时间轮:高效延时队列(定时器)。
Kafka中时间轮(TimingWheel)存储定时任务环形队列,底层数组实现,数组中每个元素存放一个定时任务列表(TimerTaskList)。TimerTaskList是环形双向链表,链表中每一项都是定时任务项(TimerTaskEntry)封装了真正定时任务TimerTask。

其他定时器 你真的了解延时队列吗 时间轮定时器优点:
任务添加\移除O(1);不占用大量资源;一个线程推进就工作
一、为什么使用环形队列
很大数组,存放延时任务。精度毫秒级!实际定时时间转换毫秒即可,将任务存入其中:
当前时间2018/10/24 19:43:45,任务存入Task[1540381425000],value是定时任务内容。
假如数组长度达到亿亿级,确实可以这么干。 如果将精度减秒级呢?也需要百亿级长度数组。不说内存够不够,定时器这么大内存浪费。
自己写map,保证不存在hash冲突问题,完全可行。

时间轮是不存在hash冲突数据结构
手表无论当前是什么时间,总能用表盘去表示它(忽略精度)


时间总能落在0 - 59任意一个bucket上,秒钟总是落0 - 59一样,这便是时间轮的环形队列。
二、表示的时间有限
局限性:想要加入一小时后的延迟任务,该怎么办?
一天内所有时间,三个数组即可(时分秒)。
动手来做,tickMs上面说一秒。wheelSize表示一圈多少个刻度,即上面说的60。interval表示一圈能表示多少时间,即 tickMs * wheelSize = 60秒。
overflowWheel分钟,以此类推。

每个时间轮来说,秒级时间轮,和分级时间轮,都有自己过期槽delayMs < tickMs时候。
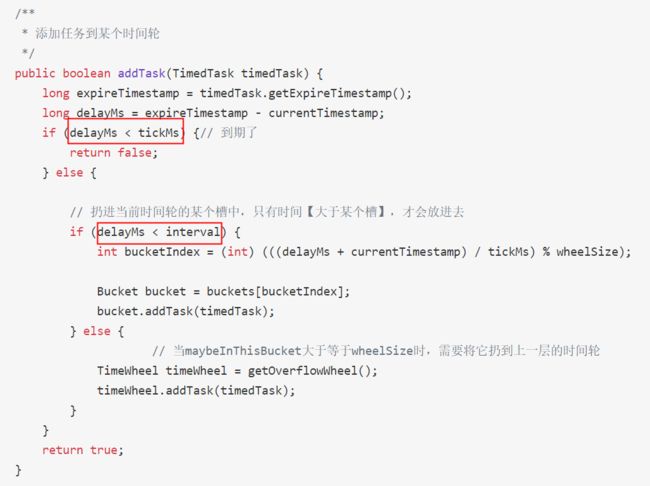
添加延时任务几种情况:
(一)、时间到期
1)任务要在 16:29:07 执行,秒级时间轮16:29:06过期了。delayMs = 1000ms,小于了秒级时间轮的tickMs(1000ms)。
任务要在 16:41:25 执行,16:41时(没有秒针)到期,delayMs = 25000ms,小于分级时间轮tickMs(60000ms)。
二、时间未到期,且delayMs小于interval
秒级时间延迟时间小于60s,肯定能找到一个秒钟槽扔进去。
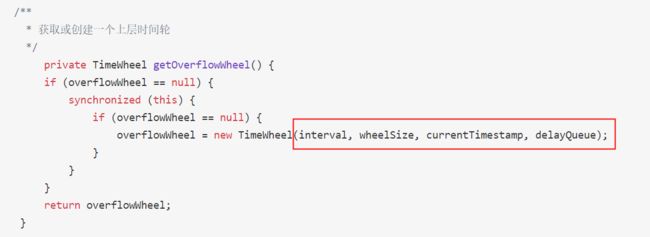
三、时间未到期,且delayMs大于interval。
秒级时间延迟时间大于等于60s,借助上层时间轮,拿到上层时间轮,递归把它扔进去。
延时一年后,递归中不断创建更上层时间轮,直到找到满足delayMs小于interval时间轮。
tickMs(精度)设置为1000ms。wheelSize设置为60。5层时间轮,时间跨度已经长达24年(216000小时)。
时间轮更像是电子表,不存在时间的中间状态,精度一定要理解好。秒级时间轮,精度只能保证到1秒,小于1秒当成是已到期

三、高层时间轮,精度越来越不准,会不会有影响?
分钟时间轮,delayMs为1秒和59秒都已经过期,取出,再扔进底层时间轮不就可以了?
1秒的被扔到秒级时间轮下一个执行槽中,59秒的会被扔到秒级时间轮的后59个时间槽中。
添加任务方法,返回bool
public boolean addTask(TimedTask timedTask)
倒回去看,添加到最底层时间轮失败(只能直接操作最底层时间轮,不能直接操作上层),是不是会直接返回flase?直接执行再入失败任务

四、如何知道一个任务已经过期?
如时间轮两层,120个槽。将槽扔进delayedQueue中。轮询地从delayedQueue取出已经过期的槽。
百万级,千万级delayQueue增删非常慢
** 一、面向槽的delayQueue**
定时任务长短不一,跨度到24年,delayQueue仅有300个元素。
** 二、处理过期的槽**
槽到期后,也就是被从delayQueue中poll出来后,将槽中的所有任务循环一次,重新加到新槽中(添加失败则直接执行)。

完整的时间轮GitHub,其实就是半抄半自己撸的Kafka时间轮简化版 Timer#main 中模拟了六百万个简单的延时任务,执行的效率很高 ~
https://my.oschina.net/anur/blog/2252539