使用 TensorFlow Quantum 训练多个 Worker


发布人:Google 团队 Cheng Xing 和 Michael Broughton
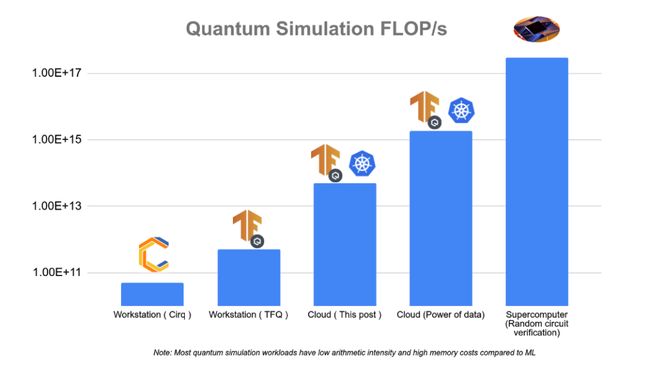
训练大型机器学习模型是 TensorFlow 的核心能力。多年来,训练规模已成为 NLP、图像识别和药物研发等众多现代机器学习系统的重要特征。利用多台机器来提高计算能力和吞吐量为机器学习领域带来巨大进步。同样,在量子计算和量子机器学习领域,更多可用的机器资源可以加速对更大的量子态和更加复杂系统的模拟。在本文中,我们将逐步带您了解如何使用 TensorFlow 和 TensorFlow Quantum 进行大规模和分布式的 QML 模拟。以更大的 FLOP/s 计数运行规模更大的模拟,可以为研究工作带来小规模模拟无法实现的全新可能性。在下方的图表中,我们大致描绘了量子模拟中几种不同硬件设置的近似扩缩能力。
运行分布式工作负载时基础架构往往都很复杂,不过我们可以用 Kubernetes 来简化这一过程。Kubernetes 是一个开源的容器编排系统,同样也是能够有效管理大规模工作负载的可靠平台。尽管我们可以用物理集群或虚拟机集群来设置多个 worker ,但 Kubernetes 能够提供出诸多优势,其中包括:
-
服务发现 - Worker 可以通过熟知的 DNS 名称轻松识别其他 worker,无需手动配置 IP 目的地。
-
自动装箱 - Kubernetes 会根据资源需求和当前的消耗量,将工作负载自动调度到不同的机器上。
-
自动发布和回滚 - Kubernetes 会通过更改配置来改变 worker 副本的数量,同时还会在响应和调度可用的机器时自动添加/删除 worker 资源。
本教程将指导您使用 Google Cloud 产品(包括 Kubernetes 托管平台 Google Kubernetes Engine)来完成 TensorFlow Quantum 多个 worker 设置。您将有机会学习 TensorFlow Quantum 中的单 worker 量子卷积神经网络 (QCNN) 教程,并将其拓展到多 worker 的训练中。
-
Google Kubernetes Engine
https://cloud.google.com/kubernetes-engine
-
量子卷积神经网络 (QCNN) 教程
https://tensorflow.google.cn/quantum/tutorials/qcnn
从我们对多 worker 设置的实验来看,如果我们用 1000 个训练示例训练 23 量子位的 QCNN(相当于使用全状态向量模拟大约 3000 个电路),在 32 个节点 (512 vCPU) 的集群上平均每个周期会花费 5 分钟,这一过程需要花费数美元。相比之下,如果我们在单 worker 上完成同样的训练作业,平均每个周期会花费约 4 小时。将规模进一步扩大来看,数十万个 30 量子位的电路可以使用超过 10000 个虚拟 CPU 在数小时内完成运行,而在单 worker 设置下运行则可能需要花费数周时间。实际性能和成本可能会因虚拟机机器类型和集群总运行时等 Cloud 设置而异。在进行大规模实验之前,我们建议您先通过类似本教程中用到的小集群进行实验。
本教程的所有源代码均可在 TensorFlow Quantum GitHub 代码库中找到。README.md 中包含能够让您快速上手并运行本教程的便捷方法。本教程将侧重于详细介绍每个操作步骤,从而帮助您理解基本概念,并将这些概念集成到您的项目中。现在就开始吧!
-
TensorFlow Quantum
https://github.com/tensorflow/quantum/tree/research/qcnn_multiworker
想获取更多 TensorFlow 官方资讯,请在微信中搜索:TensorFlow_official
关注 TensorFlow 官方微信!
在 Google Cloud 中设置基础架构
首先我们需要在 Google Cloud 中创建基础架构资源。如果您有现有的 Google Cloud 环境,则具体操作步骤可能会有所不同,例如组织政策限制条件导致的不同。本文包括一些最常见的必要步骤。值得注意的是,您需要为创建的 Google Cloud 资源付费,点击此处了解本教程中使用的计费资源摘要。如果您是 Google Cloud 新用户,那么您可以获得 300 美元赠金。如果您是学术机构成员,那么您可以获得 Google Cloud 研究赠金。
在本教程中,您将会运行数个 shell 命令。为此,您可以使用计算机上的本地 Unix shell,也可以使用 Cloud Shell,后者包含我们会在后面提到的许多工具。
-
Cloud Shell
https://cloud.google.com/shell/docs/using-cloud-shell
您可以利用 setup.sh 中的脚本自动实现以下步骤。在本节中,我们将为大家详细介绍每个步骤,如果这是您第一次使用 Google Cloud,我们建议您仔细阅读整个章节。如果您希望自动化 Google Cloud 设置过程,请跳过本章节:
-
打开
setup.sh并配置其中的参数值。 -
运行
./setup.sh infra。
-
setup.sh
https://github.com/tensorflow/quantum/blob/2a24b979467445f6d8e7156796f34ce81af147fa/qcnn_multiworker/setup.sh
在本教程中,您将会用到以下几个 Google Cloud 产品
-
Kubernetes Engine (GKE)。这是本教程中主要负责执行 QCNN 作业的基础架构平台。
-
Cloud Storage,用于存储来自 QCNN 作业的数据。
-
Container Registry,用于存储容器镜像。
为准备好 Cloud 环境,请首先遵循以下快速入门指南:
-
Container Registry 快速入门
https://cloud.google.com/container-registry/docs/quickstart
-
Kubernetes Engine 快速入门
https://cloud.google.com/kubernetes-engine/docs/quickstart
在本教程中,您可以在浏览到创建集群的说明时停止阅读 Kubernetes Engine 快速入门。此外,请安装 Cloud Storage 命令行工具 gsutil(如果您使用的是 Cloud Shell,则系统已安装好 gsutil):
gcloud components install gsutil作为参考信息,本教程中的 shell 命令将会引用以下这些变量。部分变量在结合本教程之后会提到的每个命令的上下文后,会更容易理解。
-
${CLUSTER_NAME:您在 Google Kubernetes Engine 上的首选 Kubernetes 集群名称。 -
${PROJECT}:您的 Google Cloud 项目 ID。 -
${NUM_NODES}:集群中虚拟机的数量。 -
${MACHINE_TYPE}:虚拟机的机器类型。该变量可控制每个虚拟机中 CPU 和内存资源的数量。 -
${SERVICE_ACCOUNT_NAME}:Google Cloud IAM 服务帐号和关联的 Kubernetes 服务帐号的名称。 -
${ZONE}:Kubernetes 集群的 Google Cloud 区域 -
${BUCKET_REGION}:Google Cloud Storage 存储分区的 Google Cloud 地区。 -
${BUCKET_NAME}:用于存储训练输出的 Google Cloud Storage 存储分区的名称。
为确保您拥有运行本教程其余章节的 Cloud 操作的权限,请确保您拥有 owner 的 IAM 角色或以下所有角色:
-
container.admin -
iam.serviceAccountAdmin -
Storage.admin -
IAM 角色
https://cloud.google.com/iam/docs/understanding-roles
如要查看您的角色,请运行以下命令:
gcloud projects get-iam-policy ${PROJECT}并加上您的 Google Cloud 项目 ID,然后搜索您的用户帐号。
在您完成快速入门指南后,请运行以下命令创建 Kubernetes 集群:
gcloud container clusters create ${CLUSTER_NAME} --workload-pool=${PROJECT}.svc.id.goog --num-nodes=${NUM_NODES} --machine-type=${MACHINE_TYPE} --zone=${ZONE} --preemptible
并加上您的 Google Cloud 项目 ID 和首选的集群名称。
--num-nodes 为支持 Kubernetes 集群的 Compute Engine 虚拟机的数量。这不必与您希望 QCNN 作业拥有的 worker 副本数量相同,因为 Kubernetes 能够在同一节点上调度多个副本,不过前提是该节点有足够的 CPU 和内存资源。如果您是首次尝试本教程,我们建议您使用 2 个节点。
--machine-type 可指定虚拟机的机器类型。如果您是首次尝试本教程,我们建议您使用具备 2 个 vCPU 和 7.5GB 内存的“n1-standard-2”。
-
机器类型
https://cloud.google.com/compute/docs/machine-types
--zone 是您希望集群运行所处的 Google Cloud 区域(例如“us-west1-a”)。
--workload-pool 可以启用 GKE Workload Identity 功能,从而将 Kubernetes 服务帐号和 Google Cloud IAM 服务帐号关联在一起。为实现精细访问权限控制,建议您使用 IAM 服务帐号来访问各种 Google Cloud 产品。在此您将可以创建一个用于 QCNN 作业的服务帐号。Kubernetes 服务帐号是一种机制,可以将 IAM 服务帐号的凭据注入 worker 容器中。
-
Workload Identity
https://cloud.google.com/kubernetes-engine/docs/how-to/workload-identity
-
Google Cloud IAM 服务帐号
https://cloud.google.com/iam/docs/service-accounts
--preemptible 使用 Compute Engine 抢占式虚拟机来支持 Kubernetes 集群。与普通的虚拟机相比,抢占式虚拟机在成本上降低了 80%,不过其代价是虚拟机随时都可能会被抢占,进而导致训练过程终止。这种虚拟机非常适合在短时间内训练大量集群。
然后您可以创建一个 IAM 服务帐号:
gcloud iam service-accounts create ${SERVICE_ACCOUNT_NAME}
并将其与 Workload Identity 集成:
gcloud iam service-accounts add-iam-policy-binding --role roles/iam.workloadIdentityUser --member "serviceAccount:${PROJECT}.svc.id.goog[default/${SERVICE_ACCOUNT_NAME}]" ${SERVICE_ACCOUNT_NAME}@${PROJECT}.iam.gserviceaccount.com现在创建一个存储分区,这是存储数据的基本容器:
gsutil mb -p ${PROJECT} -l ${BUCKET_REGION} -b on gs://${BUCKET_NAME}并使用您首选的存储分区名称。存储分区名称为全局唯一,因此我们建议您在存储分区名称中加入项目名称。我们建议您将存储分区地区设为包含您集群区域的地区。区域的地区,即区域名称去掉最后一个连字符之后的部分。例如,区域“us-west1-a”的地区为“us-west1”。
要让 QCNN 作业能够访问 Cloud Storage 数据,请为您的 IAM 服务帐号授予相应权限:
gsutil iam ch serviceAccount:${SERVICE_ACCOUNT_NAME}@${PROJECT}.iam.gserviceaccount.com:roles/storage.admin gs://${BUCKET_NAME}
准备 Kubernetes 集群
设置好 Cloud 环境后,现在您可以将必要的 Kubernetes 工具安装到集群中。您需要 KubeFlow 中的 tf-operator 组件。KubeFlow 是用于在 Kubernetes 上运行机器学习工作负载的工具包,子组件 tf-operator 可简化 TensorFlow 作业的管理。tf-operator 可以单独进行安装,无需安装规模更大的 KubeFlow。
-
tf-operator
https://github.com/kubeflow/tf-operator
如要安装 tf-operator ,请运行以下命令:
docker pull k8s.gcr.io/kustomize/kustomize:v3.10.0
docker run k8s.gcr.io/kustomize/kustomize:v3.10.0 build "github.com/kubeflow/tf-operator.git/manifests/overlays/standalone?ref=v1.1.0" | kubectl apply -f -
(注意 tf-operator 会使用 Kustomize 来管理其部署文件,所以在此我们也需要安装 Kustomize)
使用 MultiWorkerMirroredStrategy
进行训练
现在您可以使用 TensorFlow Quantum 研究分支中的 QCNN 代码,并将其准备好,以便以分布式方式运行这些代码。首先复制源代码:
git clone https://github.com/tensorflow/quantum.git && cd quantum && git checkout origin/research && cd qcnn_multiworker或者,如果您使用的是向 GitHub 进行身份验证的 SSH 密钥:
git clone [email protected]:tensorflow/quantum.git && cd quantum && git checkout origin/research && cd qcnn_multiworker-
向 GitHub 进行身份验证的 SSH 密钥
https://docs.github.com/en/github/getting-started-with-github/quickstart/set-up-git#next-steps-authenticating-with-github-from-git
代码设置
training 目录中包含执行 QCNN 分布式训练的必备组件。training/qcnn.py 和 common/qcnn_common.py 的组合与 TensorFlow Quantum 中的混合 QCNN 示例相同,但在功能上有所增加:
-
借助
tf.distribute.MultiWorkerMirroredStrategy,您现在可以选择利用多台机器进行训练。 -
TensorBoard 集成,我们将在下一节中详细为您讲解。
-
TensorBoard
https://tensorflow.google.cn/tensorboard
MultiWorkerMirroredStrategy 是一种可执行同步分布式训练的 TensorFlow 机制。我们在您的现有模型中增加了几行代码,以便针对分布式训练进行增强。
-
MultiWorkerMirroredStrategy
https://tensorflow.google.cn/guide/distributed_training#multiworkermirroredstrategy
在 training/qcnn.py 文件的开头,我们对 MultiWorkerMirroredStrategy 进行设置:
strategy = tf.distribute.MultiWorkerMirroredStrategy()-
training/qcnn.py
https://github.com/tensorflow/quantum/blob/2a24b979467445f6d8e7156796f34ce81af147fa/qcnn_multiworker/training/qcnn.py
然后在模型准备阶段,我们将此策略以参数的形式传入:
... = qcnn_common.prepare_model(strategy)
每个 QCNN 分布式训练作业的 worker 都会运行以上 Python 代码的副本。每个 worker 都需要知道其他所有 worker 的网络端点。通常,我们会将 TF_CONFIG 环境变量用于此目的。但在本例中,tf-operator 会自动在后台将变量注入。
模型训练完成后,权重会上传至您的 Cloud Storage 存储分区,随后推理作业会对其进行访问。
if task_type == 'worker' and task_id == 0:
qcnn_weights_path='/tmp/qcnn_weights.h5'
qcnn_model.save_weights(qcnn_weights_path)
upload_blob(args.weights_gcs_bucket, qcnn_weights_path, f'qcnn_weights.h5')Kubernetes 部署设置
在继续完成 Kubernetes 部署设置和启动 worker 之前,您需要针对您自己的设置在教程源代码中配置几个参数。此处提供的脚本 setup.sh 可以用于简化该过程。
-
setup.sh
https://github.com/tensorflow/quantum/blob/2a24b979467445f6d8e7156796f34ce81af147fa/qcnn_multiworker/setup.sh
如果您在之前的步骤中尚未完成此操作,请打开 setup.sh 并配置其中的参数值。然后运行以下命令:
./setup.sh param至此,本节剩余的步骤可通过以下这行命令来执行:
make training我们将在本节剩余部分中为您详细讲解 Kubernetes 的设置过程。
首先我们需要用 Docker 将 QCNN 作业包装为容器映像,并将其上传至 Container Registry,然后才能在 Kubernetes 中以容器的形式运行作业。Dockerfile 中包含映像规范。如要构建和上传映像,请运行以下命令:
docker build -t gcr.io/${PROJECT}/qcnn .
docker push gcr.io/${PROJECT}/qcnn
接下来,您将通过 common/sa.yaml 创建 Kubernetes 服务帐号,从而完成 Workload Identity 设置。该服务帐号将会由 QCNN 容器使用。
apiVersion: v1
kind: ServiceAccount
metadata:
annotations:
iam.gke.io/gcp-service-account: ${SERVICE_ACCOUNT_NAME}@${PROJECT}.iam.gserviceaccount.com
name: ${SERVICE_ACCOUNT_NAME}
该注释会向 GKE 表明,此 Kubernetes 服务帐号应与您之前创建的 IAM 服务帐号绑定。我们首先创建服务帐号:
kubectl apply -f common/sa.yaml
最后一步便是创建分布式训练作业。 ttraining/qcnn.yaml 中包含 Kubernetes 作业规范。在 Kubernetes 中,我们会将多个具有相关函数的容器分组成名为 pod 的单一实体,这是您可以进行调度的最基础的工作单元。通常来说,用户会利用 Deployment 和 Job 等现有资源类型来创建和管理工作负载。而您将改为使用 TFJob (该信息在“kind”字段中指定),这不是 Kubernetes 内置的资源类型,而是由 tf-operator 提供的自定义资源,可用于轻松处理 TensorFlow 工作负载。
值得注意的是,TFJob 规范中包含 tfReplicaSpecs.Worker 字段,您可通过该字段配置 MultiWorkerMirroredStrategy worker。PS(参数服务器)、Chief 和 Evaluator 的值同样也支持异步和其他形式的分布式训练。 tf-operator 会在后台为每个 worker 副本创建两个 Kubernetes 资源:
-
一个是使用
tfReplicaSpecs.Worker.template中 pod 规范模板的 pod 对象。该资源可运行您之前在 Kubernetes 上创建的容器。 -
另一个是 Service 对象,它能够在 Kubernetes 集群中公开显示已知的网络端点,从而授予对 worker gRPC 训练服务器的访问权限。其他 worker 可以仅通过指向
: . .svc:
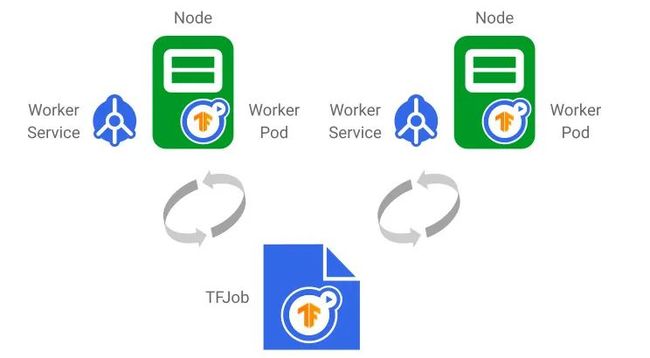
TFJob 会为每个 worker 副本生成一个 Service 和一个 pod。TFJob 更新后,相应的更改将反映在底层 Service 和 pod 中。Worker 状态也会在 TFJob 中报告显示
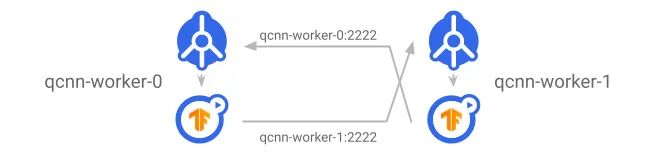
Service 会向集群的其余部分公开 worker 服务器。每个 worker 在与其他 worker 通信时都会使用目标 worker 的 Service 名称作为 DNS 名称
Worker 规范中有几个重要的字段:
Replicas:worker 副本的数量。我们可以在同一节点上调度多个副本,因此副本的数量不会受到节点数量的限制。
-
Template:每个 worker 副本的 pod 规范模板
serviceAccountName:该字段可为 pod 提供访问 Kubernetes 服务帐号的权限。
container:
image:指向您之前构建的 Container Registry 映像。
command:容器的入口点命令。
arg:命令行参数。
Ports:开放两个端口,其中一个用于 worker 间互相通信,另一个用于分析用途。
affinity:该字段会向 Kubernetes 表明,您希望在不同的节点上尽可能多地调度 worker pod,以最大限度地利用资源。
如要创建 TFJob,请运行以下命令:
kubectl apply -f training/qcnn.yaml检查部署
恭喜!您的分布式训练正在进行中。如要查看作业状态,请多次运行 kubectl get pods (或添加 -w 以流式显示输出)。最终您应该能够看到 qcnn-worker 的数量和 replicas 参数中的数量相同,且状态均为 Running:
NAME READY STATUS RESTARTS
qcnn-worker-0 1/1 Running 0
qcnn-worker-1 1/1 Running 0
如要访问 worker 的日志输出,请运行以下命令:
kubectl logs
或添加 -f 以流式显示输出。qcnn-worker-0 的输出结果如下所示:
…
I tensorflow/core/distributed_runtime/rpc/grpc_server_lib.cc:411] Started server with target: grpc:/
/qcnn-worker-0.default.svc:2222
…
I tensorflow/core/profiler/rpc/profiler_server.cc:46] Profiler server listening on [::]:2223 selecte
d port:2223
…
Epoch 1/50
…
4/4 [==============================] - 7s 940ms/step - loss: 0.9387 - accuracy: 0.0000e+00 - val_loss: 0.7432 - val_accuracy: 0.0000e+00
…
I tensorflow/core/profiler/lib/profiler_session.cc:71] Profiler session collecting data.
I tensorflow/core/profiler/lib/profiler_session.cc:172] Profiler session tear down.
…
Epoch 50/50
4/4 [==============================] - 1s 222ms/step - loss: 0.1468 - accuracy: 0.4101 - val_loss: 0.2043 - val_accuracy: 0.4583
File /tmp/qcnn_weights.h5 uploaded to qcnn_weights.h5.
qcnn-worker-1 的输出结果与上述结果类似,区别是没有最后一行。主 worker (worker 0) 负责保存整个模型的权重。
您也可以访问 Cloud Console 中的 Storage 浏览器,通过浏览之前创建的存储分区来验证模型权重。
-
Cloud Console 中的 Storage 浏览器
https://console.cloud.google.com/storage/browser
如要删除训练作业,请运行以下命令:
kubectl delete -f training/qcnn.yaml
借助 TensorBoard 了解训练性能
TensorBoard 是 TensorFlow 的可视化工具包。通过将 TensorFlow Quantum 模型与 TensorBoard 进行集成,您将获得许多开箱可用的模型可视化数据,例如训练损失和准确性、可视化模型图和程序分析。
代码设置
如要在作业中启用 TensorBoard,请创建 TensorBoard 回调并将其传入 model.fit():
tensorboard_callback = tf.keras.callbacks.TensorBoard(log_dir=args.logdir,
histogram_freq=1,
update_freq=1,
profile_batch='10, 20')
…
history = qcnn_model.fit(x=train_excitations,
y=train_labels,
batch_size=32,
epochs=50,
verbose=1,
validation_data=(test_excitations, test_labels),
callbacks=[tensorboard_callback])profile_batch 参数可在程序化模式下启用 TensorFlow 性能剖析器,从而在您于此处指定的训练步骤范围内对程序进行采样。您也可以启用采样模式。
tf.profiler.experimental.server.start(args.profiler_port)该模式允许由不同程序或通过 TensorBoard 界面发起按需分析。
TensorBoard 功能
在这里我们将重点介绍本教程中使用的部分 TensorBoard 的强大功能。请查看 TensorBoard 指南以了解详情。
-
TensorBoard 指南
https://tensorflow.google.cn/tensorboard/get_started
损失和准确性
损失是模型在训练过程中力求最小化的数量,可通过损失函数计算得出。准确性是指在训练过程中,预测结果与标签匹配的样本的比例。默认情况下系统会导出损失指标。如要启用准确性指标,请将以下命令添加到model.compile() 步骤中:
qcnn_model.compile(..., metrics=[‘accuracy’])
自定义指标
除了损失指标和准确性指标以外,TensorBoard 同样还支持自定义指标。例如,教程代码将 QCNN 读出张量以直方图的形式导出。
-
自定义指标
https://tensorflow.google.cn/tensorboard/scalars_and_keras#logging_custom_scalars
性能剖析器
TensorFlow 性能剖析器是一款十分有用的工具,该工具可助您在模型训练作业中调试性能瓶颈。在本教程中,我们同时采用了程序化模式(在预定义的训练步骤范围内进行分析)和采样模式(按需进行分析)。如果是 MultiWorkerMirroredStrategy 的设置,则目前的程序化模式仅会输出来自主 worker (worker 0) 的分析数据,而采样模式能够对所有 worker 进行分析。
-
TensorFlow 性能剖析器
https://tensorflow.google.cn/guide/profiler
当您第一次打开性能剖析器时,显示的数据均来自程序化模式。您可通过概览页面了解到每个训练步骤所需时长。无论是扩缩基础架构(向集群中添加更多的虚拟机、使用配备更多 CPU 和更大内存的虚拟机、与硬件加速器集成)还是提高代码效率,当您尝试用不同的方法来提升训练性能时,均可以此为参考。

Trace Viewer 会将所有后台训练指令耗费的时间在详细视图中分别列出,以便您确定执行时间瓶颈。
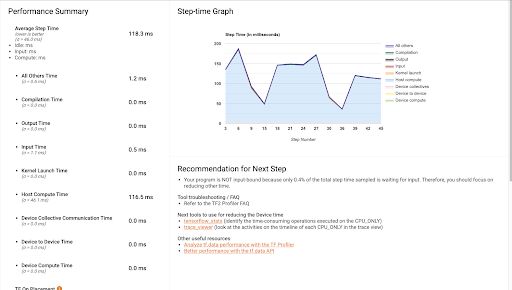
Kubernetes 部署设置
如要查看 TensorBoard 界面,您可以在 Kubernetes 中创建 TensorBoard 实例。Kubernetes 设置位于 training/tensorboard.yaml。该文件包含 2 个对象:
-
一个是 Deployment 对象,其中包含带有相同 worker 容器映像的 pod 副本,不同的是要用 TensorBoard 命令来运行:
tensorboard --logdir=gs://${BUCKET_NAME}/${LOGDIR_NAME} --port=5001 --bind_all -
一个是可以创建网络负载平衡器的 Service 对象,能够实现通过互联网访问 TensorBoard 界面,这样您就可以在浏览器中查看该界面。
您也可以通过将 --logdir 指向相同的 Cloud Storage 存储分区,以在工作站上运行 TensorBoard 本地实例,不过这需要额外的 IAM 权限设置。
创建 Kubernetes 设置:
kubectl apply -f training/tensorboard.yaml
在 kubectl get pods 的输出结果中,您应该可以看到一个前缀为 qcnn-tensorboard的 pod,其最终会处于运行状态。如要获得 TensorBoard 实例的 IP 地址,请运行以下命令:
kubectl get svc tensorboard-service -wNAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S)
tensorboard-service LoadBalancer 10.123.240.9 5001:32200/TCP 负载平衡器需要花费一些时间来进行预配,所以您可能不会马上看到 IP 地址。预配完成后,请在浏览器中转到
借助 TensorFlow 2.4 及更高版本,我们可以在采样模式下分析多个 worker:在训练作业运行期间,您可通过点击 Tensorboard 性能剖析器中的“捕获性能剖析文件”,并将“性能剖析文件服务网址”设为 qcnn-worker- 来分析 worker 。要启用此功能,worker 服务需要公开性能剖析器端口。教程源代码中提供的脚本能够修补所有由 TFJob 生成的 worker Service,为其设置性能剖析器端口。运行以下命令即可:
training/apply_profiler_ports.sh请注意,手动修补 Service 只是临时解决方案,目前我们正在计划对 tf-operator 进行修改,以支持在 TFJob 中指定其他端口。
运行推理
在完成分布式训练作业后,模型权重会存储在您的 Cloud Storage 存储分区中。然后您可以使用这些权重来构建推理程序,进而在 Kubernetes 集群中创建推理作业。您也可以在本地工作站上运行推理程序,不过这需要额外的 IAM 权限来向 Cloud Storage 授予访问权限。
代码设置
inference/ 目录中提供了推理源代码。主文件 qcnn_inference.py 基本上是重用 common/qcnn_common.py 中的模型构建代码,但是会改为从 Cloud Storage 存储分区中加载模型权重:
qcnn_weights_path = '/tmp/qcnn_weights.h5'
download_blob(args.weights_gcs_bucket, args.weights_gcs_path, qcnn_weights_path)
qcnn_model.load_weights(qcnn_weights_path)
然后主文件会将模型应用于测试集,并计算均方误差。
results = qcnn_model(test_excitations).numpy().flatten()
loss = tf.keras.losses.mean_squared_error(test_labels, results)
Kubernetes 部署设置
本节中剩余的步骤可通过以下这行命令来执行:
make inference
由于您已经在训练步骤中将推理程序内置到 Docker 映像中,所以在这一步中,您无需构建新的映像。推理作业规范 inference/inference.yaml 中存在一个 Job,其 pod 规范指向映像,但会改为执行 qcnn_inference.py。运行 kubectl apply -f inference/inference.yaml 以创建作业。
前缀为 inference-qcnn的 pod 最终应处于运行状态 (kubectl get pods)。在推理 pod (kubectl logs ) 的日志输出中,均方误差应接近于 TensorBoard 界面中显示的最终损失。
…
Blob qcnn_weights.h5 downloaded to /tmp/qcnn_weights.h5.
[-0.8220097 0.40201923 -0.82856977 0.46476707 -1.1281478 0.23317486
0.00584182 1.3351855 0.35139582 -0.09958048 1.2205497 -1.3038696
1.4065738 -1.1120421 -0.01021352 1.4553616 -0.70309246 -0.0518395
1.4699622 -1.3712595 -0.01870352 1.2939589 1.2865802 0.847203
0.3149605 1.1705848 -1.0051676 1.2537074 -0.2943283 -1.3489063
-1.4727883 1.4566276 1.3417912 0.9123422 0.2942805 -0.791862
1.2984066 -1.1139404 1.4648925 -1.6311806 -0.17530376 0.70148027
-1.0084027 0.09898916 0.4121615 0.62743163 -1.4237025 -0.6296255 ]
Test Labels
[-1 1 -1 1 -1 1 1 1 1 -1 1 -1 1 -1 1 1 -1 -1 1 -1 -1 1 1 1
1 1 -1 1 -1 -1 -1 1 1 1 -1 -1 1 -1 1 -1 -1 1 -1 1 1 1 -1 -1]
Mean squared error: tf.Tensor(0.29677835, shape=(), dtype=float32)清理
我们的分布式训练之旅到此圆满结束!在您对照着本教程实验完毕后,我们将在本节中逐步为您讲解如何清理 Google Cloud 资源。
首先移除 Kubernetes 部署。运行以下命令:
make delete-inference
kubectl delete -f training/tensorboard.yaml
如果您尚未进行此操作,请运行以下命令:
make delete-training
然后删除 GKE 集群。此操作也将删除底层虚拟机。
gcloud container clusters delete ${CLUSTER_NAME} --zone=${ZONE}
接下来,删除 Google Cloud Storage 中的训练数据。
gsutil rm -r gs://${BUCKET_NAME}
最后,按照 Cloud Console 使用说明从 Container Registry 中移除 worker 容器映像。查找名为 qcnn 的映像。
-
Cloud Console 使用说明
https://cloud.google.com/container-registry/docs/managing#deleting_images
后续工作
现在,您已尝试过多 worker 设置,那么不妨在您的项目中试着设置吧!由于本教程中提到的工具会不断更新迭代,训练多 worker 的最佳做法也会随时间发生变化。请定期查看 TensorFlow Quantum GitHub 代码库中的教程目录,以获取更新内容!
-
TensorFlow Quantum GitHub
https://github.com/tensorflow/quantum/tree/master/docs/tutorials/qcnn_multiworker
随着实验规模的不断扩大,您最终可能会受到基础架构的限制,即由于在分布式环境中工作的复杂性,您需要对本教程中用到的技术进行高级配置。如需详细了解上述内容,请查看以下资源
-
使用 TensorFlow 进行分布式训练
https://tensorflow.google.cn/guide/distributed_training
-
TensorBoard 指南
https://tensorflow.google.cn/tensorboard/get_started
-
TensorFlow 博客
https://blog.tensorflow.org/
-
Kubernetes 文档
https://kubernetes.io/docs/home/
管理容器资源,因为大型训练作业的资源通常会受到限制。
https://kubernetes.io/docs/concepts/configuration/manage-resources-containers/
-
Google Kubernetes Engine 文档
https://cloud.google.com/kubernetes-engine/docs
-
Google Cloud 博客
https://cloud.google.com/blog/
如果您有兴趣在 Tensorflow Quantum 中进行大规模的 QML 研究,请查看我们的研究赠金申请页面,以在 Google Cloud 上申请 Cloud 赠金。
-
研究赠金申请页面
https://edu.google.com/programs/credits/research/?modal_active=none
想获取更多 TensorFlow 官方资讯,可访问 TensorFlow 中国官网:tensorflow.google.cn
或扫描下方二维码关注官方微信!