深入学习OpenCV文档扫描OCR识别及答题卡识别判卷(文档扫描,图像矫正,透视变换,OCR识别)

人工智能学习离不开实践的验证,推荐大家可以多在FlyAI-AI竞赛服务平台多参加训练和竞赛,以此来提升自己的能力。FlyAI是为AI开发者提供数据竞赛并支持GPU离线训练的一站式服务平台。每周免费提供项目开源算法样例,支持算法能力变现以及快速的迭代算法模型。
如果需要处理的原图及代码,请移步小编的GitHub地址
传送门:请点击我
如果点击有误:https://github.com/LeBron-Jian/ComputerVisionPractice
下面准备学习如何对文档扫描摆正及其OCR识别的案例,主要想法是对一张不规则的文档进行矫正,然后通过tesseract进行OCR文字识别,最后返回结果。下面进入正文:
现代生活中,手机像素比较高,所以大家拍这些照片都很随意,随便拍,比如下面的照片,如发票,文本等等:


对于这些图像矫正的问题,在图像处理领域还真的很多,比如文本的矫正,车牌的矫正,身份证的矫正等等。这些都是因为拍摄者拍照随意,这就要求我们通过后期的图像处理技术将图片还原好,才能进行下一步处理,比如数字分割,数字识别,字母识别,文字识别等等。
上面的问题,我们在日常生活中遇到的可不少,因为拍摄时拍的不好,导致拍出来的图片歪歪扭扭的,很不自然,那么我们如何将图片矫正过来呢?
总的来说,要进行图像矫正,至少需要以下几步:
- 1,文档的轮廓提取技术
- 2,原始与变换坐标的计算
- 3,通过透视变换获取目标区域
本文通过两个案例,一个是菜单矫正及OCR识别;另一个是答题卡矫正及OCR识别。
1,如何扫描菜单并获取菜单内容
下面以菜单为例,慢慢剖析如何实现图像矫正,并获取菜单内容。

上面的斜着的菜单,如何扫描到如右图所示的照片呢?其实步骤有以下几步:
- 1,探测边缘
- 2,提取菜单矩阵轮廓四点进行透视变换
- 3,应用一个透视的转换去获取一个文档的自顶向下的正图
知道步骤后,我们开始做吧!
1.1,文档轮廓提取
我们拿到图像之后,首先进行边缘检测,其中预处理包括对噪音进行高斯模糊,然后进行边缘检测(这里采用了Canny算子提取特征),下面我们可以看一下边缘检测的代码与结果:
代码:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 |
|
效果如下:
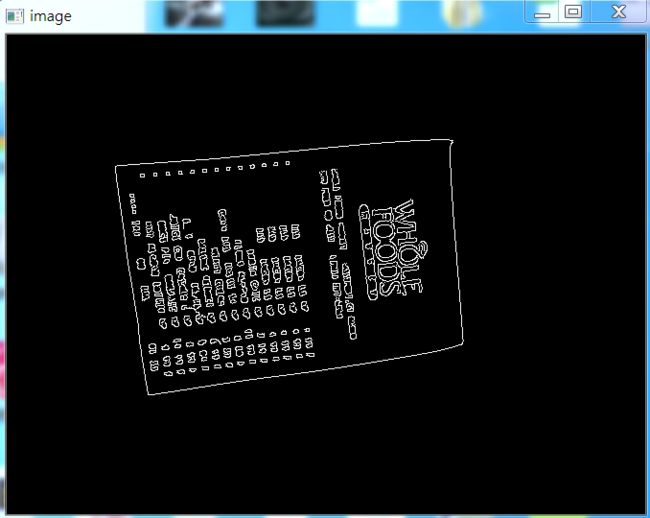
我们从上图可以看到,已经将菜单的所有轮廓都检测出来了,而我们其实只需要最外面的轮廓,下面我们通过过滤得到最边缘的轮廓即可。
代码如下:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
|
效果如下:

如果说对轮廓排序后,不进行近似的话,我们直接取最大的轮廓,效果图如下:

1.2,透视变换(摆正图像)
当获取到图片的最外轮廓后,接下来,我们需要摆正图像,在摆正图形之前,我们需要先学习透视变换。
1.2.1,cv2.getPerspectiveTransform()
透视变换(Perspective Transformation)是将成像投影到一个新的视平面(Viewing Plane),也称作投影映射(Projective mapping),如下图所示,通过透视变换ABC变换到A'B'C'。
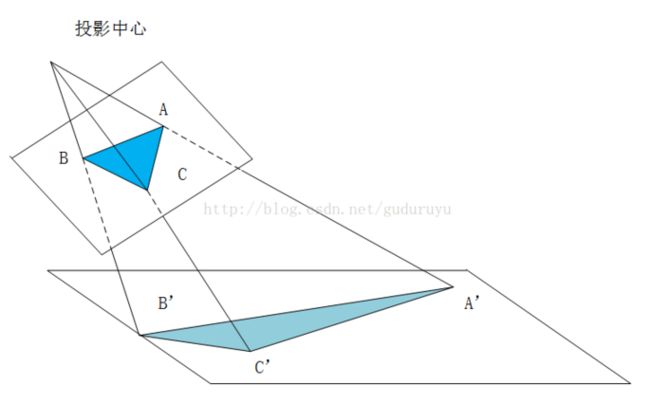
cv2.getPerspectiveTransform() 获取投射变换后的H矩阵。
cv2.getPerspectiveTransform() 函数的opencv 源码如下:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
|
参数说明:
- rect(即函数中src)表示待测矩阵的左上,右上,右下,左下四点坐标
- transform_axes(即函数中dst)表示变换后四个角的坐标,即目标图像中矩阵的坐标
返回值由原图像中矩阵到目标图像矩阵变换的矩阵,得到矩阵接下来则通过矩阵来获得变换后的图像,下面我们学习第二个函数。
1.2.2,cv2.warpPerspective()
cv2.warpPerspective() 根据H获得变换后的图像。
opencv源码如下:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
|
参数说明:
- src 表示输入的灰度图像
- M 表示变换矩阵
- dsize 表示目标图像的shape,(width, height)表示变换后的图像大小
- flags:插值方式,interpolation方法INTER_LINEAR或者INTER_NEAREST
- borderMode:边界补偿方式,BORDER_CONSTANT or BORDER_REPLCATE
- borderValue:边界补偿大小,常值,默认为0
1.2.3 cv2.perspectiveTransform()
cv2.perspectiveTransform() 和 cv2.warpPerspective()大致作用相同,但是区别在于 cv2.warpPerspective()适用于图像,而cv2.perspectiveTransform() 适用于一组点。
cv2.perspectiveTransform() 的opencv源码如下:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
|
参数含义:
- src:输入的二通道或三通道的图像
- m:变换矩阵
- 返回结果为相同size的图像
1.2.4 摆正图像
将图像框出来后,我们计算出变换前后的四个点的坐标,然后得到最终的变换结果。
代码如下:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 |
|
效果如下:

1.2.5 其他图片矫正实践
这里图片原图都可以去我的GitHub里面去拿(地址:https://github.com/LeBron-Jian/ComputerVisionPractice)。
对于下面这张图:

我们使用透视变换抠出来效果如下:

这个图使用和之前的代码就可以,不用修改任何东西就可以拿到其目标区域。
下面看这张图:

其实和上面图类似,不过这里我们依次看一下其图像处理过程,毕竟和上面两张图完全不是一个类型了。
首先是 Canny算子得到的结果:
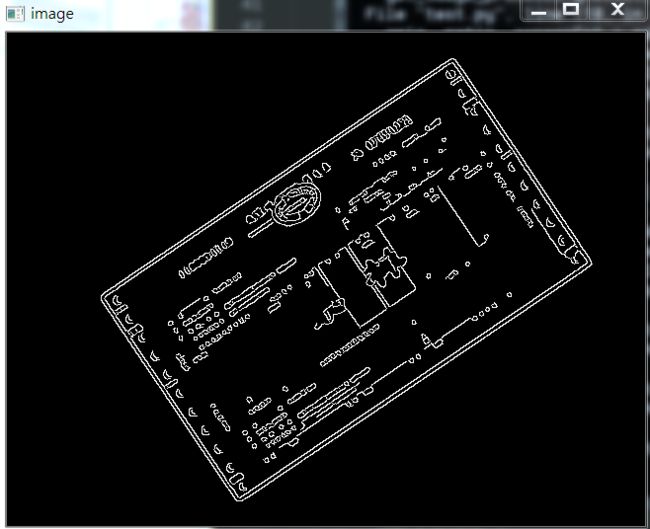
其实拿到全轮廓后,我们就直接获取最外面的轮廓即可。
我自己更改了一下,效果一样,但是还是贴上代码:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
|
最后我们不对发票做任何处理,看原图效果:

部分代码如下:
| 1 2 3 4 5 6 7 8 9 10 11 |
|
下面再看一个例子:

首先,它得到的Canny结果如下:
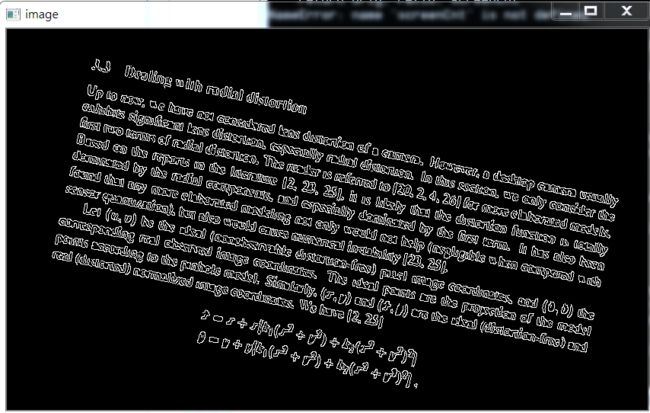
我们需要对它进行一些小小的处理。
我做了一些尝试,如果直接对膨胀后的图像,进行外接矩形,那么效果如下:

代码如下:
| 1 2 3 |
|
所以对轮廓取近似,效果稍微好点:
| 1 2 3 4 5 6 |
|
效果如下:

因为这个是不规整图形,所以无法进行四个角的转换,需要更多角,这里不再继续尝试。
1.3,OCR识别
这里回到我们的菜单来,我们已经得到了扫描后的结果,下面我们进行OCR文字识别。
这里使用tesseract进行识别,不懂的可以参考我之前的博客(包括安装tesseract,和通过tesseract训练自己的字库):
深入学习使用ocr算法识别图片中文字的方法
深入学习Tesseract-ocr识别中文并训练字库的方法
配置好tesseract之后(这里不再show过程,因为我已经有了),我们通过其进行文字识别。
1.3.1 通过Python使用tesseract的坑
如果直接使用Python进行OCR识别的话,会出现下面问题:
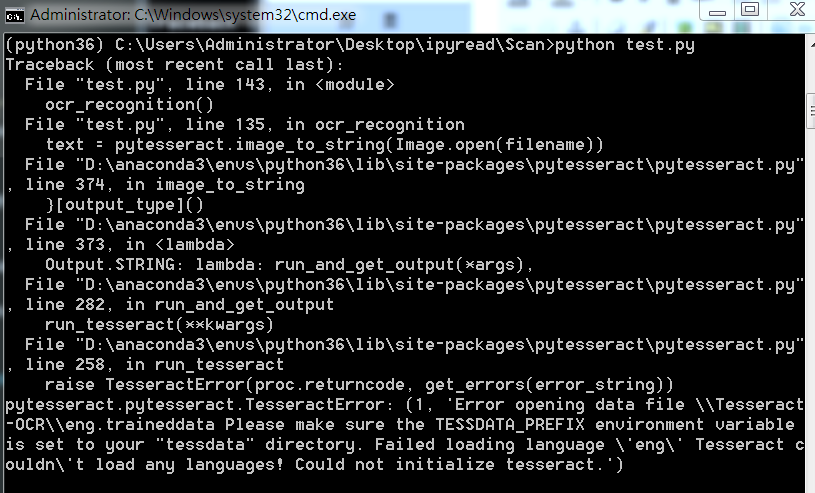
这里因为anaconda下载的 pytesseract 默认运行的tesseract.exe 是默认文件夹,所以有问题,我们改一下。
注意,找到安装地址,我们会发现有两个文件夹,我们进入上面文件夹即可

进入之后如下,我们打开 pytesseract.py。
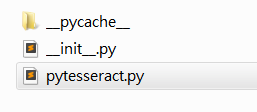
注意这里的地址:
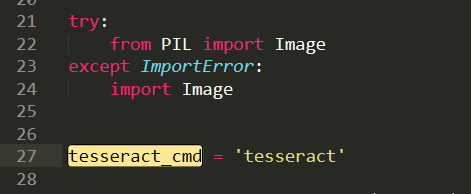
我们需要修改为我们安装的地址,即使我们之前设置了全局变量,但是Python还是不care的。
这里注意地址的话,我们通过 / 即可,不要 \,避免windows出现问题。
1.3.2 OCR识别
安装好一切之后,就可以识别了,我们这里有两种方法,一种是直接在人家的环境下运行,一种是在Python中通过安装pytesseract 库运行,效果都一样。
代码如下:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
|
使用Python运行,效果如下:
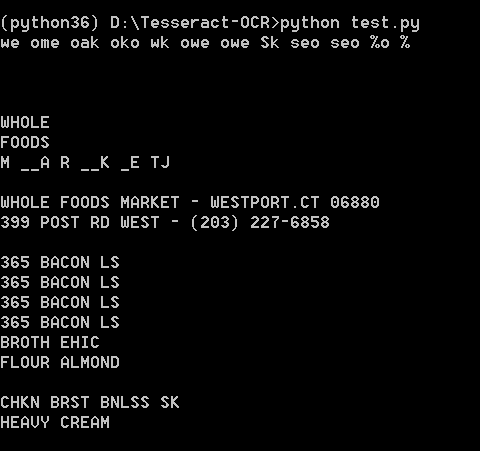
直接在tesseract.exe运行:
![]()
效果如下:
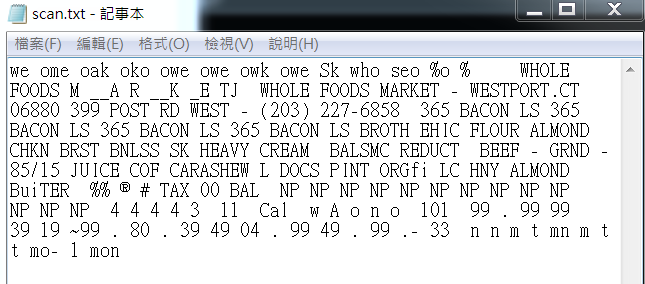
可能识别效果不是很好。不过不重要,因为图片也比较模糊,不是那么工整的。
1.4,完整代码
当然也可以去我的GitHub直接去下载。
代码如下:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 |
|
2,如何扫描答题卡并识别
答题卡识别判卷,大家应该都不陌生。那么它需要做什么呢?肯定是将我们在答题卡上画圈圈的地方识别出来。
这是答题卡样子(原图请去我GitHub上拿:https://github.com/LeBron-Jian/ComputerVisionPractice):

我们肯定是需要分为两步走,第一步就是和上面处理类似,拿到答题卡的最终透视变换结果,使得图片中的答题卡可以凸显出来。第二步就是根据正确答案和答题卡的答案来判断正确率。
2.1 扫描答题卡及透视变换
这里我们对答题卡进行透视变换,因为之前已经详细的学习了这一部分,这里不再赘述,只是简单记录一下流程和图像处理效果,并展示代码。
下面详细的总结处理步骤:
- 1,图像灰度化
- 2,高斯滤波处理
- 3,使用Canny算子找到图片边缘信息
- 4,寻找轮廓
- 5,找到最外层轮廓,并确定四个坐标点
- 6,根据四个坐标位置计算出变换后的四个角位置
- 7,获取变换矩阵H,得到最终变换结果
下面直接使用上面代码进行跑,首先展示Canny效果:

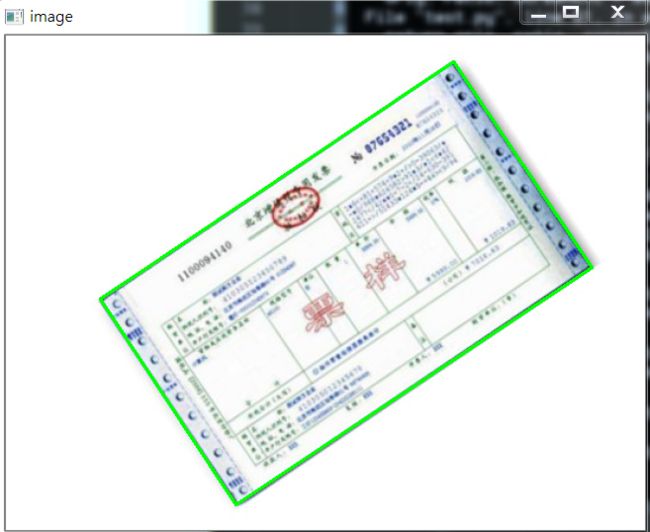
当Canny效果不错的时候,我们拿到图像的轮廓进行筛选,找到最外面的轮廓,如下图所示:

最后通过透视变换,获得答题卡的区域,如下图所示:

2.2 根据正确答案和图卡判断正确率
这里我们拿到上面得到的答题卡图像,然后进行操作,获取到涂的位置,然后和正确答案比较,最后获得正确率。
这里分为以下几个步骤:
- 1,对图像进行二值化,将涂了颜色的地方变为白色
- 2,对轮廓进行筛选,找到正确答案的轮廓
- 3,对轮廓从上到下进行排序
- 4,计算颜色最大值的位置和Nonezeros的值
- 5,结合正确答案计算正确率
- 6,将正确答案打印在图像上
下面开始实践:
首先对图像进行二值化,如下图所示:

如果对二值化后的图直接进行画轮廓,如下:

所以不能直接处理,这里我们需要做细微处理,然后拿到图像如下:

这样就可以获得其涂的轮廓,如下所示:

然后筛选出我们需要的涂了答题卡的位置,效果如下:

然后通过这五个坐标点,确定答题卡的位置,如下图所示:

然后根据真实答案和图中答案对比结果,我们将最终结果与圈出来答案展示在图上,如下:

此项目到此结束。
2.3 部分代码展示
完整代码可以去我的GitHub上拿(地址:https://github.com/LeBron-Jian/ComputerVisionPractice)
代码如下:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 |
|
参考文献:
https://www.pyimagesearch.com/2014/09/01/build-kick-ass-mobile-document-scanner-just-5-minutes/
https://blog.csdn.net/weixin_30666753/article/details/99054383
https://www.cnblogs.com/my-love-is-python/archive/2004/01/13/10439224.html

更多精彩内容请访问FlyAI-AI竞赛服务平台;为AI开发者提供数据竞赛并支持GPU离线训练的一站式服务平台;每周免费提供项目开源算法样例,支持算法能力变现以及快速的迭代算法模型。
挑战者,都在FlyAI!!!