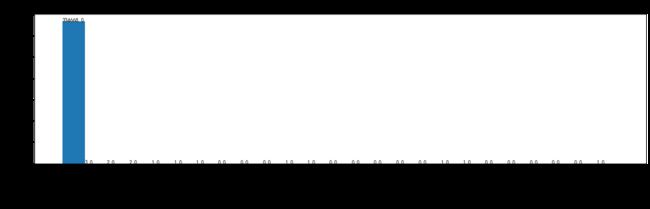
数据分布探索函数(可以直接调用)
在建模之前要对数据进行探索性分析,首先要对数据分布有一个大致了解。matplotlib里面有自带的hist()函数,直接data.hist(),全部特征的分布状态就能在一张画布上展示出来,对于一个样本量较小的数据集来说,非常方便(700多个样本,60几个特征)。比如这样:
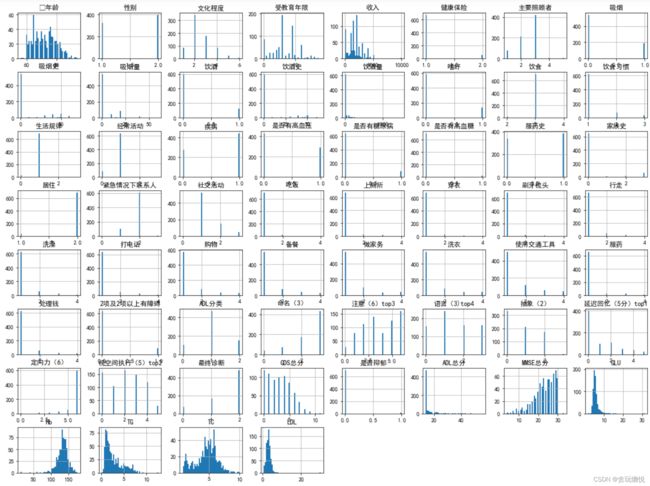
在一个样本量为300多万的数据集上面跑了一下,效果也还可以,优点是速度真的很快(对比后面自己写的那个函数)。但是真的没法看得很精细。比如这个数据集的几个特征分布图都有这样的特点(拿第一行第四幅图举例):大量数据集中在0附近,往后就空空如也,如果真的数据在后面的区间里没有分布,那为什么函数要画出来呢?
data.hist(bins=50,figsize=(20,15))
plt.show()
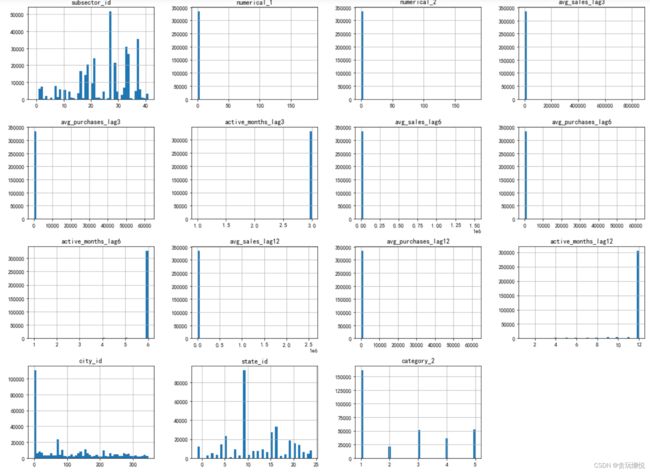 这个时候还是要结合.value_counts()函数来看一下:
这个时候还是要结合.value_counts()函数来看一下:
merchant['avg_sales_lag3'].value_counts().sort_index()
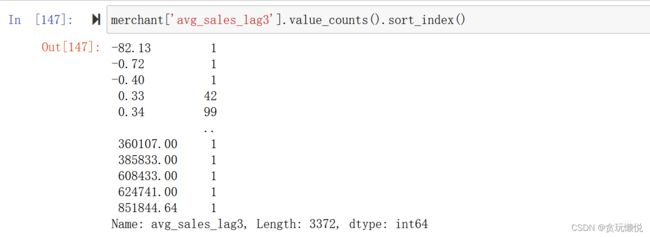 可以看到:数据不仅分布在大于0的区间,其实小于0的区间还是存在蛮多样本的,而当数值非常大的时候数据分布得很稀疏。“贫富差距”及其大得偏态分布样本。试想一下,如果这个变量存在一些缺失值,要怎样填补呢?如果直接用均值来填补的话,是不是很容易因为最大值太大而把数据分布拉偏呢?但当我用data.hist()方法来进行数据探索的时候,我真的因为对这个变量分布认识得不到位,而选择了不恰当的填补方式。
可以看到:数据不仅分布在大于0的区间,其实小于0的区间还是存在蛮多样本的,而当数值非常大的时候数据分布得很稀疏。“贫富差距”及其大得偏态分布样本。试想一下,如果这个变量存在一些缺失值,要怎样填补呢?如果直接用均值来填补的话,是不是很容易因为最大值太大而把数据分布拉偏呢?但当我用data.hist()方法来进行数据探索的时候,我真的因为对这个变量分布认识得不到位,而选择了不恰当的填补方式。
当数据量非常大时,容易出现的一个情况就是:有些连续性变量的取值范围很大、很散,而分类型变量索取的几个值之间距离也很大,这时候对分类变量画出的直方图也特别奇怪。
而且如果数据中有NaN、inf的情况下,直接data.hist()这种方法行不通,会报错。反而是把每个特征单独挑出来用plt.hist()绘制直方图不会报错。就直接把里面的NaN、inf忽略了,所以在数据没有处理得很干净的时候,直接使用data.hist()来粗略地探索数据分布比较麻烦,也不灵活。
所以就想到将数值型连续变量与分类型变量分开进行数据探索,对于连续数值型变量,可以用直方图。而对于分类型变量,可以用条形图来呈现大致分布。
下面是对于这个功能编写的一个自定义函数,需要输入的参数有:
| 参数 | 作用 |
|---|---|
| data | dataframe形式的数据集 |
| variablet | 特征名称,得是字符串 |
| va_type | 两个选择:‘numeric’时对数值型变量绘制直方图,‘category’时对分类型变量绘制条形图 |
def data_distribution_explore(data,variable,va_type):
if va_type=='numeric':
distri=data[variable].values.tolist()
plt.figure(figsize=(20,5))
nums,bins,patches = plt.hist(distri,bins=25)
plt.xticks(bins,bins)
plt.xticks(rotation=45)
for num,bin in zip(nums,bins):
plt.annotate(num,xy=(bin,num),xytext=(bin+1.5,num+0.5))
plt.title(variable,fontsize=20)
# plt.xlabel(variable,fontsize=20)
plt.ylabel('count',fontsize=20)
if va_type =='category':
distri=data[variable].value_counts().sort_index()
plt.figure(figsize=(20,5))
bar=plt.bar(distri.index, distri.values, 0.6)
for rect in bar:
height = rect.get_height()
plt.annotate('{}'.format(height),
xy=(rect.get_x() + rect.get_width() / 2, height),
xytext=(0, 0.8),#柱子上方距离
textcoords="offset points",
ha='center', va='bottom')
plt.title(variable,fontsize=20)
# plt.xlabel(variable,fontsize=20)
plt.ylabel('count',fontsize=20)
plt.show()
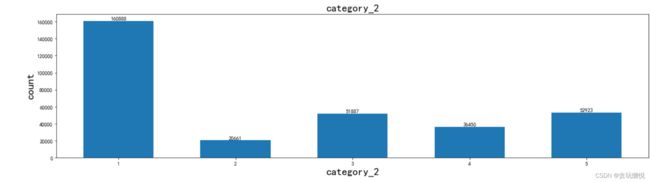
应用效果如下:
data_distribution_explore(merchant,'category_2',va_type='category')
for i in ['avg_sales_lag3','avg_sales_lag6','avg_sales_lag12']:
data_distribution_explore(merchant,i,va_type='numeric')