基于VGG-Face的年龄估计(论文总结与代码解释)

目录
1.本文改进
2.模型结构
3.训练模型
4.预测数据
5.实验结果
6.模型比较
7.结论分析
8.数据集分析
9.完整代码
1.本文改进
本文主要是使用VGG-Face模型(卷积层不变,改变全连接层)在Adience数据库上进行年龄估计。
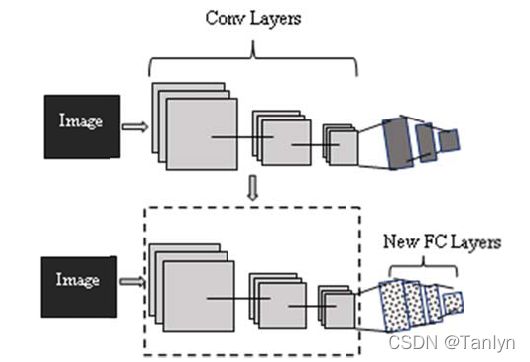
在深度神经网络中,由于深度神经网络有数百万个参数,由于它们有若干层和数千个节点,因此过拟合问题变得更加严重。所有用于年龄分类和预测的数据库都相对较小。它们在大小上无法与其他用于人脸识别和图像分类任务的数据库相提并论。为了克服过度拟合的问题,我们通过使用在一个非常大的数据库上训练的人脸识别深度CNN模型来构建我们提出的用于年龄估计的深度CNN。
2.模型结构
有一些CNN模型被成功地训练用于人脸识别任务。在这篇论文中,使用在2015年提出的VGG-face模型,该模型在LFW]和YFT数据库上取得了最先进的结果。VGG-Face由11个层、8个卷积层和3个全连接层组成。如下图所示,每个卷积层后面都有一个整流层(ReLU函数),在每个卷积块的末端运行一个max pool层。 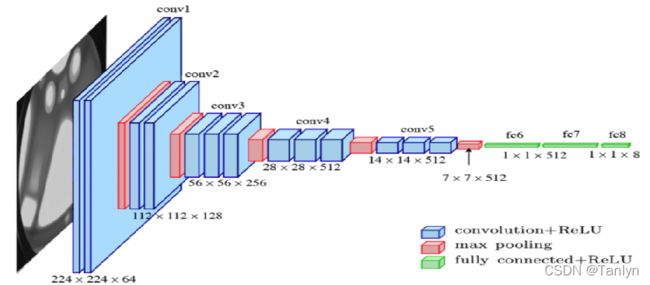
VGG-Face模型在2015年的Deep Face Recognition论文中已提出,本文就是使用该模型进行年龄估计。VGG-Face模型如下: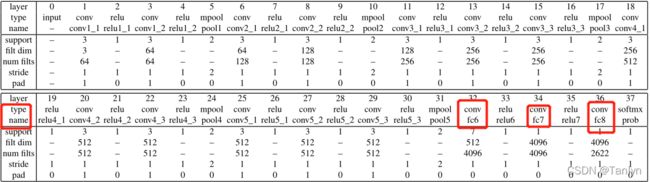
本文保持VGG- Face模型的卷积层不变,在前两个Conv的relu函数之后添加BatchNorm2d进行数据的归一化处理,这使得数据在进行Relu之前不会因为数据过大而导致网络性能的不稳定。 同时用四个新的全连接层替换全连接层,构建并重新训练VGG- Face模型用于年龄估计。 前三个全连接层之后是dropout=0.5层和relu层。 第一全连接层尺寸为4096,第二、第三全连接层尺寸为5000。 最后一个全连接层表示一个N-way类预测器,其中N表示数据库中标签(类)的数量,该模型输出层的输出大小表示年龄标签的数量为8。
注:为什么全连接层的类型也属于卷积层?因为全连接层是卷积层的一种特殊情况,其中过滤器的大小和输入数据是相同的。 卷积层可以通过改变卷积基转变为全连接层。
下面是使用pytorch实现模型结构:
卷积层:
def cnn_layers(in_channels, batch_norm=False): # 卷积层不变,不使用归一化处理
# fmt: off
config = [ # 卷积层布局
64, 64, "M", # 卷积、卷积、池化、
128, 128, "M", # 卷积、卷积、池化、
256, 256, 256, "M", # 卷积、卷积、卷积、池化、
512, 512, 512, "M", # 卷积、卷积、卷积、池化、
512, 512, 512, "M" # 卷积、卷积、卷积、池化、
] # 总共5个卷积层
layers = [] # 创建一个存放层的空列表
for v in config:
# maxpool
if v == "M": # 添加池化层
layers += [nn.MaxPool2d(kernel_size=2, stride=2)] # 2*2大小的窗口,步幅为2
# conv2d layers
else: # 否则继续添加卷积层
conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1) # 卷积层3*3
# 在前两个卷积层relu函数后面添加归一化处理
if batch_norm:
layers += [
conv2d,
nn.BatchNorm2d(v),
nn.ReLU(inplace=True),
]
else:
layers += [conv2d, nn.ReLU(inplace=True)] # 添加激活函数
# update in_channels
in_channels = v
return nn.Sequential(*layers)
# *作用在形参上,代表这个位置接收任意多个非关键字参数,转化成元组方式;*作用在实参上,代表的是将输入迭代器拆成一个个元素。全连接层:
def fc_layers(num_classes):
# fully connected layers of vgg
return nn.Sequential(
nn.Linear(512 * 7 * 7, 512),
nn.ReLU(True),
nn.Dropout(),
nn.Linear(512, 512),
nn.ReLU(True),
nn.Dropout(),
nn.Linear(512, num_classes),
)VGG16:
然后我们创建一个VGG16模型的类,全连接层和卷积层是必须要放入这个类中的,但是由于代码行数比较多,我们单独定义函数,再在类中调用。
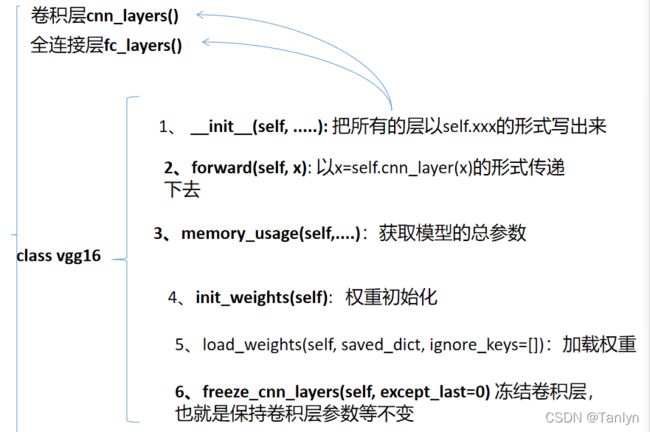
class vgg16(nn.Module): # nn.Module是nn中十分重要的类,包含网络各层的定义及forward方法
def __init__(self, num_classes, channels=3):
# __init__还是有个特殊之处,那就是它不允许有返回值
# 一般把网络中具有可学习参数的层放在构造函数__init__()中。
# 不具有可学习参数的层(如ReLU)可放在构造函数中
# vgg16 module
#
# parameters -------------------------
# - num_classes - number of outputs to predict要预测的输出数量
# - channels - number of input channels (eg. RGB:3)
# inheriting from module class
# 从模块类继承
super(vgg16, self).__init__() # 这是对继承自父类的属性进行初始化
# metadata
self.name = "vgg16"
self.num_classes = num_classes # 左边为示例属性,右边的是_init_的参数
# layers
self.features = cnn_layers(channels) # 调用卷积层
self.classifier = fc_layers(num_classes) # 调用全连接层
self.init_weights() # 权重初始化
# transfer to gpu if cuda found
if torch.cuda.is_available():
self.cuda()
def forward(self, x):
x = self.features(x)
# input首先经过self.features(x)卷积层,此时的输出x是包含batchsize维度为4的tensor,
# 即(batchsize,channels,x,y),x.size(0)指batchsize的值。
x = x.view(x.size(0), -1)
# 将前面多维度的tensor展平成一维,简化x = x.view(batchsize, -1)
# 其中batchsize指转换后有几行,而-1指在不告诉函数有多少列的情况下,根据原tensor数据和batchsize自动分配列数。
# 其实相当于x = torch.flatten(x, 1)。四维[n,c,h,w]转换成二维[n,c*h*w]
x = self.classifier(x) # 分类器
return x
def memory_usage(self):
# Get the total parameters of the model获取模型的总参数
def multiply_iter(iterable):
res = 1
for x in iterable:
res *= x
return res
def add_params(parameter):
res = 0
for x in parameter:
res += multiply_iter(x.shape)
return res
feat = add_params(self.features.parameters()) # 卷积层的参数
clsf = add_params(self.classifier.parameters()) # 全连接层的参数
total = feat + clsf # 总参数
mb_f = 4 / 1024 ** 2
print("Conv : {0}".format(feat))
print("FC : {0}".format(clsf))
print("-----------------")
print("Total : {0}".format(total))
print("Memory : {0:.2f}MB".format(total * mb_f))
print("")
def init_weights(self): # 权重初始化
for m in self.modules():
# 来判断一个对象是否是一个已知的类型,类似type()
# isinstance(object, classinfo) object -- 实例对象。
# classinfo -- 可以是直接或间接类名、基本类型或者由它们组成的元组。
if isinstance(m, nn.Conv2d): # 判断m是否为卷积层
nn.init.kaiming_normal_(
m.weight, mode="fan_out", nonlinearity="relu"
)
if m.bias is not None:
nn.init.constant_(m.bias, 0)
# tensor – n 维 torch.Tensor
# a – 该层后面一层的整流函数中负的斜率 (默认为 0,此时为 Relu)
# mode – ‘fan_in’ (default) 或者 ‘fan_out’。使用fan_in保持weights的方差在前向传播中不变;使用fan_out保持weights的方差在反向传播中不变。
# nonlinearity – 非线性函数 (nn.functional 中的名字),推荐只使用 ‘relu’ 或 ‘leaky_relu’ (default)
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1) # 用值1填充m.weight
nn.init.constant_(m.bias, 0) # 用值0填充m.bias
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01) # torch.nn.init.normal_(tensor, mean=0.0, std=1.0)
# N(mean, std^2) 用正态分布的值填充m.weight
nn.init.constant_(m.bias, 0)
def load_weights(self, saved_dict, ignore_keys=[]):
# indexable ordered dict
state_dict = self.state_dict()
saved_dict = list(saved_dict.items())
# update state_dict where pretrained dict is similar
for i, (key, val) in enumerate(state_dict.items()):
space = " " * (25 - len(str(key))) + " "
n_val = saved_dict[i][1]
if (
key not in ignore_keys
and val.shape == n_val.shape
):
state_dict[key] = n_val
print(" " + str(key) + space + "Loaded")
else:
print(" " + str(key) + space + "Ignored")
self.load_state_dict(state_dict)
def freeze_cnn_layers(self, except_last=0):
num_params = len(list(self.features.parameters())) # 卷积层总的参数个数
state_keys = [key for key in self.features.state_dict()]
"""
pytorch 中的 state_dict 是一个简单的python的字典对象,将每一层与它的对应参数建立映射关
系.(如model的每一层的weights及偏置等等)
(注意,只有那些参数可以训练的layer才会被保存到模型的state_dict中,如卷积层,线性层等等)
优化器对象Optimizer也有一个state_dict,它包含了优化器的状态以及被使用的超参数(如lr,
momentum,weight_decay等)
"""
for i, param in enumerate(self.features.parameters()): # 把所有参数自动编号
key = state_keys[i]
space = " " * (25 - len(str(key))) + " "
if num_params - i > except_last:
param.requires_grad = False # 卷积层
print(" " + str(key) + space + "Frozen")
else:
param.requires_grad = True # 全连接层
print(" " + str(key) + space + "Active")3.训练模型
输入图像被缩放到256 x 256像素,然后随机裁剪成224 x 224像素的小块。 采用随机梯度下降法对网络进行优化,最小批数为256,动量值为0.9。 此外,权重衰减设置为10-3。 在训练过程中,使用0.6的dropout rate对网络参数进行正则化。 训练以0.1的学习率开始,然后当验证集的准确性结果没有改善时,学习率降低10倍。 新添加的全连接层之间的权值采用均值为零、标准差为10-2的高斯分布初始化,而偏差初始化为零。
RGB输入图像被馈送到网络的输入层。 然后将每一隐藏层的输出作为输入馈送到下一隐藏层,直到计算出网络输出层(最后一层)的概率。 随机梯度象限法优化并找到连接层的参数,使用于估计年龄的softmax-log-loss预测最小化。 同时,卷积层的参数保持不变。 换句话说,我们优化了全连接层的参数来预测被试的年龄,而不改变卷积层的参数,卷积层是为人脸识别任务而训练和优化的。

import numpy
import torch
from torch.utils.data import DataLoader
# Dataset是一个包装类,用来将数据包装为Dataset类,然后传入DataLoader中,我们再使用DataLoader这个类来更加快捷的对数据进行操作。
# DataLoader是一个比较重要的类,它为我们提供的常用操作有:batch_size(每个batch的大小),
# shuffle(是否进行shuffle操作), num_workers(加载数据的时候使用几个子进程)
from torch.utils.data.sampler import SubsetRandomSampler
from torchvision import datasets
from torchvision import transforms
# 计算机视觉常用工具包,包含常用图像预处理、常用数据集实现、常用模型预训练。
# global variables 全局变量
# can change from outside
random_scale = (0.4, 1.0)
mean = [0.5, 0.5, 0.5]
std = [0.2, 0.2, 0.2]
def get_transforms(): # 定义一个图像变换函数做预处理
# global语句是一个声明,它保存了整个当前代码块。这意味着列出的标识符将被解释为全局标识符。
# 如果没有global,就不可能给全局变量赋值,尽管自由变量可以在没有声明global的情况下引用globals。
# 在全局语句中列出的名称不能在该全局语句文本前面的同一代码块中使用。
# 全局语句中列出的名称不能定义为形式参数,也不能定义为for循环控制目标、类定义、函数定义或import语句。
global std
global mean
global random_scale
# Compose()类,这个类的主要作用是串联多个图片变换的操作
# 将transforms列表里面的transform操作进行遍历
train_transform = transforms.Compose( # 训练数据的预处理
[
transforms.RandomResizedCrop((224, 224), scale=random_scale), # 随机长宽比裁剪
transforms.RandomHorizontalFlip(), # 依概率p水平翻转
transforms.ToTensor(),
# 将PIL Image或者 ndarray 转换为tensor,是将输入的数据shape W,H,C ——> C,W,H,并且归一化至[0-1]
transforms.Normalize(mean=mean, std=std), # 用平均值和标准偏差归一化张量图像
]
)
valid_transform = transforms.Compose( # 验证数据的预处理
[
transforms.Resize((224, 224)), # 调整图像大小
transforms.ToTensor(), # 归一化
transforms.Normalize(mean=mean, std=std), # # 用平均值和标准偏差归一化张量图像
]
)
return (train_transform, valid_transform)
def find_mean_std(train_dir):
"""
Get the mean and std per channel
very slow because of two passes
parameters -------------------------
- train_dir - path of training set 训练集路径
returns ----------------------------
- mean - mean of the dataset per channel
- std - standard deviation per channel
"""
pin_memory = True if torch.cuda.is_available() else False # 判断GPU是否可用
train_transform = transforms.Compose( # Compose()类,这个类的主要作用是串联多个图片变换的操作
# 将transforms列表里面的transform操作进行遍历
[transforms.Resize((224, 224)), transforms.ToTensor()]
) # torchvision.datasets这个包中包含MNIST、FakeData、COCO、LSUN、ImageFolder、DatasetFolder、ImageNet、CIFAR等一些常用的数据集,;
train_dataset = datasets.ImageFolder(train_dir, train_transform)
# 在train_dir路径下的图像进行train_transform
# ImageFolder是一个通用的数据加载器,它要求我们以下面这种格式来组织数据集的训练、验证或者测试图片。;
train_loader = DataLoader( # 数据读取
# DataLoader是一个比较重要的类,它为我们提供的常用操作有:batch_size(每个batch的大小),
# # shuffle(是否进行shuffle操作), num_workers(加载数据的时候使用几个子进程)
train_dataset,
batch_size=1,
num_workers=0,
pin_memory=pin_memory,
)
mn = torch.Tensor([0, 0, 0]) # 创建一个一维张量
st = torch.Tensor([0, 0, 0])
count = len(train_loader) # 多少个图片
for input, target in train_loader:
mn += input.mean([0, 2, 3])
mn = mn / count # 平均值
for input, target in train_loader: # 三个通道
ch0 = (input[0][0] - mn[0])
ch1 = (input[0][1] - mn[1])
ch2 = (input[0][2] - mn[2])
st[0] += torch.mul(ch0, ch0).sum() / 50176
st[1] += torch.mul(ch1, ch1).sum() / 50176
st[2] += torch.mul(ch2, ch2).sum() / 50176
# st = root(sum(x^2) / N)
st = torch.sqrt(st / count)
return (mn, st)
def split_loader(
train_dir, valid_frac=0.1, batch_size=32, shuffle=True,
):
"""
Function for splitting and loading train and valid iterators
函数用于分割和加载训练和验证迭代器
parameters -------------------------
- train_dir - path of training set 训练集路径
- valid_frac - fraction split of the training set used for validation训练集分割用于验证的
- batch_size - how many samples per batch to load
- shuffle - whether to shuffle the train or validation indices打乱数据
returns ----------------------------
- train_loader - training set iterator
- valid_loader - validation set iterator
"""
# valid frac range assert
error_msg = "Error : valid_frac should be in the range [0, 1]"
assert (valid_frac >= 0) and (valid_frac <= 1), error_msg
# override if cuda is available
pin_memory = True if torch.cuda.is_available() else False # 判断GPU是否可用
# load as dataset
train_transform, valid_transform = get_transforms()
train_dataset = datasets.ImageFolder(train_dir, train_transform)
valid_dataset = datasets.ImageFolder(train_dir, valid_transform)
# get indices
num_train = len(train_dataset)
indices = list(range(num_train)) # 0到99的向量
split = int(valid_frac * num_train) #
# shuffle if required
if shuffle:
numpy.random.shuffle(indices) # [1,2,3]打乱成[2,3,1]
# samplers
train_idx, valid_idx = indices[split:], indices[:split] # 分开训练验证
train_sampler = SubsetRandomSampler(train_idx)
valid_sampler = SubsetRandomSampler(valid_idx)
# 采样器都随机地从原始的数据集中抽样数据。抽样数据采用permutation。 生成任意一个下标重排,从而利用下标来提取dataset中的数据的方法
# dataloaders 数据加载
train_loader = DataLoader(
train_dataset,
batch_size=batch_size,
sampler=train_sampler,
num_workers=0, # 使用多进程加载的进程数,0代表不使用多进程
# dataloader一次性创建num_worker个worker,(也可以说dataloader一次性创建num_worker个工作进程,worker也是普通的工作进程),
# 并用batch_sampler将指定batch分配给指定worker,worker将它负责的batch加载进RAM。
pin_memory=pin_memory,
)
valid_loader = DataLoader(
valid_dataset,
batch_size=batch_size,
sampler=valid_sampler,
num_workers=0,
pin_memory=pin_memory,
)
return (train_loader, valid_loader)
def separate_loader(
train_dir, valid_dir, batch_size=32, shuffle=True,
):
"""
Function for splitting and loading train and valid iterators
parameters -------------------------
- train_dir - path of training set
- valid_dir - path of validation set
- batch_size - how many samples per batch to load
- shuffle - whether to shuffle the train or validation indices
returns ----------------------------
- train_loader - training set iterator
- valid_loader - validation set iterator
"""
# load as dataset
train_transform, valid_transform = get_transforms()
train_dataset = datasets.ImageFolder(train_dir, train_transform)
valid_dataset = datasets.ImageFolder(valid_dir, valid_transform)
# override if cuda is available
pin_memory = True if torch.cuda.is_available() else False
# dataloaders
train_loader = DataLoader(
train_dataset,
shuffle=shuffle,
batch_size=batch_size,
num_workers=0,
pin_memory=pin_memory,
)
valid_loader = DataLoader(
valid_dataset,
shuffle=False,
batch_size=batch_size,
num_workers=0,
pin_memory=pin_memory,
)
return (train_loader, valid_loader)
def test_loader(test_dir, batch_size=32, shuffle=False):
"""
Function for loading test image iterators迭代器
parameters -------------------------
- test_dir - path of image folder
- batch_size - how many samples per batch to load
returns ----------------------------
- test_loader - data iterator
"""
# override if cuda is available
pin_memory = True if torch.cuda.is_available() else False
# load as dataset
valid_transform = get_transforms()
test_dataset = datasets.ImageFolder(test_dir, valid_transform)
# dataloaders
test_loader = DataLoader(
test_dataset,
batch_size=batch_size,
num_workers=0,
pin_memory=pin_memory,
shuffle=shuffle,
)
return test_loader
def load_pth(path):
# just for code completeness
device = "cuda:0" if torch.cuda.is_available() else "cpu"
return torch.load(path, map_location=device)
import time
import shutil
import torch
# global variables全局变量
best_acc1 = 0
# Average Value Computer Class
class AverageMeter(object): # AverageMeter类来管理一些变量的更新
def __init__(self):
self.reset()
def reset(self): # 重置方法reset
self.val = 0 # 精度
self.avg = 0 # 平均值
self.sum = 0 # 总和
self.count = 0 # 图片总个数
def update(self, val, n=1): # 变量更新
self.val = val
self.sum += val * n
self.count += n
self.avg = self.sum / self.count
def _train(train_loader, model, criterion, optimizer, epoch):
"""
One epoch train function
parameters -------------------------
- train_loader - train data generator object
- model - torch model object
- criterion - loss function object
- optimizer - optimizer object
- epoch - epoch number to train
returns ----------------------------
- None
"""
# 对各个参数进行重置
losses = AverageMeter()
top1 = AverageMeter()
# top1--就是你预测的label取最后概率向量里面最大的那一个作为预测结果,
# 如果你的预测结果中概率最大的那个分类正确,则预测正确。否则预测错误
top5 = AverageMeter()
# top5-就是最后概率向量最大的前五名中,只要出现了正确概率即为预测正确。否则预测错误。
cuda_exists = torch.cuda.is_available()
len_train = len(train_loader) # 训练数据个数
# switch to train mode
model.train() # 训练模型
print("")
print("EPOCH : {}".format(epoch))
for i, (input, target) in enumerate(train_loader): # 数据迭代读取的循环函数#, 遍历整个训练数据,自动将所有数据按顺序编号
if cuda_exists:
input = input.cuda(non_blocking=True)
target = target.cuda(non_blocking=True)
# compute output
output = model(input) # 计算输出
loss = criterion(output, target) # 计算损失
# measure accuracy and record loss测量精度和记录损失
acc1, acc5 = _accuracy(output, target, topk=(1, 5))
losses.update(loss.item(), input.size(0))
top1.update(acc1[0], input.size(0))
top5.update(acc5[0], input.size(0))
# compute gradient and do SGD step
# 计算梯度和做随机梯度下降步长
optimizer.zero_grad() # 梯度归0
loss.backward() # 损失回传
optimizer.step() # 步长
# 20 bars to display progress
bar = (20 * (i + 1)) // len_train
print(
"\r"
"(" + str(i + 1) + "/" + str(len_train) + ")"
"[" + "=" * bar + "_" * (20 - bar) + "] "
"Loss: {loss.val:.4f} ({loss.avg:.4f}) "
"Acc@1: {top1.val:.3f} ({top1.avg:.3f}) "
"Acc@5: {top5.val:.3f} ({top5.avg:.3f})".format(
loss=losses, top1=top1, top5=top5,
),
end="",
)
print("")
def _validate(valid_loader, model, criterion):
"""
Validation function
parameters -------------------------
- valid_loader - validation data generator object
- model - torch model object
- criterion - loss function object
returns ----------------------------
- top1.avg - top 1 average accuracy
"""
losses = AverageMeter()
top1 = AverageMeter()
top5 = AverageMeter()
cuda_exists = torch.cuda.is_available()
len_valid = len(valid_loader)
# switch to evaluate mode
model.eval()
print("VALIDATION :")
with torch.no_grad(): # 是一个上下文管理器
for i, (input, target) in enumerate(valid_loader):
if cuda_exists:
input = input.cuda(non_blocking=True)
target = target.cuda(non_blocking=True)
# compute output
output = model(input)
loss = criterion(output, target)
# measure accuracy and record loss
acc1, acc5 = _accuracy(output, target, topk=(1, 5))
losses.update(loss.item(), input.size(0))
top1.update(acc1[0], input.size(0))
top5.update(acc5[0], input.size(0))
# 20 bars to display progress
bar = (20 * (i + 1)) // len_valid
print(
"\r"
"(" + str(i + 1) + "/" + str(len_valid) + ")"
"[" + "=" * bar + "_" * (20 - bar) + "] "
"Loss: {loss.val:.4f} ({loss.avg:.4f}) "
"Acc@1: {top1.val:.3f} ({top1.avg:.3f}) "
"Acc@5: {top5.val:.3f} ({top5.avg:.3f})".format(
loss=losses, top1=top1, top5=top5,
),
end="",
)
print("")
return top1.avg
def _accuracy(output, target, topk=(1,)):
"""
Compute the accuracy over the k top predictions
计算前面k个预测的准确性
parameters -------------------------
- output - model output tensor
- target - actual label tensor
- topk - top k accuracy values to return
returns ----------------------------
- res - list of k top accuracies
"""
num_classes = 1
for dim in output.shape[1:]:
num_classes *= dim
with torch.no_grad(): # torch.no_grad() 是一个上下文管理器,被该语句 wrap 起来的部分将不会track 梯度。
maxk = max(topk)
maxk = min(maxk, num_classes)
batch_size = target.size(0)
_, pred = output.topk(maxk, 1, True, True)
pred = pred.t()
correct = pred.eq(target.view(1, -1).expand_as(pred))
res = []
for k in topk:
if k < num_classes:
correct_k = correct[:k].view(-1).float().sum(0, keepdim=True)
res.append(correct_k.mul_(100.0 / batch_size))
else:
res.append([0, 0])
return res
def train(
model,
loaders,
lr=0.01,
momentum=0.9,
weight_decay=1e-4,
epochs=10,
checkpoint=None,
):
"""
The main worker function used to train network
parameters -------------------------
- model - torch nn module
- loaders - tuple of train and validation DataLoader
- lr - learning rate of model
- momentum - weighted average coefficient (alpha)
- weight_decay - decay of weights coefficient (eta)
- epochs - number of iterations to train
- checkpoint - checkpoint dict
returns ----------------------------
- None
"""
global best_acc1
# create model
print("=> training", model.name)
# unpack loaders
train_loader, valid_loader = loaders
# find device
if torch.cuda.is_available():
device = torch.device("cuda:0")
print("=> found cuda compatible gpu")
else:
device = torch.device("cpu")
print("=> no cuda devices found, using cpu for training")
# device switches and optimization
torch.backends.cudnn.benchmark = True
# loss and optimizer
criterion = torch.nn.CrossEntropyLoss().to(device=device)
optimizer = torch.optim.SGD(
model.parameters(), lr, momentum, weight_decay=weight_decay,
)
# resume from a checkpoint
if checkpoint:
start_epoch = checkpoint["epoch"]
best_acc1 = checkpoint["best_acc1"]
model.load_state_dict(checkpoint["state_dict"])
optimizer.load_state_dict(checkpoint["optimizer"])
print("=> loaded checkpoint", end=" ")
print("with epoch = %d" % start_epoch, end=" ")
print("and accuracy = %.2f" % best_acc1)
else:
start_epoch = 0
crtm = time.ctime().split()[1:-1]
print("=> checkpoints will be saved as checkpoint.pth")
print("=> training started at %s-%s %s" % (crtm[0], crtm[1], crtm[2]))
# training
for epoch in range(start_epoch, epochs):
# adjust learning rate
lr_adj = lr * (0.1 ** (epoch // 30))
for param_group in optimizer.param_groups:
param_group["lr"] = lr_adj
# train for one epoch
_train(
train_loader, model, criterion, optimizer, epoch,
)
# remember best accuracy
acc1 = _validate(valid_loader, model, criterion)
is_best = acc1 > best_acc1
best_acc1 = max(acc1, best_acc1)
# save checkpoint
save_dict = {
"epoch": epoch + 1,
"arch": model.name,
"best_acc1": best_acc1,
"state_dict": model.state_dict(),
"optimizer": optimizer.state_dict(),
}
torch.save(save_dict, "checkpoint.pth")
def confusion_matrix(model, valid_loader):
"""
Obtain confusion matrix from prediction
and actual labels
由预测得到混淆矩阵 和实际的标签
"""
len_valid = len(valid_loader)
cuda_exists = True if torch.cuda.is_available() else False
# confusion matrix of ncls * ncls
ncls = model.num_classes
conf_matrix = torch.zeros(ncls, ncls)
# switch to evaluate mode
model.eval()
print("VALIDATION :")
with torch.no_grad():
for i, (input, target) in enumerate(valid_loader):
# compute output
if cuda_exists:
input = input.cuda(non_blocking=True)
target = target.cuda(non_blocking=True)
output = model(input)
_, preds = torch.max(output, 1)
for t, p in zip(target.view(-1), preds.view(-1)):
conf_matrix[t.long(), p.long()] += 1
# 20 bars to display progress
bar = (20 * (i + 1)) // len_valid
print(
"\r"
"(" + str(i + 1) + "/" + str(len_valid) + ")"
"[" + "=" * bar + "_" * (20 - bar) + "]",
end="",
)
print("")
# horiz normalization to get percentage
norm_conf = []
for row in conf_matrix:
factor = float(row.sum())
normed = [float(i) / factor for i in row]
norm_conf.append(normed)
return norm_conf
4.预测数据
测试图像被缩放到256x256像素。 然后提取大小为224x224的三幅图像。 第一幅图像是从原始测试图像的中心得到的。 第二幅图像和第三幅图像分别从原始测试图像的左下角和右上角提取。 利用训练后的CCN网络,将提取的三幅图像输入模型,计算每幅图像的softmax概率输出向量。 获得对原始测试图像的类分数的最终概率向量,对三幅图像的输出分数向量进行平均。 这种方法减少了低分辨率和遮挡等低质量图像的影响。
5.实验结果
1-off精度,表示结果在左或右一个相邻的年龄标签的误差时的精度。根据我们的结果,在精确精度和1-off精度方面,所提议的工作显著优于最先进的结果。这些结果证实了所提出的工作的有效性。表2给出了建议模型的混淆矩阵。

6.模型比较
与修改的GoogleNet模型进行比较: 为了进一步证明所提工作的有效性,对GoogLeNet模型进行了图像训练 ,在ImageNet ILSVRC数据库上进行了重新训练、微调和测试。 我们修改和微调了GoogLeNet CNN来执行年龄预测,完全替换连接层和改变节点的数量。 在修改后的体系结构中,有四个完全连接的层 每层节点数分别为1024、2048、2048和8。 然后修改后的 GoogLeNet被重新训练和微调,同时在训练期间保持卷积层不变 。
改进后的GoogLeNet CNN在年龄估计方面达到了45.07%。 表六世通过使用VGG-Face CNN和GoogLeNet CNN,给出了所提模型的性能 估计。 为了进行年龄估计,使用了经过训练的GoogLeNet CNN进行图像分类任务 提供合理的结果。 但是,从表VI的结果可以明显看出,使用CNN提取的特征针对人脸识别任务训练的CNN模型比使用CNN模型提取的特征更有效图像分类训练。

7.结论分析
在本文中,提出了一个基于面部图像的年龄估计模型,该模型使用深度CNN称为VGG-Face,它是在一个大型数据库上训练的人脸识别。 对VGG-Face CNN进行了改进和微调,以进行年龄估计。 提出的模型在Adience数据库上比之前的算法提高了9%,Adience数据库是最新的具有挑战性的年龄估计基准,由无约束的人脸图像组成。 GoogLeNet是在一个包含数百万训练图像的大型数据库上进行训练的,它在年龄估计方面的性能与提出的使用VGG-Face的模型不具有竞争力。 不仅训练图像的数量和训练数据库中被训练对象的数量影响年龄估计的性能,而且所使用的CNN的训练前任务也决定了网络的年龄估计性能。
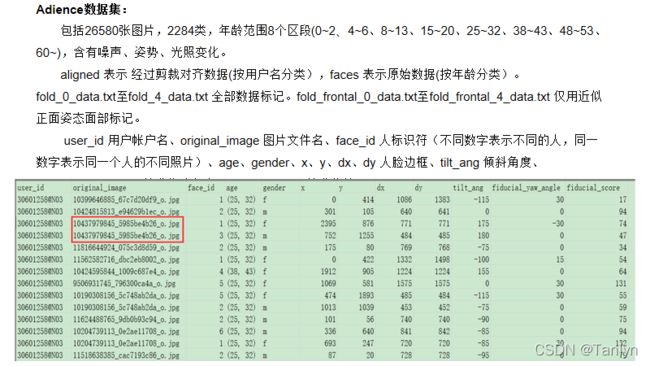
8.数据集分析
9.完整代码
完整代码 :总共4个py文件:loader.py、models.py、worker.py、vgg16.py(下面代码)
# 读取CSV文件
import pandas as pd
frames = []
folder_path = "F:/研究生/数据集/Adience_adience/adience/"
for i in range(5):
temp_df = pd.read_csv(folder_path + "fold_" + str(i) + "_data.txt", delimiter="\t")
"""
pandas提供了pd.read_csv()方法可以读取其中的数据并且转换成DataFrame数据帧(一个矩阵样式的数据表)。
python的强大之处就在于他可以把不同的数据库类型,比如txt/csv/.xls/.sql转换成统一的DataFrame格式然后进行统一的处理。真是做到了标准化
"""
frames.append(temp_df) # 加载5个文件,依次放入frames列表的末尾中
df = pd.concat(frames) # 把各个文件数据根据不同的轴简单融合
df.head() # 观察前5行的数据。括号内没有数字默认为5个,要加载任意个数需添加任意的数
# print(df.head())
# print(df)
# for cleaning anomalies清理异常
# 不同年龄放入不同的年龄区间段,字典
map_dict = {
"13": "(08, 12)",
"2": "(00, 02)",
"22": "(15, 20)",
"23": "(25, 32)",
"29": "(25, 32)",
"3": "(00, 02)",
"32": "(25, 32)",
"34": "(25, 32)",
"35": "(25, 32)",
"36": "(38, 43)",
"42": "(38, 43)",
"45": "(38, 43)",
"46": "(48, 53)",
"55": "(48, 53)",
"56": "(48, 53)",
"57": "(60, 100)",
"58": "(60, 100)",
"(8, 23)": "(08, 12)",
"(27, 32)": "(25, 32)",
"(38, 42)": "(38, 43)",
"(38, 48)": "(38, 43)",
"(00, 02)": "(00, 02)",
"(04, 06)": "(04, 06)",
"(08, 12)": "(08, 12)",
"(15, 20)": "(15, 20)",
"(25, 32)": "(25, 32)",
"(38, 43)": "(38, 43)",
"(48, 53)": "(48, 53)",
"(60, 100)": "(60, 100)"
}
def map_func(x): # 定义一个年龄分布函数
if x in map_dict:
return map_dict[x]
else:
return x
df["age"] = df["age"].map(map_func) # map()函数
# 重组目录
import os
import shutil
folder_path = "F:/研究生/数据集/Adience_adience/adience/faces/" # 原始数据
file_list = [] # 创建一个空文件列表
formats = ["jpg", "png"]
# 对数据集进行处理:指定文件路径-找文件夹包含的文件-把路径和文件名称连接起来-判断路径是否为目录-
# pytorch数据加载程序无法识别目录结构。
# 为了重组树,使它是可读的,每个文件都被移动到以其类命名的子文件夹下。
for subdir in os.listdir(folder_path): # os.listdir用于返回指定的文件夹包含的文件或文件夹的名字的列表
subpath = os.path.join(folder_path, subdir) # 连接两个或更多的路径名组件
if os.path.isdir(subpath): # 判断某一路径是否为目录
for f in os.listdir(subpath):
filepath = os.path.join(subpath, f)
part = f.split(".") # 拆分字符串。通过指定分隔符对字符串进行切片,并返回分割后的字符串列表(list)
# os.path.split():按照路径将文件名和路径分割开
if os.path.isfile(filepath) and part[-1] in formats: # 用于判断某一对象(需提供绝对路径)是否为文件
file_list.append((subpath, f))
im_len = len(file_list)
print(im_len)
for i, (filepath, filename) in enumerate(file_list): # 把所有文件路径和文件名按顺序编号
# get the identifiers
parts = filename.split(".") # 把文件名 filename按.分开
user_id = filepath.split("/")[-1] # 把文件路径按/分开,去最后一个路径
file_id = parts[-2] + "." + parts[-1] # 取文件名最后两个路径、
face_id = int(parts[-3]) # 文件倒数第三个路径转化为整形
# find class df是一个字典
if df[(df["user_id"] == user_id) &(df["original_image"] == file_id) &(df["face_id"] == face_id)].empty:
continue
else:
class_ = df[(df["user_id"] == user_id) & (df["original_image"] == file_id) & (df["face_id"] == face_id)]["age"].values[0]
new_path = os.path.join('F:/研究生/数据集/Adience_adience/adience/faces/', class_)
if not os.path.exists(new_path):
os.makedirs(new_path)
# move file
new_path = os.path.join(new_path, filename)
file_path=os.path.join(filepath, filename)
shutil.move(file_path, new_path)
# progress
prog = (20 * (i + 1)) // im_len
print("\r[" + "=" * prog + "_" * (20 - prog) + "]", end="")
for subdir in os.listdir(folder_path):
subpath = os.path.join(folder_path, subdir)
if os.path.isdir(subpath):
if subdir[0] != "(":
shutil.rmtree(subpath) # 表示递归删除文件夹下的所有子文件夹和子文件。
elif os.path.isfile(subpath):
os.remove(subdir) # 删除subdir文件路径
# 准备
import torch
import source.models as models
import source.worker as worker
import source.loader as loader
# the mean and std of dataset are found by running this
# 通过运行该程序,可以得到数据集的均值和标准差
# takes some time to iterate twice
# 需要一些时间迭代两次
loader.find_mean_std("F:/研究生/数据集/Adience_adience/adience/faces/")
loader.random_scale = (0.8, 1.0)
loader.mean = [0.437, 0.340, 0.304]
loader.std = [0.286, 0.252, 0.236]
# Dataset Loader to feed into network
# 数据集加载器将馈送到网络
# 20% of data is used for validation
loaders = loader.split_loader("F:/研究生/数据集/Adience_adience/adience/faces/", valid_frac=0.2, batch_size=32)
# pretrained weights - for convolution layers
state = loader.load_pth("F:/研究生/论文/vgg-age-master/vgg_face_dag.pth")
# 模型初试化
model = models.vgg16(num_classes=8) # 8类
model.load_weights(state) # 加载权重
model.memory_usage() # 模型的总参数
worker.train(model, loaders, lr=0.01, epochs=3) # 训练
check = loader.load_pth("checkpoint.pth")
model.load_weights(check["state_dict"])
valid_loader = loaders[1]
conf_mat = worker.confusion_matrix(model, valid_loader)
# 混淆矩阵
for row in conf_mat:
for elem in row:
print("%.2f"%(elem*100), end="\t")
print("")
ncls = len(conf_mat)
tot_acc = 0
for i in range(ncls):
acc = conf_mat[i][i]
# add left
if i > 0:
acc += conf_mat[i][i - 1]
if i < ncls - 1:
acc += conf_mat[i][i + 1]
tot_acc += acc
tot_acc = tot_acc / ncls
print("%.2f" % (tot_acc * 100))
# 相应的预测和目标标签随输入图像一起可视化。
import os
import torch
import source.models as models
import source.worker as worker
import source.loader as loader
import matplotlib.pyplot as plt
import torchvision.transforms as transforms
# from NewSource import model
# from NewSource import valid_loader
dire = "F:/研究生/数据集/Adience_adience/adience/faces/"
classes = os.listdir(dire)
classes.sort()
idx_to_class = {i:classes[i] for i in range(len(classes))}
print(idx_to_class)
model.eval()
batch_size = 32
model.to(torch.device("cpu"))
mean = loader.mean
std = loader.std
mn_inv = [-m/s for m, s in zip(mean, std)]
sd_inv = [1/s for s in std]
inv_transform = transforms.Normalize(mean=mn_inv, std=sd_inv)
with torch.no_grad():
for i, (input, target) in enumerate(valid_loader):
output = model(input)
_, preds = torch.max(output, 1)
fig=plt.figure(figsize=(15, 15))
columns = 4
rows = 5
for i in range(1, columns*rows + 1):
pred_class = idx_to_class[int(preds[i])]
real_class = idx_to_class[int(target[i])]
ax = fig.add_subplot(rows, columns, i)
ax.title.set_text("pred:" + pred_class + "," + "real:" + real_class)
ax.axis("off")
plt.imshow(inv_transform(input[i]).permute(1, 2, 0))
break
plt.show()