在github看到这个文章写的不错,就转载了,大家一起学习:
https://github.com/keithyin/mynotes/tree/master/MachineLearning/algorithms
——————————————————————————————————————————
该作者也推荐了下面一个系列的文章,也写的不错:
- Variational inference
- KL(q∥p) minimization-1
- KL(p∥q) minimization-2
- VAE variation inference变分推理 清爽介绍
——————————————————————————————————————————

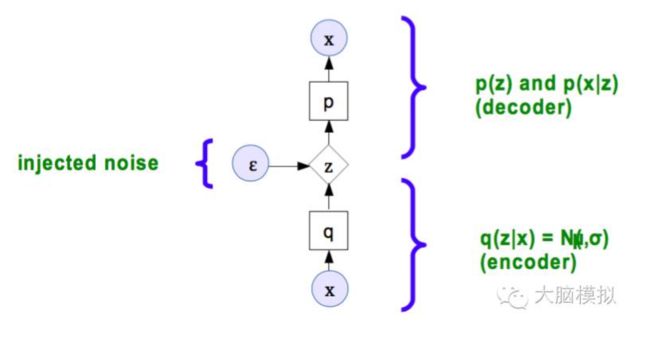 Variational Auto-Encoder
Variational Auto-Encoder
大家对贝叶斯公式应该都很熟悉
我们称为posterior distribution。posterior distribution的计算通常是非常困难的,为什么呢?
假设是一个高维的随机变量,如果要求,我们不可避免的要计算,由于是高维随机变量,这个积分是相当难算的。
variational inference就是用来计算posterior distribution的。
core idea
variational inference的核心思想包含两步:
- 假设分布 (这个分布是我们搞得定的,搞不定的就没意义了)
- 通过改变分布的参数 , 使 靠近
总结称一句话就是,为真实的后验分布引入了一个参数话的模型。 即:用一个简单的分布 拟合复杂的分布 。
这种策略将计算 的问题转化成优化问题了
收敛后,就可以用 来代替 了
公式推导
等式的两边同时对分布求期望,得
我们的目标是使 靠近 ,就是
由于 中包含 ,这项非常难求。将看做变量时, 为常量,所以, 等价于 。
称为Evidence Lower Bound(ELBO)。
现在,variational inference的目标变成
为什么称之为ELBO呢?
一般被称之为evidence,又因为 , 所以 , 这就是为什么被称为ELBO。
ELBO
继续看一下ELBO
The first term represents an energy. The energy encourages to focus probability mass where the model puts high probability . The entropy encourages to spread probability mass to avoid concentrating to one location.
包含K个独立部分(K 维, 当然,第i维也可能是高维向量),我们假设:
这个被称为mean field approximation。(关于mean field approximationhttps://metacademy.org/graphs/concepts/mean_field)
ELBO则变成
第一项为 energy, 第二项为H(q)
energy
符号的含义:
先处理第一项:
其中 , 保证 是一个分布。 与分布的参数 有关,与变量无关!!
H(q)
再处理第二项:
再看ELBO
经过上面的处理,ELBO变为
再看上式 中的项:
所以ELBO又可以写成:
我们要,如何更新 呢?
从
可以看出,当 时, 。 这时,ELBO取最大值。
所以参数更新策略就变成了
关于
是要更新的节点, 是观测的数据,由于 Markov Blanket(下面介绍),更新公式变成:
由于式子中和 无关的项都被积分积掉了,所以写成了 Markov Blanket 这种形式
Markov Blanket
In machine learning, the Markov blanket for a node in a Bayesian network is the set of nodes composed of parents, its children, and its children's other parents. In a Markov random field, the Markov blanket of a node is its set of neighboring nodes.
Every set of nodes in the network is conditionally independent of when conditioned on the set , that is, when conditioned on the Markov blanket of the node . The probability has the Markov property; formally, for distinct nodes and :
The Markov blanket of a node contains all the variables that shield the node from the rest of the network. This means that the Markov blanket of a node is the only knowledge needed to predict the behavior of that node.
参考资料
https://en.wikipedia.org/wiki/Markov_blanket
http://edwardlib.org/tutorials/inference
http://edwardlib.org/tutorials/variational-inference