深度学习 | 双重注意力机制之CBAM
点击上方“算法与数据之美”,选择“置顶公众号”
更多精彩等你来!
之前我们分享了2017年的冠军图像分类模型SENet,今天给大家带来的这篇2018年发表在ECCV上的论文不仅考虑到了不同特征通道的重要性不一,还考虑到了同一个特征通道的不同位置的重要性程度。

也就是说既包含通道的注意力机制,又包含空间的注意力机制。相比于只关注通道的SENet,ConvolutionalBlock Attention Module (CBAM) 取得了更好的效果。

上图为整个CBAM的示意图,先是通过注意力机制模块,然后是空间注意力模块,对于两个模块先后顺序对模型性能的影响,本文作者也给出了实验的数据对比,先通道再空间要比先空间再通道以及通道和空间注意力模块并行的方式效果要略胜一筹。
那么这个通道注意力模块和空间注意力模块又是如何实现的呢?
通道注意力模块
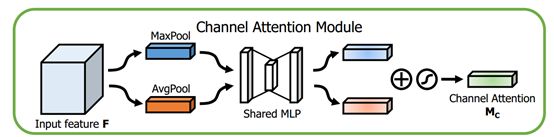
这个部分大体上和SENet的注意力模块相同,主要的区别是CBAM在S步采取了全局平均池化以及全局最大池化,两种不同的池化意味着提取的高层次特征更加丰富。接着在E步同样通过两个全连接层和相应的激活函数建模通道之间的相关性,合并两个输出得到各个特征通道的权重。最后,得到特征通道的权重之后,通过乘法逐通道加权到原来的特征上,完成在通道维度上的原始特征重标定。
空间注意力模块
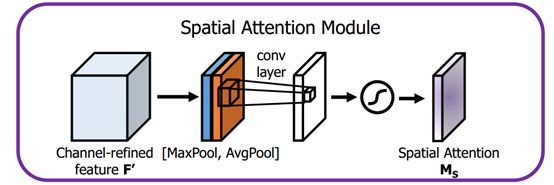
首先输入的是经过通道注意力模块的特征,同样利用了全局平均池化和全局最大池化,不同的是,这里是在通道这个维度上进行的操作,也就是说把所有输入通道池化成2个实数,由(h*w*c)形状的输入得到两个(h*w*1)的特征图。接着使用一个 7*7 的卷积核,卷积后形成新的(h*w*1)的特征图。最后也是相同的Scale操作,注意力模块特征与得到的新特征图相乘得到经过双重注意力调整的特征图。
Tensorflow 实现
光说不练假把式,同样的我们通过对论文的理解,对CBAM做一个简单的代码复现。input_x 表示输入的张量,reduction_axis 表示池化的维度,out_dim 表示输出的通道数目,ratio 表示缩小比例。张量的形状为[number,channel,h,w]。
def CBAM(input_x,reduction_axis,ratio,out_dim):
channel_attention_max=tf.reduce_max(input_x,reduction_axis,keep_dims=True)
channel_attention_avg=tf.reduce_mean(input_x,reduction_axis,keep_dims=True)
channel_attention_max=layers.fully_connected(layers.flatten(channel_attention_max),num_outputs=int(out_dim/ratio),
activation_fn=None, normalizer_fn=None,
weights_initializer=tf.random_normal_initializer(mean=0., stddev=0.01),
biases_initializer=tf.constant_initializer(0.))
channel_attention_max=tf.nn.relu(channel_attention_max)
channel_attention_max=layers.fully_connected(layers.flatten(channel_attention_max),num_outputs=out_dim,
activation_fn=None, normalizer_fn=None,
weights_initializer=tf.random_normal_initializer(mean=0., stddev=0.01),
biases_initializer=tf.constant_initializer(0.))
channel_attention_max=tf.reshape(channel_attention_max, [-1,out_dim,1,1])
channel_attention_avg=layers.fully_connected(layers.flatten(channel_attention_avg),num_outputs=int(out_dim/ratio),
activation_fn=None, normalizer_fn=None,
weights_initializer=tf.random_normal_initializer(mean=0., stddev=0.01),
biases_initializer=tf.constant_initializer(0.))
channel_attention_avg=tf.nn.relu(channel_attention_avg)
channel_attention_avg=layers.fully_connected(layers.flatten(channel_attention_avg),num_outputs=out_dim,
activation_fn=None, normalizer_fn=None,
weights_initializer=tf.random_normal_initializer(mean=0., stddev=0.01),
biases_initializer=tf.constant_initializer(0.))
channel_attention_avg=tf.reshape(channel_attention_avg, [-1,out_dim,1,1])
channel_attention=tf.nn.sigmoid(channel_attention_max+channel_attention_avg)
channel_refined_feature=input_x*channel_attention
spatial_attention_max=tf.reduce_max(input_x,axis=1,keep_dims=True)
spatial_attention_avg=tf.reduce_avg(input_x,axis=1,keep_dims=True)
spatial_attention=tf.concat([spatial_attention_max,spatial_attention_avg],axis=1)
spatial_attention=layers.conv2d(spatial_attention,num_outputs=out_dim, kernel_size=7)
spatial_attention=tf.nn.sigmoid(spatial_attention)
refined_feature=channel_refined_feature*spatial_attention
return refined_feature
往期精彩
深度学习 | SENet
数据可视化 | 2019中国最好学科排名
自动化篇 | 模糊匹配助力自动答题