一. 定时任务未生效
@Scheduled不生效了:有一天我的定时任务突然不执行了
可能原因 任务是懒加载的,调用一次之后才会加载执行
解决方法:手动配置了 定时任务的 ScheduledThreadPoolExecutor 代码如下:
@Configuration
public class ScheduleConfig implements SchedulingConfigurer {
@Override
public void configureTasks(ScheduledTaskRegistrar scheduledTaskRegistrar) {
scheduledTaskRegistrar.setScheduler(new ScheduledThreadPoolExecutor(Runtime.getRuntime().availableProcessors(),
new ThreadFactory() {
@Override
public Thread newThread(Runnable r) {
return new Thread(r,"my-schedule");
}
}));
}
}
基于 @Scheduled 的定时任务,其实会在 bean 实例化阶段 的 BeanPostProcessor(的具体子类实现ScheduledAnnotationBeanPostProcessor 的 postProcessAfterInitialization)将 所有附带 @Scheduled注解的方法检测出,分析对应的 参数内容, 然后加入各个任务队列之中。
我们配置了 定时任务 使用自己的 ScheduledThreadPoolExecutor 内部其实 基于 DelayQueue,每次任务执行完成之后会计算是否需要下次执行,以及下次执行的时间,然后将任务在放入队列之中。
关于 @EnableScheduling,不加这个注解,在项目启动时 @Scheduled(cron = "0 30 19 * * ?") 这个不会执行, 但是 @Scheduled(fixedDelay = 2)会执行, 因为 initialDelay是默认值的缘故,在将任务加入队列之前会 先 调用一下当前的任务,所以项目启动时 会执行一次。
二. Java 正则表达式:语法讲解和常用表达式汇总
使用正则表达式需要引入 java.util.regex 包,我们就从这里入手讲解:
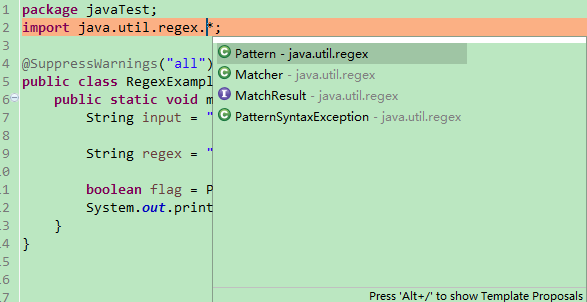
java.util.regex 包主要包括以下三个类:
Pattern 类:
Pattern 对象是一个正则表达式的编译表示。Pattern 类没有公共构造方法。要创建一个 Pattern 对象,你必须首先调用其公共静态编译方法,它返回一个 Pattern 对象。该方法接受一个正则表达式作为它的第一个参数。
Matcher 类
Matcher 对象是对输入字符串进行解释和匹配操作的引擎。与Pattern类一样,Matcher 也没有公共构造方法。你需要调用 Pattern 对象的 matcher 方法来获得一个 Matcher 对象。

PatternSyntaxException:
PatternSyntaxException 是一个非强制异常类,它表示一个正则表达式模式中的语法错误。
1. 正则表达式的使用:
/* import java.util.regex.*; */
public void RegexExample() {
String input = "I am Jimmy from mp.csdn.net";
String regex = ".*csdn.*";
// 方式1:String 的 matches 方法
boolean flag1 = input.matches(regex);
// 方式2:Pattern 对象的 matches 方法
boolean flag2 = Pattern.matches(regex, input);
// 方式3: Matcher 对象的 matches 方法
Pattern p = Pattern.compile(regex);
Matcher m = p.matcher(input);
boolean flag3 = m.matches();
System.out.println("字符串中是否包含了'csdn'子字符串? " + flag1 );
System.out.println("字符串中是否包含了'csdn'子字符串? " + flag2 );
System.out.println("字符串中是否包含了'csdn'子字符串? " + flag3 );
}
输出结果:
- 字符串中是否包含了'csdn'子字符串? true
- 字符串中是否包含了'csdn'子字符串? true
- 字符串中是否包含了'csdn'子字符串? true
从上面的代码中,你会看到一个现象:
- 3种方式的底层实现其实是一样的,只是封装的成度不一样,实际也确实如此;
- 明白方式3,更有助于理解正则的执行过程;
2. 正则表达式语法
在其他语言中,\ 表示:我想要在正则表达式中插入一个普通的(字面上的)反斜杠,请不要给它任何特殊的意义。
在 Java 中,\ 表示:我要插入一个正则表达式的反斜线,所以其后的字符具有特殊的意义。
常用表达式汇总
三. 解决IDEA提示JAVA字符串常量过长问题
环境:
Intellij IDEA 2018.1.5;
在做一个非常长的JSON 转对象的dubug时Intellij IDEA 编译不通过,报”java常量字符串太长”,解决方案如下.
IDEA的操作流程:
File -> Settings -> Build,Execution,Deployment -> Compiler -> Java Compiler。
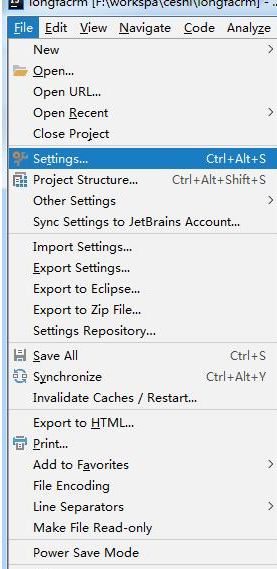

点击 Use Compiler, 选择Eclipse, 点击确定保存即可。
三. 关于SQL和MySQL的语句执行顺序
1. SQL执行顺序
- from
- join
- on
- where
- group by(开始使用select中的别名,后面的语句中都可以使用)
- avg,sum....
- having
- select
- distinct
- order by
从这个顺序中我们不难发现,所有的 查询语句都是从from开始执行的,在执行过程中,每个步骤都会为下一个步骤生成一个虚拟表,这个虚拟表将作为下一个执行步骤的输入。
第一步:首先对from子句中的前两个表执行一个笛卡尔乘积,此时生成虚拟表 vt1(选择相对小的表做基础表)
第二步:接下来便是应用on筛选器,on 中的逻辑表达式将应用到 vt1 中的各个行,筛选出满足on逻辑表达式的行,生成虚拟表 vt2
第三步:如果是outer join 那么这一步就将添加外部行,left outer jion 就把左表在第二步中过滤的添加进来,如果是right outer join 那么就将右表在第二步中过滤掉的行添加进来,这样生成虚拟表 vt3
第四步:如果 from 子句中的表数目多余两个表,那么就将vt3和第三个表连接从而计算笛卡尔乘积,生成虚拟表,该过程就是一个重复1-3的步骤,最终得到一个新的虚拟表 vt3。
第五步:应用where筛选器,对上一步生产的虚拟表引用where筛选器,生成虚拟表vt4,在这有个比较重要的细节不得不说一下,对于包含outer join子句的查询,就有一个让人感到困惑的问题,到底在on筛选器还是用where筛选器指定逻辑表达式呢?on和where的最大区别在于,如果在on应用逻辑表达式那么在第三步outer join中还可以把移除的行再次添加回来,而where的移除的最终的。举个简单的例子,有一个学生表(班级,姓名)和一个成绩表(姓名,成绩),我现在需要返回一个x班级的全体同学的成绩,但是这个班级有几个学生缺考,也就是说在成绩表中没有记录。为了得到我们预期的结果我们就需要在on子句指定学生和成绩表的关系(学生.姓名=成绩.姓名)那么我们是否发现在执行第二步的时候,对于没有参加考试的学生记录就不会出现在vt2中,因为他们被on的逻辑表达式过滤掉了,但是我们用left outer join就可以把左表(学生)中没有参加考试的学生找回来,因为我们想返回的是x班级的所有学生,如果在on中应用学生.班级='x'的话,left outer join会把x班级的所有学生记录找回(感谢网友康钦谋__康钦苗的指正),所以只能在where筛选器中应用学生.班级='x' 因为它的过滤是最终的。
第六步:group by 子句将中的唯一的值组合成为一组,得到虚拟表vt5。如果应用了group by,那么后面的所有步骤都只能得到的vt5的列或者是聚合函数(count、sum、avg等)。原因在于最终的结果集中只为每个组包含一行。这一点请牢记。
第七步:应用cube或者rollup选项,为vt5生成超组,生成vt6.
第八步:应用having筛选器,生成vt7。having筛选器是第一个也是为唯一一个应用到已分组数据的筛选器。
第九步:处理select子句。将vt7中的在select中出现的列筛选出来。生成vt8.
第十步:应用distinct子句,vt8中移除相同的行,生成vt9。事实上如果应用了group by子句那么distinct是多余的,原因同样在于,分组的时候是将列中唯一的值分成一组,同时只为每一组返回一行记录,那么所以的记录都将是不相同的。
第十一步:应用order by子句。按照order_by_condition排序vt9,此时返回的一个游标,而不是虚拟表。sql是基于集合的理论的,集合不会预先对他的行排序,它只是成员的逻辑集合,成员的顺序是无关紧要的。对表进行排序的查询可以返回一个对象,这个对象包含特定的物理顺序的逻辑组织。这个对象就叫游标。正因为返回值是游标,那么使用order by 子句查询不能应用于表表达式。排序是很需要成本的,除非你必须要排序,否则最好不要指定order by,最后,在这一步中是第一个也是唯一一个可以使用select列表中别名的步骤。
第十二步:应用top选项。此时才返回结果给请求者即用户。
2. mysql的执行顺序
SELECT语句定义
一个完成的SELECT语句包含可选的几个子句。SELECT语句的定义如下:
SQL代码
SELECT子句是必选的,其它子句如WHERE子句、GROUP BY子句等是可选的。
一个SELECT语句中,子句的顺序是固定的。例如GROUP BY子句不会位于WHERE子句的前面。
SELECT语句执行顺序
SELECT语句中子句的执行顺序与SELECT语句中子句的输入顺序是不一样的,所以并不是从SELECT子句开始执行的,而是按照下面的顺序执行:
开始->FROM子句->WHERE子句->GROUP BY子句->HAVING子句->ORDER BY子句->SELECT子句->LIMIT子句->最终结果
每个子句执行后都会产生一个中间结果,供接下来的子句使用,如果不存在某个子句,就跳过
对比了一下,mysql和sql执行顺序基本是一样的, 标准顺序的 SQL 语句为:
select 考生姓名, max(总成绩) as max总成绩
from tb_Grade
where 考生姓名 is not null
group by 考生姓名
having max(总成绩) > 600
order by max总成绩
在上面的示例中 SQL 语句的执行顺序如下:
- 首先执行 FROM 子句, 从 tb_Grade 表组装数据源的数据
- 执行 WHERE 子句, 筛选 tb_Grade 表中所有数据不为 NULL 的数据
- 执行 GROUP BY 子句, 把 tb_Grade 表按 "学生姓名" 列进行分组(注:这一步开始才可以使用select中的别名,他返回的是一个游标,而不是一个表,所以在where中不可以使用select中的别名,而having却可以使用,感谢网友 zyt1369 提出这个问题)
- 计算 max() 聚集函数, 按 "总成绩" 求出总成绩中最大的一些数值
- 执行 HAVING 子句, 筛选课程的总成绩大于 600 分的.
- 执行 ORDER BY 子句, 把最后的结果按 "Max 成绩" 进行排序.
四. [Err] ORA-00979: not a GROUP BY expression
Oracle中group by用法
在使用group by 时,有一个规则需要遵守,即出现在select列表中的字段,如果没有在组函数中,那么必须出现在group by 子句中。
(select中的字段不可以单独出现,必须出现在group语句中或者在组函数中。)否则就会出现错误。
在select 语句中可以使用group by 子句将行划分成较小的组,一旦使用分组后select操作的对象变为各个分组后的数据,使用聚组函数返回的是每一个组的汇总信息。
使用having子句 限制返回的结果集。group by 子句可以将查询结果分组,并返回行的汇总信息Oracle 按照group by 子句中指定的表达式的值分组查询结果。
在带有group by 子句的查询语句中,在select 列表中指定的列要么是group by 子句中指定的列,要么包含聚组函数 select max(sal),job emp group by job;
(注意max(sal),job的job并非一定要出现,但有意义) 查询语句的select 和group by ,having 子句是聚组函数唯一出现的地方,在where 子句中不能使用聚组函数。
select deptno,sum(sal) from emp where sal>1200 group by deptno having sum(sal)>8500 order by deptno;
当在gropu by 子句中使用having 子句时,查询结果中只返回满足having条件的组。在一个sql语句中可以有where子句和having子句。having 与where 子句类似,均用于设置限定条件 where 子句的作用是在对查询结果进行分组前,将不符合where条件的行去掉,即在分组之前过滤数据,条件中不能包含聚合函数,使用where条件显示特定的行。
having 子句的作用是筛选满足条件的组,即在分组之后过滤数据,条件中经常包含聚合函数,使用having 条件显示特定的组,也可以使用多个分组标准进行分组。
使用order by排序时order by子句置于group by 之后 并且 order by 子句的排序标准不能出现在select查询之外的列。
查询每个部门的每种职位的雇员数
select deptno,job,count(*) from emp group by deptno,job
记住这就行了:
在使用group by 时,有一个规则需要遵守,即出现在select列表中的字段,如果没有在组函数中,那么必须出现在group by 子句中。(select中的字段不可以单独出现,必须出现在group语句中或者在组函数中。)
五. 去重是distinct还是group by?
distinct简单来说就是用来去重的,而group by的设计目的则是用来聚合统计的,两者在能够实现的功能上有些相同之处,但应该仔细区分,因为用错场景的话,效率相差可以倍计。
单纯的去重操作使用distinct,速度是快于group by的。
1. distinct
distinct支持单列、多列的去重方式。
单列去重的方式简明易懂,即相同值只保留1个。
多列的去重则是根据指定的去重的列信息来进行,即只有所有指定的列信息都相同,才会被认为是重复的信息。
干巴巴的说不好理解,示例一下:
示例数据表中的数据:
mysql> select * from talk_test;
+----+-------+--------+
| id | name | mobile |
+----+-------+--------+
| 1 | xiao9 | 555555 |
| 2 | xiao6 | 666666 |
| 3 | xiao9 | 888888 |
| 4 | xiao9 | 555555 |
| 5 | xiao6 | 777777 |
+----+-------+--------+
进行单列去重后的结果:
mysql> select distinct(name) from talk_test;
+-------+
| name |
+-------+
| xiao9 |
| xiao6 |
+-------+
2 rows in set (0.01 sec)
mysql> select distinct(mobile) from talk_test;
+--------+
| mobile |
+--------+
| 555555 |
| 666666 |
| 888888 |
| 777777 |
+--------+
**只会保留指定的列的信息
进行多列去重后的结果:
mysql> select distinct name,mobile from talk_test;
+-------+--------+
| name | mobile |
+-------+--------+
| xiao9 | 555555 |
| xiao6 | 666666 |
| xiao9 | 888888 |
| xiao6 | 777777 |
+-------+--------+
**只有所有指定的列信息都相同,才会被认定为重复的信息
group by使用的频率相对较高,但正如其功能一样,它的目的是用来进行聚合统计的,虽然也可能实现去重的功能,但这并不是它的长项。
六. UEditor添加字体
最近工作中遇到一个问题,百度富文本里的字体不够用,还想扩展其他的字体,今天来记录一下:
第一步,修改zh-cn.js 找到fontfamily,添加要添加的字体
'fontfamily':{
'FangSong': '仿宋',
'songti':'宋体',
'heiti':'黑体',
'kaiti':'楷体',
'lishu':'隶书',
'yahei':'微软雅黑',
'arial':'arial',
'arialBlack':'arial black',
'bookAntiqua':'Book Antiqua',
'Calibri':'Calibri',
'comicSansMs':'comic sans ms',
'Courier New':'Courier New',
'Garamond':'Garamond',
'Georgia':'Georgia',
'Helvetica':'Helvetica',
'impact':'impact,chicago',
'Narrow':'Narrow',
'Sans Serif':'Sans Serif',
'Serif':'Serif',
'Symbol':'Symbol',
'Tahoma':'Tahoma',
'timesNewRoman':'times new roman',
'Trebuchet MS':'Trebuchet MS',
'Verdana':'Verdana',
'andaleMono':'andale mono'
},
第二步,修改ueditor.config.js ,找到fontfamily(如果是注释掉的就把注释打开),添加字体信息即可
,'fontfamily':[
{ label:'',name:'FangSong',val:'仿宋,FangSong'},
{ label:'',name:'songti',val:'宋体,SimSun'},
{ label:'',name:'heiti',val:'黑体, SimHei'},
{ label:'',name:'kaiti',val:'楷体,楷体_GB2312, SimKai'},
{ label:'',name:'lishu',val:'隶书, SimLi'},
{ label:'',name:'yahei',val:'微软雅黑,Microsoft YaHei'},
{ label:'',name:'arial',val:'arial, helvetica,sans-serif'},
{ label:'',name:'arialBlack',val:'arial black,avant garde'},//Arial Black
{ label:'',name:'bookAntiqua',val:'Book Antiqua'},//
{ label:'',name:'Calibri',val:'Calibri'},//Calibri
{ label:'',name:'comicSansMs',val:'comic sans ms'},
{ label:'',name:'Courier New',val:'Courier New'},//Courier New
{ label:'',name:'Garamond',val:'Garamond'},//Garamond
{ label:'',name:'Georgia',val:'Georgia'},//Georgia
{ label:'',name:'Helvetica',val:'Helvetica'},//Helvetica
{ label:'',name:'impact',val:'impact,chicago'},
{ label:'',name:'Narrow',val:'Narrow'},//Narrow
{ label:'',name:'Sans Serif',val:'Sans Serif'},//Sans Serif
{ label:'',name:'Serif',val:'Serif'},//Serif
{ label:'',name:'Symbol',val:'Symbol'},//Symbol
{ label:'',name:'Tahoma',val:'Tahoma'},//Tahoma
{ label:'',name:'timesNewRoman',val:'times new roman'},//Times New Roman
{ label:'',name:'Trebuchet MS',val:'Trebuchet MS'},//Trebuchet MS
{ label:'',name:'Verdana',val:'Verdana'},//Verdana
{ label:'',name:'andaleMono',val:'andale mono'}
]
配置完以上两步重新启动项目刷新就可以啦~