北大博士生提出CAE,下游任务泛化能力优于何恺明MAE
杨净 发自 凹非寺
量子位 | 公众号 QbitAI
上回说道,何恺明时隔两年发一作论文,提出了一种视觉自监督学习新范式——
用掩蔽自编码器MAE,为视觉大模型开路。
这一次,北大博士生提出一个新方法CAE,在其下游任务中展现的泛化能力超过了MAE。

来看看这是一项什么样的研究?
这是一项什么研究?
自何恺明提出MAE以来,基于MIM,Masked Image Modeling,这一自监督学习表征算法就越来越引发关注。
它的主要思路,就是对输入图像进行分块和随机掩码操作,然后对掩码区域做预测。
预测的目标可以是Token ID(如微软提出的BEiT),也可以是RGB值(如MAE)。
通过MIM这一方法,编码器学习到好的表征,从而在下游任务中取得良好的泛化性能。
以往这一方法常见于NLP领域,但随着ViT的提出和发展,这一方法在视觉领域也取得了一些进展。
团队认为,近期两个代表性工作,BEiT和MAE,没有充分挖掘编码器encoder的潜力,限制了预训练学习的表征质量。
简单来说,BEiT的编码器只有一部分负责表征学习,还有一部分在做“前置/代理任务”(pretext task)。
到了MAE则是另一种情况,解码器也做了一部分表征学习,可能让编码器学会“偷懒”。
基于这一背景,团队提出了Context Autoencoder,简称CAE。核心设计思想是对“表征学习”和“前置/代理任务(pretext task)这两个功能做分离。
在预训练时,编码器只负责表征学习,解码器只负责解决前置任务,两者分工合作,将编码器表征能力最大化。
CAE包含四个部分。
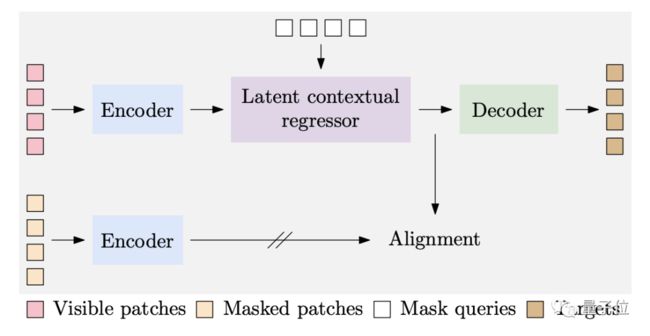
1、编码器是一个ViT模型,负责学习图像可见patch的表征,提取图像特征Zv。
2、Latent contextual regressor(隐式上下文回归器)则是在此基础上预测出掩蔽patch的表征Zm。
3、解码器以Zm和对应的位置编码作为输入,通过Zm预测掩蔽patch的某些性质,比如RGB值、Token ID。这过程中Zv不会更新,表征学习任务全交给编码器。
4、Latent representation alignment对 Zm添加约束,希望 latent contextual regressor 的输出和编码器的输出在同一空间。具体来说,图像的掩蔽patch也将输入到编码器中(此过程不参与梯度反传),获得的这部分表征,作为Zm的学习目标。
Alignment很重要,如果想对掩码部分做好预测,要求latent contextual regressor 的输出(也是解码器的输入)含有比较好的语义信息。通过对齐操作,可以鼓励编码器的操作也含有好的语义信息,提高编码器的表征质量。
论文对alignment做了可视化:将全部patch输入编码器,然后将表征直接输入到解码器中,进行RGB的重建。CAE可以将原图重建出来 (第一行是原图,第二行是重建结果),说明编码器的输出和latent contextual regressor 的输出处于同一编码空间。

如果训练时不做alignment约束,那么输出的结果将是这样…嗯,都是乱码。

这种设计的编码器学到的表征也相对更差,下游任务结果也会变差。
损失函数由两部分组成,一个是对解码器预测的监督,使用的是cross-entropy loss;一个是对alignment的监督,使用MSE损失函数。
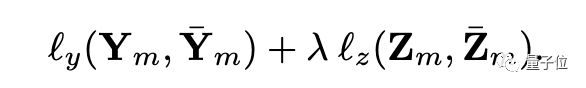
除此之外,也进一步验证了以CAE为代表的MIM方法,要比Moco v3、DINO为代表的对比学习方法更适合下游任务。
该论文从随机裁剪操作的性质分析,认为随机裁剪有很大概率包含图像的中心区域。
而ImageNet-1K这种数据集中,中心区域通常是1000类标签集中的物体(如下图)。因此,对比学习方法主要提取图像中主体物体的特征。

而MIM方法能学到每个patch的特征,包括图像的背景区域,而不仅仅是图像主体物体,这让MIM学到的表征更适合下游检测分割任务。
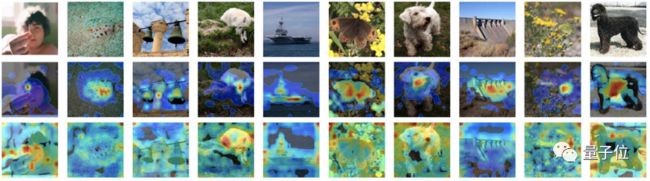
论文对CAE和MoCo v3的注意力图做了可视化。红色表示注意力值更高,蓝色表示注意力值更低。第一行是原图,第二行是 MoCo v3,第三行是 CAE。可以看到,MoCo v3 的注意力图主要在图像的主体区域有高响应,而 CAE 能考虑到几乎所有patch。
实验结果
研究团队使用ViT-small和ViT-base在 ImageNet-1K 上进行实验,输入图像的分辨率224*224,每张图被分成14*14的patch,每个patch的大小为16*16。
每次将有75个patch被随机掩码,其余patch则为可见的。
本文参照BEiT,使用DALL-E tokenizer对输入图像token化,得到预测目标。
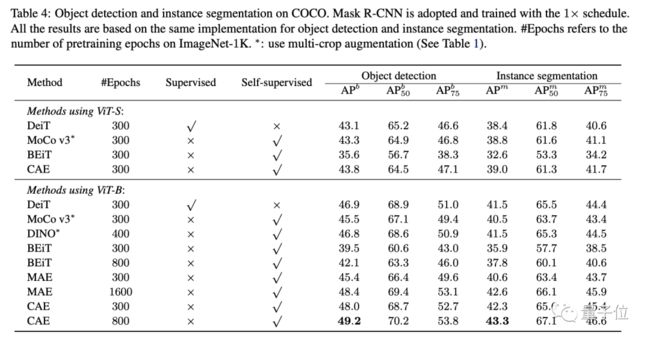
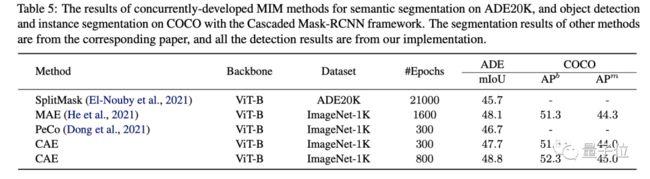
最终结果显示,在语义分割任务中,跟其他MIM方法,比如MAE、BEiT,以及对比学习、有监督预训练方法的表征结果更好。

在物体检测、实例分割的结果也是如此。
百度CV大牛领衔
本次研究由北京大学、香港大学、百度共同完成。
第一作者是在读博士生陈小康,来自北京大学机器感知与智能(教育部)重点实验室。
通讯作者是百度计算机视觉首席架构师王井东,同时也是IEEE Fellow。
在加盟百度之前,曾在微软亚研院视觉计算组担任首席研究员。

感兴趣的旁友,可戳下方链接进一步查看论文~
论文链接:
https://arxiv.org/abs/2202.03026