Node.js如何创建多进程
这里我们在主进程cluster.isMaster中根据系统CPU的总核数require('os').cpus()创建多个工作进程cluster.fork()。在各工作进程即子进程中创建HTTP服务器,监听同一端口号8090并返回响应。具体实现如下图所示:

通过上面的处理逻辑,我发现在主进程中只是执行了创建子进程的动作,并没有创建服务器的动作。那么主进程的服务器是如何创建的呢?由于服务器创建的动作是在子进程中执行的,因此主进程是否就离不开子进程的交互了。
Q:主进程在cluster模式下如何创建服务器?
关于集群,你应该知道的事儿
在集群模式下,主进程的服务器会接受到请求然后发送给子进程。而主进程服务器的创建当然和子进程密切相关了。下面详细分析一下:

子进程在cluster._getServer函数中向已建立的IPC通道发送内部消息message,该消息包含serverQuery信息,同时包含act: 'queryServer'字段,等待服务器响应后继续执行回调函数modifyHandle。
主进程internal/cluster/master.js中会监听message。
function onmessage(message, handle) {
const worker = this;
if (message.act === 'online')
online(worker);
else if (message.act === 'queryServer')
queryServer(worker, message);
else if (message.act === 'listening')
listening(worker, message);
else if (message.act === 'exitedAfterDisconnect')
exitedAfterDisconnect(worker, message);
else if (message.act === 'close')
close(worker, message);
}
主进程接收到子进程发送到内部消息,会根据act:'queryServer'执行对应queryServer()方法,完成服务器到创建,同时发送回复消息给子进程,子进程执行回调函数modifyHandle,继续接下来到操作。
Q:为什么可以通过cluster.isMaster判断是主进程还是子进程呢?
这里就需要查看Node.js的具体实现了。我们可以发现在Node.js的cluster模块中只有一行处理代码,如下所示:
const childOrMaster = 'NODE_UNIQUE_ID' in process.env ? 'child' : 'master';
module.exports = require(`internal/cluster/${childOrMaster}`);
其中NODE_UNIQUE_ID变量默认是没有的,所以默认创建的是主进程。而变量NODE_UNIQUE_ID是在主进程fork子进程时传递进去的参数,因此采用cluster.fork()创建的子进程是一定包含NODE_UNIQUE_ID的,具体流程如下图所示:

⚠️这里需要指出的是,必须通过cluster.fork创建的子进程才有NODE_UNIQUE_ID变量,如果通过child_process.fork的子进程,在不传递环境变量的情况下是没有NODE_UNIQUE_ID的。因此,当你在child_process.fork的子进程中执行cluster.isMaster判断时,返回 true。
Q:如何做到多个子进程共同监听一个端口号的?
我们都知道,同一个端口号是不能同时被多个进程监听的,如果有两个进程同时对一个端口进行监听,Node.js会直接抛出一个异常(Error: listen EADDRINUSE)。
但是如果使用代理模式同时监听多个端口,让master进程监听8090端口,收到请求时,再将请求分发给不同服务,而且master进程还能做适当的负载均衡。
首先我们先启动项目,查看系统端口占用情况,以便后期分析:
-
启动项目,但是不发起任何请求,此时应该只有主进程在运行。
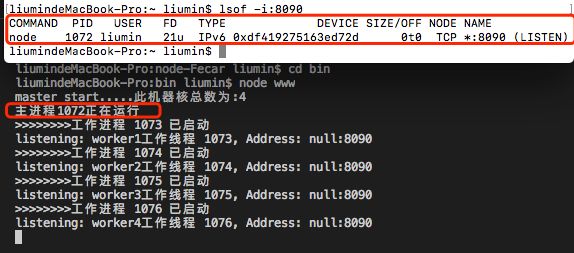 image.png
image.png -
发起请求,主进程开始分配任务给工作进程执行。
 image.png
image.png
通过上图,可以发现主进程监听8090端口,并且对请求进行分配转发到各工作进程。这就是Master-Worker模式,又称主从模式。是典型的分布式架构中用于并行处理业务的模式,具备较好的可伸缩性(很好的处理并发情况)和稳定性(一个进程挂掉不会影响其它进程)。
主进程不负责具体的业务处理,而是负责调度和管理工作进程,它是趋向于稳定的。而工作进程负责具体的业务处理。
Q:主进程对请求进行分配,是否做了负载均衡
对于这个问题,我们在服务上线后通过日志进行打印分析,统计各工作进程被调用次数,分析该模块是否已实现负载均衡。
- 方案一:在app.js中创建全局变量
global.works = [ ];在每次请求的时候将当前使用的工作进程id添加到全局数组中,并进行统计分析。
 image.png
image.png
该方案存在问题:由于每个子进程是单独创建到服务实例 http.createServer(app); 。。。全局变量global.works每次会被重置,因此没有只能看当当次请求所使用当进程情况。
通过fork()复制的进程都是一个独立的进程,每个进程中有着独立而全新的V8实例。
- 方案二:在主进程中创建全局变量,并监听包含notifyRequest的消息对子进程的调用进行统计分析。
app.js process.send({cmd:'notifyRequest'});//记录子进程调用次数使用返回notifyRequest消息
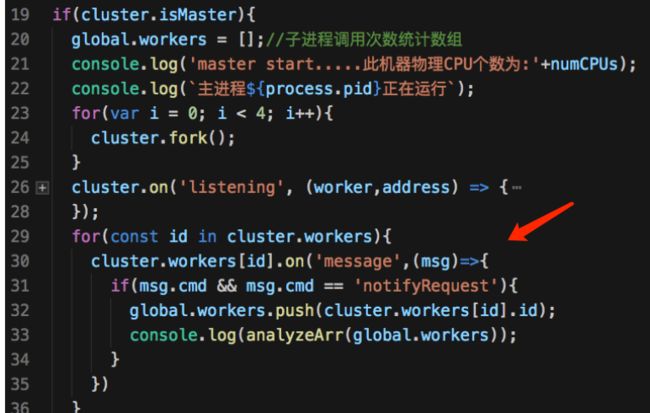
监控结果展示:
根据监控结果展示,发现Node.js的集群模式已经实现了负载均衡。
参考:
http://nodejs.cn/api/cluster.html#cluster_event_message
http://nodejs.cn/api/child_process.html
Q1:为什么方案二能统计到所有进程调度到情况?
- 在app.js中使用
app.use((req, res, next)=>{
process.send({cmd:'notifyRequest'});//记录子进程调用次数使用
console.log(`工作进程${cluster.worker.id} 正在端口${cluster.worker.process.pid}运行`);
next();
})
是为了在每次请求(app.use()匹配了所有/路由)的时候发送特定信息给各进程。
- 在主进程中创建全局变量
global.workers = [];//子进程调用次数统计数组 - 各个工作进程中监听message消息,只要有进程接受到请求信息就将当前进程的idpush到全局变量中,并对全局变量中的信息进行统计分析。
如果Node.js进程是通过进程间通信产生的,那么,process.send()方法可以用来给父进程发送消息。 接收到的消息被视为父进程的ChildProcess对象上的一个'message'事件。
如果Node.js进程不是通过进程间通信产生的, process.send() 会是undefined。
所以说主进程和各工作进程之间是通过消息传递内容,而不是共享或直接操作相关资源。⚠️通过fork()或者其它API创建子进程后,为实现父子进程之间的通信,父进程和子进程之间会创建IPC通道(通过IPC通道,父子进程之间才能通过message和send()传递消息)。
Q:负载均衡是如何实现的?
Node.js在实现负载均衡上有至少两种处理方式:
- 抢占式策略
- Round-Robin 轮叫调度
由于单个Node程序仅仅利用单核CPU,因此为了更好利用系统资源就需要fork多个Node进程来执行HTTP服务器逻辑,所以Node内建模块提供了
child_process和cluster模块。
Q: child_process和cluster模块的区别
- 利用child_process模块,我们可以执行shell命令,可以fork子进程执行代码,也可以直接执行二进制文件;
- 利用cluster模块,使用node封装好的API、IPC通道和调度机可以非常简单的创建包括一个master进程下HTTP代理服务器 + 多个worker进程多个HTTP应用服务器的架构,并提供两种调度子进程算法。
Q:多进程之间的共享Session实现。
背景描述:在项目接入cluster模块实现多进程处理后,发现项目启动后,会出现请求异常(Session丢失)导致页面空白。
分析发现是因为在进入系统后,会有多个请求,各请求可能被转发到不同到工作进程(不同的进程是不同的实例),因此会出现请求中携带的Session丢失,导致异常。查看解决方案发现,Express模块提供了express-session模块,可保存session。
var express = require('express');
var cookieParser = require('cookie-parser');
var session = require('express-session');
var RedisStore = require('connect-redis')(session);
app.use(session({
'secret': '12345',
'name': 'fecarApp', //这里的name值得是cookie的name,默认cookie的name是:connect.sid
'cookie': { maxAge: 8000000 }, //设置maxAge是80000ms,即80s后session和相应的cookie失效过期
'resave': false,
'saveUninitialized': true,
'store': new RedisStore(options),
genid: function (req) {
// 如果没有 ticket 就随机生成
if (!req.query.ticket) return uid(24)
// 如果有 ticket 就把 ticket MD5加密返回
return MD5(req.query.ticket)
}
}));
参考:
https://www.cnblogs.com/chenchenluo/p/4197181.html
Node.jsos模块获取CPU信息
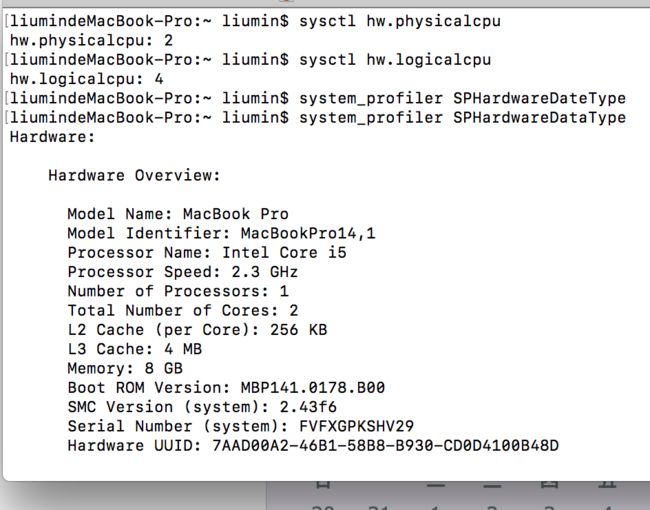
require('os').cpus();返回一个对象数组,如下图所示,包含所安装的每个 CPU/内核的信息。
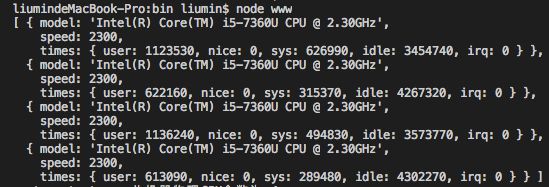
require('os').cpus().length;返回是总核数(总核数 = 物理CPU个数 X 每颗物理CPU的核数)。
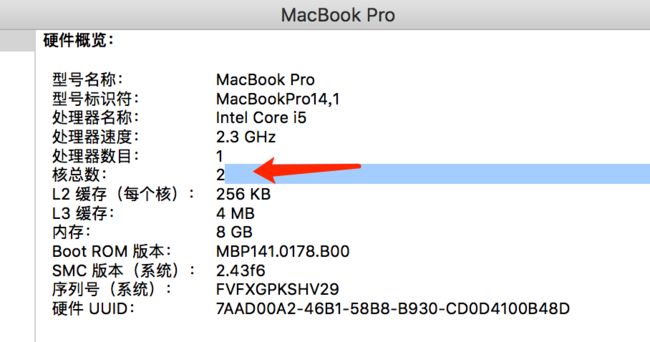
拿我本机来说,查看系统配置发现核总数为2(物理CPU数目)。使用如上代码查看发现是4(核总数),说明是双核CPU。
# 总核数 = 物理CPU个数 X 每颗物理CPU的核数
# 总逻辑CPU数 = 物理CPU个数 X 每颗物理CPU的核数 X 超线程数
# 查看物理CPU个数
cat /proc/cpuinfo| grep "physical id"| sort| uniq| wc -l
# 查看每个物理CPU中core的个数(即核数)
cat /proc/cpuinfo| grep "cpu cores"| uniq
# 查看逻辑CPU的个数
cat /proc/cpuinfo| grep "processor"| wc -l
参考
https://www.cnblogs.com/zmxmumu/p/6179503.html
https://blog.csdn.net/feijiges/article/details/76860372
https://segmentfault.com/a/1190000016169207
https://www.cnblogs.com/emanlee/p/3587571.html
Node.js采取cluster模块创建多进程后无法开启调试模式