一、Mybatis 概念
- Mybatis 是一款优秀得持久层框架,它支持自定义 SQL、存储过程以及高级映射。MyBatis 免除了几乎所有得 JDBC 代码以及设置参数和获取结果集的工作。Mybatis 可以通过简单的 XML 或注解来配置和映射原始类型、接口和 Java POJO 为数据库中的记录。
- ORM (Object Relational Mapping):对象关系映射
- Mybatis 是半自动花的 ORM 框架,依赖一个配置文件,将数据库和 Java POJO 中的实体类的关系解耦,可以在内部自由编写 SQL 语句。
- 中文文档:https://mybatis.org/mybatis-3/zh/index.html
- Github:https://github.com/mybatis/mybatis-3
二、Mybatis 配置开发
2.1、开发步骤
1、pom 文件导入相关依赖
maven 仓库获取相关依赖:https://mvnrepository.com/
2、编写核心配置文件
3、编写 MyBatis 工具类
- 中文官方文档有示范代码,其主要作用是从 XML 文件中构建 SqlSessionFactory 的实例。
import org.apache.ibatis.io.Resources;
import org.apache.ibatis.session.SqlSession;
import org.apache.ibatis.session.SqlSessionFactory;
import org.apache.ibatis.session.SqlSessionFactoryBuilder;
import java.io.IOException;
import java.io.InputStream;
public class MybatisUtils {
private static SqlSessionFactory sqlSessionFactory;
static {
try {
String resource = "mybatis-config.xml";
InputStream inputStream = Resources.getResourceAsStream(resource);
sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
} catch (IOException e) {
e.printStackTrace();
}
}
//获取SqlSession连接 public static SqlSession getSession(){
return sqlSessionFactory.openSession();
}
}
4、创建实体类
- 与数据库中定义的 字段进行映射
5、定义 Dao 层的接口
6、编写 Mapper 配置文件
- 接口实现类由原来的UserDaoImpl转变成一个Mapper配置文件。
2.2、核心配置文件解析
1、常用标签
configuration(配置):核心根标签
properties(属性): —— 引入数据库连接的配置文件
settings(设置):配置 日志
typeAliases(类型别名 :起别名
typeHandlers(类型处理器)
objectFactory(对象工厂)
plugins(插件)
environments(环境配置)
environment(环境变量)
transactionManager(事务管理器)
dataSource(数据源)
databaseIdProvider(数据库厂商标识)
mappers(映射器) :引入映射配置文件
2、Properties 优化
- 数据库这些属性都是可外部配置且可动态替换的,既可以在典型的 Java 属性文件中配置,亦可通过 properties 元素的子元素来传递。具体的官方文档
- 优化步骤
- 第一步 ; 在资源目录下新建一个db.properties
- 第二步 : 将文件导入properties 配置文件,通过 导入
- 配置文件优先级问题:如果两个文件有同一个字段,优先使用外部配置文件的。
3、TypeAliases 优化
- 类型别名是为 Java 类型设置一个短的名字。它只和 XML 配置有关,存在的意义仅在于用来减少类完全限定名的冗余。
- 也可以指定一个包名,MyBatis 会在包名下面搜索需要的 Java Bean。它的默认别名就为这个类的类名,首字母小写!
- 若有注解,则别名为其注解值。
4、environments 环境配置
- 配置 MyBatis 的多套运行环境,将 SQL 映射到多个不同的数据库上,但必须指定其中一个默认运行环境(通过 default 指定)
- MyBatis 默认的事务管理器是 JDBC,默认连接池是 POOLED
5、mappers 映射器
- 映射器 : 定义映射SQL语句文件
- 既然 MyBatis 的行为其他元素已经配置完了,我们现在就要定义 SQL 映射语句了。但是首先我们需要告诉 MyBatis 到哪里去找到这些语句。Java 在自动查找这方面没有提供一个很好的方法,所以最佳的方式是告诉 MyBatis 到哪里去找映射文件。你可以使用相对于类路径的资源引用, 或完全限定资源定位符(包括 file:/// 的 URL),或类名和包名等。映射器是MyBatis中最核心的组件之一,在MyBatis 3之前,只支持xml映射器,即:所有的SQL语句都必须在xml文件中配置。而从MyBatis 3开始,还支持接口映射器,这种映射器方式允许以Java代码的方式注解定义SQL语句,非常简洁。
- 引入资源方式
2.3、Mapper 映射文件解析
1、常用标签
mapper:核心根标签
namespace 属性:名称空间
select :查询功能标签
id 属性:唯一标识
resultType:指定结果映射对象类型
parameterType:指定参数映射对象类型(在 MyBatis 内部会自动识别参数,并推导其属性,故该参数可以不配置)
2、namespace 详解
- namespace中文意思:命名空间,作用如下:
- namespace的命名必须跟某个接口同名
- 接口中的方法与映射文件中sql语句id应该一一对应
- namespace和子元素的id联合保证唯一 , 区别不同的mapper
- 绑定DAO接口
- namespace命名规则 : 包名+类名
2.4、作用域(Scope)和生命周期
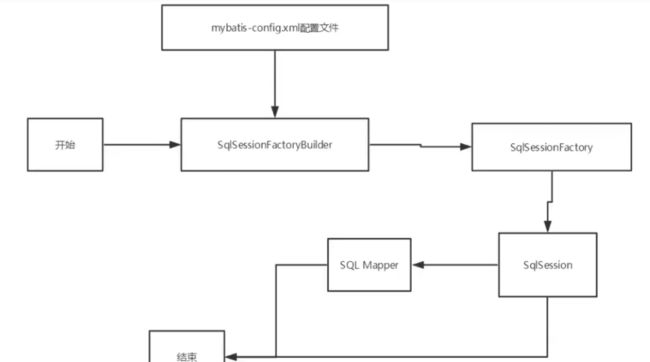
1、生命周期
2、作用域
- SqlSessionFactoryBuilder 的作用在于创建 SqlSessionFactory,创建成功后,SqlSessionFactoryBuilder 就失去了作用,所以它只能存在于创建 SqlSessionFactory 的方法中,而不要让其长期存在。因此 SqlSessionFactoryBuilder 实例的最佳作用域是方法作用域(也就是局部方法变量)。
- SqlSessionFactory 可以被认为是一个数据库连接池,它的作用是创建 SqlSession 接口对象。因为 MyBatis 的本质就是 Java 对数据库的操作,所以 SqlSessionFactory 的生命周期存在于整个 MyBatis 的应用之中,所以一旦创建了 SqlSessionFactory,就要长期保存它,直至不再使用 MyBatis 应用,所以可以认为 SqlSessionFactory 的生命周期就等同于 MyBatis 的应用周期。
- 由于 SqlSessionFactory 是一个对数据库的连接池,所以它占据着数据库的连接资源。如果创建多个 SqlSessionFactory,那么就存在多个数据库连接池,这样不利于对数据库资源的控制,也会导致数据库连接资源被消耗光,出现系统宕机等情况,所以尽量避免发生这样的情况。
因此在一般的应用中我们往往希望 SqlSessionFactory 作为一个单例,让它在应用中被共享。所以说 SqlSessionFactory 的最佳作用域是应用作用域。 - 如果说 SqlSessionFactory 相当于数据库连接池,那么 SqlSession 就相当于一个数据库连接(Connection 对象),你可以在一个事务里面执行多条 SQL,然后通过它的 commit、rollback 等方法,提交或者回滚事务。所以它应该存活在一个业务请求中,处理完整个请求后,应该关闭这条连接,让它归还给 SqlSessionFactory,否则数据库资源就很快被耗费精光,系统就会瘫痪,所以用 try...catch...finally... 语句来保证其正确关闭。
- 所以 SqlSession 的最佳的作用域是请求或方法作用域。
2.5、解决属性名和字段名不一致问题
1、为列名指定别名 , 别名和java实体类的属性名一致
2、使用结果集映射->ResultMap 【推荐】
- 自动映射
- resultMap 元素是 MyBatis 中最重要最强大的元素。它可以让你从 90% 的 JDBC ResultSets 数据提取代码中解放出来。
- 实际上,在为一些比如连接的复杂语句编写映射代码的时候,一份 resultMap 能够代替实现同等功能的长达数千行的代码。
- ResultMap 的设计思想是,对于简单的语句根本不需要配置显式的结果映射,而对于复杂一点的语句只需要描述它们的关系就行了。
你已经见过简单映射语句的示例了,但并没有显式指定 resultMap。比如:
-
上述语句只是简单地将所有的列映射到 HashMap 的键上,这由 resultType 属性指定。虽然在大部分情况下都够用,但是 HashMap 不是一个很好的模型。你的程序更可能会使用 JavaBean 或 POJO(Plain Old Java Objects,普通老式 Java 对象)作为模型。
ResultMap 最优秀的地方在于,虽然你已经对它相当了解了,但是根本就不需要显式地用到他们。 -
手动映射
1、返回值类型为resultMap
2、编写resultMap,实现手动映射!
三、注解开发
3.1、开发步骤
1、pom 文件导入相关依赖
2、编写核心配置文件
- 配置文件内容和配置开发一致
- 映射器引入方法更改为通过类引入:
3、编写 MyBatis 工具类
4、创建实体类与数据库中字段对应
5、编写接口
6、在接口方法上利用注解声明 SQL 语句。
3.2、常用注解
- @Insert:新增
- @Update:更新
- @Delete:删除
- @Select :查询
- @Results:多个结果集封装
- @One:实现一对一结果集封装
- @Many:实现一对多结果集封装
3.3、注解解析
1、@Param注解用于给方法参数起一个名字。以下是总结的使用原则:
- 在方法只接受一个参数的情况下,可以不使用@Param。
- 在方法接受多个参数的情况下,建议一定要使用@Param注解给参数命名。
- 如果参数是 JavaBean , 则不能使用@Param。
- 不使用@Param注解时,参数只能有一个,并且是Javabean。
2、# 与 $ 的区别
- '#'{} 的作用主要是替换预编译语句(PrepareStatement)中的占位符? 【推荐使用】
INSERT INTO user (name) VALUES (#{name});
INSERT INTO user (name) VALUES (?);
- ${} 的作用是直接进行字符串替换
INSERT INTO user (name) VALUES ('${name}');
INSERT INTO user (name) VALUES ('kuangshen');
- 使用注解和配置文件协同开发,才是MyBatis的最佳实践!
四、多对一处理
4.1、按找结果嵌套处理
4.2、按照查询嵌套处理
2、小结
- 按照查询进行嵌套处理就像SQL中的子查询
- 按照结果进行嵌套处理就像SQL中的联表查询
五、一对多的处理
5.1、按结果嵌套处理
1、TeacherMapper接口编写方法
//获取指定老师,及老师下的所有学生public Teacher getTeacher(int id);
2、编写接口对应的Mapper配置文件
5.2、按照查询嵌套处理
1、TeacherMapper接口编写方法
public Teacher getTeacher2(int id);
2、编写接口对应的Mapper配置文件
3、小结
1、关联-association
2、集合-collection
3、所以association是用于一对一和多对一,而collection是用于一对多的关系
4、JavaType和ofType都是用来指定对象类型的
- JavaType是用来指定pojo中属性的类型
- ofType指定的是映射到list集合属性中pojo的类型。
六、动态 SQL
6.1、动态 SQL 之
1、标签
- < if >:条件判断标签
- < if test = "判断条件"> and 查询条件拼接 (注意标点符号)
2、注意
- 单独使用 标签,拼接的 and 语句会使得 SQL 语句报错。
3、解决方案
- :条件标签
- 如果有动态条件,则使用该标签代替 where
- 这个 标签会知道如果它包含的标签中有返回值的话,它就插入一个‘where’。此外,如果标签返回的内容是以AND 或OR 开头的,则它会剔除掉。
6.2、动态 SQL 之
update blog
title = #{title},
author = #{author}
where id = #{id};
6.3、动态 SQL 之
- 有时候,我们不想用到所有的查询条件,只想选择其中的一个,查询条件有一个满足即可,使用 choose 标签可以解决此类问题,类似于 Java 的 switch 语句
6.4、动态 SQL 之
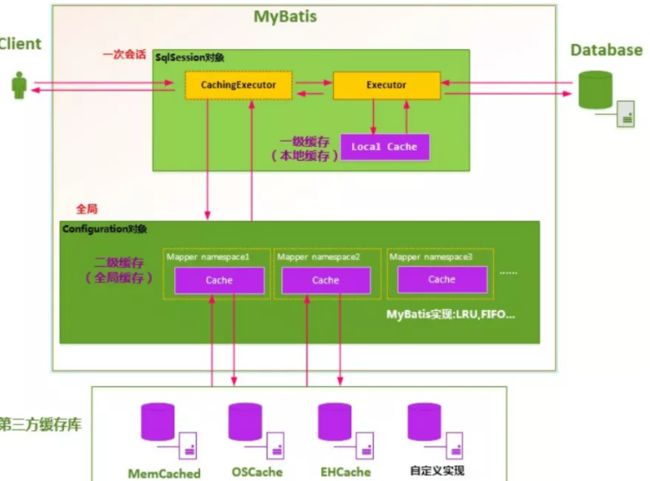
七、缓存
7.1、缓存概念
1、什么是缓存
- 存在内存中的临时数据
- 将用户经常查询的数据放在缓存(内存)中,用户去查询数据就不会从磁盘上(关系型数据库数据文件)查询,从缓存中查询,从而提高查询效率,解决了高并发系统的性能问题。
2、为什么使用缓存
- 减少和数据库的交互次数,减少系统开销,提高系统效率
3、什么样的数据能使用缓存?
- 经常查询并且不经常改变的数据。
7.2、一级缓存
1、一级缓存特性
- 默认情况下,只用一级缓存开启。(SqlSession 级别的缓存,也称为本地缓存)
- Spring 中,一级缓存会失效。
- 与数据库同一次会话期间查询到的数据会放在本地缓存中。
- 以后如果需要获取相同的数据,直接从缓存中拿,不需要在去查询数据库。
2、一级缓存失效的四种状况
- SqlSession 不同
- 每个 SqlSession 中的缓存相互独立
- SqlSession 相同,查询条件不同
- 当前缓存中,不存在这个数据
- SqlSession 相同,两次查询之间执行了增删改操作
- 增删改操作会,清除缓存
- SqlSession 相同,手动清除一级缓存
7.3、二级缓存
1、二级缓存特性
- 二级缓存也叫全局缓存,一级缓存作用域太低了,所以诞生了二级缓存
- 基于namespace级别的缓存,一个名称空间,对应一个二级缓存;
- 工作机制
- 一个会话查询一条数据,这个数据就会被放在当前会话的一级缓存中;
- 如果当前会话关闭了,这个会话对应的一级缓存就没了;但是我们想要的是,会话关闭了,一级缓存中的数据被保存到二级缓存中;
- 新的会话查询信息,就可以从二级缓存中获取内容;
- 不同的mapper查出的数据会放在自己对应的缓存(map)中;
2、结论
- 只要开启了二级缓存,我们在同一个Mapper中的查询,可以在二级缓存中拿到数据
- 查出的数据都会被默认先放在一级缓存中
- 只有会话提交或者关闭以后,一级缓存中的数据才会转到二级缓存中
3、缓存原理图