本文主要介绍了如何利用Selenium对网站进行登录,Xpath元素定位,及窗口操作的一些常用方法,附上详细代码及解析,同时简单总结元素定位不到的原因有哪些。双击下面图片查看动图
双击图片,查看效果
一 图片验证码登录
这部分主要完成浏览器打开,通过元素定位在浏览器中输入账号、密码信息,最后通过OCR识别技术完成验证码的输入,保证登录成功。
1.1启用浏览器并打开测试网站
代码:
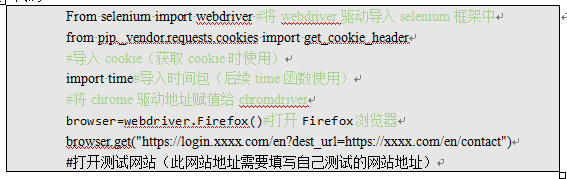
From selenium import webdriver #将webdriver驱动导入selenium框架中
from pip._vendor.requests.cookies import get_cookie_header
#导入cookie(获取cookie时使用)
import time#导入时间包(后续time函数使用)
#将chrome驱动地址赋值给chromdriver
browser=webdriver.Firefox()#打开Firefox浏览器
browser.get("https://login.xxxx.com/en?dest_url=https://xxxx.com/en/contact")
#打开测试网站(此网站地址需要填写自己测试的网站地址)
1.2设置等待时间
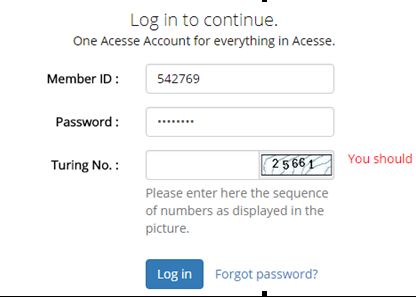
在上面登录过程中网页加载慢,出现了还没等图片完全加载出来就进行图片识别的现象,导致识别失败,如下图
那么我们应该如何操作去避免提前加载的现象呢?
如果给它加一个条件满足(图片验证码显示完全)时:再进行图片识别操作是否可行呢,我们来看看
Selenium有3种等待时间:
名称 方法 特点
强制等待 Thread.sleep() 执行到此时不管什么就固定的等待三秒之后再接着执行后面的操作
隐式等待方法 implicitlyWait() 隐式等待采用全部设置,此方法针对执行脚本的所有对象,等待10秒
显示等待方法 WebDriverWait() 明确的要等到某个元素的出现或者是某个元素的可点击等条件,等不到,就一直等,除非在规定的时间之内都没找到,那么就跳出Exception
这里使用WebDriverWait()方法:
WebDriverWait(driver,timeout,poll_frequency=0.5,ignored_exceptions=None)
driver :浏览器驱动名称
timeout :最长超时时间,默认以秒为单位。
poll_frequency :检测的间隔(步长)时间,默认为0.5S。
ignored_exceptions :超时后的异常信息,默认情况下抛NoSuchElementException异常
WebDriverWait()一般由until()或until_not()方法配合使用
HTML结构:

代码:
Element=WebDriverWait(browser,100).until(
EC.presence_of_element_located((By.ID,"captcha_img_id"))
)
代码意思是:ID名称为"captcha_img_id"的元素显示等待100s,如果没有出现,抛出异常,通过上面方法就可以处理等待页面元素加载完全后进行相关功能操作。
1.3账号、密码元素定位并输入内容
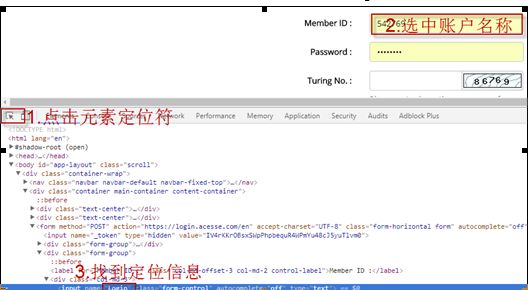
首先通过F12打开代码界面,点击元素定位图标,选中要定位的“账号”文本框内容,在代码区域找到定位的元素代码信息,如下图中的name名称“login”,密码元素同理
代码:
browser.find_element_by_name("Login").send_keys("xxxx")
#通过name定位登录文本框,通过send_keys输入账户信息
browser.find_element_by_name("Password").send_keys("xxxx")
#通过name定位密码文本框,通过send_keys输入密码信息
1.4验证码处理-使用OCR自动识别
看网上介绍验证码处理大致有4种方法,1.让开发把验证码代码注释掉 2.让开发设置万能验证码 3.通过添加cookie方式绕过图片验证码 4.OCR自动识别,其中1-2因为这个网站与开发接触不到,不予考虑方法3一般适用于记住登录状态的网站才适合,这里我使用第4种方法,这种方法适合于处理比较简单的验证码
OCR自动识别的原理是什么呢?
在这里我们需要使用pytesseract,它是一款用于光学字符识别(OCR)的python工具,即从图片中识别出其中嵌入的文字。整个过程分为截取登录页面->获取验证码的位置坐标->打开截图->从截图中截取验证码的区域->使用pytesseract工具识别验证码
代码:
browser.save_screenshot('f://a.png')#截取当前网页,该网页有我们需要的验证码
yzm=browser.find_element_by_id("captcha_img_id") #定位验证码
location=yzm.location#获取验证码x,y轴坐标
size=yzm.size#获取验证码的长宽
rangle=(int(location['x']),int(location['y']),int(location['x']+size['width']),int(location['y']+size['height']))#截取的位置坐标
i=Image.open("f://a.png") #打开截图
frame4=i.crop(rangle) #使用Image的crop函数,从截图中再次截取我们需要的区域
frame4.save('f://frame4.jpg')#将截取到的验证码保存为jpg图片
qq=Image.open('f://frame4.jpg')#打开jpg验证码图片
text=pytesseract.image_to_string(qq).strip() #使用image_to_string识别验证码
browser.find_element_by_name("turing").send_keys(text)#将识别的图片验证码信息输入到验证码输入文本框中
browser.find_element_by_class_name("btn").click()#点击登录按钮
运行代码后可能会遇到提示“系统找不到指定文件”

这个问题困扰了我好久,最后处理方案如下:
首先保证pytesseract环境安装正确-参见pytesseract环境安装文章:
https://www.cnblogs.com/hupeng1234/p/7136442.html
其次,打开文件 pytesseract.py,找到如下代码,将tesseract_cmd的值修改为全路径如:
tesseract_cmd = 'C:\\Program Files\\Tesseract-OCR\\tesseract'#这里一定要用\\不能用\,在程序里\\表示转译,如果只使用\是没用的。
运行代码,图1中的整个自动登录功能就实现了,怎么样有没有一种要飞的感觉…
二Firepath工具方法定位元素
2.1 实现的主要功能
点击用户名称,选择选中下拉菜单选项进入详细页面
借助Firebug和Firepath工具,方便我们使用Xpath对元素进行定位,这里我们使用Xpath定位,一般都通过Xpath结合属性值进行定位元素,95%以上的定位都能通过此方法解决
2.2具体操作
1. 首先下载Firebug和Firepath工具,下载步骤:工具-web开发者-获取更多工具-搜索框搜索Firebug-添加到Firefox即可【Firepath同理】
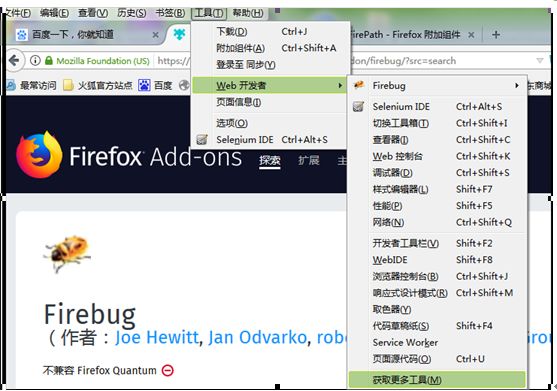
2. 工具使用,firefox中按[F12]
(1) 在Firebug 选项左键单击
(2) 右键选中要定位的元素选择【使用Firebug查找元素】
(3) 右键选中高亮代码,右键选择在FirePath面板中查看
(4) FirePath下文本框内容就是Xpath定位命令,拷贝命定到代码编辑器中(elipse)
HTML代码:
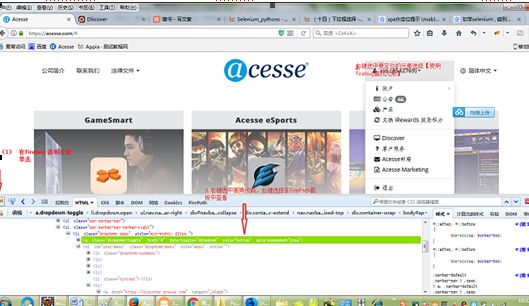
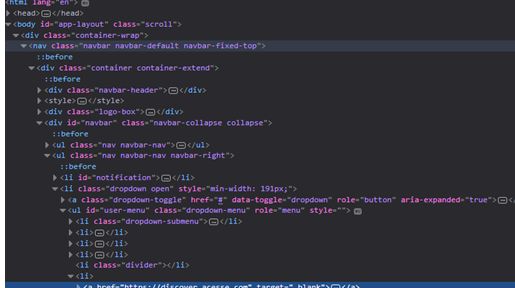
3. 定位Xpath元素,实现点击按钮
browser.find_element_by_xpath("//*[@id='navbar']/ul[2]/li[1]/a").click()
其中“//*[@id='navbar']/ul[2]/li[1]/a”这句话表示什么意思呢,跟着我一步一步看,(1)//表示在文档的全部层级进行查找
(2)[@id='navbar']表示定位id='navbar'元素下
(3)ul[2]表示定位到第二个无序列表的样式ul下
(4)li[1]表示定位到第一个列表内行的样式li下
(5)a表示定位到超链接下
从(1)到(5)是逐级展开的
4. 通过link text定位元素实现跳转
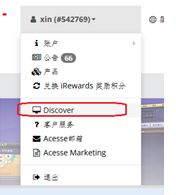
实现代码:browser.find_element_by_link_text("Discover").click()
(1) by_link_text:文本链接方式
(2) click():鼠标点击功能
Firepath工具可以帮助我们轻松定位元素,对于初学者是一个非常不错的工具,熟练之后再慢慢练习自己写。
三.元素定位不到原因分析--窗口句柄

在程序运行过程中,一直提示元素定位不到“unable to locate element”,这个问题我解决了大概有一个星期,下面是我的解决思路。
页面元素结构:
定位代码:
browser.find_element_by_xpath("//form/div/div/descendant::a[@href='/adview']").click()
1. 无论怎么定位都提示“unable to locate element”,如下图
于是就开启了找问题出在哪里
3.1.网上查定位元素不到的原因有哪些
首先,我在网上查元素定位不到的原因,因为根据提示,我们知道是元素没有定位成功
网上的思路大概都是:
1. 定位的ID是动态,这里不涉及ID,所以排除
2. iframe原因定位不到元素
3. 不在同一个frame里边查找元素,这里不涉及iframe元素,所以2/3排除
4. Xpath描述错误
刚开始我以为是我元素定位的错误,所以花了很多时间在换各种方式进行定位:包括使用Selenium IDE 工具、使用Link()方法、利用Firepath 中的Xpath Css定位,仍提示定位不成功
5. 点击速度过快 页面没有加载出来就需要点击页面上的元素
我在语句前面加上加载时间time.sleep(5)等待,还是不行
6. firefox安全性强,不允许跨域调用出现报错
错误描述:uncaught exception: [Exception... "Component returned failure code: 0x80004005 (NS_ERROR_FAILURE) [nsIDOMNSHTMLDocument.execCommand]" nsresult: "0x80004005 (NS_ERROR_FAILURE)" location:
根据错误描述,这点也不符合,排除
3.2. 如何排除不是语句错误
根据之前操作,感觉不应该定位语句错误的原因,所以如何排除判断是不是语句错误呢
1. 因为这个页面属于登录成功后调用的第二个页面,所以我从上一页面开始,把之前的代码前加上注释#后运行
2.结果调用成功了,直接跳转到第三个页面了,可以说明语句没有编写错误
3.这里还有一个方法,就是你换其他浏览器试一试,但是我觉得还得重新配置太麻烦了
3.3 罪魁祸首-窗口句柄
既然语句编写的没有问题,那么我又开始怀疑人生了,到低哪里出错了
1. 继续网上找资料,发现是从a页面到b页面,窗口句柄还停留在上一个页面,所以无法定位元素
窗口句柄是什么
想要在某个窗口做一些事情,你就得让操作系统知道你是在哪一个窗口做这些事情,而窗口的句柄就能起到识别哪一个窗口的作用
所以刚刚进入到一个页面后,将窗口进行重新定位应该就可以了
time.sleep(5
browser.switch_to_window(browser.window_handles[1])
browser.find_element_by_xpath("//form/div/div/descendant::a[@href='/adview']").click()
总结:以后再遇到跳转新页面的时候不要忘记加窗口句柄!!!
本篇文章就到这里,附上所有运行代码:
# coding=gbk
'''
Created on 2018年3月8日
@author: Administrator
'''
#!/usr/bin/python
# -*-encoding:utf-8 -*-
#1.启用浏览器并打开测试网站
from PIL import Image
import pytesseract
from selenium import webdriver #将webdriver驱动导入selenium框架中
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from pip._vendor.requests.cookies import get_cookie_header#导入cookie
import time#导入时间包
from pydoc import browse
from pip import locations
from test.test_largefile import size
from _elementtree import Element
from select import select
from cgitb import text
from test.test_os import LoginTests
#chromedriver="C:\Program Files\Internet Explorer\IEDriverServer.exe"#将chrome驱动地址赋值给chromdriver
#browser=webdriver.Chrome()
browser=webdriver.Firefox()
browser.get("https://login.acesse.com/en?dest_url=https://acesse.com/en/contact")#打开测试网站
Element=WebDriverWait(browser,100).until(
EC.presence_of_element_located((By.ID,"captcha_img_id"))
)
#2.对账号、密码元素进行定位
browser.find_element_by_name("Login").send_keys("xxxxx")
browser.find_element_by_name("Password").send_keys("xxxxxxx")
#3.验证码处理-使用OCR自动识别
#browser.maximize_window()
def login():
browser.save_screenshot('f://a.png')#截取当前网页,该网页有我们需要的验证码
yzm=browser.find_element_by_id("captcha_img_id") #定位验证码
location=yzm.location#获取验证码x,y轴坐标
size=yzm.size#获取验证码的长宽
rangle=(int(location['x']),int(location['y']),int(location['x']+size['width']),int(location['y']+size['height']))#截取的位置坐标
i=Image.open("f://a.png") #打开截图
frame4=i.crop(rangle) #使用Image的crop函数,从截图中再次截取我们需要的区域
frame4= frame4.convert('RGB')
frame4.save('f://frame4.jpeg')#讲截取到的验证码保存为jpg图片
qq=Image.open('f://frame4.jpeg')#打开jpg验证码图片
text=pytesseract.image_to_string(qq).strip() #使用image_to_string识别验证码
browser.find_element_by_name('turing').send_keys(text)#将识别的图片验证码信息输入到验证码输入文本框中
browser.find_element_by_class_name("btn").click()#点击登录按钮
login()
browser.find_element_by_xpath("/html/body/div[1]/nav/div/div[3]/ul[2]/li[2]/a").click()
browser.find_element_by_xpath('/html/body/div[1]/nav/div/div[3]/ul[2]/li[2]/ul/li[6]/a/span').click()
#browser.implicitly_wait(30)
time.sleep(5)
browser.switch_to_window(browser.window_handles[1])
browser.find_element_by_xpath("//form/div/div/descendant::a[@href='/adview']").click()