【论文笔记——自监督学习综述】Self-supervised Visual Feature Learning with Deep Neural Networks: A Survey
【论文笔记——自监督学习综述】Self-supervised Visual Feature Learning with Deep Neural Networks: A Survey
Abstract
Large-scale labeled data are generally required to train deep neural networks in order to obtain better performance in visual feature learning from images or videos for computer vision applications. T o avoid extensive cost of collecting and annotating large-scale datasets, as a subset of unsupervised learning methods, self-supervised learning methods are proposed to learn general image and video features from large-scale unlabeled data without using any human-annotated labels. This paper provides an extensive review of deep learning-based self-supervised general visual feature learning methods from images or videos. First, the motivation, general pipeline, and terminologies of this field are described. Then the common deep neural network architectures that used for self-supervised learning are summarized. Next, the schema and evaluation metrics of self-supervised learning methods are reviewed followed by the commonly used image and video datasets and the existing self-supervised visual feature learning methods. Finally, quantitative performance comparisons of the reviewed methods on benchmark datasets are summarized and discussed for both image and video feature learning. At last, this paper is concluded and lists a set of promising future directions for self-supervised visual feature learning
论文链接:https://arxiv.org/abs/1902.06162
1 介绍
1.1 动机
(1)Deep ConvNets 的性能很大程度上取决于它的 capability 和数据集的数量,但是大规模数据集的收集和注释非常昂贵。
(2)因此近年来提出了许多 self-supervised learning 的方法,即从大规模无标记的数据中自主的学习特征。采取的方法通常是设置一些 pretext tasks(如图像上色、图像修补、图像拼接等),训练网络去解决 pretext tasks,在完成这些任务的过程中,网络就学习到了相应的特征,从而生成对应的伪标签(pseudo label)。
(3)pretext task需要满足以下两个条件:
-
ConvNets 需要捕获图片/视频中的 visual features 来解决 pretext tasks
-
可以根据图像/视频的某些属性自动生成用于 pretext task 的伪标签
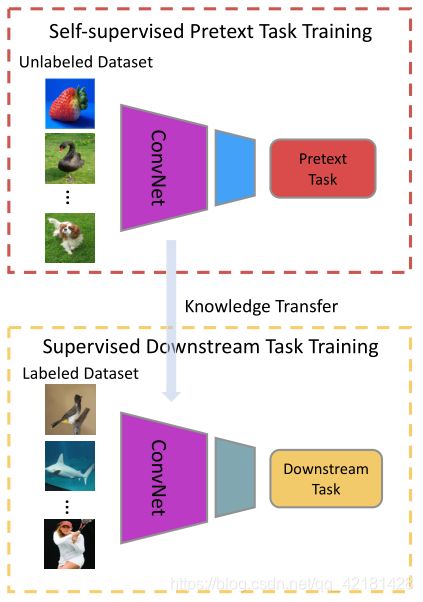
self-supervised learning 的一般流程: -
首先,设计一个预定义的前置任务(pretext task),训练网络来解决改任务,根据数据的某些属性自动生成前置任务下的伪标签。
-
然后,训练 ConvNet 学习 pretext task 的目标函数(object functions),当 pretext task 训练完成后,学习到的视觉特征可以被进一步迁移到下游任务中,从而提高性能并减少过拟合。
-
通常来说,浅层捕获一些低级特征,如边缘、拐角和纹理,而较深层捕获与任务相关的高级特征。因此,在受监督的下游任务训练阶段,只是转移了前几层的视觉特征。
1.2 术语定义
(1)术语解释:
- Human-annotated label: 由人工进行注释的数据标签。
- Pseudo Label: 基于用于 pretext task 的数据属性自动生成的标签。
- Pretext Task: 预先设计的让网络进行解决的任务,通过学习 pretext task 的目标函数(object functions)可以让网络自动学习的数据的视觉特征。
- Downstream Task: 用来评估自监督学习到特征的质量的计算机视觉应用程序。通常需要人工注释的标签来解决下游任务,但在某些情况下,下游任务可以与前置任务相同,这样就无需任何人工注释标签。
- Supervised Learning: 监督学习,用带有细粒度的人工注释标签来训练网络的学习方法。
- Semi-supervised Learning: 半监督学习,用少量标记数据和大量的未标记数据来训练网络的学习方法。
- Weakly-supervised Learning: 弱监督学习,用粗粒度或不准确的标签进行训练的学习方法,粗粒度标签的获取成本比细粒度低很多。
- Unsupervised Learning: 无监督学习,不适用任何人工注释标签的学习方法。
- Self-supervised Learning: 自监督学习,使用自动生成的标签对 ConvNets 进行训练的学习方法。(本文仅关注视觉特征相关的方法)
(2)文章主要贡献:
- 首次有关 Deep ConvNets 的自监督视觉特征学习的综述。
- 对最近自监督学习的方法和数据集进行回顾。
- 对现有的方法的性能进行定量的分析和比较。
- 指出了自监督学习未来可能的方向。
2 不同的学习模式
下面将对有监督、无监督(自监督学习看作无监督学习的子类)、弱监督和半监督四种视觉特征学习方法进行比较。
2.1 监督学习
监督学习损失函数定义如下:
loss ( D ) = min θ 1 N ∑ i = 1 N loss ( X i , Y i ) \operatorname{loss}(D)=\min _{\theta} \frac{1}{N} \sum_{i=1}^{N} \operatorname{loss}\left(X_{i}, Y_{i}\right) loss(D)=θminN1i=1∑Nloss(Xi,Yi)
N N N为数据集数量, X i X_i Xi为数据集中的一个数据, Y i Y_i Yi为其对应的人工标注的标签:
-
优点:标签精确,效果好,取得了突破性成果。
-
缺点:数据收集和注释昂贵,需要耗费大量人力物力。
2.2 半监督学习
半监督学习的损失函数如下:
loss ( D 1 , D 2 ) = min θ 1 N ∑ i = 1 N loss ( X i , Y i ) + 1 M ∑ i = 1 M loss ( Z i , R ( Z i , X ) ) \operatorname{loss}\left(D_{1}, D_{2}\right)=\min _{\theta} \frac{1}{N} \sum_{i=1}^{N} \operatorname{loss}\left(X_{i}, Y_{i}\right)+\frac{1}{M} \sum_{i=1}^{M} \operatorname{loss} \left(Z_{i}, R\left(Z_{i}, X\right)\right) loss(D1,D2)=θminN1i=1∑Nloss(Xi,Yi)+M1i=1∑Mloss(Zi,R(Zi,X))
X X X表示少量的有标签数据集(数据集大小为 N N N,表示为 D 1 D_1 D1),其中每个 X i X_i Xi对应的人工注释的标签为 Y i Y_i Yi; Z Z Z表示大量的无标签数据集(数据集大小为 M M M,表示为 D 2 D_2 D2)。
R ( Z i , X ) R(Z_i,X) R(Zi,X)是一个针对某个特定的任务的函数,用来表示无标签数据 Z i Z_i Zi与有标签数据 X X X之间的关系。
2.3 弱监督学习
弱监督学习的损失函数如下:
loss ( D ) = min θ 1 N ∑ i = 1 N loss ( X i , C i ) \operatorname{loss}(D)=\min _{\theta} \frac{1}{N} \sum_{i=1}^{N} \operatorname{loss}\left(X_{i}, C_{i}\right) loss(D)=θminN1i=1∑Nloss(Xi,Ci)
C i C_i Ci为数据 X i X_i Xi粗粒度的标签。
粗粒度标签获取的成本要大大低于细粒度,因此相对容易获得大规模数据集。近年来,在某些方面也取得了不错的性能。 [ 21 ] [ 22 ] ^{[21][22]} [21][22]
2.4 无监督学习
无监督学习即指学习过程不需要任何人工注释的标签,其中包括完全无监督学习(不需要任何标签)以及自监督学习(利用自动生成的伪标签进行训练)。
2.4.1 自监督学习
近年来,已经出现了许多用于视觉特征学习的自监督学习方法 [ 23 ] − [ 35 ] ^{[23]-[35]} [23]−[35]。
与监督学习相似的地方是:自监督学习也需要 X i X_i Xi~ P i P_i Pi的的数据对进行训练,不过这里的 P i P_i Pi并不是监督学习里通过人工注释的到的标签,而是完成 pretext task 而自动生成的伪标签。
给定一组数据集 D = { P i } i = 0 N D=\{P_i\}^N_{i=0} D={Pi}i=0N,其训练损失函数定义为:
loss ( D ) = min θ 1 N ∑ i = 1 N loss ( X i , P i ) \operatorname{loss}(D)=\min _{\theta} \frac{1}{N} \sum_{i=1}^{N} \operatorname{loss}\left(X_{i}, P_{i}\right) loss(D)=θminN1i=1∑Nloss(Xi,Pi)
只要伪标签 P i P_i Pi不是由人工标注的,那么就属于自监督学习。
3 常见的深度网络架构
该节主要介绍了用于学习图像和视频特征的常见架构,对于不同的学习方法来说,架构大致是相同的
3.1 学习图像特征的架构
主要介绍 AlexNet [ 8 ] ^{[8]} [8]、VGG [ 9 ] ^{[9]} [9]、GooLeNet [ 10 ] ^{[10]} [10]、ResNet [ 11 ] ^{[11]} [11] 和 DenseNet [ 12 ] ^{[12]} [12] 五种图像特征学习架构。
3.1.1 AlexNet
https://my.oschina.net/u/876354/blog/1620906

6240万个参数的AlexNet在ImageNet上训练了130万张图片。AlexNet具有8层,其中5层为卷积层,3层为全连接层,ReLU应用在每个卷积层之后。94%的参数来自全连接层,很容易过拟合,因此可通过数据扩充、数据丢失和正则化来避免。
3.1.2 VGG
详细参考:https://my.oschina.net/u/876354/blog/1634322

VGG具有16个卷积层,分别属于5个卷积块。其与AlexNet不同的是,AlexNet具有大的卷积步幅和内核大小,但是VGG中的所有卷积核都有相同的小尺寸(3×3)和小的卷积步幅(1×1)。
较大的内核大小会导致过多的参数和较大的模型大小,而较大的卷积步幅会导致网络在较低层丢失一些精细的功能。
3.1.3 ResNet
详细参考:https://zhuanlan.zhihu.com/p/31852747
VGG证明了更深的网络具有更好的性能,但是难以训练(梯度消失、梯度爆炸)。
残差网络ResNet通过使用条约连接(skip connection),将前一个特征图发送到下一个卷积来在卷积快中使用来客服梯度消失和梯度爆炸。
skip connections中文为跳跃连接,通常用于残差网络中,作用是在比较深的网络中,解决在训练的过程中梯度爆炸和梯度消失问题。
参考:https://cloud.tencent.com/developer/news/134921

3.1.4 GoogLeNet
详细参考:https://my.oschina.net/u/876354/blog/1637819
GoogLeNet 是一个22层的深度网络,基本块是七十块,它由4个具有不同内核大小的并行卷积层组成,然后是1×1卷积来降维。
GoogLeNet在计算成本不变的情况下增加了网络的深度和宽度,结构如下:

3.1.5 DenseNet
详细参考:https://zhuanlan.zhihu.com/p/37189203
为了减轻深层网络中深层难以记住网络的低级功能的问题,提出了密集连接,将卷积块之前的所有特征作为神经网络中下一个卷积块的输入发送,这样所有先前的卷积块的输出特征都用作当前块的输入。这样,较浅的块可以专注于低级功能,而较深的块专注于高级任务特定功能。

3.2 学习视频特征的架构
- 基于2DConvNet的方法在每个单帧上应用2DConvNet,并将多个帧的图像特征融合为视频特征。
- 基于3DConvNet的方法采用3D卷积运算从多个帧中同时提取空间和时间特征。
- 基于LSTM的方法采用LSTM对视频中的长期动态进行建模。
3.2.1 Two-Stream Network(双流网络)

用一个2DConvNet捕获RGB流中的空间特征,用另一个2DConvNet捕获光流中的时间特征。实验表面,两种流的融合可以显著提高动作识别的准确性,后来这项工作已经扩展到多流网络,以融合不同类型输入的特征。
3.2.2 Spatiotemporal Convolutional Neural Network(时空卷积神经网络)
3DConvNets能够同时从多个帧中提取空间和时间特征。
C3D是一个类似VGG的11层的3DConvNet,其中8个卷积层,3个全连接层,所有核的大小为3×3×3,卷积步幅固定为1个像素。
LTC(long-term temporal convolutions)任务C3D从16个连续RGB帧中提取外观和时间,不足以表示持续时间更长的整个动作。因此采用了大量的帧训练3DConvNets并取得了由于C3D的性能。
由于3D卷积对视频分析任务的成果,已经提出了各种3DConvNet的体系结构。提出了一种通过3D卷积层替换ResNet中的所有2D卷积层,提出了3DResNet。
3.2.3 Recurrent Neural Network(递归神经网络,RNN)
由于能够对序列中的时间动态建模,RNN经常作为有序帧序列应用于视频。
LSTM使用存储单元来存储、修改和访问内部状态,可以更好的对长期时间关系建模。 [ 73 ] ^{[73]} [73]
基于LSTM提出的用于人类动作识别的长期递归卷积网络(LRCN,long-term recurrent convolutional networks)框架如下: [ 54 ] ^{[54]} [54]
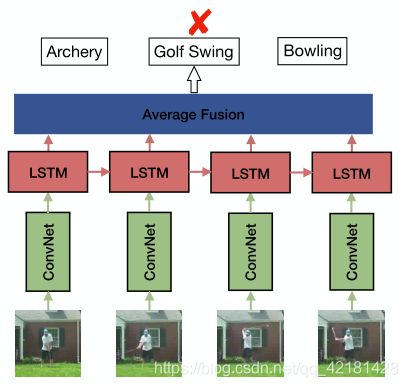
将LSTM顺序的应用于ConvNets提取的特征,以模拟帧序列中的时间动态。使用LSTM将视频建模为帧序列,能显式地对视频中的长期时间动态建模。
3.3 ConvNet 架构的总结
深度卷积网络已经在各种计算机视觉任务中表现得很好,但是一个常见是这些网络在数据稀缺的情况下通常由数百万个参数,从而导致数百万个参数。
在大数据集上进行预训练并在小数据集上进行微调,无论是性能和效率上都要优于在小规模数据集从头开始训练,但是大规模数据集的收集和注释仍然是一个代价很大的过程。因此提出了许多子监督学习办法,之后的部分介绍了针对图像和视频特征的自监督学习的一般流程。
4 常见的前置任务和下游任务
大多数自监督学习的方法都遵循下图的模式:

为ConvNets定义一个预任务,通过解决该预任务来学习到视觉特征,并自动生成伪标签 P P P,而无需人工注释。通过最小化ConvNet的预测 O O O和伪标签 P P P的误差来优化ConvNet,这样在完成前置任务后就得到了能捕获图像或视频视觉特征的ConvNet模型。
4.1 从前置任务中学习视觉特征
目前已经有许多前置任务应用于自监督学习,如前景对象分割(foreground object segmentation) [ 81 ] ^{[81]} [81]、图像修复(image inpainting) [ 19 ] ^{[19]} [19]、聚类(clustering) [ 44 ] ^{[44]} [44]、图像着色(image colorization) [ 82 ] ^{[82]} [82]、时间序列验证(temporal order verification) [ 44 ] ^{[44]} [44]、视频音频对应验证(visual audio correspondence verification) [ 25 ] ^{[25]} [25]。
以图像着色为例子,该任务即需要将灰度图着色为彩色图。在着色的过程中,只有网络学习到了图像的结构和上下文信息,才能生成逼真的彩色图像。
4.2 常用的前置任务
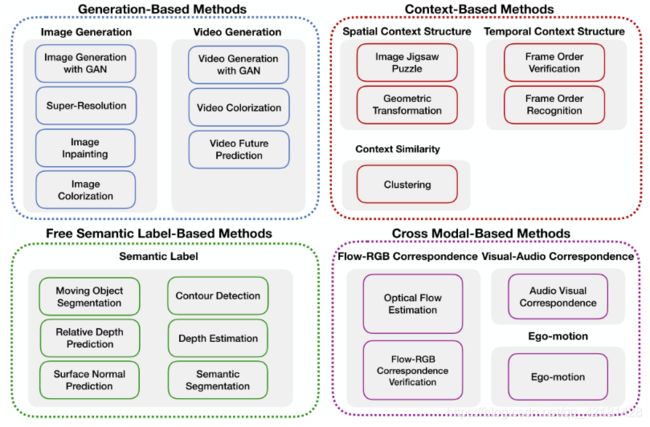
通常,自监督学习的前置任务可以分为四类:
(1)Generation-based Methods(基于生成的)
- Image Generation(图像生成): 图像着色、图像超分辨率(指由一幅低分辨率图像或图像序列恢复出高分辨率图像)、图像修复、用GANs生成图像
- Video Generation(视频生成): 利用GANs进行视频的生成及预测
(2)Context-based pretext tasks(基于上下文的)
- Context Similarity(上下文相似度): 根据图像补丁之间的上下文相似性设计前置任务,包括基于图像聚类的方法(image clustering-based methods)和基于图像约束的方法( graph constraint-based methods)。
- Spatial Context Structure(空间上下文结构): 基于图像补丁之间的空间关系,包括图像拼图(image jigsaw puzzle)、上下文预测(context prediction)、几何变换识别(geometric transformation recognition)。
- Temporal Context Structure(时间上下文结构): 来自视频的时间顺序用作监视信号。对ConvNet进行训练,以验证输入帧序列是否以正确的顺寻或识别帧序列的顺序。
(3)Free semantic label-based(基于自动生成语义标签的方法)
使用自动生成的语义标签来训练网络,标签是由传统的硬编码算法或游戏引擎生成的。包括运动对象分割(moving object segmentation)、轮廓检测(contour detection)、相对深度预测(relative depth prediction)。
(4)Cross modal-based(基于跨模态的方法)
这种前置任务训练ConvNet验证两个不同的输入数据通道是否彼此对应。包括视觉-音频对应验证(Visual-Audio Correspondence Verification)、RGB流对应验证(RGB-Flow Correspondence Verification)、自我感应(egomotion)。
上面四类如下图所示:
4.3 常用的下游评估任务
为了评估通过自监督方法学习方法学习到的的图像或视频特征的质量,将学习到参数用作预训练模型,然后对下游高级任务进行微调,这种迁移学习的能力可以证明所学特征的泛化能力。
常见的下游高级视觉任务有:
- Semantic Segmentation(语义分割):为图像中每个像素分配语义标签的任务。
- Object Detection(目标检测):在图像中定位目标位置别识别其类别的任务。
- Image Classification(图像分类):识别每个图像中对象类别的任务,通常每个图像只能使用一个类别标签。将自监督学习模型应用于每个图象上来提取特征,然后用这些特征训练一个分类器(如SVM),将分类器在测试集上的表现与自监督模型进行比较,来评估所学特征的质量。
- Human Action Recognition(人体行为识别):识别视频中的人们在做什么,以获取预定义动作类别的列表。通常用于从视频中学习到的特征的质量。
除了以上对所学特征进行定量的评估之外,还有一些定性可视化的方法对自监督学习的特征进行评估(Qualitative Evaluation):
-
Kernel Visualization: 定性的可视化通过前置任务学习的第一个卷积层的内核,并比较监督模型的内核。通过比较监督学习模型和自监督学习模型内核的相似性,来评估其有效性。
-
Feature Map Visualization: 可视化特征图来显示网络的关注区域,较大的激活表示神经网络更关注图像中的相应区域,通常对特征图进行定性可视化,并与监督模型进行比较。
-
Nearest Neighbor Retrieval: 通常具有相似外观的图像在特征空间中更靠近。最近邻方法用于从自监督学习模型学习的特征的特征空间中找到前K个最近的邻居。
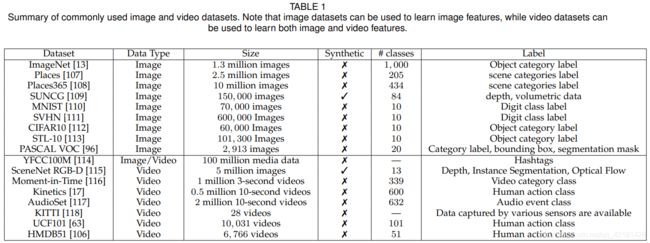
5 数据集
自监督学习不需要人工标注的数据,因此任何监督学习的数据集都可以用来自监督方式的视觉特征学习。
6 图像特征的学习
6.1 基于生成(Generation-based)
(1)Image Generation with GAN
GAN通常用来生成逼真的图像,有一个生成器(generator)和一个判别器(discriminator)判别器为了能够区分真实图像与生成数据图像分布的区别,就需要捕获图像中的语义特征来完成任务,因此就可以将判别器的参数应用于下游视觉任务。但是此类生成图像任务主要目的是生成逼真的图像,而不是在下游任务获得更好的性能。
对抗训练(adversarial training)可以帮助网络捕获真实数据的真实分布并生成真实数据,当没有人工注释的标签涉及时,也属于自监督学习。
(2)Image Inpainting

图像修补(Image Inpainting)是根据图像的其余部分预测任意缺失区域的任务,只有模型真正读懂了这张图所代表的含义,学习到了图像的特征(颜色、结构等),才能有效的修补缺失的区域。 [ 19 ] ^{[19]} [19]
一般是由生成器和判别器两个网络进行对抗从而预测缺失部分,为了完成图像修复任务,两个网络都需要学习图像的语义特征:
- 生成网络分为编码器和解码器两部分:编码器的输入是需要修复的图像,上下文编码器学习图像的语义特征。上下文解码器将基于此特征预测丢失的区域。因此就要求生成器了解图像的内容,以便生成合理的假设。
- 判别网络经过训练可以区分输入图像是否是生成器的输出。
(3)Image Super Resolution
图像超分辨率(Image super-resolution)是增强图像分辨率的任务,从低分辨率图像中生成高分辨率图像。Ledig等人提出了用于单一图像超分辨率的生成对抗网络SRGAN [ 15 ] ^{[15]} [15]。
- 生成网络:增强输入的低分辨率图像的分辨率。
- 判别网络:判别生成的图像与原始的高分辨率的图像的相似性。
和其他GAN相似,判别网络学到的参数可以迁移到其他下游任务上,但是目前还没有人测试这个迁移学习的性能如何。
(4)Image Colorization

图像着色(Image Colorization)将灰度图片作为输入,网络需要正确的为图片进行着色,为了使每个像素正确着色,网络就需要识别对象并将统一部分的像素分组在一起,从而在该过程中学习了图像的视觉特征。
最近几年,研究人员提出了许多基于图像着色的方法 [ 18 ] [ 137 ] [ 138 ] ^{[18][137][138]} [18][137][138],并且有一些工作专门使用图像着色作为自监督图像表征学习的前置任务。
6.2 基于上下文(Context-Based)
(1)Context Similarity
基于上下文相似性进行学习(Learning with Context Similarity),这里指的是在自监督学习中使用聚类算法。基于传统的提取特征的方法(e.g. Hog, SIFT)将图像聚类,然后基于聚类后的伪标签进行训练,让ConvNET对数据进行分类(或识别两个图像是否来自同一个类)。为了能够完成该分类任务,ConvNet就需要学习每个类别之间的相似性和不同类别之间的差异性。
下图为DeepCluster的架构,用K-Means对图像迭代的进行聚类,然后用后续的聚类伪标签监督的更新ConvNet的权重。
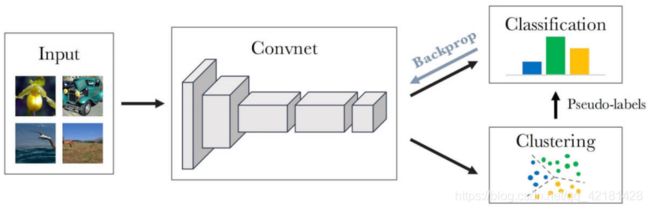
Contrasting(基于对比的):中心思想是训练一个网络使其可以最大化来自同一图片的相似性,最小化来自不同图片的相似性。值得一提的是SimCLR,这个方法在ImageNet上比其他自监督的方法精度高。
(2)Spatial Context Structure
利用图像包含的丰富的空间上下文信息来设计前置任务,例如图像中不同块之间的相对位置。
-
Image Jigsaw Puzzle [ 20 ] ^{[20]} [20]: 将图像切块,随机打乱,训练网络重新复原该图像。该方法的关键在于,找到一个合适的任务,让任务不会太过简单(达不到训练预期效果),也不会太难(训练无法收敛)。

-
Geometric Transformation [ 28 ] ^{[28]} [28]: 将原图旋转一定角度,让网络预测出图像的旋转角度。
6.3 基于自动生成语义标签(Free Semantic Label-based)
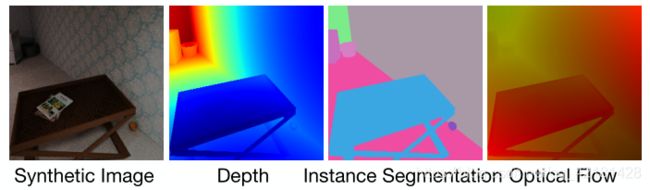
通过Game Engine或Hard-code自动生成语义标签(如segmentation masks、depth images、optic flows、surface normal images),因为这些语义标签不需要任何人工注释,因此可以使用合成数据集与无标记大型数据集结合使用进行自监督学习。
(1)Labels Generated by Game Engines
Game Engine可以渲染逼真的图像比提供精确的像素级标签,并且可以低成本合成大规模数据集。
虽然可以利用自动生产的语义标签进行学习,但是毕竟合成的图像与真实图像学习到的视觉特征还是有区别的。因此,Ren和Lee提出了一种基于对抗学习的无监督特征空间域自适应方法 [ 30 ] ^{[30]} [30](这里可以理解为自监督):

该方法使用了一个鉴别器 D D D进行对抗训练,来不断最小化真实图像和合成图像直接特征空间域的差异,这样就可以在合成图像的语义标签训练下,更好的捕获真实图像的视觉特征。
优点: 与其他的让网络隐式的学习视觉特征不同,此种方法直接利用了合成图像自动生成的精确语义标签进行训练,使得网络学习与图像中对象高度相关的特征。
(2)Labels Generated by Hard-code programs
通过在图像或视频上使用硬编码程序(Hard-code program)来获取语义标签,使用生成的标签训练ConvNet。
优点是可以用语义标签作为监督信号,驱使ConvNet直接学习语义特征;确定是硬编码检测器生成的语义标签容易引入噪音,需要专门处理。
6.4 总结
用于图像的自监督学习前置任务总结:

7 视频特征的学习
7.1 基于生成(Generation-based)
(1)Video Generation with GAN
与图像类生成方法类似,通常由两部分组成:Generator(生成器:生成视频)和Discriminator(判别器:区分生成的与真实的视频),Discriminator为解决判别任务需要学习视频中到相应的语义特征,然后其中的参数可以被迁移到其他下游任务。
- VideoGAN [ 85 ] ^{[85]} [85]:利用双流网络的思想,一条流将视频中的静态区域建模为背景,另一条流将视频中的移动对象建模为前景,视频由前景流和背景流组合生成。
- MocoGAN [ 86 ] ^{[86]} [86]:用两个子空间的组合来表示视频,一个空间为上下文空间(该空间的每一个变量代表一个身份),另一个空间为运动空间(该空间中的轨迹代表身份的运动)
(2)Video Colorization
视频上色(Video Colorization)是将灰度帧着色为彩色帧的任务。给定参考的RGB帧和灰度图像,网络需要学习它们之间的内部连接才能成果上色 [ 145 ] ^{[145]} [145]。
考虑视频中时间连贯性(指短时间内的连续帧具有相似的连贯性外观)的思想,利用颜色一致性(color coherence)来作为监督信号,但是这方面的研究还较少。
(3)Video Prediction
视频预测(Video Prediction)是基于有限的视频帧来预测未来帧序列的任务,为了预测未来的帧,网络就必须学习到给定帧中外观的变化,因此可以利用这些视频预测的方法进行自监督学习。
通常视频预测框架分为编码器和解码器:
- 编码器:根据给定视频帧对空间和时间进行建模。
- 解码器:根据编码器提取的特征预测未来的帧。
目前,研究视频预测所学特征的泛化能力如何的工作还较少。
7.2 基于时序(Temporal Context-based)
-
Temporal Order Verification:输入一段视频序列,模型需要判断视频的序列是否是正确的序列 [ 40 ] ^{[40]} [40]。
-
Temporal Order Recognition:输入一段视频序列,模型需要给出视频的正确序列。
这些方法的通常会经历大量的数据准备步骤;训练网络使用的视频序列是根据光流(Optical Flow的解释可看:https://zhuanlan.zhihu.com/p/44859953)量决定的,光流计算是昂贵且慢的。
7.3 基于跨模态(Cross Modal-based)
基于跨模态的学习方法通常从多个数据流的对应关系中学习视频的特征,包括RGB帧序列(RGB frame sequence)、光流序列(optical flow sequence)、音频数据(audio data)、摄像机姿态(camera pose)。训练网络以识别两种输入数据是否彼此对应,或者训练网络以学习不同模态之间的转换。
(1)RGB-Flow Correspondence
验证输入的RGB帧和光流是否彼此对应来学习视频特征 [ 23 ] , [ 24 ] ^{[23],[24]} [23],[24]。
(2)Visual-Audio Correspondence
利用视频和音频对应关系学习特征的方法 [ 25 ] , [ 93 ] ^{[25],[93]} [25],[93]。

通过从一个视频的同一时间提取视频帧和音频来采样正数据,而通过从不同的视频或一个视频的不同时间提取视频帧和音频来生成负训练数据。训练网络以发现视频数据和音频数据的相关性以完成此任务。
(3)Ego-motion
利用以自我为中心的视频和自我运动信号 [ 94 ] , [ 95 ] ^{[94],[95]} [94],[95]之间的对应关系进行学习。
参考链接:https://blog.csdn.net/cserwangjun/article/details/103154308
7.4 总结
用于视频的自监督学习前置任务总结:

8 性能比较
8.1 学习图像特征的性能
使用来自AlexNet的卷积层的激活作为特征对ImageNet和Places数据集进行线性分类,其中“Places labels ”和“ImageNet labels ”两行为具有人工注释标签的监督学习,结果如下,

- 自监督学习的性能总是由于从头训练(第二栏第一行)。
- 所有自监督方法都在conv3和conv4表现较好,可能因为浅层捕获了一般的低级特征,而深层捕获了与预任务相关的特征。
- 当用于训练预任务的数据集与下游任务的数据集之间存在领域差距时,自监督学习方法能够达到与使用ImageNet标签监督训练的模型相当的性能。
在除了图像分类下游任务,在目标检测和语义分割的性能对比如下:

总体来看,DeepClustering在所有自监督学习方法中表现最好。
8.2 学习视频特征的性能
比较现有的自我监督方法在UCF101和HMDB51数据集上的动作识别性能,Kinetics Label表示人工注释标签的监督学的性能:

9 展望
(1)Learning Features from Synthetic Data(从合成的数据中学习)
-
利用合成数据来练网络,因为通过游戏引擎生成的图像和视频可以自动生成精确的注释,从而利用预任务从合成数据中学习特征具有较好的效果。
-
现存问题:如何弥合合成数据和真实数据之间的领域鸿沟。
(2)Learning from Web Data(从网络数据中学习)
- 利用网络收集的数据 [ 22 ] , [ 167 ] , [ 168 ] ^{[22],[167],[168]} [22],[167],[168],并基于它们现有的关联标签来训练网络。通过大规模Web数据及其关联的元数据,可以提高自我监督方法的性能
- 现存问题:如何处理Web数据及其关联的元数据中的噪声。
(3)Learning Spatiotemporal Features from Videos(从视频中学习时空特征的性能)
- 自监督学习的图像特征已经具有不错的效果,但是视频特征(尤其是3DConvNet)的自监督学习效果不是很好,还有待新的自监督方法来提高性能。
(4)Learning with Data from Different Sensors(从不同传感器的数据中学习)
- 目前的研究关注的主要是视频和图像,但是如果可以使用来自不同模态的其他类型数据,则可以将不同数据类型直接的对应或约束关系应用于网络的训练 [ 155 ] ^{[155]} [155]。
- 通过自动驾驶汽车可以很容易获得多种传感器的数据集,如RGB摄像机、灰度摄像机、3D激光扫描仪、高精度GPS测量和IMU加速等。
(5)Learning with Multiple Pretext Tasks(使用多个预任务进行学习)
- 现有的大多数自监督学习都是训练网络解决某一个Pretext task,很少研究探索是否使用多个预任务进行训练会有更好的性能 [ 30 ] , [ 32 ] ^{[30],[32]} [30],[32]。
参考链接:
一文读懂 Self-Supervised Learning
Self-supervised Learning 再次入门
部分参考文献:
[8] A. Krizhevsky , I. Sutskever, and G. E. Hinton, “Imagenet classification with deep convolutional neural networks,” in NIPS, pp. 1097–1105, 2012.
[9] K. Simonyan and A. Zisserman, “V ery deep convolutional networks for large-scale image recognition,” ICLR, 2015.
[10] C. Szegedy , W. Liu, Y . Jia, P . Sermanet, S. Reed, D. Anguelov , D. Erhan, V . Vanhoucke, and A. Rabinovich, “Going deeper with convolutions,” CVPR, 2015.
[11] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in CVPR, pp. 770–778, 2016.
[12] G. Huang, Z. Liu, K. Q. Weinberger, and L. van der Maaten, “Densely connected convolutional networks,” in CVPR, vol. 1, p. 3, 2017.
[15] C. Ledig, L. Theis, F. Huszar, J. Caballero, A. Cunningham,
A. Acosta, A. P . Aitken, A. Tejani, J. Totz, Z. Wang, and W. Shi,
“Photo-realistic single image super-resolution using a generative
adversarial network,” in CVPR.
[18] R. Zhang, P . Isola, and A. A. Efros, “Colorful image colorization,”
in ECCV, pp. 649–666, Springer, 2016.
[19] D. Pathak, P . Krahenbuhl, J. Donahue, T. Darrell, and A. A. Efros, “Context encoders: Feature learning by inpainting,” in CVPR, pp. 2536–2544, 2016.
[20] M. Noroozi and P . Favaro, “Unsupervised learning of visual representions by solving jigsaw puzzles,” in ECCV, 2016.
[21] D. Mahajan, R. B. Girshick, V . Ramanathan, K. He, M. Paluri, Y . Li, A. Bharambe, and L. van der Maaten, “Exploring the limits of weakly supervised pretraining,” in ECCV, pp. 185–201, 2018.
[22] W. Li, L. Wang, W. Li, E. Agustsson, and L. Van Gool, “Webvision database: Visual learning and understanding from web data,” arXiv preprint arXiv:1708.02862, 2017.
[23] A. Mahendran, J. Thewlis, and A. V edaldi, “Cross pixel optical flow similarity for self-supervised learning,” arXiv preprint arXiv:1807.05636, 2018.
[24] N. Sayed, B. Brattoli, and B. Ommer, “Cross and learn: Crossmodal self-supervision,” arXiv preprint arXiv:1811.03879, 2018.
[25] B. Korbar, D. Tran, and L. Torresani, “Cooperative learning of audio and video models from self-supervised synchronization,” in NIPS, pp. 7773–7784, 2018.
[26] A. Owens and A. A. Efros, “Audio-visual scene analysis with self-supervised multisensory features,” arXiv preprint arXiv:1804.03641, 2018.
[27] D. Kim, D. Cho, and I. S. Kweon, “Self-supervised video representation learning with space-time cubic puzzles,” arXiv preprint arXiv:1811.09795, 2018.
[28] L. Jing and Y . Tian, “Self-supervised spatiotemporal feature learning by video geometric transformations,” arXiv preprint arXiv:1811.11387, 2018.
[29] B. Fernando, H. Bilen, E. Gavves, and S. Gould, “Self-supervised video representation learning with odd-one-out networks,” in CVPR, 2017.
[30] Z. Ren and Y . J. Lee, “Cross-domain self-supervised multi-task feature learning using synthetic imagery ,” in CVPR, 2018.
[31] X. Wang, K. He, and A. Gupta, “Transitive invariance for selfsupervised visual representation learning,” in ICCV, 2017.
[32] C. Doersch and A. Zisserman, “Multi-task self-supervised visual learning,” in ICCV, 2017.
[33] T. N. Mundhenk, D. Ho, and B. Y . Chen, “Improvements to context based self-supervised learning,” in CVPR, 2018.
[34] M. Noroozi, A. Vinjimoor, P . Favaro, and H. Pirsiavash, “Boosting self-supervised learning via knowledge transfer,” arXiv preprint arXiv:1805.00385, 2018.
[35] U. Büchler, B. Brattoli, and B. Ommer, “Improving spatiotemporal self-supervision by deep reinforcement learning,” in ECCV, pp. 770–786, 2018.
[40] I. Misra, C. L. Zitnick, and M. Hebert, “Shuffle and learn: unsupervised learning using temporal order verification,” in ECCV, pp. 527–544, Springer, 2016.
[44] M. Caron, P . Bojanowski, A. Joulin, and M. Douze, “Deep clustering for unsupervised learning of visual features,” in ECCV, 2018.
[54] J. Donahue, L. A. Hendricks, S. Guadarrama, M. Rohrbach, S. V enugopalan, K. Saenko, and T. Darrell, “Long-term recurrent convolutional networks for visual recognition and description,” in CVPR, 2015.
[73] S. Hochreiter and J. Schmidhuber, “Long short-term memory,” Neural computation, vol. 9, no. 8, pp. 1735–1780, 1997
[81] D. Pathak, R. Girshick, P . Dollár, T. Darrell, and B. Hariharan, “Learning features by watching objects move,” in CVPR, vol. 2, 2017
[82] G. Larsson, M. Maire, and G. Shakhnarovich, “Colorization as a proxy task for visual understanding,” in CVPR, 2017.
[85] C. V ondrick, H. Pirsiavash, and A. Torralba, “Generating videos with scene dynamics,” in NIPS, pp. 613–621, 2016.
[86] S. Tulyakov , M.-Y . Liu, X. Yang, and J. Kautz, “Mocogan: Decomposing motion and content for video generation,” CVPR, 2018.
[93] R. Arandjelovic and A. Zisserman, “Look, listen and learn,” in ICCV, pp. 609–617, IEEE, 2017.
[137] R. Zhang, J.-Y . Zhu, P . Isola, X. Geng, A. S. Lin, T. Yu, and A. A.
Efros, “Real-time user-guided image colorization with learned
deep priors,” arXiv preprint arXiv:1705.02999, 2017.
[138] S. Iizuka, E. Simo-Serra, and H. Ishikawa, “Let there be color!:
joint end-to-end learning of global and local image priors for
automatic image colorization with simultaneous classification,”
TOG, vol. 35, no. 4, p. 110, 2016.
[155] T. Zhou, M. Brown, N. Snavely , and D. G. Lowe, “Unsupervised learning of depth and ego-motion from video,” in CVPR, vol. 2, p. 7, 2017
[167] S. Abu-El-Haija, N. Kothari, J. Lee, P . Natsev , G. Toderici, B. Varadarajan, and S. Vijayanarasimhan, “Youtube-8m: A large-scale video classification benchmark,” arXiv preprint arXiv:1609.08675, 2016.
[168] L. Gomez, Y . Patel, M. Rusi˜ nol, D. Karatzas, and C. Jawahar, “Self-supervised learning of visual features through embedding images into text topic spaces,” in CVPR, IEEE, 2017.