写在前面
这是小李在写的第一篇文章,先介绍一下自己:
今年22岁,目前是一个上海金融科技民工,从大二开始接触Python,可以熟练使用pandas处理数据,以及用seaborn简单做图,sklearn也会一点点。现在利用业余时间加强学习一下数据分析能力,在这里记录一下自己学习的收获、反思等。
虽然接触python时间不短,但是非科班出身(专业金融辅修计算机)所以编码上有可能会存在一些“低级错误”,希望大家伙可以不吝赐教,非常欢迎交流分享。(目前的兴趣点在数据分析以及机器学习上)。
就这样,正文开始~
一、 数据获取
这次使用的数据是从美国统计局下载的联邦医疗补贴数据,这里就不放链接了。名字是“Medicaid_Financial_Management_Data.CSV”。
本来是想用这个数据做机器学习的,结果发现没啥好学习的,就索性学习了一下数据可视化。
二、 工具准备
之前分析数据(一般是股票数据、财务数据之类的)我比较喜欢用Jupyter Notebook,因为它的交互界面还有Markdown实在太好用了,甚至在写完之后直接生成HTML就能当附件交作业。但是我听说Pycharm比较适合机器学习,所以现在开始尝试着使用Pycharm,此次分析使用的是开源免费版本的PyCharm Community Edition x64。
这次会用到两个库:pandas以及pyecharts。
import pandas as pd
from pyecharts import options as opts
from pyecharts.charts import Map, Page
三、 分析开始
读取数据

通过观察数据,发现此数据集的空值表达形式为空即"",所以在读取时将空值转化为NAN,否则在后续dropna时会失效。
f = pd.read_csv('./Medicaid_Financial_Management_Data.csv', na_values="")
df = pd.DataFrame(f)
清洗数据
数据集是2016年,经过检验year列没有2016以外的数据,所以直接丢掉。
# df = df[df['Year'] == 2016]
df.drop('Year', axis=1, inplace=True)
按照州名以及项目名聚合一下
group = df.groupby(['State', 'Program']).mean()
# 确定group中每个state下只有[Administration, Medical Assistance Program]两行
# program = df[['Program']].groupby(['Program']).count()
# print(program)
汗,我可能太依赖于Jupyter的一行代码一行输出的模式了,Pycharm没法及时查看代码运行效果让我有些难受(也可能是我还没发现怎么用。。。)用print调试太痛苦了。
通过筛选发现需要将数据分为Administration和Medical Assistance Program,可以用循环分离两行,此次目的分析医疗补助项目,故管理项目可丢弃。现在计算联邦医疗补助占联邦份额比例。
for index, row in group.iterrows():
if index[1] == 'Administration':
group.drop(index, inplace=True)
else:
continue
group['%medicaid Federal'] = group['Federal Share Medicaid'] / group['Federal Share']
group = group[['%medicaid Federal', 'Federal Share']]
group.reset_index(inplace=True)
group.set_index('State', inplace=True)
group.drop('Program', axis=1, inplace=True)
'''
group = (group[['%medicaid Federal', 'Federal Share']]
.reset_index(inplace=True)
.set_index('State', inplace=True)
.drop('Program', axis=1, inplace=True))
'''
这里我本来想用链式结构的,不知道为什么老是报错。“Nonetype do not have reset_index attribute.” 之后再改进吧。
Pyecharts可视化
数据集生成
将数据分为联邦份额以及医疗补贴占比:
data_med = []
data_share = []
for index, row in group.iterrows():
data_med.append([index, row[0]])
data_share.append([index, row[1]])
地图函数
如果想要同时显示的图属于同一类图而且底图尺度一样时,Pyecharts默认会绘制到一副底图上,虽然在有些场景不错但此次我想要的是一个同行双显图,库自带的Page类可以使多幅图在同一页面显示,而DraggablePageLayout属性可以让画布可以被调整,相当人性化了。
def medmap_america() -> Map:
c = (
Map()
.add('%联邦医疗补助', data_med, maptype='美国', zoom=1)
.set_series_opts(label_opts=opts.LabelOpts(is_show=False))
.set_global_opts(
title_opts=opts.TitleOpts(title="医疗补贴地图"),
visualmap_opts=opts.VisualMapOpts(max_=max(x[1] for x in data_med), min_=min(x[1] for x in data_med),
split_number=7, is_calculable=True),
)
)
d = (
Map()
.add('联邦份额', data_share, maptype='美国', zoom=1)
.set_series_opts(label_opts=opts.LabelOpts(is_show=False))
.set_global_opts(
title_opts=opts.TitleOpts(title="联邦份额地图"),
visualmap_opts=opts.VisualMapOpts(max_=max(x[1] for x in data_share), min_=min(x[1] for x in data_share),
split_number=7, is_calculable=True),
)
)
page = (
Page(layout=Page.DraggablePageLayout)
.add(c)
.add(d)
)
return page
d_map = medmap_america()
d_map.render("./med_america.html")
Pyecharts最后输出的成果是HTML,如果接入前端然后加载页面内HTML用作BI系统的数据可视化展示应该还是蛮炫酷的吧。
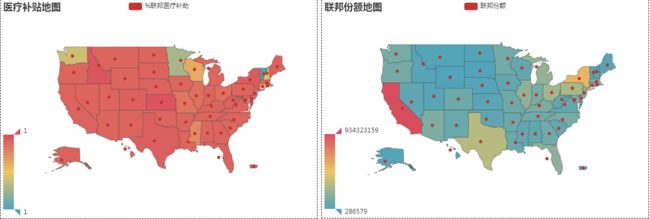
四、 分析以及反思
- 从图表中可以看出美国的医疗补贴力度比较大,除了寥寥三四个州之外其余州的医疗补贴100%由政府出资,但出资比例高并不代表着医疗补贴水平高,因为出资规模差异非常大。
- 右图为联邦出资规模最多的加利福尼亚州有934,323,159美元最低的州只有286,579美元,其间是3位数的差距(感觉有些辛酸,好大的贫富差距)不过这里还需要人口数据作为佐证不然有些以偏概全了。这个数据集是2016年的数据,最新情况还不得而知,但在2016年加利福尼亚州的财政支出已远超纽约我只能说加利福尼亚州牛逼,毕竟坐拥硅谷以及旧金山湾区,经济科技发展没的说。
- 整个分析从准备到调试到最终输出大概耗时3天(的空余时间),是一个小项目吧。还是简单分析一下得失:
- 收获:学习了新的可视化利器Pyecharts,感觉有中文document真的有点爽。
- 不足之处:
- 虽然看样子分析了不少,但是除了California Yes之外似乎并没有得出什么有用的结论。日后还是得在数据获取、数据模型、评估算法上下些功夫。
- 数据处理过程有些不够流畅,出了挺多Bug,蛮遗憾的。