Binder驱动
Binder驱动是Android专用的一个驱动程序,保持了和一般Linux驱动一样框架。Binder驱动不涉及任何外设,本质上只操作内存,负责将数据从一个进程传递到另外一个进程。Binder驱动的代码存放在如下几个目录:
kernel/drivers/android
kernel\include\uapi\linux\android
下面介绍Binder驱动中的几个关键函数:
binder_init
static int __init binder_init(void)
{
int ret;
char *device_name, *device_names;
struct binder_device *device;
struct hlist_node *tmp;
atomic_set(&binder_transaction_log.cur, ~0U);
atomic_set(&binder_transaction_log_failed.cur, ~0U);
//1. 创建*binder_deferred_workqueue*
binder_deferred_workqueue = create_singlethread_workqueue("binder");
if (!binder_deferred_workqueue)
return -ENOMEM;
//2. 在debugfs创建一些设备节点用于调试
binder_debugfs_dir_entry_root = debugfs_create_dir("binder", NULL);
if (binder_debugfs_dir_entry_root)
binder_debugfs_dir_entry_proc = debugfs_create_dir("proc",
binder_debugfs_dir_entry_root);
if (binder_debugfs_dir_entry_root) {
debugfs_create_file("state",
S_IRUGO,
binder_debugfs_dir_entry_root,
NULL,
&binder_state_fops);
//...
}
//3. 创建设备节点
device_names = kzalloc(strlen(binder_devices_param) + 1, GFP_KERNEL);
if (!device_names) {
ret = -ENOMEM;
goto err_alloc_device_names_failed;
}
strcpy(device_names, binder_devices_param);
while ((device_name = strsep(&device_names, ","))) {
ret = init_binder_device(device_name);
if (ret)
goto err_init_binder_device_failed;
}
return ret;
}
Binder初始化代码可以分为三个部分:
- 创建binder_deferred_workqueue
- 在debugfs创建一些设备节点用于调试
- 创建设备节点
这里重点分析第三部分代码
static char *binder_devices_param = CONFIG_ANDROID_BINDER_DEVICES;
char *device_name, *device_names;
device_names = kzalloc(strlen(binder_devices_param) + 1, GFP_KERNEL);
if (!device_names) {
ret = -ENOMEM;
goto err_alloc_device_names_failed;
}
strcpy(device_names, binder_devices_param);
while ((device_name = strsep(&device_names, ","))) {
ret = init_binder_device(device_name);
}
CONFIG_ANDROID_BINDER_DEVICES 在kernel配置如下:
CONFIG_ANDROID_BINDER_DEVICES="binder,hwbinder,vndbinder"
上述代码即分别创建了名字为binder,hwbinder,vndbinder的三个设备。我们继续分析init_binder_device这个函数
static int __init init_binder_device(const char *name)
{
int ret;
struct binder_device *binder_device;
binder_device = kzalloc(sizeof(*binder_device), GFP_KERNEL);
if (!binder_device)
return -ENOMEM;
binder_device->miscdev.fops = &binder_fops;
binder_device->miscdev.minor = MISC_DYNAMIC_MINOR;
binder_device->miscdev.name = name;
binder_device->context.binder_context_mgr_uid = INVALID_UID;
binder_device->context.name = name;
mutex_init(&binder_device->context.context_mgr_node_lock);
ret = misc_register(&binder_device->miscdev);
if (ret < 0) {
kfree(binder_device);
return ret;
}
hlist_add_head(&binder_device->hlist, &binder_devices);
return ret;
}
这个函数主要做了下面三件事:
- 初始化binder_device结构
- 使用 misc_register方法向系统注册设备节点。该函数成功调用后即会在/device/binder (/device/vndbinder,/device/hwbinder)下生成设备节点
- binder_device* 加入到binder_devices链表中
binder_fops结构定义了操作binder设备的各个函数的指针:
static const struct file_operations binder_fops = {
.owner = THIS_MODULE,
.poll = binder_poll,
.unlocked_ioctl = binder_ioctl,
.compat_ioctl = binder_ioctl,
.mmap = binder_mmap,
.open = binder_open,
.flush = binder_flush,
.release = binder_release,
};
另外这类需要介绍Binder驱动中的两个数据机构.
- binder_device
struct binder_device {
struct hlist_node hlist;
struct miscdevice miscdev;
struct binder_context context;
};
binder_device代表了一个Binder设备,参考之前的代码 hlist_node 指向Bidner设备在binder_devices链表的节点,miscdevice代表了内核中的一个misc设备,binder_context即当前Binder设备的上下文。
- binder_context
struct binder_context {
struct binder_node *binder_context_mgr_node;
struct mutex context_mgr_node_lock;
kuid_t binder_context_mgr_uid;
const char *name;
};
binder_context用于表示一个binder设备的上下文,这个binder设备的上下文即是我们熟悉的ServiceManager在内核这中的表示。其中
binder_context_mgr_node表示想用的ServiceManager在内核中的Binder节点。其他的数据结构后续在分析后续代码时再做介绍。
binder_open
用户空间要使用Binder设备进行IPC,首先需要使用open系统调用打开Binder设备,此时内核会通过指针调用注册设备时传入的open函数,binder驱动的open函数如下:
static int binder_open(struct inode *nodp, struct file *filp)
{
struct binder_proc *proc;
struct binder_device *binder_dev;
proc = kzalloc(sizeof(*proc), GFP_KERNEL);
//1. 初始化锁
spin_lock_init(&proc->inner_lock);
spin_lock_init(&proc->outer_lock);
get_task_struct(current->group_leader);
//2. 将tsk对象赋值为当前进程的进程描述符
proc->tsk = current->group_leader;
//3. 初始化todo链表
INIT_LIST_HEAD(&proc->todo);
//4. 将进程优先级信息初始化为线程的优先级
if (binder_supported_policy(current->policy)) {
proc->default_priority.sched_policy = current->policy;
proc->default_priority.prio = current->normal_prio;
} else {
proc->default_priority.sched_policy = SCHED_NORMAL;
proc->default_priority.prio = NICE_TO_PRIO(0);
}
binder_dev = container_of(filp->private_data, struct binder_device,
miscdev);
//5. 将上下文指向打开设备的上下文
proc->context = &binder_dev->context;
//6. 初始化alloc
binder_alloc_init(&proc->alloc);
binder_stats_created(BINDER_STAT_PROC);
//7. 将PID设置为当前进程的PID
proc->pid = current->group_leader->pid;
//8. 初始化delivered_death和waiting_threads链表
INIT_LIST_HEAD(&proc->delivered_death);
INIT_LIST_HEAD(&proc->waiting_threads);
//9. 将filp->private_data指向binder_proc
filp->private_data = proc;
mutex_lock(&binder_procs_lock);
//10. 添加到binder_procs双向链表
hlist_add_head(&proc->proc_node, &binder_procs);
mutex_unlock(&binder_procs_lock);
//...
return 0;
}
笼统的讲,这个函数仅完成了一项工作:为打开驱动的进程创建了一个 binder_proc 结构,并将该结构添加到 binder_procs 链表中。binder_proc代表了一个打开了Binder驱动的进程,在binder_open函数中对binder_proc结构的部分成员做了初始化工作:
- 初始化锁
- 将tsk对象赋值为当前进程的进程描述符
- 初始化todo链表
- 将进程优先级信息初始化为线程的优先级
- 将上下文指向打开设备的上下文
- 初始化alloc
- 将PID设置为当前进程的PID
- 初始化delivered_death和waiting_threads链表
其中第6步初始化了binder_alloc对象基本内容:
void binder_alloc_init(struct binder_alloc *alloc)
{
alloc->tsk = current->group_leader;
alloc->pid = current->group_leader->pid;
mutex_init(&alloc->mutex);
INIT_LIST_HEAD(&alloc->buffers);
}
binder_mmap
mmap是一种内存映射文件的方法,即将一个文件或者其它对象映射到进程的地址空间,实现文件磁盘地址和进程虚拟地址空间中一段虚拟地址的一一对映关系。在用户空间使用mmap系统调用,内核会通过设备指针调用相应驱动的mmap函数。而Binder驱动中的mmap实现,实际上是将用户空间的一段虚拟地址和kernel空间的一段虚拟地址映射到同一块物理地址上,以减少IPC过程中数据从用户空间向内核空间的拷贝次数。具体代码如下:
static int binder_mmap(struct file *filp, struct vm_area_struct *vma)
{
int ret;
struct binder_proc *proc = filp->private_data;
//...
vma->vm_flags = (vma->vm_flags | VM_DONTCOPY) & ~VM_MAYWRITE;
vma->vm_ops = &binder_vm_ops;
vma->vm_private_data = proc;
//...
ret = binder_alloc_mmap_handler(&proc->alloc, vma);
//...
proc->files = get_files_struct(current);
return 0;
}
上述代码主要调用了 binder_alloc_mmap_handler,该函数传入的参数为proc->alloc以及vma,类型分别为binder_alloc以及vm_area_struct。在具体分析这个函数之前,先回忆一下之前介绍的基础知识
- 在打开MMU之后,用户空间和内核空间访问内存使用的是虚拟地址,需要通过MMU转换成物理地址后访问
- 通常Kernel将其虚拟地址空间的前896M(3G-3G+896M)映射到物理内存前896M(0-896M)
- Kernel虚拟地址空间后128M不做固定映射,需要时将虚拟地址(以页为单位)映射到任意物理地址
另外有几个内核中的结构体和方法需要介绍一下:
- vm_area_struct
struct vm_area_struct
{
struct mm_struct *vm_mm;
unsigned long vm_start; /*虚拟内存区域起始地址*/
unsigned long vm_end; /*虚拟内存区域结束地址*/
//....
} ;
vm_area_struct表示用户空间的一段虚拟内存区域,其中vm_mm域指向了进程的mm_struct结构体,vm_start和vm_end分别指向这段虚拟地址区域的起始地址和结束地址,其中vm_start即使mmap系统调用所返回的地址。
- vm_struct
struct vm_struct {
struct vm_struct *next; /*指向下一个vm区域*/
void *addr; /*指向第一个内存单元(线性地址)*/
unsigned long size; /*该块内存区的大小*/
//...
};
vm_struct和vm_area_struct类似,表示的是内核空间的一段连续的虚拟内存区域,用于将内核空间后120M地址映射到物理地址,其中addr表示这段虚拟内存区域的起始地址,size表示这段内虚拟存区域的大小。
- get_vm_area
struct vm_struct *get_vm_area(unsigned long size, unsigned long flags)
get_vm_area用于向kernel申请一段虚拟的内存区域,其中size为要申请虚拟区域大小,返回值为vm_struct指针。
- alloc_page
#define alloc_page(gfp_mask) alloc_pages(gfp_mask, 0)
struct page * alloc_pages(unsigned int gfp_mask, unsigned int order)
alloc_page(gfp_mask) 实际调用alloc_pages函数,分配20个页面,并返回一个struct page指针。struct page用于表示一个内存物理页。
- map_kernel_range_noflush
int map_kernel_range_noflush(unsigned long addr, unsigned long size, pgprot_t prot, struct page **pages)
map_kernel_range_noflush用于将内核地址空间的一段地址和一些特定的内存物理页面映射。其中addr参数为内核虚地址的起始地址,size表示这段虚拟地址的大小,port为物理页面的保护标志位,pages指向物理页面的(数组的)指针。
- flush_cache_vmap
flush_cache_vmap和具体的架构相关,map_kernel_range_noflush并不会刷新缓存,flush_cache_vmap通常和其配合使用用于刷新缓存。
- vm_insert_page
int vm_insert_page(struct vm_area_struct *vma, unsigned long addr, struct page *page)
vm_insert_page用于将一个page指针指向的物理页插入到用户虚拟地址空间。其中vma用于描述这段虚拟地址控件,addr用于描述该物理页需要插入的用户空间的虚拟地址。
接下来具体分析binder_alloc_mmap_handler函数的实现:
int binder_alloc_mmap_handler(struct binder_alloc *alloc, struct vm_area_struct *vma)
{
int ret;
struct vm_struct *area;
const char *failure_string;
struct binder_buffer *buffer;
mutex_lock(&binder_alloc_mmap_lock);
/*1*/
area = get_vm_area(vma->vm_end - vma->vm_start, VM_IOREMAP);
/*2*/
alloc->buffer = area->addr;
/*3*/
alloc->user_buffer_offset =
vma->vm_start - (uintptr_t)alloc->buffer;
mutex_unlock(&binder_alloc_mmap_lock);
/*4*/
alloc->pages = kzalloc(sizeof(alloc->pages[0]) *
((vma->vm_end - vma->vm_start) / PAGE_SIZE),
GFP_KERNEL);
alloc->buffer_size = vma->vm_end - vma->vm_start;
/*5*/
buffer = kzalloc(sizeof(*buffer), GFP_KERNEL);
/*6*/
if (__binder_update_page_range(alloc, 1, alloc->buffer,alloc->buffer BINDER_MIN_ALLOC, vma)) {
}
/*7*/
buffer->data = alloc->buffer;
list_add(&buffer->entry, &alloc->buffers);
buffer->free = 1;
/*7*/
binder_insert_free_buffer(alloc, buffer);
alloc->free_async_space = alloc->buffer_size / 2;
barrier();
alloc->vma = vma;
alloc->vma_vm_mm = vma->vm_mm;
return 0;
}
这个函数中需要注意的地方,已经增加标记,解释如下:
- 申请一段内核空间的虚拟地址
- 将这段虚拟地址的首地址复制给alloc->buffer,alloc结构是在binder_open中初始化的
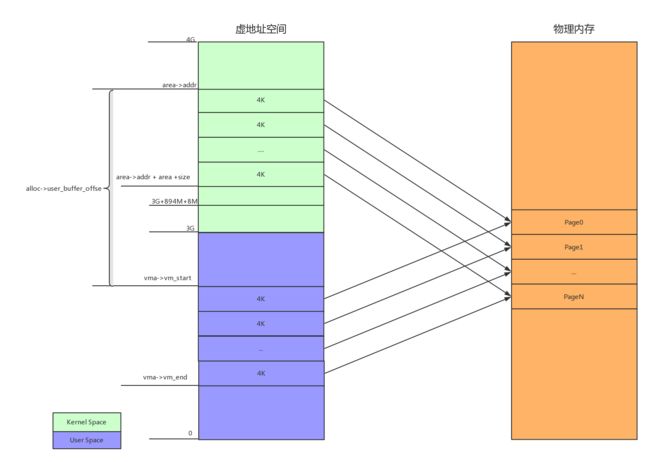
- 计算alloc->user_buffer_offset,vma->vm_start是用户空间的虚拟地址的首地址,alloc->buffer是Kernel空间的首地址,user_buffer_offset为两者的差。计算完成后,vma 和 area这两段虚拟地址空间的任意地址,都可以通过user_buffer_offset进行换算。
- 分配page数组,并计算buffer_size
- 为一个binder_buffer结构体分配内存
- 调用__binder_update_page_range函数,这个函数后续会继续深入介绍
- 初始化这个binder_buffer,data指向申请的内核虚拟地址段的首地址,并添加大量alloc->buffers数组,free置为1
- 调用binder_insert_free_buffer函数,将buffer结构插入到alloc->free_buffers这颗红黑树种,便于
继续分析__binder_update_page_range函数,主要代码如下:
static int __binder_update_page_range(struct binder_alloc *alloc, int allocate,
void *start, void *end,
struct vm_area_struct *vma)
{
void *page_addr;
unsigned long user_page_addr;
struct page **page;
struct mm_struct *mm;
for (page_addr = start; page_addr < end; page_addr += PAGE_SIZE) {
int ret;
page = &alloc->pages[(page_addr - alloc->buffer) / PAGE_SIZE];
/*1*/
*page = alloc_page(GFP_KERNEL | __GFP_HIGHMEM | __GFP_ZERO);
/*2*/
ret = map_kernel_range_noflush((unsigned long)page_addr,
PAGE_SIZE, PAGE_KERNEL, page);
flush_cache_vmap((unsigned long)page_addr,
(unsigned long)page_addr + PAGE_SIZE);
/*3*/
user_page_addr =
(uintptr_t)page_addr + alloc->user_buffer_offset;
ret = vm_insert_page(vma, user_page_addr, page[0]);
}
return 0;
}
这段代码主要逻辑位于for循环中,循环中需要注意的地方已通过注释标注,解释如下:
- 申请一个物理页面,并将返回的struct page结构体指针,存入到alloc->pages数组中
- 映射page_addr指向的内核虚拟地址控件和申请的物理页面
- 将申请的物理页面插入到对应的用户空间虚拟地址
for循环首先将page_addr初始化为start,每次增加一个PAGE_SIZE,page_addr >=end结束。实际的效果就是将start - end这段内核虚地址空间以及对应的用户虚地址控件,映射到同一组物理页面上。这样在用户空间和内核空间都可以通过自己的虚地址访问相同的物理内存。映射的结果入下图所示: