Sleuth+Zipkin完成分布式系统链路追踪
目录
一、先抛两个常见的问题
二、链路追踪系统是做什么的
三、什么是Sleuth
四、 Sleuth怎么用
五、zipkin介绍和部署实战
六、使用Zipkin+Sleuth业务分析调用链路分析
七、现这种zipkin启动方式存在的问题
一、先抛两个常见的问题
微服务调用链路出现了问题怎么快速排查?
微服务调用链路耗时长怎么定位是哪个服务?
二、链路追踪系统是做什么的
分布式应用架构虽然满足了应用横向扩展的需求,但是运维和诊断的过程变得越来越复杂,例如会遇到接口诊断困难、应用性能诊断复杂、架构分析复杂等难题,传统的监控工具并无法满足,分布式链路系统由此诞生
核心是将一次请求分布式调用,使用GPS定位串起来,记录每个调用的耗时、性能等日志,并通过可视化工具展示出来
注意:AlibabaCloud全家桶还没对应的链路追踪系统,我们使用Sleuth和zipking(内部使用的鹰眼)
三、什么是Sleuth
一个组件,专门用于记录链路数据的开源组件
文档:https://spring.io/projects/spring-cloud-sleuth
案例
[order-service,96f95a0dd81fe3ab,852ef4cfcdecabf3,false]
第一个值,spring.application.name的值
第二个值,96f95a0dd81fe3ab ,sleuth生成的一个ID,叫Trace ID,用来标识一条请求链路,一条请求链路中包含一个Trace ID,多个Span ID
第三个值,852ef4cfcdecabf3、spanid 基本的工作单元,获取元数据,如发送一个http
第四个值:false,是否要将该信息输出到zipkin服务中来收集和展示
四、 Sleuth怎么用
微服务引入依赖pom.xml
org.springframework.cloud
spring-cloud-starter-sleuth
2.2.5.RELEASE
然后启动相关微服务,看下日志输出:
网关的日志

视频的日志
订单的日志
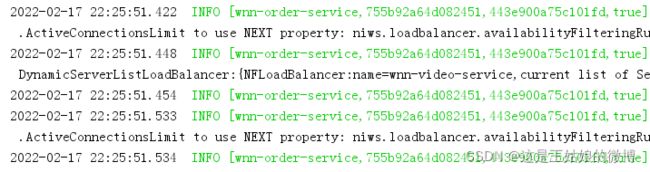
一条请求连接中的Trace ID都是一样的755b92a64d082451。
那么,这种怎么放到页面的可视化界面中呢?继续往下看~
五、zipkin介绍和部署实战
什么是zipkin
官网 https://zipkin.io/ https://zipkin.io/pages/quickstart.html
大规模分布式系统的APM工具(Application Performance Management),基于Google Dapper的基础实现,和sleuth结合可以提供可视化web界面分析调用链路耗时情况
同类产品
鹰眼(EagleEye)
CAT
twitter开源zipkin,结合sleuth
Pinpoint,运用JavaAgent字节码增强技术
开始使用:
java -jar zipkin-server-2.12.9-exec.jar 启动
访问入口:http://127.0.0.1:9411/zipkin/
zipkin组成:Collector、Storage、Restful API、Web UI组成

六、使用Zipkin+Sleuth业务分析调用链路分析
sleuth收集跟踪信息通过http请求发送给zipkin server
zipkin server进行跟踪信息的存储以及提供Rest API即可
Zipkin UI调用其API接口进行数据展示默认存储是内存,可也用mysql 或者elasticsearch等存储
微服务加入依赖:
org.springframework.cloud
spring-cloud-starter-zipkin
增加配置:
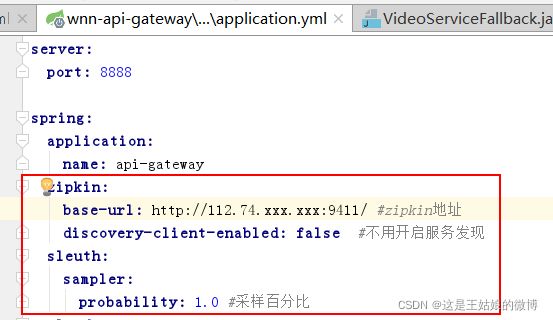
默认为0.1,即10%,这里配置1,是记录全部的sleuth信息,是为了收集到更多的数据(仅供测试用)。
在分布式系统中,过于频繁的采样会影响系统性能,所以这里配置需要采用一个合适的值。
配置后启动项目,访问接口,再查看下zipkin页面如下:
可根据服务名进行筛选

可以点开进入详情列表链路,继续查看服务的调用链路以及使用时间
点击某一个链路,可以继续进入详情页面:

七、现这种zipkin启动方式存在的问题
服务重启会导致链路追踪系统数据丢失
持久化配置:mysql或者elasticsearch
持久化到mysql的脚本:zipkin.sql
CREATE TABLE IF NOT EXISTS zipkin_spans (
`trace_id_high` BIGINT NOT NULL DEFAULT 0 COMMENT 'If non zero, this means the trace uses 128 bit traceIds instead of 64 bit',
`trace_id` BIGINT NOT NULL,
`id` BIGINT NOT NULL,
`name` VARCHAR(255) NOT NULL,
`remote_service_name` VARCHAR(255),
`parent_id` BIGINT,
`debug` BIT(1),
`start_ts` BIGINT COMMENT 'Span.timestamp(): epoch micros used for endTs query and to implement TTL',
`duration` BIGINT COMMENT 'Span.duration(): micros used for minDuration and maxDuration query',
PRIMARY KEY (`trace_id_high`, `trace_id`, `id`)
) ENGINE=InnoDB ROW_FORMAT=COMPRESSED CHARACTER SET=utf8 COLLATE utf8_general_ci;
ALTER TABLE zipkin_spans ADD INDEX(`trace_id_high`, `trace_id`) COMMENT 'for getTracesByIds';
ALTER TABLE zipkin_spans ADD INDEX(`name`) COMMENT 'for getTraces and getSpanNames';
ALTER TABLE zipkin_spans ADD INDEX(`remote_service_name`) COMMENT 'for getTraces and getRemoteServiceNames';
ALTER TABLE zipkin_spans ADD INDEX(`start_ts`) COMMENT 'for getTraces ordering and range';
CREATE TABLE IF NOT EXISTS zipkin_annotations (
`trace_id_high` BIGINT NOT NULL DEFAULT 0 COMMENT 'If non zero, this means the trace uses 128 bit traceIds instead of 64 bit',
`trace_id` BIGINT NOT NULL COMMENT 'coincides with zipkin_spans.trace_id',
`span_id` BIGINT NOT NULL COMMENT 'coincides with zipkin_spans.id',
`a_key` VARCHAR(255) NOT NULL COMMENT 'BinaryAnnotation.key or Annotation.value if type == -1',
`a_value` BLOB COMMENT 'BinaryAnnotation.value(), which must be smaller than 64KB',
`a_type` INT NOT NULL COMMENT 'BinaryAnnotation.type() or -1 if Annotation',
`a_timestamp` BIGINT COMMENT 'Used to implement TTL; Annotation.timestamp or zipkin_spans.timestamp',
`endpoint_ipv4` INT COMMENT 'Null when Binary/Annotation.endpoint is null',
`endpoint_ipv6` BINARY(16) COMMENT 'Null when Binary/Annotation.endpoint is null, or no IPv6 address',
`endpoint_port` SMALLINT COMMENT 'Null when Binary/Annotation.endpoint is null',
`endpoint_service_name` VARCHAR(255) COMMENT 'Null when Binary/Annotation.endpoint is null'
) ENGINE=InnoDB ROW_FORMAT=COMPRESSED CHARACTER SET=utf8 COLLATE utf8_general_ci;
ALTER TABLE zipkin_annotations ADD UNIQUE KEY(`trace_id_high`, `trace_id`, `span_id`, `a_key`, `a_timestamp`) COMMENT 'Ignore insert on duplicate';
ALTER TABLE zipkin_annotations ADD INDEX(`trace_id_high`, `trace_id`, `span_id`) COMMENT 'for joining with zipkin_spans';
ALTER TABLE zipkin_annotations ADD INDEX(`trace_id_high`, `trace_id`) COMMENT 'for getTraces/ByIds';
ALTER TABLE zipkin_annotations ADD INDEX(`endpoint_service_name`) COMMENT 'for getTraces and getServiceNames';
ALTER TABLE zipkin_annotations ADD INDEX(`a_type`) COMMENT 'for getTraces and autocomplete values';
ALTER TABLE zipkin_annotations ADD INDEX(`a_key`) COMMENT 'for getTraces and autocomplete values';
ALTER TABLE zipkin_annotations ADD INDEX(`trace_id`, `span_id`, `a_key`) COMMENT 'for dependencies job';
CREATE TABLE IF NOT EXISTS zipkin_dependencies (
`day` DATE NOT NULL,
`parent` VARCHAR(255) NOT NULL,
`child` VARCHAR(255) NOT NULL,
`call_count` BIGINT,
`error_count` BIGINT,
PRIMARY KEY (`day`, `parent`, `child`)
) ENGINE=InnoDB ROW_FORMAT=COMPRESSED CHARACTER SET=utf8 COLLATE utf8_general_ci;启动方式中需要带上mysql的信息:
java -jar zipkin-server-2.12.9-exec.jar --STORAGE_TYPE=mysql --MYSQL_HOST=127.0.0.1 --MYSQL_TCP_PORT=3306 --MYSQL_DB=zipkin_log(库的名称自定义的) --MYSQL_USER=root --MYSQL_PASS=123456(这是密码)
启动后再访问相关连接:


刚创建的几个表中都是有数据的,后面再重启zipkin数据都不会丢失啦!