Flink_01_概述(个人总结)
声明: 1. 本文为我的个人复习总结, 并非那种从零基础开始普及知识 内容详细全面, 言辞官方的文章
2. 由于是个人总结, 所以用最精简的话语来写文章
3. 若有错误不当之处, 请指出
简介:
Flink用于对无界和有界数据流进行有状态计算
一切皆为流数据(数据是源源不断过来的, 没有边界尽头), 批处理数据是有界数据流
流处理 VS 批处理:
数据来一点处理一点
数据积攒到一批才进行处理
窗口是有点批处理那味的, 但是窗口有滑动步长, 可以步长设小点, 依然要不停地实时计算
窗口是有界流
无界流, 处理数据时是 认为只拿到当前以及之前的数据
有界流, 处理数据时是 认为一次性拿到所有数据
实时计算 VS 离线计算:
实时计算 数据处理的延迟低, 以毫秒为单位
离线计算 数据处理的延迟高, 以天/小时为单位
准实时计算: 延迟处于实时和离线之间, 以秒/分钟为单位
实时离线 是从数据处理延迟的角度来看的, 流处理批处理 是从数据积攒量的角度来看的,
一般而言 实时计算是流处理, 离线计算是批处理
状态:
状态就是一块本地内存, 要访问历史窗口(或批次)的数据时就需要用到状态, 把历史窗口(或批次)的数据处理结果值保存到状态里
事件驱动型:
事件的到来会触发计算
优点:
-
同时支持 高吞吐, 低延迟, 高性能
Spark 高吞吐, 高延迟, 高性能
Storm 低吞吐, 低延迟, 高性能
吞吐量是指一段时间内数据的处理量
低延迟和高吞吐其实是悖论:
-
如果要求数据延迟低的话,那么数据肯定是来一条就处理一条,然后马上将数据发送给下游,这样延迟肯定是最低的
-
但是如果要提高吞吐量的话,不如先缓存一批数据,然后一次性将缓存的数据进行处理然后发送出去这样效率比较高
网络传输方面(分布式计算系统 JobManager和TaskManager的传输), 一次传输100条数据, 肯定比100次传1条数据更高效,
可以减小在网络上频繁传输单个消息带来的
延迟和网络带宽开销 ,减小了TCP连接次数从而节约了三次握手四次挥手的次数
Flink对低延迟和高吞吐 权衡一下取了一个折中,
可以用setBufferTimeout方法设置timeoutMills参数, 用于控制上游往下游发送数据的频率:
-
设成100(默认值), 即每隔100ms会flush一次所有的channel,将当前Task中的数据发送给下游
-
设成-1, 那么就会在Buffer满了或者Checkpoint触发时才会将数据发送到下游, 此时能够获得最大的吞吐量
-
设成0,那么每条数据处理完毕之后都会立刻发送到下游,此时能够获得最低的延迟
-
-
自行高效地管理JVM内存
-
支持灵活的窗口操作, 有时间语义和Watermark容忍迟到数据
-
支持有状态的计算
-
高容错, 有检查点持久化机制, 基于分布式快照算法实现
-
有FlinkSQL和CEP这种强大的高级API
Flink的四大基石:
window, time(时间语义+watermark), state, checkpoint
Flink对比其他计算引擎:
分析角度:
- 延时上
- 吞吐量上
- 使用磁盘 or 内存
- 更多的强大机制
Flink VS Spark:
Flink VS SparkStreaming:
-
Flink 高吞吐, 低延迟, 高性能
Spark 高吞吐, 高延迟, 高性能
-
Flink是流处理, 实时计算
Spark是微批处理, 准实时计算
-
Flink完全基于内存
Spark的Shuffle阶段基于磁盘, 其他阶段基于内存
-
很多处理机制上, Flink更强大
- 有多种时间语义
- 有watermark允许迟到机制
- 有多种窗口
- State更丰富
- 有侧输出流, 用来临时存放数据, 然后后续根据标签进行提取
- 有采用分布式快照算法, 持久化工作 和 Task 并发运行
- 有Exactly Once机制
Flink VS SparkRDD(非Streaming模块):
-
Flink是流处理, 实时计算
SparkRDD是批处理, 离线计算
-
Flink完全基于内存
Spark的Shuffle阶段基于磁盘, 其他阶段基于内存
Flink VS MapReduce:
-
Flink是流处理, 实时计算
MapReduce是批处理, 离线计算
-
Flink完全基于内存
MapReduce基于磁盘
模块:
- Process: 最底层API, 功能最全面
- DataSet: 批处理数据集
- DataStream: 流处理数据流
- FlinkSQL/TableAPI (做到了批流通一, 共用一套API)
- CEP (类似于正则表达式, 将事件按照一定的规则进行匹配)
- 图计算
数据处理架构:
实时计算的准确性没有离线计算高, 因为实时计算要抛弃迟到时间过长(可能有网络拥堵)的数据
Flink采用了lambda架构, 既具有流处理, 又具有批处理
优点: 同时保证了数据 处理延迟低 & 准确处理
缺点: 同时要维护两套系统, 当需求变更时, 二者都需要变, 较为麻烦
lambda架构:
- 速度层 进行流处理
- 批处理层 进行批处理
Kappa架构:
只有速度层, 流处理和批处理都放在这一层,
适用于流处理需求逻辑和批处理需求逻辑完全一致,
当流处理逻辑和批处理逻辑不一致时, Kappa就没法做了
slot(插槽):
是资源的最小管理单位, 各个slot之间是并行处理的
slot数量即并行度, 应用程序的并行度=max{各个Task的并行度}
one-to-one: 即窄依赖
Redistributing: 即款依赖
任务链: 将并行度相同 & one-to-one Task(不用等待, 而如果是Redistributing的话得等待上游所有分区数据都到齐), 合成一个大的Task, 以减少任务之间数据的传递, 以及节省所需slot的个数
可以自行设置任务是否允许合并, 是否要独立使用一个slot, 以及设置slot共享组
parallelism是实际执行时的并行度, slot是最大并行度
分区间的Task是并行执行的
Flink架构:
-
JobManager
- 生成作业执行流程图
- 向ResourceManager申请给TaskManager分配资源(即slot)
-
TaskManager
任务的执行者
-
ResourceManager
是Flink内部的ResourceManager, 管理TaskManager中的slot(分配 & 释放)
-
Dispatcher
接收客户端提交的作业, 转交给JobManager;
同时会提供WebUI界面, 用来监控和展示作业的执行情况
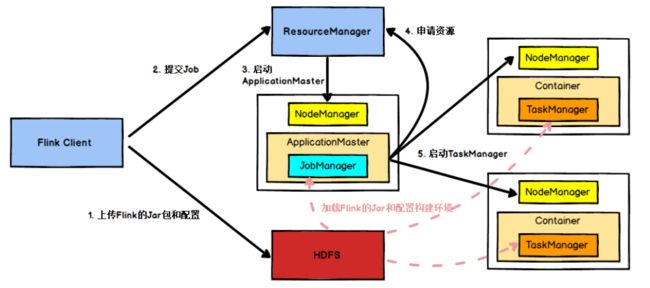
部署模式:
Yarn, K8S
其中Yarn模式分为:
Session-Cluster模式:
在yarn中初始化一个常驻的flink集群, 开辟指定的资源, 以后提交任务都向这里提交
Per-Job-Cluster模式(推荐):
每次提交都会创建一个新的 临时的flink集群
优点: 任务之间互相独立互不影响, 方便管理
作业提交流程: