深度学习框架落地 | 量化网络的重要性(附源码地址下载)

欢迎关注“
计算机视觉研究院
”

计算机视觉研究院专栏
作者:Edison_G

计算机视觉研究院
长按扫描二维码
回复“量化”,获取下载链接
深度学习在移动端的应用是越来越广泛,由于移动端的运算力与服务器相比还是有差距,所以在移动端部署深度学习模型的难点就在于如何保证模型效果的同时,运行效率也有保证。
在实验阶段对于模型结构可以选择大模型,因为该阶段主要是为了验证方法的有效性。在验证完了之后,开始着手部署到移动端,这时候就要精简模型的结构了,一般是对训好的大模型进行剪枝,或者参考现有的比如MobileNetV2和ShuffleNetV2等轻量级的网络重新设计自己的网络模块。而算法层面的优化除了剪枝还有量化,量化就是把浮点数(高精度)表示的权值和激活值用更低精度的整数来近似表示。低精度的优点有,相比于高精度算术运算,其在单位时间内能处理更多的数据,而且权值量化之后模型的存储空间能进一步的减少等等。
超越MobileNetV3的轻量级网络(文末论文下载)
对训练好的网络做量化,在实践中尝试过TensorRT的后训练量化算法,效果还不错。但是如果能在训练过程中去模拟量化的过程,让网络学习去修正量化带来的误差,那么得到的量化参数应该是更准确的,而且在实际量化推断中模型的性能损失应该能更小。
近年来,定点量化使用更少的比特数(如8-bit、3-bit、2-bit等)表示神经网络的权重和激活已被验证是有效的。定点量化的优点包括低内存带宽、低功耗、低计算资源占用以及低模型存储需求等。
低精度定点数操作的硬件面积大小及能耗比高精度浮点数要少几个数量级。使用定点量化可带来4倍的模型压缩、4倍的内存带宽提升,以及更高效的cache利用(很多硬件设备,内存访问是主要能耗)。除此之外,计算速度也会更快(通常具有2x-3x的性能提升)。由表2可知,在很多场景下,定点量化操作对精度并不会造成损失。另外,定点量化对神经网络于嵌入式设备上的推断来说是极其重要的。
目前,学术界主要将量化分为两大类:Post Training Quantization和Quantization Aware Training。Post Training Quantization是指使用KL散度、滑动平均等方法确定量化参数且不需要重新训练的定点量化方法。Quantization Aware Training是在训练过程中对量化进行建模以确定量化参数,它与Post Training Quantization模式相比可以提供更高的预测精度。本文主要针对Quantization Aware Training量化模式进行阐述说明。
训练模拟量化
方法介绍
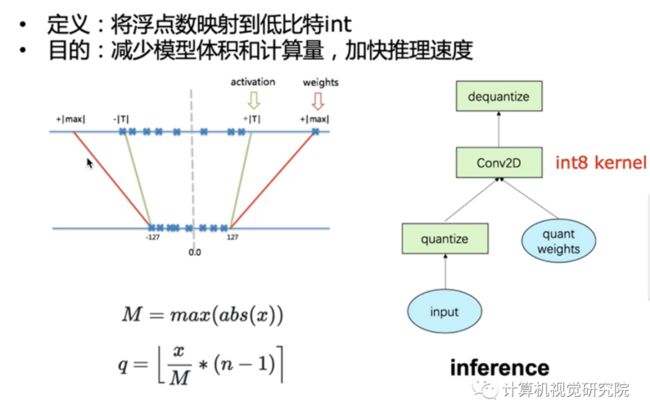
首先来看下量化的具体定义,对于量化激活值到有符号8bit整数,论文中给出的定义如下:

公式中的三角形表示量化的缩放因子,x表示浮点数激活值,首先通过除以缩放因子然后最近邻取整,然后把范围限制到一个区间内,比如量化到有符号8bit,那么范围就是 [-128, 127]。而对于权值还有一个小的技巧,就是量化到[-127, 127]:
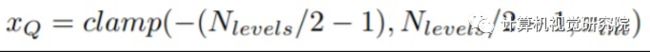
具体为什么这么做,论文中说了是为了实现上的优化,具体解释可以看论文[Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference]附录B ARM NEON details这一小节。而训练量化说白了就是在forward阶段去模拟量化这个过程,本质就是把权值和激活值量化到8bit再反量化回有误差的32bit,所以训练还是浮点,backward阶段是对模拟量化之后权值的求梯度,然后用这个梯度去更新量化前的权值。然后在下个batch继续这个过程,通过这样子能够让网络学会去修正量化带来的误差。

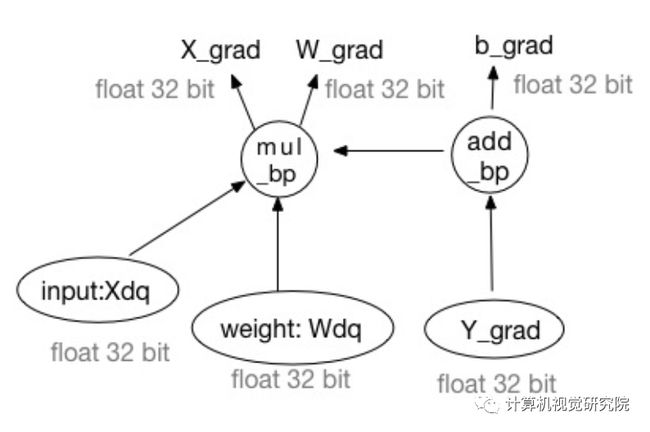
上面给这个示意图就很直观的表示了模拟量化的过程,比如上面那条线表示的是量化前的范围[rmin, rmax],然后下面那条线表示的就是量化之后的范围[-128, 127],比如现在要进行模拟量化的forward,先看上面那条线从左到右数第4个圆点,通过除以缩放因子之后就会映射124到125之间的一个浮点数,然后通过最近邻取整就取到了125,再通过乘以缩放因子返回上面第五个圆点,最后就用这个有误差的数替换原来的去forward。forward阶段的模拟量化用公式表示如下:
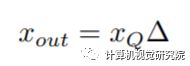
backward阶段求梯度的公式表示如下:

对于缩放因子的计算,权值和激活值的不一样,权值的计算方法是每次forward直接对权值求绝对值取最大值,然后缩放因子 weight scale = max(abs(weight)) / 127。然后对于激活值,稍微有些不一样,激活值的量化范围不是简单的计算最大值,而是通过EMA(exponential moving averages)在训练中去统计这个量化范围,更新公式如下:
moving_max = moving_max * momenta + max(abs(activation)) * (1- momenta)
公式中的activation表示每个batch的激活值,而论文中说momenta取接近1的数就行了,在实验中是取0.95。然后缩放因子 activation scale = moving_max /128。
量化训练时怎么进行反向传播
如下图所示,经过quantize和dequantize后得到的是有误差的浮点数,所以训练还是针对浮点,反向传播过程中的所有输入和输出均为浮点型数据。梯度更新时,计算出的梯度将被加到原始权重上而非量化后或反量化后的权重上。
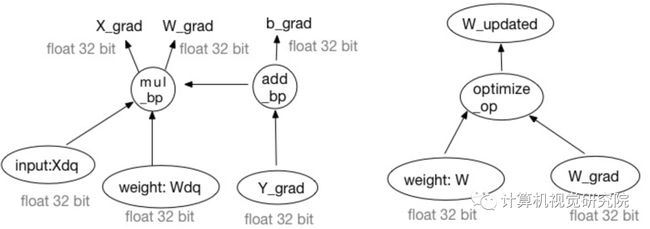
左图是Backward Pass,右图是Weight Updating
对称量化与非对称量化
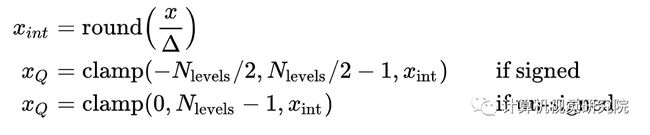
非对称量化将浮点数范围内的最小/最大值映射为整数范围内的最小/最大值。这是通过使用零点(也称为量化偏差,或偏移)来实现的。需要注意的是bias的需要是整型,因为在深度学习的模型中,有太多的0-padding存在了,若是bias非整型,那么在量化过程中会有大量的数值0的精度收到损失。
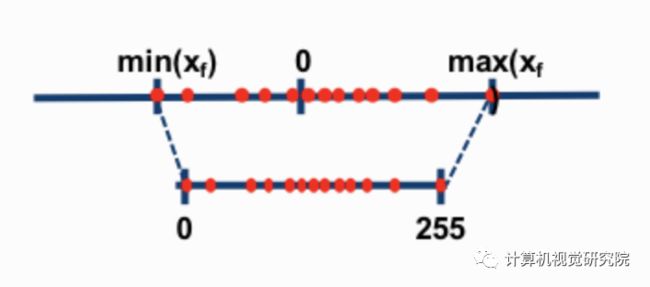
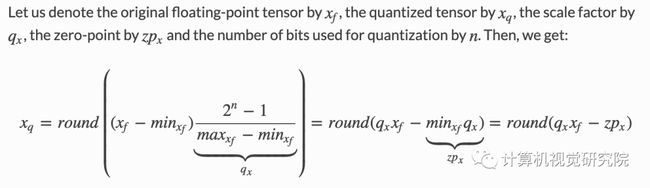
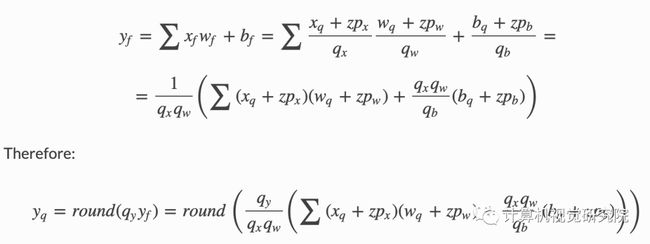
对称量化在最大或最小值间选择最大的绝对值作为量化范围,不设置零点,量化的浮点范围关于原点对称。
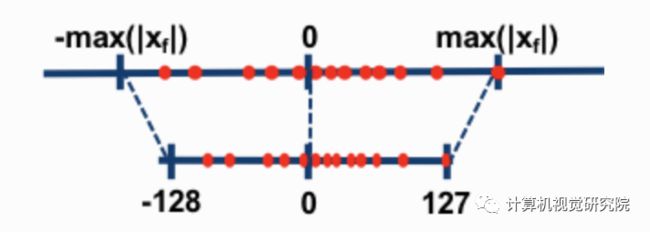
对称量化的范围选择有full range和restricted range两种,论文上说restricted range精度会更低一些。PyTorch(v1.3)和ONNX用的是full range,TensorFlow、 NVIDIA TensorRT 和Intel DNNL (aka MKL-DNN)用的是restricted range。
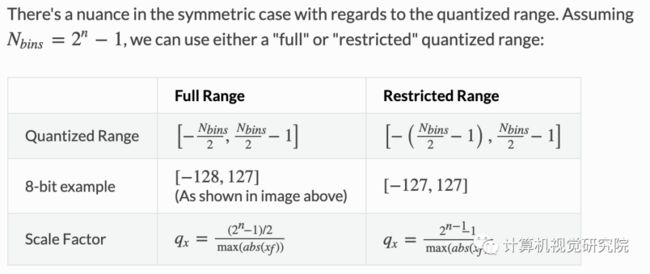
这两种模式的选择主要是做简单性和量化范围利用率之间的trade off。当使用非对称量化时,量化范围被充分利用,浮点数的min、max直接映射到量化范围的min、max;当使用对称量化时,如果浮点数分布偏向零点一侧,会造成量化范围利用率降低(如ReLU,相当于有效位减少了1bit)。另一方面来看,非对称量化要引入零点增加复杂度。
逐层量化和逐通道量化
某些层的权重参数不同通道之间的数据方差很大,利用常见的per-layer量化策略(即整个层的参数作为一个tensor进行量化),则会使得值较小的通道直接全部被置为0,导致精度的下降,per-channel的方法可以解决这个问题,但是在硬件实现上因为要针对每一个通道都有自己独立的缩放系数和偏移值考虑,会导致很多额外的开销,所以目前TensorRT和Tensorflow等都采用的是per-layer。
add和concat怎么量化?
量化的add相比float计算开销更expensive,需要将一组input基于另一组input先rescale,公式为 。
concat支持和add一样的rescale方法来实现,但uint8的rescale是一个有损的操作,tensorflow采用重新统计concat op的input、output,采用input、output统一min、max的方式可以实现无损,代码如下:
bool HardcodeMinMaxForConcatenation(Model* model, Operator* op) {
// Do not early return if the output already has min/max:
// we may still need to adjust the inputs min/max.
bool has_minmax = false;
double overall_min = std::numeric_limits::infinity();
double overall_max = -std::numeric_limits::infinity();
for (const auto& input : op->inputs) {
if (model->GetArray(input).minmax) {
has_minmax = true;
const auto* minmax = model->GetArray(input).minmax.get();
if (minmax) {
overall_min = std::min(overall_min, minmax->min);
overall_max = std::max(overall_max, minmax->max);
}
}
}
auto& output = model->GetArray(op->outputs[0]);
if (output.minmax) {
has_minmax = true;
const auto* minmax = model->GetArray(op->outputs[0]).minmax.get();
if (minmax) {
overall_min = std::min(overall_min, minmax->min);
overall_max = std::max(overall_max, minmax->max);
}
}
if (!has_minmax) {
return false;
}
MinMax overall_minmax;
overall_minmax.min = overall_min;
overall_minmax.max = overall_max;
bool changed = false;
for (const auto& input : op->inputs) {
auto& array = model->GetArray(input);
if (!array.minmax) {
changed = true;
} else if (!(overall_minmax == array.GetMinMax())) {
changed = true;
LOG(WARNING)
<< "Tweaking the MinMax of array " << input << ", which is "
<< "an input to " << LogName(*op) << ", because we want all inputs "
<< "and outputs of a Concatenation operator to have the same MinMax "
<< "so that it can be implemented as a pure byte-copy, no "
"arithmetic.";
}
array.GetOrCreateMinMax() = overall_minmax;
}
if (!output.minmax) {
changed = true;
} else if (!(overall_minmax == output.GetMinMax())) {
changed = true;
LOG(WARNING)
<< "Tweaking the MinMax of the output array of " << LogName(*op)
<< ", because we want all inputs "
<< "and outputs of a Concatenation operator to have the same MinMax "
<< "so that it can be implemented as a pure byte-copy, no arithmetic.";
}
output.GetOrCreateMinMax() = overall_minmax;
return changed;
}
量化范围的选取
量化分为weight和activation的量化。
weight量化范围通过每次forward时,对weight的绝对值取最大值得到。
activation量化范围用EMA算法平滑,可以避免一些极端激活值情况带来的参数分布影响,公式如下 :
为每个batch的激活值, 为接近1的值,可取0.9。

今天就先到这里,下一期我们给大家带来量化训练以及卷积核剪裁原理。
© THE END
我们开创“计算机视觉协会”知识星球一年有余,也得到很多同学的认可,我们定时会推送实践型内容与大家分享,在星球里的同学可以随时提问,随时提需求,我们都会及时给予回复及给出对应的答复。

如果想加入我们“计算机视觉研究院”,请扫二维码加入我们。我们会按照你的需求将你拉入对应的学习群!
计算机视觉研究院主要涉及深度学习领域,主要致力于人脸检测、人脸识别,多目标检测、目标跟踪、图像分割等研究方向。研究院接下来会不断分享最新的论文算法新框架,我们这次改革不同点就是,我们要着重”研究“。之后我们会针对相应领域分享实践过程,让大家真正体会摆脱理论的真实场景,培养爱动手编程爱动脑思考的习惯!

计算机视觉研究院
长按扫描二维码
回复“量化”,获取下载链接