把大核卷积拆成三步,清华胡事民团队新视觉Backbone刷榜了,集CNN与ViT优点于一身...
梦晨 发自 凹非寺
量子位 | 公众号 QbitAI
在视觉任务上,CNN、ViT各有各的优势和劣势。
于是,以经典Backbone为基础、细节上相互借鉴,成了最近一个热门研究方向。
前有微软SwinTransformer引入CNN的滑动窗口等特性,刷榜下游任务并获马尔奖。
后有Meta AI的ConvNeXT用ViT上的大量技巧魔改ResNet后实现性能反超。
现在一种全新Backbone——VAN(Visiual Attention Network, 视觉注意力网络)再次引起学界关注。
因为新模型再一次刷榜三大视觉任务,把上面那两位又都给比下去了。
VAN号称同时吸收了CNN和ViT的优势且简单高效,精度更高的同时参数量和计算量还更小。
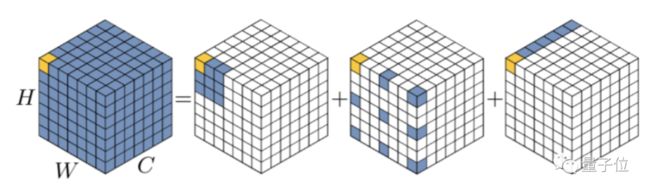
VAN来自清华计图胡事民团队,他们提出一个标准大核卷积可以拆解成三部分:
深度卷积(DW-Conv)、深度扩张卷积(DW-D-Conv)和1 × 1卷积(1 × 1 Conv)。
更关键的是,再加上一步element-wise相乘可以获得类似注意力的效果,团队把新的卷积模块命名为大核注意力LKA(Large Kernel Attention)

论文最后还提到,现在的VAN只是一个直觉的原始版本、没有仔细打磨,也就是说后续还有很大提升潜力。
(代码已开源,地址在文末)
拆解大核卷积能算注意力
注意力机制,可以理解为一种自适应选择过程,能根据输入辨别出关键特征并自动忽略噪声。
关键步骤是学习输入数据的长距离依赖,生成注意力图。
有两种常用方法来生成注意图。
第一种是从NLP来的自注意力机制,但用在视觉上还有一些不足,比如把图像转换为一维序列会忽略其二维结构。
第二种是视觉上的大核卷积方法,但计算开销又太大。
为克服上面的问题,团队提出的LKA方法把大核卷积拆解成三部分。
设扩张间隔为d,一个K x K的卷积可以拆解成K/d x K/d的深度扩张卷积,一个(2d − 1) × (2d − 1)的深度卷积核一个1 x 1的point-wise卷积。
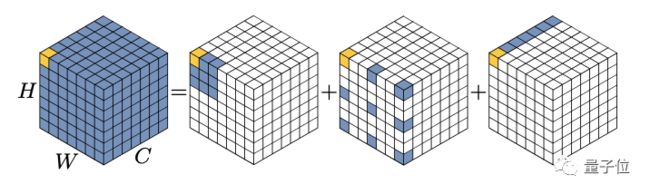 △c为通道(channel)
△c为通道(channel)
这样做,在捕捉到长距离依赖的同时节省了计算开销,进一步可以生成注意力图。
LKA方法不仅综合了卷积和自注意力的优势,还额外获得了通道适应性。
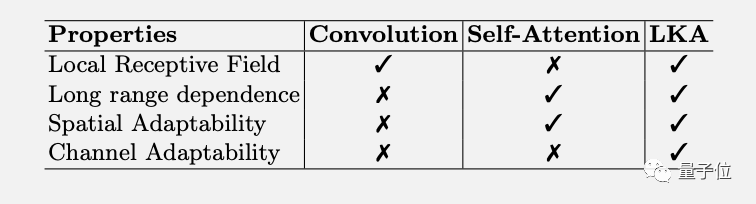
在CNN里,LKA方法与MobileNet的两部分拆解法类似,增加的深度扩张卷积可以捕获长距离依赖。
与ViT相比,解决了自注意力的二次复杂度对高分辨率图像计算代价太大的问题,
MLP架构中的gMLP也引入了注意力机制,但只能处理固定分辨率的图像,且只关注了全局特征,忽略了图像的局部结构。
从理论上来说,LKA方法综合了各方优势,同时克服了上述缺点。
那么,实际效果如何?
新Backbone刷榜三大任务
根据LKA方法设计的新Backbone网络VAN,延续了经典的四阶段设计,具体配置如下。
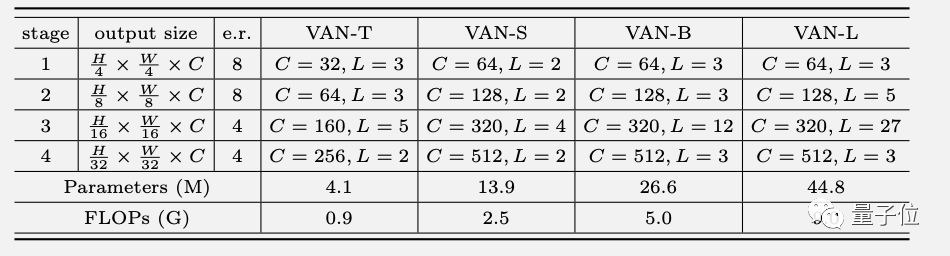
每个阶段的结构如图所示,其中下采样率由步长控制,CFF代表卷积前馈网络( convolutional feed-forward network)

假输入和输出拥有相等的宽高和通道数,可以算出计算复杂性。
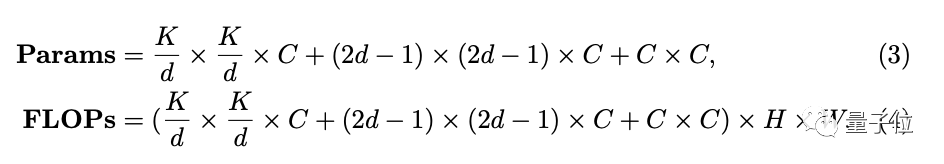
其中当卷积核大小(K)为21时,扩张间隔(d)取3可以让参数量最小,便以此为默认配置。
团队认为按此配置对于全局特征和局部特征的提取效果都比较理想。
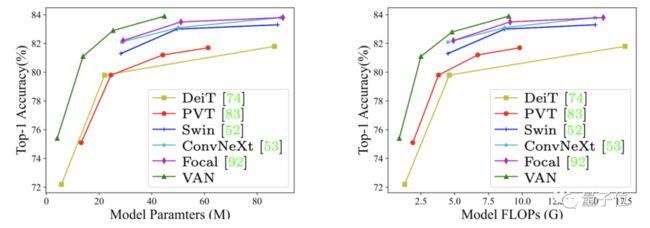
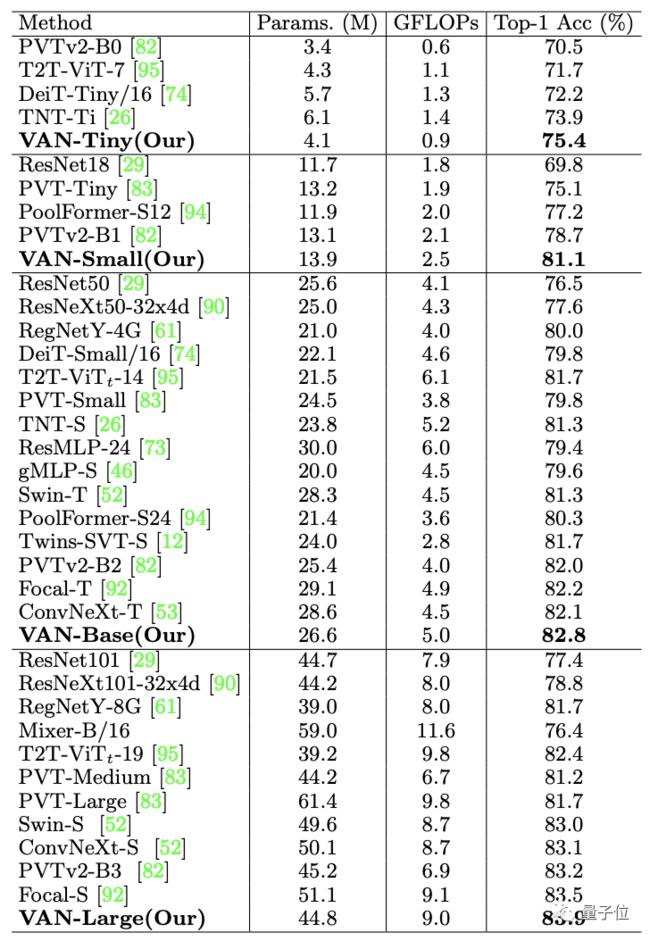
最终,在ImageNet上不同规模的VAN精度都超过了各类CNN、ViT和MLP。
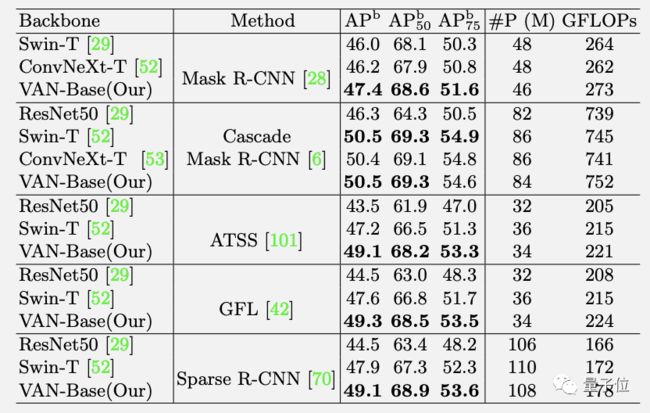
在COCO 2017目标检测任务上,以VAN为Backbone应用多种检测方法也都领先。
ADE20K语意分割任务上同样如此。
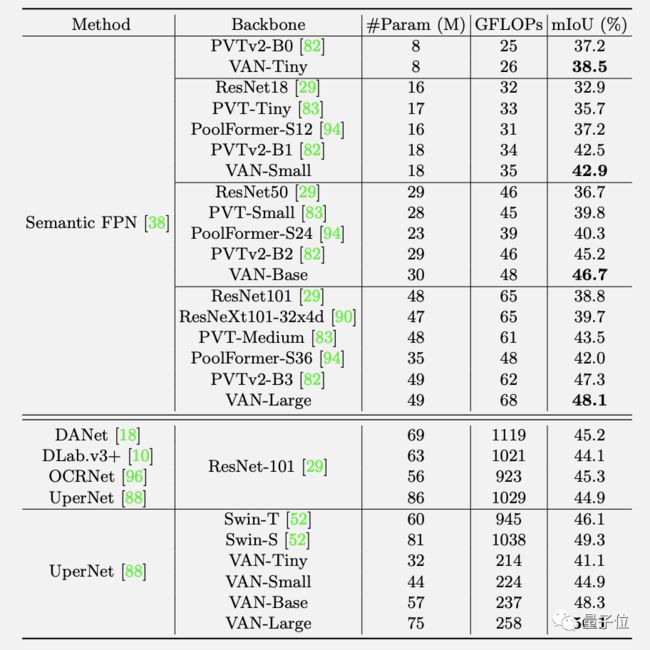
而且正如前文所述,VAN未经仔细打磨就已刷榜三大任务,后续还有提升空间。
对于今后的改进方向,团队表示可能会尝试更大的卷积核,引入来自Res2Net的多尺度结构,或者Inception中的多分支结构。
另外用VAN做图像自监督学习和迁移学习,甚至能否做NLP都有待后续探索。
作者介绍
这篇论文来自清华大学计算机系胡事民团队。
胡事民教授是清华计图框架团队的负责人,计图框架则是首个由中国高校开源的深度学习框架。

一作博士生国孟昊,现就读于清华大学计算机系,也是计图团队的成员。

这次论文的代码已经开源,并且提供了Pytorch版和计图框架两种版本。
该团队之前有一篇视觉注意力的综述,还成了arXiv上的爆款
配套的GitHub仓库视觉注意力论文大合集Awesome-Vision-Attentions也有1.2k星。
最后八卦一下,莫非是团队研究遍了各种视觉注意力机制后,碰撞出这个新的思路?
也是666了。
论文地址:
https://arxiv.org/abs/2202.09741
GitHub地址:
https://github.com/Visual-Attention-Network
Awesome-Vision-Attentions
https://github.com/MenghaoGuo/Awesome-Vision-Attentions