cin>>T;
for(int t=1;t<=T;t++){
printf("Case #%d: ",t);
scanf("%d%d",&n,&q);
maxl=0;
for(int i=1;i<=n;i++)e[i].clear();
for(int i=1;i 计算机中的换行符、回车符、\n、\r、\n\r怎么区别
参考:https://zhidao.baidu.com/question/386412786.html
'\r’是回车,前者使光标到行首,(carriage return)
'\n’是换行,后者使光标下移一格,(line feed)
\r 是回车,return
\n 是换行,newline
对于换行这个动作,unix下一般只有一个0x0A表示换行("\n"),windows下一般都是0x0D和0x0A两个字符("\r\n"),苹果机(MAC OS系统)则采用回车符CR表示下一行(\r)Unix系统里,每行结尾只有“<换行>”,即“\n”;Windows系统里面,每行结尾是“<回车><换行>”,即“\r\n”;Mac系统里,每行结尾是“<回车>”,即“\r”。
windows采用回车+换行CR/LF表示下一行,即^M ( ( (不是换行符的表示,换行符没有表示出来,$是文本结束EOF的表示)
无视无关输入字符
for(int i=0;itypedef用法
参考:https://baike.baidu.com/item/typedef/9558154?fr=aladdin
typedef是在计算机编程语言中用来为复杂的声明定义简单的别名,它与宏定义有些差异。它本身是一种存储类的关键字,与auto、extern、mutable、static、register等关键字不能出现在同一个表达式中。
typedef long long ll;
之后ll就是long long类型的别名了
lower_bound( )和upper_bound( )
参考:https://blog.csdn.net/qq_40160605/article/details/80150252
lower_bound( )和upper_bound( )都是利用二分查找的方法在一个排好序的数组中进行查找的。
在从小到大的排序数组中,
lower_bound( begin,end,num):从数组的begin位置到end-1位置二分查找第一个大于或等于num的数字,找到返回该数字的地址,不存在则返回end。通过返回的地址减去起始地址begin,得到找到数字在数组中的下标。
upper_bound( begin,end,num):从数组的begin位置到end-1位置二分查找第一个大于num的数字,找到返回该数字的地址,不存在则返回end。通过返回的地址减去起始地址begin,得到找到数字在数组中的下标。
在从大到小的排序数组中,重载lower_bound()和upper_bound()
lower_bound( begin,end,num,greater() ):从数组的begin位置到end-1位置二分查找第一个小于或等于num的数字,找到返回该数字的地址,不存在则返回end。通过返回的地址减去起始地址begin,得到找到数字在数组中的下标。
upper_bound( begin,end,num,greater() ):从数组的begin位置到end-1位置二分查找第一个小于num的数字,找到返回该数字的地址,不存在则返回end。通过返回的地址减去起始地址begin,得到找到数字在数组中的下标。
#include
using namespace std;
const int maxn=100000+10;
const int INF=2*int(1e9)+10;
#define LL long long
int cmd(int a,int b){
return a>b;
}
int main(){
int num[6]={1,2,4,7,15,34};
sort(num,num+6); //按从小到大排序
int pos1=lower_bound(num,num+6,7)-num; //返回数组中第一个大于或等于被查数的值
int pos2=upper_bound(num,num+6,7)-num; //返回数组中第一个大于被查数的值
cout<())-num; //返回数组中第一个小于或等于被查数的值
int pos4=upper_bound(num,num+6,7,greater())-num; //返回数组中第一个小于被查数的值
cout< 用ios::sync_with_stdio(false)有什么作用
参考:https://blog.csdn.net/qq_46144237/article/details/107348235?utm_medium=distribute.pc_relevant.none-task-blog-baidujs_title-0&spm=1001.2101.3001.4242
因为系统默认standard stream应该都是同步的,设置sync_with_stdio(false),其实应该是让C风格的stream和C++风格的stream变成async且分用不同buffer。
注意:
1.
ios::sync_with_stdio(false)不可以与scanf混用,否则会造成异常。
2.
虽然ios::sync_with_stdio对cin有加速所用,但是还是没有scanf的速度快。
下面是ios::sync_with_stdio()的简单使用
int main(){
ios::sync_with_stdio(0);//提高cout、cin的速度
ll l,r;cin>>l>>r;
for(int i=1;i<=9;i++){
cout<C++ uniform_int_distribution离散均匀分布类用法详解
参考:https://blog.csdn.net/qq_42780289/article/details/91348748
参考:http://c.biancheng.net/view/639.html
用cout保留小数
用cout保留double的5位小数
cout<C++ 读取.csv文件
参考:https://www.jianshu.com/p/1172e2de7a7a
#include
#include
#include
int main(){
vector> user_arr;
ifstream fp("xxx/user_data.csv"); //定义声明一个ifstream对象,指定文件路径
string line;
getline(fp,line); //跳过列名,第一行不做处理
while (getline(fp,line)){ //循环读取每行数据
vector data_line;
string number;
istringstream readstr(line); //string数据流化
//将一行数据按','分割
for(int j = 0;j < 11;j++){ //可根据数据的实际情况取循环获取
getline(readstr,number,','); //循环读取数据
data_line.push_back(atoi(number.c_str())); //字符串传int
}
user_arr.push_back(data_line); //插入到vector中
}
return 0;
}
补充:
将字符串类型数据转换成 int 类型需要先使用 .c_str() 转成 const char* 类型,再用 atoi() 转成 int ,如果转为浮点型则 atof() ,long 型则 atol() 等等。
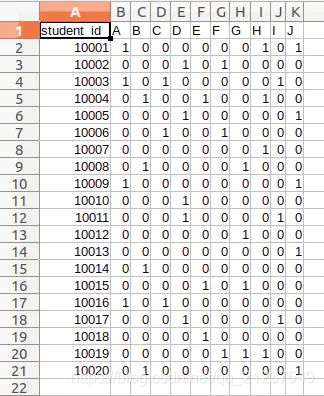

int main(){
//读入400个士兵的情况
ifstream fp("people_postition_table.csv"); //定义声明一个ifstream对象,指定文件路径
string line;
getline(fp,line); //跳过列名,第一行不做处理
while (getline(fp,line)){ //循环读取每行数据
string number;
line=line+',';
istringstream readstr(line); //string数据流化
//将一行数据按','分割
//cout<C++中string转double和int
参考:https://blog.csdn.net/qq_32273417/article/details/88318161
以下是string转double的方法
#include
#include
#include
using namespace std;
int main() {
string s;
cin >> s;
double n = atof(s.c_str());
cout << n << endl;
return 0;
}
以下是string转int的方法
#include
#include
#include
using namespace std;
int main() {
string s;
cin >> s;
cout << atoi(s.c_str()) << endl;
return 0;
}
multiset与set的对比用法
multiset会把多个重复的数都存下来,set只会存一个(剩下的相同的会无视)
#include输出
1
1
2
1
1
1
2
c++ memset
表示初始化
memset(ans,0,sizeof(ans));//初始化为全0
memset(ans,-1,sizeof(ans));//初始化为全-1
memset(ans,42,sizeof(ans));//初始化为全很大的数
exit(0)的用法
用在函数中,相比continue,break,return。
exit(0)表示直接退出整个程序。
c++直接给vector赋值
参考:https://blog.csdn.net/winnyrain/article/details/78189222
int myarray[5] = {1,3,5,7,9};
vector<int> myvector(myarray , myarray+5);
这样可以把myarray中的元素换成myvector这个向量
链表
链表1-10并输出
#includeswitch的用法
注意必须要有break,不然会输出下面多个。
#includevector初始化,定义固定大小。
参考:https://leetcode-cn.com/problems/shortest-path-visiting-all-nodes/
vector<vector<int>> flag(n,vector<int>(1<<n));
表示开了第一维的大小为0-(n-1),第二维大小为0-((1< 开的时候可以tuple 参考:https://blog.csdn.net/weixin_30897079/article/details/97119054 表示清空并释放vecnum动态数组,后面可以继续用push_back加入。 参考题目:https://leetcode-cn.com/problems/arithmetic-slices-ii-subsequence/ 参考:https://baike.baidu.com/item/memset/4747579?fr=aladdin void *memset(void *s, int ch, size_t n); 题目:https://leetcode-cn.com/problems/all-paths-from-source-to-target/ 指针可以直接用map存下来, &head和head,head存的是具体所指变量的地址位置,&head是指存这个地址信息的指针变量的地址。 先用变量定义,然后直接调用class中的public里面的函数。 https://leetcode-cn.com/problems/random-pick-with-weight/submissions/ 比如 .clear() 参考:https://blog.csdn.net/andrewgithub/article/details/78760381 友元的正确使用能提高程序的运行效率,但同时也破坏了类的封装性和数据的隐藏性,导致程序可维护性变差。 友元函数是可以直接访问类的私有成员的非成员函数。它是定义在类外的普通函数,它不属于任何类,但需要在类的定义中加以声明,声明时只需在友元的名称前加上关键字friend,其格式如下: 友元类 : 直接用to_string即可 即开了0->(N-1)的vector值,且初始为0 新建一个n行m列的向量 参考:https://blog.csdn.net/qq_21997625/article/details/84672775 表示从mark开始拷贝k位 std::cin.tie(0); 在默认的情况下cin绑定的是cout,每次执行 << 操作符的时候都要调用flush,这样会增加IO负担。可以通过tie(0)(0表示NULL)来解除cin与cout的绑定,进一步加快执行效率。 如下所示: #include 让cin与标准输入输出不同步,比赛不要用,会干扰文件输入输出 .back()为最后一位,.pop_back()为弹出最后一位 输出 reverse(q.begin(),q.end())tuple的用法
拿出元素直接auto [x,y,z]=…class Solution {
public:
int shortestPathLength(vector<vector<int>>& graph) {
int n=graph.size();
vector<vector<int>> flag(n,vector<int>(1<<n));
queue<tuple<int,int,int>>q;
int ans;
for(int i=0;i<n;i++){
flag[i][1<<i]=1;
q.push({i,1<<i,0});
}
while(q.size()){
auto [x,y,z]=q.front();
q.pop();
if(y==(1<<n)-1){
ans=z;
break;
}
int m=graph[x].size();
for(int i=0;i<m;i++){
int yy=graph[x][i];
if(flag[yy][(1<<yy)|y]==0){
flag[yy][(1<<yy)|y]=1;
q.push({yy,(1<<yy)|y,z+1});
}
}
}
return ans;
}
};
vector快速清除空间并释放内存
vector<int>().swap(vecnum);
数组中嵌套map
class Solution {
public:
int numberOfArithmeticSlices(vector<int>& nums) {
int ans=0;
int cnt;
int n=nums.size();
map<long long,int>f[1100];
for(int i=1;i<n;i++){
for(int j=0;j<i;j++){
long long d=(long long)nums[i]-nums[j];
if(f[j].count(d)==0)cnt=0;
else cnt=f[j][d];
ans+=cnt;
f[i][d]+=cnt+1;
}
}
return ans;
}
};
memset的意思
函数解释:将s中当前位置后面的n个字节 (typedef unsigned int size_t )用 ch 替换并返回 s 。
memset:作用是在一段内存块中填充某个给定的值,它是对较大的结构体或数组进行清零操作的一种最快方法 [1] 。
memset()函数原型是extern void *memset(void *buffer, int c, int count) buffer:为指针或是数组,c:是赋给buffer的值,count:是buffer的长度.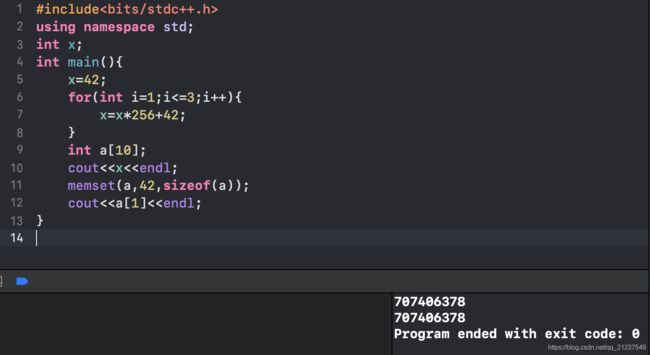
本质上就是把每个字节变成相应的ch。c++中vector赋值
要赋值二维vector,直接设个vectorclass Solution {
public:
int ans[20],n;
vector<vector<int>>fin;
vector<vector<int>>graph1;
void dfs(int now,int cnt){
ans[cnt]=now;
if(now==n-1){
vector<int>res;
for(int i=1;i<=cnt;i++)res.push_back(ans[i]);
fin.push_back(res);
return;
}
int m=graph1[now].size();
for(int i=0;i<m;i++){
dfs(graph1[now][i],cnt+1);
}
}
vector<vector<int>> allPathsSourceTarget(vector<vector<int>>& graph) {
graph1=graph;
n=graph.size();
dfs(0,1);
return fin;
}
};
c++指针
#includec++的class与public
#include
vector的初始化大小定义
直接用.resize(n)即可,n为需要初始化的大小。class Solution {
public:
vector<int>arr;
int sum;
Solution(vector<int>& w) {
int n=w.size();
arr.resize(n);
arr[0]=w[0];
for(int i=1;i<n;i++)arr[i]=arr[i-1]+w[i];
sum=arr[n-1];
}
int pickIndex() {
int x=rand()%sum+1;
int id=lower_bound(arr.begin(),arr.end(),x)-arr.begin();
return id;
}
};
/**
* Your Solution object will be instantiated and called as such:
* Solution* obj = new Solution(w);
* int param_1 = obj->pickIndex();
*/
注意对double进行sqrt,可能会有精度问题
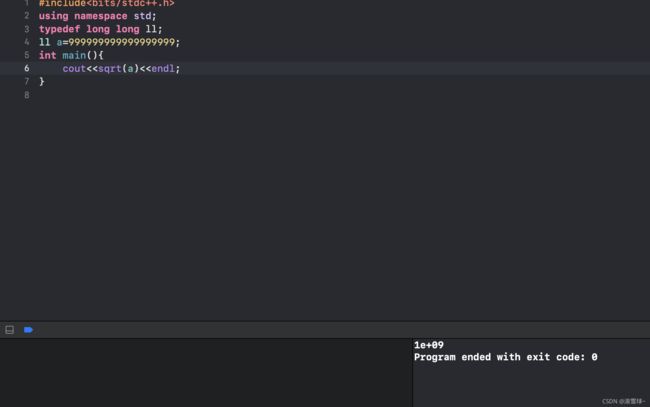
故最好用反向的乘法来代码除法,可以确保正确性。pair用法
#includemap清空
mapvector初始化方法
vectorconstexpr

constexpr表示这玩意儿在编译期就可以算出来(前提是为了算出它所依赖的东西也是在编译期可以算出来的)。而const只保证了运行时不直接被修改(但这个东西仍然可能是个动态变量)。友元函数
友元提供了不同类的成员函数之间、类的成员函数与一般函数之间进行数据共享的机制。通过友元,一个不同函数或另一个类中的成员函数可以访问类中的私有成员和保护成员。c++中的友元为封装隐藏这堵不透明的墙开了一个小孔,外界可以通过这个小孔窥视内部的秘密。
友元函数 :
friend 类型 函数名(形式参数);友元函数的声明可以放在类的私有部分,也可以放在公有部分,它们是没有区别的,都说明是该类的一个友元函数。
一个函数可以是多个类的友元函数,只需要在各个类中分别声明。
友元函数的调用与一般函数的调用方式和原理一致。
友元类的所有成员函数都是另一个类的友元函数,都可以访问另一个类中的隐藏信息(包括私有成员和保护成员)。
当希望一个类可以存取另一个类的私有成员时,可以将该类声明为另一类的友元类。定义友元类的语句格式如下:
friend class 类名;
其中:friend和class是关键字,类名必须是程序中的一个已定义过的类。
普通函数友元函数: a) 目的:使普通函数能够访问类的友元
b) 语法:声明位置:公有私有均可,常写为公有
声明: friend + 普通函数声明
实现位置:可以在类外或类中
实现代码:与普通函数相同(不加不用friend和类::)
调用:类似普通函数,直接调用
class INTEGER
{
private:
int num;
public:
friend void Print(const INTEGER& obj);//声明友元函数
};
void Print(const INTEGER& obj)//不使用friend和类::
{
//函数体
}
void main()
{
INTEGER obj;
Print(obj);//直接调用
}
int转string
#includevector初始化开n个值为0的空间
const int N=200005;
const int M=200000;
int ans=0;
vector新建一个二维vector
vector#includemap与unordered_map的区别
map内部实现了一个红黑树,unordered_map内部实现了一个哈希表,在查找上unordered_map会比map更快。c++拷贝string
string ss=s.substr(mark,k);class Solution {
public:
string subStrHash(string s, int power, int modulo, int k, int hashValue) {
int n=s.length();
long long mul=1,mark=0;
long long sum=0;
for(int i=n-k;i加速cin
ios::sync_with_stdio(false);
int main()
{
std::ios::sync_with_stdio(false);
std::cin.tie(0);
// IO
}#includevector的最后一位与删除最后一位
//https://www.acwing.com/problem/content/792/
#include2
1
1
vector取反