机器学习——数字图像与机器视觉2
目录酱
- 一、颜色空间转换
-
- 1.彩色图片转灰度图片
- 2.彩色图像(RGB)转为HSV、HSI 格式
- 二、切割车牌
- 三、总结
- 参考链接
一、颜色空间转换
1.彩色图片转灰度图片
- 首先准备一张彩色图片
- 导包及文件路径
#文件路径
#导入相关包
import cv2
import numpy as np
source_path="biaco.png"
- 利用openCV读取为灰度图片
#使用opencv
#直接读取灰度图片
img=cv2.imread(source_path,0)
#也可以先读取彩色图片再转为灰度图片
#cv_read=cv2.imread(source_path)
#灰度化cv_gray=cv2.cvtColor(cv_read,cv2.COLOR_BGR2GRAY)
img = cv2.resize(img,None,fx=0.5,fy=0.5)
cv2.imshow('biaco',img)
cv2.waitKey(0)

- 不使用opencv的转换函数
#不使用opencv
img=cv2.imread(source_path)
row,col,channel=img.shape
img_gray=np.zeros((row,col))
for r in range(row):
for l in range(col):
img_gray[r,l]=1/3*cv_read[r,l,0]+1/3*cv_read[r,l,1]+1/3*cv_read[r,l,2]
#对图片进行缩放
img_show = cv2.resize(img_gray,None,fx=0.5,fy=0.5)
cv2.imshow("biaco",img_show.astype("uint8"))
cv2.waitKey(0)

2.彩色图像(RGB)转为HSV、HSI 格式
- HSV颜色空间介绍
HSV(Hue, Saturation, Value)是根据颜色的直观特性由A. R. Smith在1978年创建的一种颜色空间, 也称六角锥体模型
色调H
用角度度量,取值范围为0°~360°,从红色开始按逆时针方向计算,红色为0°,绿色为120°,蓝色为240°。它们的补色是:黄色为60°,青色为180°,紫色为300°;
饱和度S
饱和度S表示颜色接近光谱色的程度。一种颜色,可以看成是某种光谱色与白色混合的结果。其中光谱色所占的比例愈大,颜色接近光谱色的程度就愈高,颜色的饱和度也就愈高。饱和度高,颜色则深而艳。光谱色的白光成分为0,饱和度达到最高。通常取值范围为0%~100%,值越大,颜色越饱和。
明度V
明度表示颜色明亮的程度,对于光源色,明度值与发光体的光亮度有关;对于物体色,此值和物体的透射比或反射比有关。通常取值范围为0%(黑)到100%(白)。
- 转换代码
#使用opencv
#直接读取图片
cv_read=cv2.imread(source_path)
#转化为hsv格式
img_hsv=cv2.cvtColor(cv_read,cv2.COLOR_BGR2HSV)
#对图片进行缩放
img = cv2.resize(img_hsv,None,fx=0.5,fy=0.5)
cv2.imshow('biaco',img)
cv2.waitKey(0)

- HSI颜色空间介绍
HSI是指一个数字图像的模型,是美国色彩学家孟塞尔(H.A.Munsell)于1915年提出的,它反映了人的视觉系统感知彩色的方式,以色调、饱和度和亮度三种基本特征量来感知颜色。
HSI模型的建立基于两个重要的事实:第一个,分量与图像的彩色信息无关;第二个,H和S分量与人感受颜色的方式是紧密相联的。这些特点使得HSI模型非常适合彩色特性检测与分析。
色调H(Hue):与光波的频率有关,它表示人的感官对不同颜色的感受,如红色、绿色、蓝色等,它也可表示一定范围的颜色,如暖色、冷色等。
饱和度S(Saturation):表示颜色的纯度,纯光谱色是完全饱和的,加入白光会稀释饱和度。饱和度越大,颜色看起来就会越鲜艳,反之亦然。
亮度I(Intensity):对应成像亮度和图像灰度,是颜色的明亮程度。
- opencv没有直接将RBG转化为HSI的函数,定义函数转换
def RBG_to_HSI(rgb_img):
"""
: param rgb_img: RGB彩色图像
: return : HSI图像
"""
pi=3.14
#保存原始图像的行列数
row=np.shape(rgb_img)[0]
col=np.shape(rgb_img)[1]
#对原始图像进行复制
hsi_img=rgb_img.copy()
#对图像进行通道拆分
B,G,R=cv2.split(rgb_img)
#把通道归一化到[0,1]
[B,G,R]=[i/255.0 for i in ([B,G,R])]
H=np.zeros((row,col))#定义H通道
I=(R+G+B)/3.0 #计算I通道
S=np.zeros((row,col))#定义S通道
for i in range(row):
den = np.sqrt((R[i]-G[i])**2+(R[i]-B[i])*(G[i]-B[i]))
thetha=np.arccos(0.5*(R[i]-B[i]+R[i]-G[i])/den)#计算夹角
h=np.zeros(col) #定义临时数组
#den>0且G>=B的元素h赋值为thetha
h[B[i]<=G[i]]=thetha[B[i]<=G[i]]
#den>0且G<=B的元素h赋值为thetha
h[G[i]<=B[i]]=2*np.pi-thetha[G[i]<=B[i]]
#den<0的元素h赋值为0
h[den==0]=0
H[i]=h/(2*np.pi) #弧度化之后赋值给H通道
for i in range(row):
min_=[]
#找出每组RGB的最小值
for j in range(col):
arr=[B[i][j],G[i][j],R[i][j]]
min_.append(np.min(arr))
min_=np.array(min_)
#计算S通道
S[i]=1-min_*3/(R[i]+B[i]+G[i])
#I为0的值直接赋值0
S[i][R[i]+B[i]+G[i]==0]=0
#扩充到255以方便显示,一般H分量在[0,2pi]之间,S和I在[0,1]之间
hsi_img[:,:,0]=H*255/2/3.14
hsi_img[:,:,1]=S*255
hsi_img[:,:,2]=I*255
return hsi_img
- 调用函数
#使用opencv
#读取图片
cv_read=cv2.imread(source_path)
img_hsi=RBG_to_HSI(cv_read)
#对图片进行缩放
img = cv2.resize(img_hsi,None,fx=0.5,fy=0.5)
cv2.imshow('biaco',img)
cv2.waitKey(0)

二、切割车牌
- 读取车牌
#导入相关包
import cv2
import numpy as np
import os
pic_folder='./'
pic_one="car_board.png"
save_path='./opencv/'
#创建文件夹
def mkdir(path):
folder=os.path.exists(path)
if not folder:#判断是否存在
os.makedirs(path)
#图片路径构建及创建文件夹
plate_numbers=pic_folder+pic_one
s_path=save_path+pic_one
mkdir(s_path)
plate=cv2.imdecode(np.fromfile(plate_numbers,dtype=np.uint8),-1)
cv2.imshow("cell",plate)
cv2.waitKey(0)

- 对图片进行灰度化和二值化处理
#对图片进行处理,进行二值化
plate_gauss=cv2.GaussianBlur(plate,(5,5),0)#高斯降噪
plate_gray=cv2.cvtColor(plate_gauss,cv2.COLOR_BGR2GRAY)#灰度化
thre,plate_bw=cv2.threshold(plate_gray,170,255,cv2.THRESH_BINARY)#二值化
cv2.imshow("cell",plate_bw)
cv2.waitKey(0)

- 闭运算,使字连在一起,变成一个整体
#闭运算,填充空洞
#构造一个全1的5*5的矩阵
kernel=np.ones((8,8),int)#设置形态学操作卷积的大小
plate_close=cv2.morphologyEx(plate_bw,cv2.MORPH_CLOSE,kernel)
cv2.imshow("cell",plate_close)
cv2.waitKey(0)

- 腐蚀运算,去掉中间那个螺丝带来的影响
#腐蚀运算,消除掉中间那颗螺丝的影响
#构造一个全1的5*5的矩阵
kernel=np.ones((3,3),int)#设置形态学操作卷积的大小
plate_corr=cv2.erode(plate_close,kernel,iterations=1)
cv2.imshow("cell",plate_corr)
cv2.waitKey(0)

- 定义一个切割并保存的函数
#切割图片并保存
def cutting(start,end,order,src,path):
dst=src[:,start-3:end+3]
file_name=path+str(order)+'.jpg'
cv2.imencode(".jpg",dst)[1].tofile(file_name)
- 现在就可以利用findContours来切割了
image,plate_count,hir=cv2.findContours(plate_corr,cv2.RETR_EXTERNAL ,cv2.CHAIN_APPROX_NONE)
#检测所有轮廓,所有轮廓建立一个等级树结构。
plate_read=cv2.imdecode(np.fromfile(plate_numbers,dtype=np.uint8),-1)
result=plate_read
for i in range(len(plate_count)):
cnt=plate_count[i]
x,y,w,h=cv2.boundingRect(cnt)
mkdir(save_path)
cutting(x,x+w,i,plate_read,save_path)
- 不使用opencv,手动切割,实现代码
#flag是用来判断字符个数的,当flag为7时,就代表已经全部识别完了
#word是用来判断一个字的开始和结束,开始时word会加1,结束时word也会加一,所以为2就检测完了一个字
flag=0
word=0
word_start=0
word_end=0
word_color=False#判断某一列中是否有字体的颜色
save_path_a=save_path+'/artificial/'
plate_read=cv2.imdecode(np.fromfile(plate_numbers,dtype=np.uint8),-1)
for i in range(len(plate_corr[0])):#遍历每一列
word_color=False
if 255 in plate_corr[:,i]:
word_color=True
if word_color==True and word==0:#如果检测到字体的颜色,word+1
word+=1
word_start=i
elif word_color==False and word==1:#判断字结束
word+=1
word_end=i+3
flag+=1
mkdir(save_path_a)
cutting(word_start,word_end,flag,plate_read,save_path_a)
if word==2:
word=0
word_start=0
word_end=0
if flag==7:
break
- 文件夹内容,两者的顺序不一样,利用opencv的寻找轮廓的函数并不是从左到右按顺序来的,而手动切割则是按照顺序来的
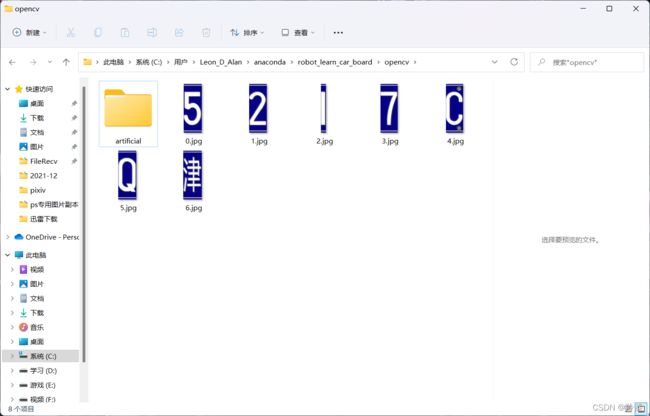
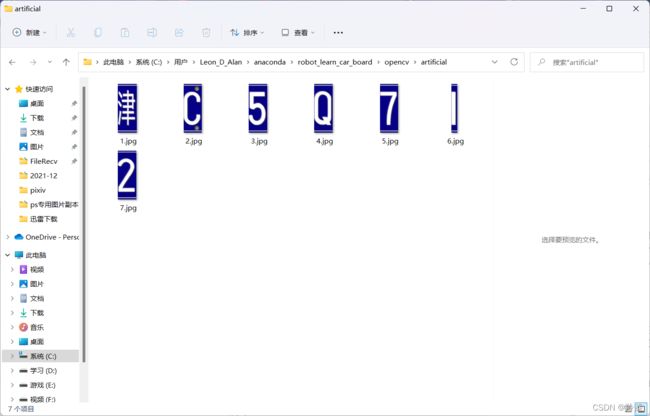
三、总结
其实用opencv操作并不难,看一下转化之后的数据的内容,就基本明白完成目标对应的原理是什么了,不过对图片进行调参还是比较耗时间
参考链接
https://blog.csdn.net/junseven164/article/details/121714300