| 目录 |
| - 1、Neutron 三层技术简介 - 2、集中式router - 1、在节点上安装L3 agent - 2、配置外部网络 - 3、通过CLI或者Horizon 来创建路由 - 4、连接租户网络和外部网络 - 5、启动实例 - 6、配置路由器的NAT功能 - 3、高可用路由 - 4、分布式路由(DVR) - dvr创建 - dvr东西向流量 - dvr南北向流量 - NAT流量模型 - 浮动IP - ARP代理 - 5、云上的三层架构设计 |
1、Neutron 三层技术简介
三层的实现主要对应传统路由器组网的功能。包括三层的路由、NAT转换、ARP代理、DHCP服务等。neutron在三层的实现上与二层的耦合性较低,即无论二层采用linux bridge还是ovs,L3都是采用的相同的实现方式。
但有意思的是,三层也分两种不同的实现架构:分别是集中式、分布式。这两者之间也恰好代表了传统和未来的两种实现方式。
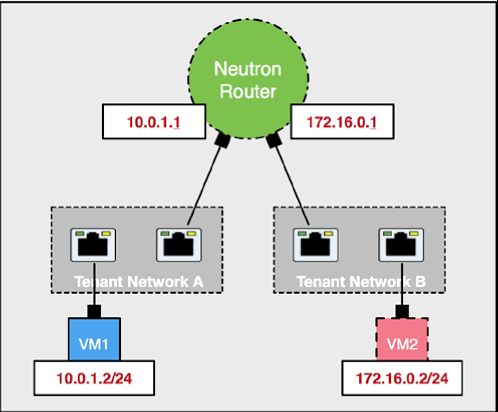
集中式路由

分布式路由
2、集中式router
openstack的 Juno 版本时期,用户只能创建单机的路由器,即不同的VPC之间要实现互联,VPC内的数据需要全部转发到该路由实例上进行转发。
路由实例在这种场景下,提供:
1、用户内网(VPC与VPC)之间的互联、
2、用户内网与外网(VPC与基础网络、Internet、DCI)之间的互联,通常还要兼任NAT网关的工作。

用户创建的虚拟网络之间是隔离的,无法互相访问。Neutron router 作为默认的网关能够实现租户网络之间的互访。
路由器同样是主机linux系统内的一个网络命名空间,单机部署时,一般部署在物理集群的网络节点上,一边连接租户网络,一边连接外部网络。下图是openstack官方文档中对neutron router的介绍:
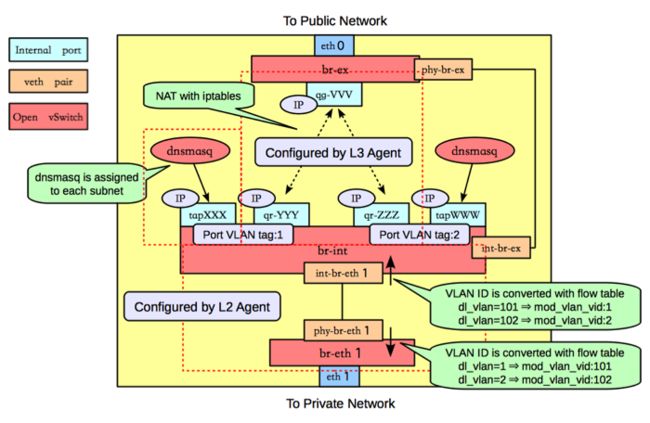
图中br-int、br-ex、br-eth 是ovs的交换机,路由器和虚拟主机一样连接在br-int上,用户的每一个私有网段都会连接到路由器的一个接口上,同时路由器上行连接到外部交换机上,实现用户私有网络与外部的通信。并由主机上的 L3 Agent 来完成路由器的配置。图中的 dnsmasq 是linux上的一个小型服务器,neutron 用它来实现 DHCP server 的功能,租户的每一个私有网络都会创建一个对应的 dnsmasq 实例。
内网与外部网络之间的NAT地址转化则是在路由器上完成。NAT转换使用的是在安全组的介绍中提到过的iptables。由iptables对数据包源地址或目的地址进行重写,实现路由器的SNAT和DNAT。
在openstack的网络节点上创建用户路由器的整体流程如下:
1、在节点上安装L3 agent
安装neutron L3 agent需要在cotroller节点上运行以下命令,跟安装一般软件包没有区别。
# apt-get install neutron-l3-agent
Neutron router同时支持linux bridge和ovs。
2、配置外部网络
/etc/ neutron/l3_agent.ini
[DEFAULT] …
external_network_bridge =
该配置项用于指定路由器的上行交换机。默认值为 br-ex ,即使用br-ex作为连接外部网络的交换机,一旦使用br-ex后,neutron会将路由器的上联口连接到br-ex上,并且路由器将不会处理vlan标签的插入和移除。这种情况下L3 agent只能关联一个外部网络,该主机上的所有的路由器都将使用这个外部网络作为上行的网络。
如果这值为空,L3 Agent将自行创建交换机、端口、和交换机的流规则。并且同时关联多个外部网络。所以该怎么做,已经一目了然了吧。
当有多个外部网络时,需要手动设置网络属性为 router:external。
除此之外如果要制定某个特定的外部的网络,则需要设置 gateway_external_network_id =
此外较早期版本的openstack中,路由器删除后,路由器所使用的网络命令空间不会自动删除,需要修改配置文件中
[DEFAULT] ...
router_delete_namespaces = true
3、通过CLI或者Horizon 来创建路由
然后就可以开始创建路由器了。
router-create [--tenant-id TENANT_ID] [--admin-state-down] NAME
4、连接租户网络和外部网络
连接指定的租户网络
router-interface-add ROUTER INTERFACE
连接外部网络
router-gateway-set [--disable-snat] ROUTER EXTERNAL-NETWORK
路由器默认会开启SNAT功能,为租户网络内的虚拟机提供NAT服务,保证虚拟机与外部网络通信。
需要注意的是,目前为止,一个路由器只能连接一个外部网络。所有内部网络的流量都将经由此接口流出。这既与neutron router的定位有关,又影响了openstack三层的组网结构。很明显neutron 的路由器不适合作为汇聚路由器、核心、或者出口路由。无法实现路由之间的互联、也不支持动态路由协议。所以当前opentsack是无法实现租户复杂组网环境的。不同子网的虚拟机需要连接到一个路由器,来实现互联互通。这直接导致大规模部署时,集中式路由器基本不可用。基本上是一环扣一环推出,未来铁定是分布式路由器的天下。只能说当前 openstack 在三层组网上稍有欠缺,而nicira在这一块则完整得多。
有意思的是,当前 opentack 的 project 中还没有看到路由器的规划,有点好奇未来openstack将用何种方式填补这一空缺,是直接像 nicira 一样引入 NFV, 还是用ovs来代替路由器,亦或是再给iproute2缝缝补补续上几年。
5、启动实例
启动虚拟机,并按照上一篇的内容连接租户网络。
6、配置路由器的NAT功能
这里就主要是使用浮动IP了。
neutron路由器支持一对一的静态NAT,和多对一的PNAT。默认情况下路由器执行PNAT操作,租户网络内的主机经路由器与外部通信时,源地址都会修改为路由器路由器外部接口的地址。这也被称作源地址转换SNAT。是内网主机上网最常用的一种方式。这种情况下所有的主机共用一个外网地址,外部网络的主机无法主动发起与内网的通信。这时就需要静态NAT功能,将内网主机映射为特定的外网地址。即给主机绑定一个fip。
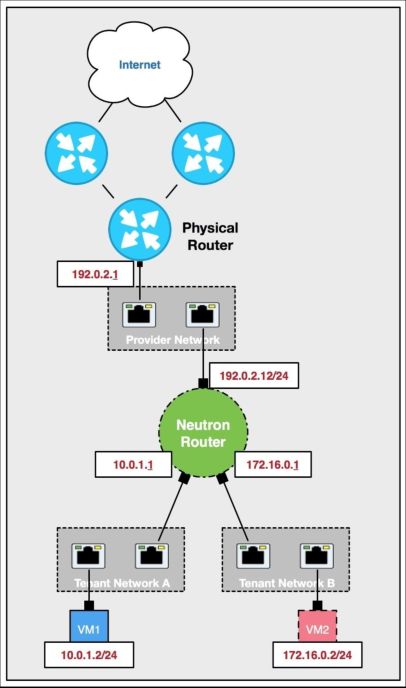
Neutron route 为虚拟机提供NAT服务
通过路由的NAT功能,只要统一做好外部网络的地址规划后,即可实现租户内网IP子网的复用,不同的租户之间能够复用完全相同的子网网段,且不会冲突。这也是公有云上能够容纳大量租户的原因之一。
集中路由模式的问题显而易见,网络节点上的路由成为流量的瓶颈点和故障点。在这种模式所有租户的VPC之间的流量的都经由网络节点上的路由器转发,当云上的租户较多,所有的流量都汇集到网络节点的设备上,会直接导致网络拥塞。同时单个router出现故障,如被重启时,租户网络之间就无法通信了。
3、高可用路由
高可用路由模式是对集中路由模式的一种补充,其核心是采用VRPP协议实现双路由部署模式下的高可用。VRRP(虚拟路由冗余协议)脱胎于 cisco 的 HSRP,是一个老牌的网络协议了。在传统网络设备中就被大量的使用,曾经也有过VRRP+MSTP这种典型的组网模式,扯远了。
VRRP 部署模式下,网络节点上需要部署多个路由器,组成一个 VRRP 组,组内的路由器将通过一个虚拟IP与外界通信。也就是说外部回指路由指向这个虚拟的IP。
VRRP组内将选举出一个活动的路由器,其余的路由器则作为热备路由器。主路由器将响应发送给虚拟IP的数据包,备用路由器则不会响应。备用路由器将通过心跳信号检测主路由器的存活情况,当主路由发生故障时,剩下的备用路由器中将选举出一个新的活动路由器,备胎转正。
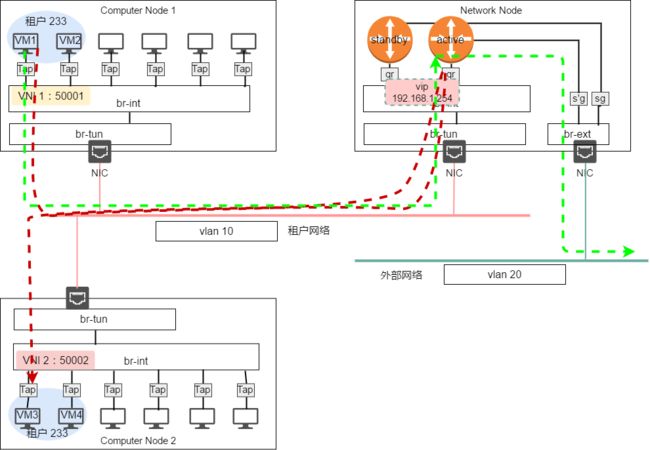
VRRP的大名路人皆知,这里就不赘述了。很容易看出,高可用路由模式解决了路由器单点故障的问题,单个路由器故障时,备用路由将接替故障路由器的工作,以保证租户网络流量的正常。
但是同时,高可用路由模式依旧同时只有一台路由在工作,流量发卡弯的问题依旧没有解决,路由器依旧是大规模部署时的网络性能瓶颈。这个时候最终就该DVR(分布式虚拟路由器)登场了。
4、分布式路由(DVR)
是的,就是上篇中提到的Linux bridge不支持的那个DVR。
分布式的使用场景下,内外网的流量不再汇集到网络节点上之后再转发。而是在计算节点本地就能处理,在该模式下,当租户在计算节点上创建了使用DVR的私有网络时,该节点随之会自动创建一个路由器实例。传统模式下跨子网的通信都需要将数据包转发到网络节点的路由器上,分布式路由器模式下跨子网的通信,都会由本地的路由器来执行路由
。
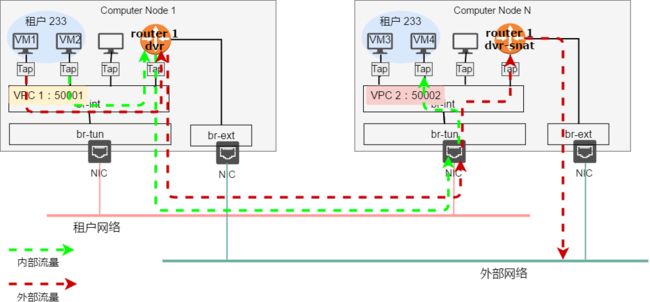
Dvr 流量模型
DVR有两种运行模式。一个是 dvr-snat 模式,该模式的下,主机上的 dvr_snat 不仅要负责不同子网之间东西向的流量,还要作为租户网络与外部网络通信的网关。内网与外部网络所有的南北向流量都需要经过该主机上的 dvr 进行传输,并启用路由器SNAT功能。另一种则是 dvr 模式,这一模式下,dvr 仅处理租户网络内部子网的东西向流量,即租户在物理主机与物理主机之间的内网流量。该配置由由L3agent的配置文件实现
agent_mode = dvr_snat/dvr
dvr创建
dvr 路由器的创建的命令则与普通路由器一样,不过最后要带上--distributed 参数。其他命令与传统路由器类似,采取同样命令进行管理。不过需要注意的是 dvr 二层只能使用 ovs,且需要在所有计算节点上启用 ovs,并修改 neutron ML2 的配置文件的参数:
/etc/neutron/plugins/ml2/ml2_conf.ini
……
enable_distributed_routing = True
l2_population = True
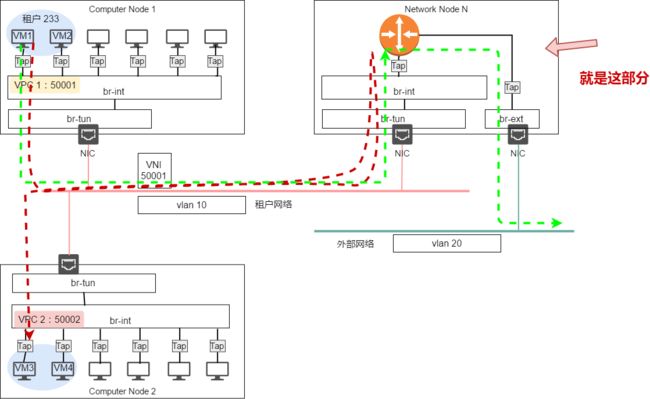
dvr创建好后,neutron L3 agent 会在所有连接了 dvr 的子网所在的主机上都会自动创建一个dvr的实例,用来对本地子网的流量进行路由。ovs则会连接路由器接口,并生成对应的流表。
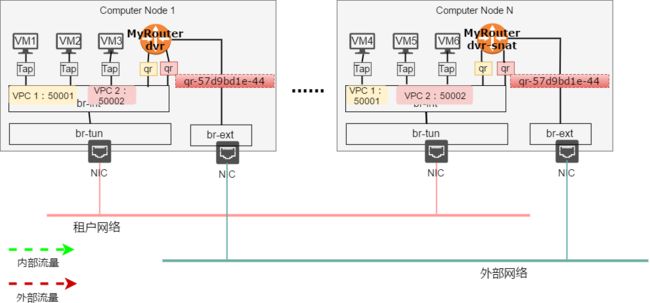

在管理的时候,看到的是单个路由器
实际上在每一个计算节点上都有一个该路由器实例,如下图中的MyRouter-DVR 就在controller01和computer01、02上分别创建了路由器实例,这些路由器由DVR统一配置。

通过ip netns exec命令可以查看ar路由器的接口信息和命名空间,每个路由器实例都共享相同的接口名称、IP地址、MAC地址。
控制节点:

计算节点:
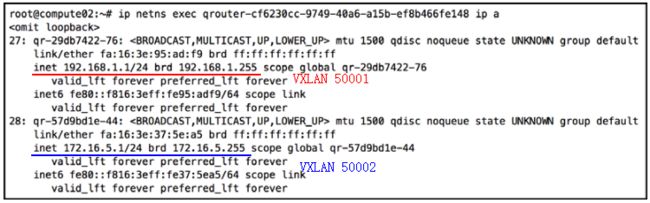
可以看到,控制节点和计算节点上的两个路由器都包含ip地址为192.168.1.1 的qr-29db7422的接口,这个接口都连接到同一个子网 VPC 。VPC内的虚拟机需要跨子网通信时,可以就近将数据包发往本地的网关。本地的路由实例收到数据包后进行路由。
不过这也带来一个显著的问题,如果两个路由器的接口使用相同的 IP 地址和 MAC 地址的话,那么交换机将从不同的接口上学到相同的MAC地址,在交换机收到虚拟机发来的目的MAC地址为网关的二层帧的时候,交换机将不知道要将数据包发送到哪个接口上,这将导致交换机转发表的震荡。
dvr东西向流量

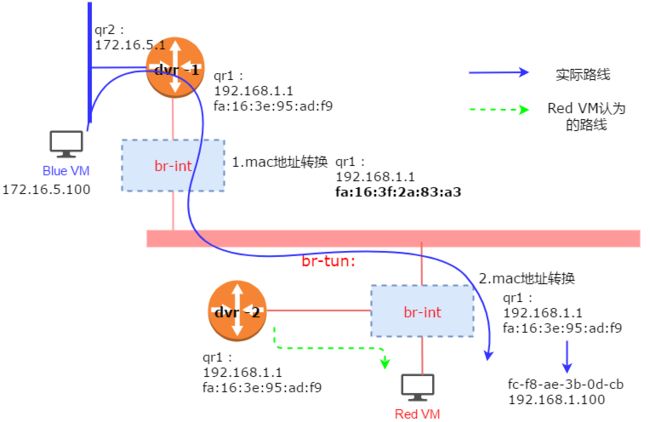
为了解决相同的IP和MAC,导致虚拟交换机上 MAC 地址漂移的问题,neutron 引入了独立MAC地址,每个命名空间都有各自不同的MAC地址,但是当分布式路由器的数据包从计算节点内部离开时,ovs的流规则会对数据包的源MAC地址进行改写,改为各个节点的独立 MAC地址。这样
而当数据从外部接入节点时,流规则会将源mac地址中的统一mac地址修改为本地路由实例的 mac 地址。实现 mac地址的转换。

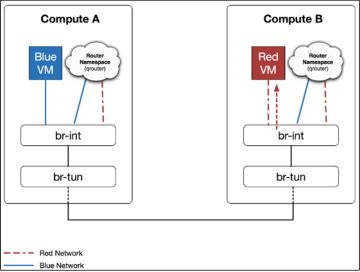
不同子网的虚拟机跨主机之间通信的这一详细过程如下:
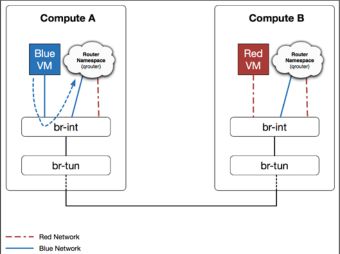

第一步:blue VM将数据包发往本地的网关,数据包的源mac地址为虚拟机网卡,目标mac地址为路由器在的接口。Br-int在收到数据包后将它发送给本地的router。
![]()
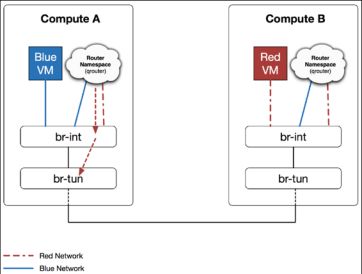
第二步,本地路由实例查找路由表后,发现Red VM 位于子网red,因此将数据包从路由器位于子网2的端口发送出去。此时处理还正常,源 MAC 地址为路由器在子网 Red 的 MAC 地址,目的地址为 Red 子网内 Red VM的地址。同时发往 br-int。
如果 br-in t如果不加任何修改,直接转发,br-tun势必从多台物理主机收到相同的 MAC,br-tun将无法正常回包。所以此 时br-int 会将路由器发来源 MAC 地址转换为主机的独立MAC,这样 br-tun 收到的数据包分别来自不同的主机。
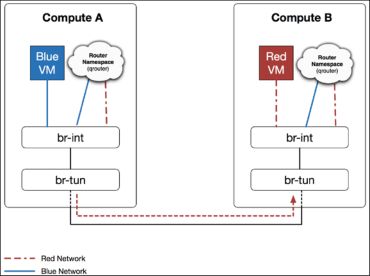

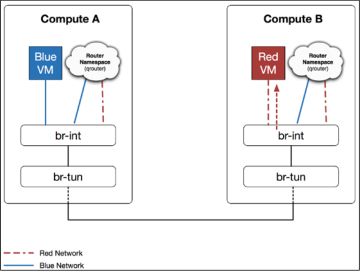
第三步:接下来,br-tun 看到目的为Red VM ,正常将数据包转发给位于主机B。
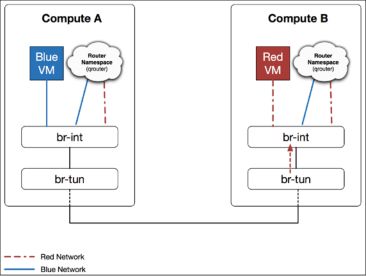

第四步:主机B上的 br-tun 收到数据包之后,正常将数据包解封装,并根据流规则添加local vlan的标签,并转发给br-int。
![]()
第五步:主机B上的br-int 在收到数据包后,知道要发给 vlanxx 内的Red VM。同时主机B上的 br-int将包的源 MAC 地址从主机A的独立 MAC 转换为路由器在 Red 子网的接口的 MAC。

第六步:br-int 根据流规则去掉vlan标签随后转发到对应的red VM。
经过这一系列的转换,Red VM以为自己全程在与本地路由器在通信,而实际上数据包是从另一台主机上的路由器发来的。而在br-tun看来,只是三个不同 MAC地址的主机在通信而已。
全程缩略图如下:
dvr南北向流量
南北向的流量主要分为两种情况,一种是子网内所有主机共有一个出口:SNAT、一种是单个主机绑定浮动IP,这两种情况稍有不同。
NAT流量模型
Neutron 默认开启了SNAT,没有绑定FIP的虚拟机访问外部网络时,路由器会将数据包中虚拟机的内网地址改写为路由器外部接口的地址。集中式路由、HA路由、分布式路由都支持SNAT。当使用DVR时,只有工作于dvr_snat模式的路由器才负责与外部的网络的通信和SNAT。
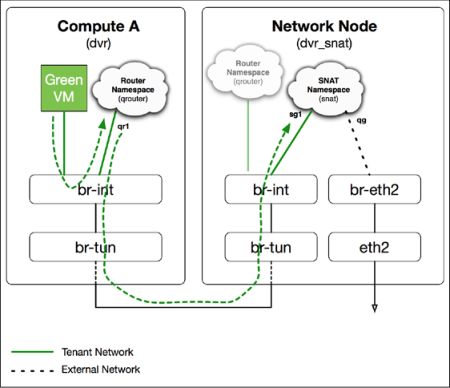
传统模式下,所有与外部交互的流量都通过网络节点上的路由器上,并通过浮动地址与外部通信。SANT 命名空间专门用作 SNAT服务,浮动IP和路由上的SNAT都是由它实现。
Dvr-snat模式下,路由器会附加一个同名的nat命名空间。创建后,路由器不再与外部网络直接连,而是通过SNAT的 qg 端口与外部连接。同时,SNAT上还有一个端口连接到内网,这个内网端口的地址与路由器内网接口的地址在同一个子网。例如同为 192.168.1.0/24.

路由器的内网接口
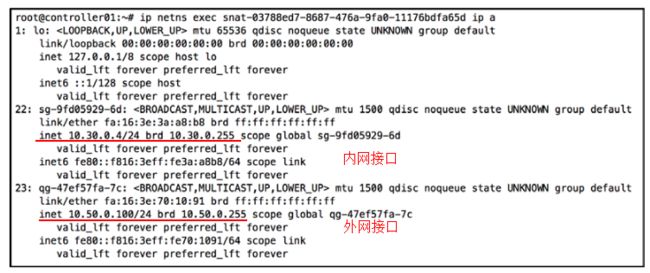
snat的两种接口

计算节点上添加的默认路由
注意,此时计算节点上的默认路由指向了SNAT的内网接口地址。SNAT收到包后会修改包头的源IP地址为外网接口的地址,然后转发到外部网络。
浮动IP
如果说SNAT是一群主机的狂欢,那么浮动IP就是一台主机的孤单。公有云中最为常见的功能,通过将公网地址直接绑定到主机网卡上,实现主机与外部网络的直接通信。并可以随时解绑,关联到其他任意主机。
浮动IP本质上是1对1的静态NAT,将主机的内网地址翻译成公网地址,实现主机与外部的通信。当租户创建FIP关联时,neutron L3agent即在节点上创建一个network namespace,作为3层的插件来实现NAT地址转换。FIP一端连接外部网络、一端连接着路由器。

当浮动IP直接关联到虚拟机上时,计算节点上的L3 agent会创建一个新浮动ip命名空间(fip namespace),并创建新的 fg 端口与浮动ip所属的外部网路进行通信。fip命名空间依靠该端口与外部网络通信,该端口也需要配置一个外部网络的ip地址。
该计算节点上的路由器命名空间也连接到相同的外部网络,则会通过一个veth接口与fip的命令空间相连,并且会使用169.254.x.x地址段中一个反掩码为/31的ip地址作为接口地址。每个主机上只有一个fip命名空间,多个路由器连接到这一个命名空间。
在路由器这端,接口名称为rfp (router to FIP)

在fip 命名空间这端,接口名称为fpr(FIP to router)
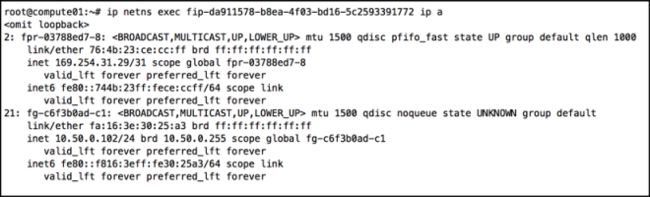
同时qrouter的命名空间中会添加一条新的源路由规则:
32768: from 10.30.0.3 lookup 16
其中 对应的路由条目为:
![]()
也就是,当关联了浮动ip的vm与外界通信时,默认会通过rfp接口转发到FIP命名空间中进行处理。所有的计算节点上都可能有主机需要通过 FIP 来连接外部网络,这要求所有的物理主机都有网卡连接到外部网络。这会导致公网ip的浪费,现实中通过其他途径来解决这一问题。
ARP代理
之前的内容都是内网上行的流量,那么从外界进入内网的流量呢?这就涉及到南北向流量的最核心的问题——上下行流量的对称性。特别是云环境中,虚拟机会任意漂移,绑定了FIP的虚拟机可能出现在集群的任意一台主机上,这就给路由带来了很大的困扰。

arp代理用于fip 回包
FIP的fg接口上设置了公网地址,同时FIP可能还关联了多个绑定了公网IP地址的云主机,当路由器需要知道这些云主机在哪时,例如访问一个绑定了公网IP的web服务云主机。这时FIP会启用ARP代理,即当外界的路由器发起ARP请求时,FIP会通过将自己的MAC地址提供给路由器,这样路由器能够正常回包,而又不用每个云主机都绑定一个不同的FIP。
这要求外界的路由器接口与这些FIP之间具备二层的互联能力,路由器的ARP的广播包能够直接传递到集群的主机。
5、云上的三层架构设计
Neutron router的三层功能发展至今已经基本能够满足云上租户的需求。租户可以基于以下的拓扑组建自己的云上三层网络。租户不同的VPC通过路由器连接在一起,实现VPC之间、VPC和外网之间的通信。
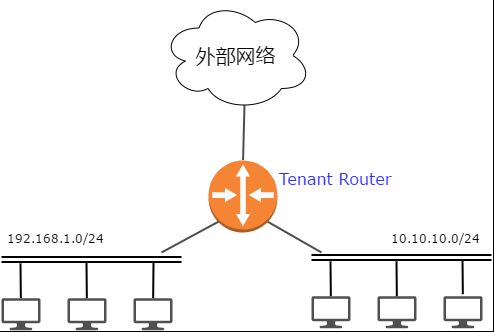
三层路由器逻辑拓扑

DVR逻辑拓扑
但也仅此而已。流量从VPC出去之后呢?underlay网络的路由如何走?
出口选路和负载均衡由谁负责?公网地址池的容量不够了怎么办?核心网络的路由有调整该怎么办?
对于云服务提供者来说,neutron的功能还远不能满足他们的使用需求。云的运营者需要的是从租户创建虚拟网络、连接虚拟机、关联公网地址、创建到外部的访问策略等这一完整的服务链的协调、编排、控制。而且这一切要对上层透明,对底层交换机、路由器、防火墙、虚拟路由、虚拟防火墙等设备的操作。实现underlay网络和overlay网络一体化的自动化管理。
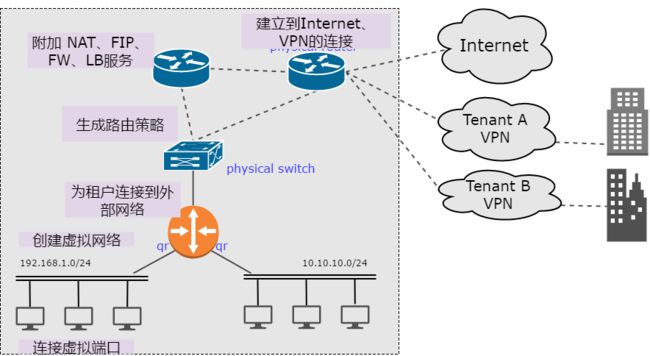
云网络自动化
显然,Neutron还不能形成一个完整的闭环,这也是大量SDN企业的发力点。那有较为完善的商业系统能够与openstack集成,实现全网络的自动化编排以满足我们的需求么?
首先看 VMware(nicira):

VMware 给出的解决方案是NFV,VMware在租户层面上与openstack类似,同样的分布式交换机、分布式路由器。但是VMware比openstack多出了一个组件:Edge。VMware推荐使用Edge作为租户分布式路由器的下一跳设备,Edge以NFV的方式承载了租户网络的FW、NAT、LB等功能,并且运行着动态路由协议,可以实现与外部网络之间的路由交换。
这样做的好处显而易见,Edge 可以通过 VMware 的NSX平台统一管理,租户网络的所有操作都可以自动化完成,无需底层unerlay网络的参与即可实现,物理设备仅需实现互联即可,无需做任何更改。从租户的创建到最后租户的离开,都可以实现自动化的编排。
其次,Edge是虚拟设备,云提供商可以按需增加和缩减设备,为不同的租户分配不同的虚拟设备,这样整个网络中不会存在明显的单点故障点,流量被分散开来。
但是这样做也存在以下的问题:1.使用NFV的方式实现,则底层硬件只能使用X86的设备,X86设备作为转发设备费效比太低,NAT、FW性能嬴弱,单个NFV设备能够承载的租户有限,如果数据中心内部流量过大,很可能导致需要部署大量的网络节点来解决这一问题。

相比openstack,VMware的NSX平台显然更为成熟,也更为完善。
然后是juniper
Juniper 在SDN方面收购了open contrail 与其硬件路由器、虚拟防火墙一起组成了较为完整的云数据中心SDN解决方案。并可以与openstack平台集成,实现网络的自动化编排。

Open Contrail 架构
Contrail 的控制器包含三大组件,分别是配置、分析、控制。配置组件负责与其他系统的对接(如,Openstack Neutron),并将北向的应用层的需求翻译成对网元的操作,控制组件负责将配置信息同步到各个网元中,分析系统则实时从网元中获取数据并进行呈现。
转发层面则是由分布在各个计算节点上的vRouter完成,vRouter定位类似OVS,本身由vRouter Agent和位于hypervisor中的转发平面构成。vRouter Agent通过XMPP与控制器通信,获取路由等信息,并植入到转发平面中。转发平面上的转发表(FIB)记录了到达各个目标主机的路由信息,同时其包含的流表则提供了丰富的防火墙、负载均衡等功能。
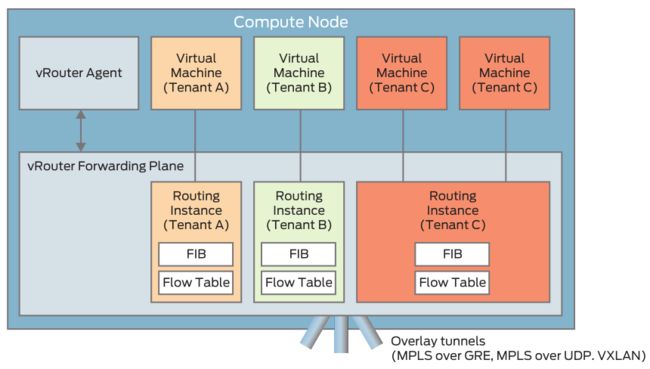
相比Neutron更为优势的是,OpenContrail 的服务链支持更为智能的转发策略。并支持通过gateway节点实现租户网络与外部Internet或VPN的连接。得益于juniper在硬件领域的优势,gateway节点可以选用 Juniper Networks MX 系列 3D 通用 Edge Routers 和 QFX 系列 、EX 系列的交换机。

MX系列路由器
juniper的MX系列路由器有着不错的性能和丰富的特性,支持MPLS、BGP、VPN、VXLAN、和VRF等特性,基本可以满足云租户的各种出口场景的使用需求。并且也可以扩展DPI、防火墙、负载均衡等等线卡。
而且Contrail 控制模块与Gateway之间是通过BGP协议来交换路由信息的,这也是现如今大部分硬件路由器和软件路由广泛支持的协议,所以使用非juniper的路由器无需改动也一样能达到相同的效果,仅仅只是缺失部分juniper独有的特性。
OpenContrail的解决方案在转发层面虽有不同但与openstack是非常类似的,同时通过bgp协议对硬件设备的的统一编排,实现租户与外部、租户与租户之间L2-L7的服务链实现。整个方案的架构上没有明显的短板,难怪的获得了Mirantis 的认可,作为其openstack发行版默认的SDN组件,将来很有可能将完全替代 Neutron,成为其私有云甚至容器平台的SDN解决方案。但技术的先进不能决定产品的成功,未来还等 OpenContrail 给出答案。
然后是cisco
Cisco的 DNA (Digital Network Architecture) 解决方案覆盖了从接入到WAN、数据中心和云多个领域,包含了网络的方方面面。
与此同时Cisco也推出一系列的网络设备作为数据转发设备,包括Cisco Catalyst系列、Nexus系列交换机、ISR、ASR、ASA路由、安全设备、以及无线设备等。以及一系列的管理、控制软件 SD-Access(终端接入)、DNA Center(云内网络)、SD-WAN、IWAN(智能广域网)。产品成熟度较高,且拥有能够覆盖大多数网络使用的场景。
基于这个统一的平台,Cisco希望能够在所有这些场景下上提供一套端到端的的控制策略,实现全网的的SDN化。与此同时Cisco甚至允许用户自行编写应用运行在设备上,以提供额外的功能和更适应客户的网络环境。

DNA解决方案

DNA 产品
Cisco的SDN解决方案秉承着有限的开放策略,允许用户在Cisco允许的范围内进行一定的开发,但是这种开放是极度受限的,所有其上运行的应用都是通过调用设备自身提供的接口来实现新的功能,这受限于设备硬件和NOS本身的能力,以及软件的License。真正涉及到操作系统、底层功能等核心的部分依旧是封闭的。在当前环境下这种有限的开放能满足大部分企业的需求,但是鉴于其架构与常用的开源方案架构差异较大,用户迁移壁垒较高,整个服务链中只要有一环不是Cisco的设备就无法实现完全的自动化和编排,而同时开源解决方案展现的强大生命力已经让昔日的大哥黯然失色。
最后,Cisco这套全家桶可不便宜…
midonet
midonet同样采用的是分布式架构,没有中心化的网络节点,所有节点的流量都由计算节点本地的midolm agent来路由,但是midonet 引入了一个 gateway 节点,网关节点上运行开源的BGP Daemon ( Quagga )路由软件,通过BGP实现外部网络与Internet之间的路由交换。新版的(5.0以后)midonet以及支持创建多个gateway实现出口的分流。
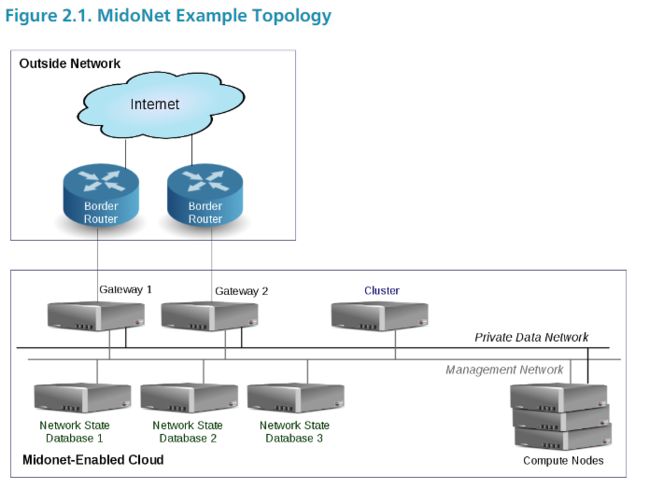
midonet的实现与vmware类似。通过 Provider router 来实现云内网络与云外网络的互联,provider router可以代替传统的出口路由器或者VPN设备,而云内部的流量则由计算节点上的网络agent来管理和维护。
最后上个big switch
Big Switch Fabic最大的特色是在转发层面上有两套方案:
一是,Switch light OS,一个轻量化网络操作系统,基于开放计算联盟(OCP)中的开放网络项目构建。Switch light OS可安装在支持Broadcom Trident系列或 Tomahawk 系列ASIC芯片的交换机内部。并可以兼容诸多开源的转发插件,如:Quagga(是的,就是Midonet gateway上使用的那个,支持非常丰富的路由特性)、BIRD以及Facebook FBOSS 。这样使得一台支持OCP标准的白牌交换机能够直接变为一台SDN交换机。
另外一个,Switch Light VX则是一套部署在KVM上的虚拟化版本,在OVS内核上增加了更多的功能并提升了性能。类似vmware的纯软件部署模式,同样能够实现网络的SDN化。
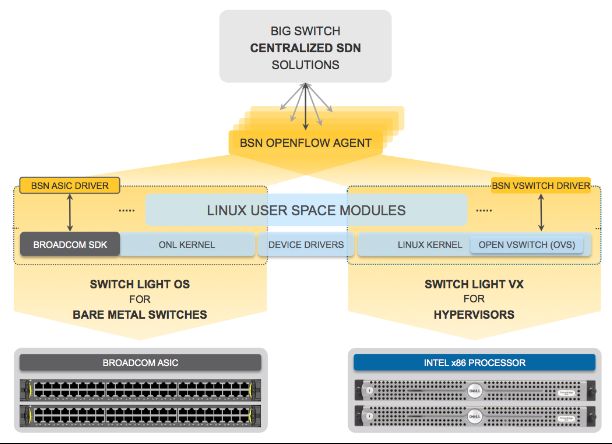
Big Network Controller 则是基于开源项目Floodlight 开发的SDN控制器,南向采用的是标准的openflow 标准协议对网元的转发行为进行控制,北向则向各种应用提供标准的API接口。

Big switch 这种“软硬结合”的方式,也可以算得上另辟蹊径了,不过Big Switch显然想做的是SDN界的微软,把控SDN设备的操作系统。不过显然的事实是,相比要用openflow统一南向的ONF来说,想把各设备厂家最核心的OS都给替换掉的Bigswitch简直是冒天下之大不韪,要了所有硬件厂家的命。几乎难以获得厂家的支持,除了与DELL合作了数款设备外少有大型设备厂商的支持。注定难以全面下沉到普通用户侧,其未来可能还要看由Facebook主导的开放计算联盟(Open Compute Project)的发展情况。
各路解决方案已经演化出自己的特色,给网络这一领域的技术发展带来了极大的活力,并开始在各个领域广泛应用,那么这些系统能够满足你的需求么?