Hive全解
文章目录
-
-
- 一.Hive基本介绍
-
- 1.基本名词解释
- 2.hive概述
- 3.hive可以做什么 以及 适用场景
-
- a 不适合:
- b 适合:
- 4.hive特点
- 5.hive安装与配置
- 二.Hiveql与Hive基础指令
-
- 1.基础指令
- 2.join操作
- 3.Hive工作流程
- 三.Hive表类型
-
- !注意
- 1.内部表
-
- 概念
- 特点
- 2.外部表
-
- 概念
- 特点
- 如何创建
- 3.分区表
-
- a.基本介绍
- b.作用
- c. 实际运用
- d.语法
- 4.分桶表
-
- a.分桶原理
- b.分桶语法 TABLESAMPLE(BUCKET X OUT OF Y)
- c.分桶指令(分桶表只能是内部表)
- 四.Hive语法
-
- 1.数据类型
-
- a 基本数据类型
- b 复杂数据类型
- 2.字符串操作
- 3.explode
- 4.UDF与UDAF与UDTF
-
- a.UDF可以做什么?
- b.什么时候用UDF
- 五.Hive的数据倾斜
-
- 1.场景
- 2.哪些操作会导致数据倾斜
- 3.处理数据倾斜
-
- a.处理group by
- b.解决join
- c.解决count distinct
- 六.Hive优化
-
- 1.见五的数据倾斜处理
- 2.调整切片数(map任务数)
- 3.JVM重利用
- 4.启用严格模式
- 七.Hive体系结构
-
- 1. 用户接口
- 2.Metastore(元数据信息 默认derby 可设置成mysql)
- 3.解释器(complier)、优化器(optimizer)、执行器(executor)组件
- 4.Hadoop
- 八.Sqoop安装与指令
- 九.hive面试题
-
- 1.问题
-
- a.Hive的主要作用是什么?
- b.Hive中追加导入数据的4种方式是什么?请写出简要语法。
- c.Hive导出数据有几种方式?如何导出数据?
- d.Hive几种排序的特点
- e.Sqoop如何导入数据,如何导出数据?
- f.海量数据分布在100台电脑中,想个办法高效统计出这批数据的TOP10
- g.分区和分桶的区别
- h.Hive数据倾斜的原因与解决方案
- i.Hive如何优化
- j.配置hive-env.sh都涉及到哪些属性
- k.配置hive-site.xml都修改了哪些属性,请写出属性名称并解释该属性
- 2.答案
-
- a.
- b.
- c.
- d.
- e.
- f.
- g.
- h.
- i.
- j.
- k.
- l.
- 十.拓展
-
- 1.常用sql练习
- 2.hiveql练习
-
- 写出将 text.txt 文件放入 hive 中 test 表‘2016-10-10’ 分区的语句,test 的分区字段是 l_date。
- 转成hive SELECT a.key,a.value FROM a WHERE a.key not in (SELECT b.key FROM b)
- Hive创建id,name,sex表的语法是什么?
- Hive中如何复制一张表的表结构(不带有被复制表数据)
- 十一.hive下配置元数据存在mysql(默认derby)
-
一.Hive基本介绍
1.基本名词解释
- 数据库:
为捕获数据设计 - 数据仓库:
为分析数据设计 ,弱事务,数据存储的都是从历史角度提供信息,一般就只有只读操作(分析) - ETL:(数据清洗)数据的提取,转化,加载
- OLTP:联机事务处理系统 如Mysql
- OLAP:联机分析处理系统 如Hive,Hbase
2.hive概述
- 基于Hadoop的一个数据仓库工具
- hiveql转化为M/R任务执行 十分适合数据仓库的统计分析
- 可以进行ETL
- 离线大数据分析工具
3.hive可以做什么 以及 适用场景
a 不适合:
- 大规模数据集的低延迟快速查询
- 本质上还是离线数据的处理的工具,实时查询性能有限,本质上是一个基于hadoop的数据仓库工具,不能支持行级别的新增修改和删除 hive支持查询,行级别的插入
b 适合:
- 大数据集的离线批处理作业
4.hive特点
- 拥有MapReduce的特点(海量数据高兴能处理 高拓展性与高容错性)
- 类sql的查询语言 学习成本不高
- 与Hadoop其他产品兼容(支持处理 HDFS 上的多种文件格式(TextFile、SequenceFile 等),还支持处理 HBase 数据库。用户也完全可以实现自己的驱动来增加新的数据源和数据格式。一种理想的应用模型是将数据存储在 HBase 中实现实时访问,而用Hive对HBase 中的数据进行批量分析。)
- hiveql的可拓展性(用户可以自定义数据类型函数 用任何语言自定义mapper与reducer脚本)
5.hive安装与配置
https://blog.csdn.net/qq_38061534/article/details/86553379
二.Hiveql与Hive基础指令
1.基础指令
https://blog.csdn.net/qq_38061534/article/details/86553848
在HDFS实际存储目录:
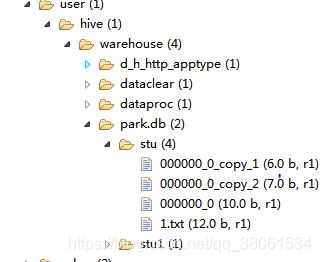
2.join操作
3.Hive工作流程
- 通过客户端提交一条Hql语句
- 通过complier(编译组件)对Hql进行词法分析、语法分析。在这一步,编译器要知道此hql语句到底要操作哪张表
- 去元数据库找表信息
- 得到信息
- complier编译器提交Hql语句分析方案。
- executor 执行器收到方案后,执行方案(DDL过程)。在这里注意,执行器在执行方案时,会判断
如果当前方案不涉及到MR组件,比如为表添加分区信息、比如字符串操作等,比如简单的查询操作等,此时就会直接和元数据库交互,然后去HDFS上去找具体数据。
如果方案需要转换成MR job,则会将job 提交给Hadoop的JobTracker。 - MR job完成,并且将运行结果写入到HDFS上。
- 执行器和HDFS交互,获取结果文件信息。
如果客户端提交Hql语句是带有查询结果性的,则会发生:6-7-8步,完成结果的查询。
三.Hive表类型
!注意
- hive表的元数据信息 存放在数据库中(默认derby 可以修改为mysql)
- 数据存储在HDFS中
- 元数据信息表中 有一张TBLS表,
其中有一个字段属性:TBL_TYPE——MANAGED_TABLE
MANAGED_TABLE 表示内部表 EXTERNAL_TABLE表示内部表
1.内部表
概念
先在hive里建一张表,然后向这个表插入数据(用insert可以插入数据,也可以通过加载外部文件方式来插入数据)
特点
- 先有hive表再有数据
- 内部表删除时 HDFS里对应存储的数据也会被删除
2.外部表
概念
HDFS里已经有数据了 如2.txt hive创建一个新表来管理这个文件数据
特点
- 先有数据再有hive表
- hive外部表管理的是HDFS某一个文件目录中的文件数据
- 删除外部表 外部表管理的对应的文件数据并不会被删除
- 当向HDFS对应的目录节点下追加文件时(只要格式符合),hive都可以把数据管理进来
如何创建
进入hive,执行:
create external table stu (id int,name string) row format delimited fields terminated by ’ ’ location ‘/目录路径’
3.分区表
a.基本介绍
- 在HDFS存储目录上 一个分区对应一个目录 分区就是一个目录
b.作用
- 可以避免查询整表,在生产环境下,基本都是建立带有分区字段的表,在查询时,带上分区条件。
c. 实际运用
- 一般以日期 如天 为单位来建立分区 方便管理表数据
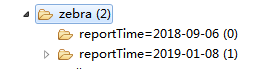
d.语法
- 创建分区
执行:create table book (id int, name string) partitioned by (category string)
row format delimited fields terminated by ‘\t’;
注:在创建分区表时,partitioned字段可以不在字段列表中。生成的表中自动就会具有该字段。
category 是自定义的字段。
-
给分区加载数据
1)load data local inpath ‘/home/cn.txt’ overwrite into table book partition (category=‘cn’);
2)load data local inpath ‘./book_english.txt’ overwrite into table book partition (category=‘en’);
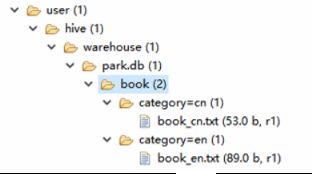
select * from book; 查询book目录下的所有数据
select * from book where category=‘cn’; 只查询 cn分区的数据 -
通过创建目录来增加分区
先在HDFS目录下 手动创建一个分区目录(category=jp) 然后在此目录下上传文件

!!!注意:此时手动创建的目录hive无法使用 要在元数据库记录该分区才行
ALTER TABLE book add PARTITION (category = ‘jp’) location ‘/user/hive/warehouse/park01.db/book/category=jp’;
作用是 添加分区 即在元数据表中创建对应的元数据 -
显示分区
show partitions iteblog;
-
添加分区
alter table book add partition (category=‘jp’) location ‘hdfs某个目录’
-
删除cn分区
alter table book drop partition(category=‘cn’)
-
修改分区
alter table book partition(category=‘french’) rename to partition(category=‘hh’)
分区名称由french改为hh
4.分桶表
https://blog.csdn.net/qq_38061534/article/details/86569037
a.分桶原理
根据指定的列的计算hash值模余分桶数量后将数据分开存放。方便数据抽样
b.分桶语法 TABLESAMPLE(BUCKET X OUT OF Y)
- 总抽取数量 N=总bucket数目S/Y
- 抽取第x个,第x+y个,第x+2*y个,…,总共N个为止
c.分桶指令(分桶表只能是内部表)
1.创建带桶的 table :
create table teacher(name string) clustered by (name) into 3 buckets row format delimited fields terminated by ’ ';
2.开启分桶机制:
set hive.enforce.bucketing=true;
3.往表中插入数据:
insert overwrite table teacher select * from tmp;//需要提前准备好temp,从temp查询数据写入到teacher
注:teacher是一个分桶表,对于分桶表,不允许以外部文件方式导入数据,只能从另外一张表数据导入。分通表只能是内部表。
四.Hive语法
1.数据类型
a 基本数据类型
- int
- boolean
- float
- double
- string
b 复杂数据类型
- array
- map
- struct
说明如下:
https://blog.csdn.net/qq_38061534/article/details/86554930
2.字符串操作
https://blog.csdn.net/qq_38061534/article/details/86554965
3.explode
![]()

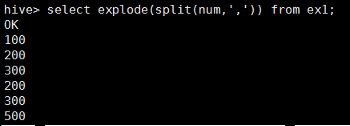
注意行数据必须是String类型
4.UDF与UDAF与UDTF
https://blog.csdn.net/dreamingfish2011/article/details/51283542
- UDF 输入一行输出一行数据
- UDAF 输入多行数据输出一行数据,一般在group by中使用。
- UDTF 用来实现一行输入多行输出
a.UDF可以做什么?
可以看如下文章:
https://blog.csdn.net/scgaliguodong123_/article/details/46993005
https://blog.csdn.net/qq_38061534/article/details/86569511
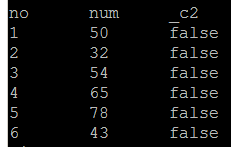
- 用户自定义函数来操作hive表 如
select no,num,bigthan(no,num) from testudf
判断no是否大于num
b.什么时候用UDF
用户的需求hiveql的内置函数不能满足需求 需要用户自己开发函数去实现
UDF使用实例
https://blog.csdn.net/zolalad/article/details/10819749
五.Hive的数据倾斜
1.场景

2.哪些操作会导致数据倾斜
- group by
- distinct xx
- join
3.处理数据倾斜
a.处理group by
set hive.groupby.skewindata=true;(shell 中输入是会话级别的)
原理:
生成的查询计划会有两个MRJob。第一个MRJob 中,Map的输出结果集合会随机分布到Reduce中,每个Reduce做部分聚合操作,并输出结果,这样处理的结果是相同的GroupBy Key有可能被分发到不同的Reduce中,从而达到负载均衡的目的;第二个MRJob再根据预处理的数据结果按照GroupBy Key分布到Reduce中(这个过程可以保证相同的GroupBy Key被分布到同一个Reduce中),最后完成最终的聚合操作。
解释:比如 100g数据80g是(aaa,某个value),这样设置后 (aaa,1) (aaa,2) 可能分配到不同的reduce任务中 这样数据就不会倾斜
b.解决join
- map side join(hive做jion时 小表在左)
当链接的两个表是一个比较小的表和一个特别大的表的时候,我们把比较小的table直接放到内存中去,然后再对比较大的表格进行map操作。join就发生在map操作的时候,每当扫描一个大的table中的数据,就要去去查看小表的数据,哪条与之相符,继而进行连接。这里的join并不会涉及reduce操作。map端join的优势就是在于没有shuffle,在实际的应用中,我们这样设置:
set hive.auto.convert.join=true;
此外,hive有一个参数:hive.mapjoin.smalltable.filesize,默认值是25mb(其中一个表大小小于25mb时,自动启用mapjoin)
- join语句优化
c.解决count distinct
六.Hive优化
1.见五的数据倾斜处理
2.调整切片数(map任务数)
3.JVM重利用
4.启用严格模式
在hive里面可以通过严格模式防止用户执行那些可能产生意想不到的不好的效果的查询,从而保护hive的集群。

七.Hive体系结构
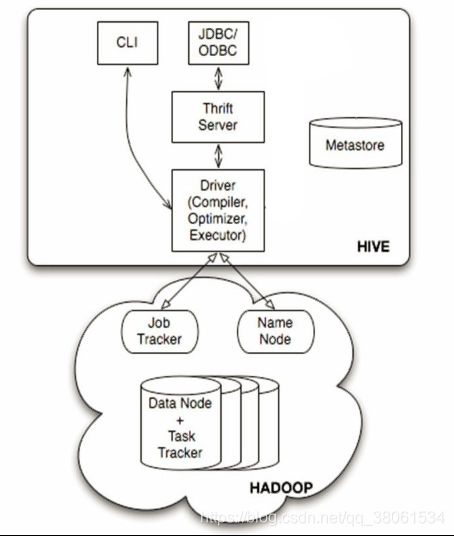
1. 用户接口
- JDBC 使用java代码操作
- CLI hive> 命令行下操作
2.Metastore(元数据信息 默认derby 可设置成mysql)
存储表的列,分区及其属性,是否为外部表,表数据所在目录
3.解释器(complier)、优化器(optimizer)、执行器(executor)组件
HQL语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储在HDFS中,并在随后有MapReduce调用执行。
4.Hadoop
Hive的数据存储在HDFS中,大部分的查询、计算由MapReduce完成
八.Sqoop安装与指令
https://blog.csdn.net/qq_38061534/article/details/86571782
九.hive面试题
1.问题
a.Hive的主要作用是什么?
b.Hive中追加导入数据的4种方式是什么?请写出简要语法。
c.Hive导出数据有几种方式?如何导出数据?
d.Hive几种排序的特点
e.Sqoop如何导入数据,如何导出数据?
f.海量数据分布在100台电脑中,想个办法高效统计出这批数据的TOP10
g.分区和分桶的区别
h.Hive数据倾斜的原因与解决方案
i.Hive如何优化
j.配置hive-env.sh都涉及到哪些属性
k.配置hive-site.xml都修改了哪些属性,请写出属性名称并解释该属性
2.答案
a.
b.
1.从本地导入: load data local inpath ‘/home/1.txt’ (overwrite)into table student;
2.从Hdfs导入: load data inpath ‘/user/hive/warehouse/1.txt’ (overwrite)into table student;
3.查询导入: create table student1 as select * from student;(也可以具体查询某项数据)
4.查询结果导入:insert (overwrite)into table staff select * from track_log;
c.
1.用insert overwrite导出方式
导出到本地:
1. insert overwrite local directory ‘/home/robot/1/2’ rom format delimited fields terminated by ‘\t’
select * from staff;(递归创建目录)
导出到HDFS
2.insert overwrite directory ‘/user/hive/1/2’ rom format delimited fields terminated by ‘\t’
select * from staff;
2.Bash shell覆盖追加导出
例如:$ bin/hive -e “select * from staff;” > /home/z/backup.log
3.Sqoop把hive数据导出到外部
d.
e.
f.
g.
h.
i.
j.
k.
l.
十.拓展
1.常用sql练习
2.hiveql练习
写出将 text.txt 文件放入 hive 中 test 表‘2016-10-10’ 分区的语句,test 的分区字段是 l_date。
转成hive SELECT a.key,a.value FROM a WHERE a.key not in (SELECT b.key FROM b)
Hive创建id,name,sex表的语法是什么?
Hive中如何复制一张表的表结构(不带有被复制表数据)
十一.hive下配置元数据存在mysql(默认derby)
https://blog.csdn.net/qq_38061534/article/details/86571985