elasticsearch全文检索
示例:
1.准备数据
使用kibana,准备两条数据
PUT /testindex/users/102
{
"name":"zhangsan",
"age":25
}
PUT /testindex/users/101
{
"name":"ZHANgsan",
"age":24
}
2.查询示例
GET /testindex/users/_search
{
"query": {
"match": {
"name": "谁是zhangsan啊"
}
}
}
我们发现两条数据都被查询了出来。那么es是如何实现的呢?
分析器(analyzer )
官网描述.
概括来说分析器一般有三部分组成,
1、字符过滤器(Character Filters)
2、分词器(Tokenizers)
3、分词过滤器(Token filters)
ES 给我们内置了若干分析器类型。其中常用的是标准分析器,名称叫做
"standard"。我们肯定需要扩展,并使用一些第三方分析器。
不过我们得先了解标准分析器是 怎么工作的。Anaylyzer通常由一个Tokenizer (怎么分词), 以及若干个 TokenFilter(过滤分词)、 Character Filters(过滤字符)组成。
下面我们使用具体例子来学习一下
1.标准分析器(es内置)
POST _analyze
{
"analyzer": "standard",
"text": "谁是zhangsan啊"
}

2.简单分析器
POST _analyze
{
"analyzer": "simple",
"text": "谁是zHangsan啊"
}
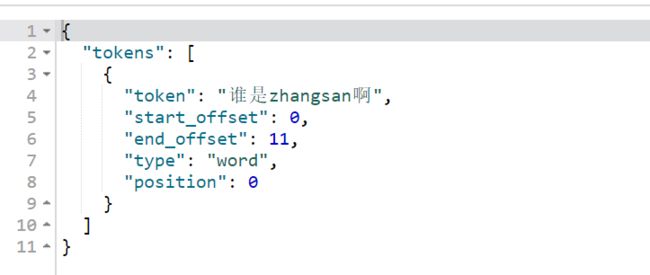
3.标准分词器(注意框选中的单词)
POST _analyze
{
"tokenizer": "standard",
"text": "谁是zhANgSan啊"
}
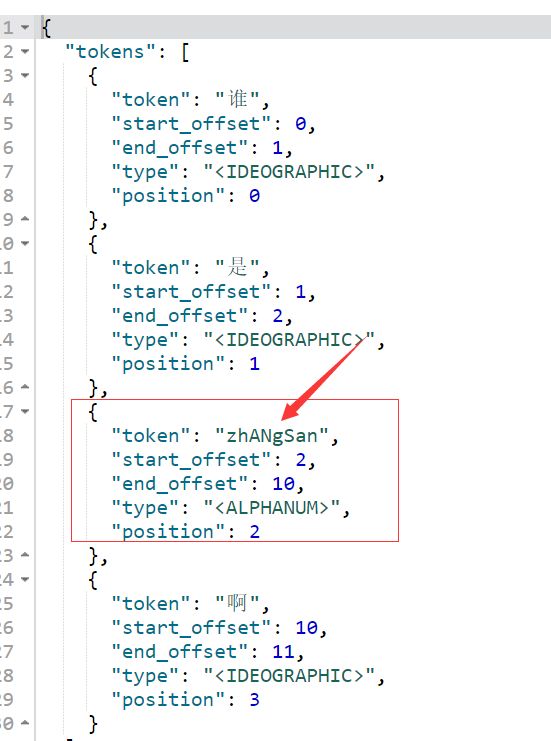
显然仅仅使用标准分词器并不能做到大小写的忽略。
4.组合使用
POST _analyze
{
"tokenizer": "standard",
"filter": ["lowercase"],
"char_filter": ["html_strip"],
"text": "谁是zhANgSan啊"
}
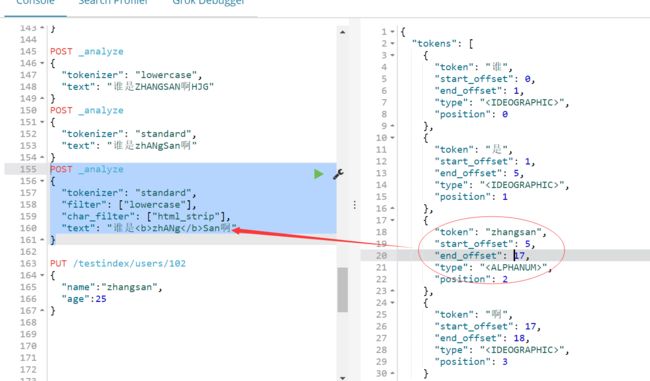
在运行结果中,我们看到他和我们预想的结果是一致的。我们使用的标准的分词器("tokenizer": "standard",)使中文和单词分开,使用小写分词过滤器("filter": ["lowercase"], )使单词小写化,使用字符过滤器("char_filter": ["html_strip"], )使text中的html标签过滤掉。最终的效果是和标准分析器("analyzer": "standard",)是一致的。
通过上面的例子,我们显然可以知道,我们是可以根据自己的业务自定义分析器的。
我们自定义一个自己的分析器
PUT testindex
{
"settings":
{
"analysis": {
"analyzer": {
"my-analyzer":{
"type":"custom",
"tokenizer":"standard",
"char_filter":["html_strip"],
"filter":["lowercase"]
}
}
}
}
}
这样执行会报错,因为索引已经存在了。而自定义分析器需要在索引建立之前建立。所以这样又引出了我们要学习的另一个知识点:索引的备份和恢复。
索引的备份和恢复
我使用的是docker 拉取sebp/elk镜像来搭建的。运行容器正常之后,我们来进行下面的操作。
1.配置elasticsearch.yml文件
进入容器
docker exec -it elk /bin.bash
sudo vim /opt/elasticsearch/config/elasticsearch.yml
//在配置文件最后加上,path.repo: /var/backups
path.repo: /var/backups
2.创建仓库
//创建仓库
PUT /_snapshot/mybak
{
"type": "fs",
"settings": {
"location": "/var/backups/testindex"
}
}
//查看仓库信息
GET /_snapshot/mybak
3.备份索引
//备份索引
PUT /_snapshot/mybak/bak1?wait_for_completion=true
{
"indices": "testindex"
}
4.删除索引和自定义分析器
#删除索引
DELETE testindex
#自定义分析器
PUT testindex
{
"settings":
{
"analysis": {
"analyzer": {
"my-analyzer":{
"type":"custom",
"tokenizer":"standard",
"char_filter":["html_strip"],
"filter":["lowercase"]
}
}
}
}
}
5.备份和恢复
#备份恢复
#1.关闭索引
POST testindex/_close
#2.恢复
POST _snapshot/mybak/bak2/_restore?wait_for_completion=true
{
"indices": "testindex"
}
#3.打开索引
POST testindex/_open