误差反向传播和深度学习相关技巧总结
误差反向传播和深度学习相关技巧总结
文章目录
- 误差反向传播和深度学习相关技巧总结
-
- 一、误差反向传播法
-
- 1.几个问题
- 2.简单层(加法、乘法层)、激活函数层、Affine/softmax层的实现
- 3.误差反向传播的实现
- 二、与学习相关的技巧
-
- 1.关于参数的更新
- 2.权重的初始值
- 3、其它与之相关的学习技巧
- 三、总结
一、误差反向传播法
1.几个问题
- 误差反向传播的目的是什么?
为了能够更高效的计算权重参数的梯度方法,数值微分虽然很好理解,但是它的计算量确实很大,执行效率很低。 - 反向传播的理论依据?
首先要明白的是求梯度,就是求导数。传递局部导数原理成立的原理就是基于链式法则
2.简单层(加法、乘法层)、激活函数层、Affine/softmax层的实现
说明:通过计算图,人们可以直观地把握整个计算过程,计算图的节点是由局部构成的,局部计算构成全局计算。建议自己动手手推BP(反向传播)神经网络!注:以下代码和内容都是学习《深度学习入门》一书的学习笔记。
- 加法层和乘法层的实现比较简单,加法层反向传播中,只需要将上游的值原封不动的传给下游;乘法层的反向传播中需要将上游的值乘以正向传播的输入信号的“翻转值”。以下是python实现的代码:
import numpy as np
class Addlayer:#加法层
def __init__(self):
pass
def forward(self,x,y):
out=x+y
return out
def backward(self,dout):
dx=dout*1
dy=dout*1
return dx,dy
class Mulayer:#乘法层
def __init__(self):
self.x=None
self.y=None
def forward(self,x,y):
self.x=x
self.y=y
out =x*y
return out
def backward(self,dout):
dx=dout*self.y
dy=dout*self.x
return dx,dy
- ReLU和Sigmoid层的实现
由于ReLu的计算图比较简单,以下展示的是Sigmoid的计算图,建议多动手去推导这个过程

熟悉上面这个过程之后,以后就只要关注下面这个输入和输出就OK了。

以下为python代码实现方式
class Sigmoid:
def __init__(self):
self.out = None
def forward(self, x):
out = sigmoid(x)
self.out = out
return out
def backward(self, dout):
dx = dout * (1.0 - self.out) * self.out
return dx
- Affine层的实现
Affine层就是算层与层之间的点积的,注意算点积的反向传播的时候要乘以输入信号的转置。以下为Affine的计算图
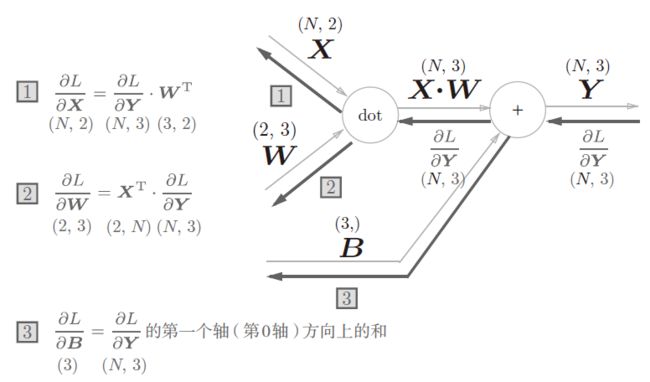
以下为Affine层的python代码实现
class Affine:
def __init__(self,W,b):
self.W=W
self.b=b
self.X = None
self.dW=None
self.db=None
def forward(self,x):
self.x=x
out=np.dot(x,self.W)+self.b
return out
def backward(self,dout):
self.dx = np.dot(dout , self.W.T)
self.dW=np.dot(self.x.T,dout)
self.db=np.sum(dout,axis=0)#为什么是求和?
return dx
问题:为什么Affine层反向传播过程中,db是对dout的列求和?
参见损失值对b的梯度
- Softmax-With-Loss层的实现
这里的话就是Softmax层和损失函数层(下面用交叉熵误差)的反向传播,下面先介绍Softmax层的计算公式和计算图

Softmax输出层的计算图如下,反向传播只标注了a1->y1这一条神经网络,其它的同理。推理过程中需要注意的是"/"节点,"X"节点以及"EXP"节点的反向传播,这里是要用一个整体的代换。

损失函数(交叉熵误差)的计算图如下
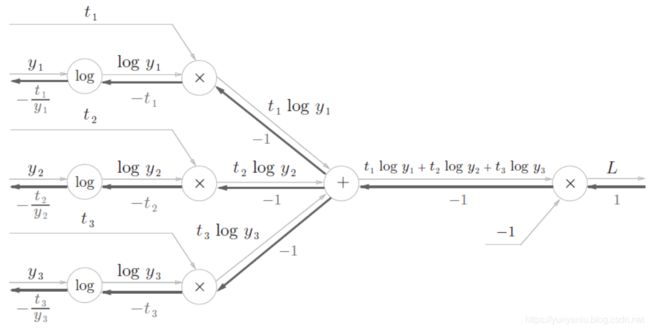
弄懂了上面这些细节之后,以后就只需要关注经过一个层的输入和输出就可以了,以下是Softmax-With-loss的简洁版,其中的ai是神经网络推理过程的得分,ti是正确解标签。

以下是Softmax-with-loss层的python代码实现
class SoftmaxWithLoss:
def __init__(self):
self.loss = None
self.y = None # softmax的输出
self.t = None # 监督数据
def forward(self, x, t):
self.t = t
self.y = softmax(x)
self.loss = cross_entropy_error(self.y, self.t)
return self.loss
def backward(self, dout=1):
batch_size = self.t.shape[0]
if self.t.size == self.y.size: # 监督数据是one-hot-vector的情况
# test=self.y - self.t
dx = (self.y - self.t) / batch_size
else:
dx = self.y.copy()
dx[np.arange(batch_size), self.t] -= 1
dx = dx / batch_size#为什么要除以batch_size的大小?
return dx
3.误差反向传播的实现
- 以下为主要的python源代码
# coding: utf-8
import sys, os
sys.path.append(os.pardir)
import timejiqiao
import numpy as np
from dataset.mnist import load_mnist
from two_layer_net import TwoLayerNet
from common.util import smooth_curve
import matplotlib.pyplot as plt
start = time.time()
# 读入数据
(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True, one_hot_label=True)
network = TwoLayerNet(input_size=784, hidden_size=50, output_sizejiqiao=10)
iters_num = 10000#迭代次数
train_size = x_train.shape[0]
batch_size = 100jiqiao
learning_rate = 0.1jiqiao
jiqiao
train_loss_list = []
train_acc_list = []
test_acc_list = []
iter_per_epoch = max(train_size / batch_size, 1)
for i in range(iters_num):
batch_mask = np.random.choice(train_size, batch_size)#随机选择了100组数据
x_batch = x_train[batch_mask]
t_batch = t_train[batch_mask]
# 梯度
# grad = network.numerical_gradient(x_batch, t_batch)
grad = network.gradient(x_batch, t_batch)
# 更新
for key in ('W1', 'b1', 'W2', 'b2'):
network.params[key] -= learning_rate * grad[key]
loss = network.loss(x_batch, t_batch)
train_loss_list.append(loss)
if i % iter_per_epoch == 0:
train_acc = network.accuracy(x_train, t_train)
test_acc = network.accuracy(x_test, t_test)
train_acc_list.append(train_acc)
test_acc_list.append(test_acc)
print(train_acc, test_acc)
print(len(train_loss_list))
x=np.arange(iters_num)
plt.plot(x, smooth_curve(train_loss_list))
plt.xlabel("iterations")
plt.ylabel("loss")
plt.title("gradient")
# plt.title("numerical_gradient")
# plt.legend()
plt.show()
end = time.time()
print("time: ",str(end-start)+"s ")
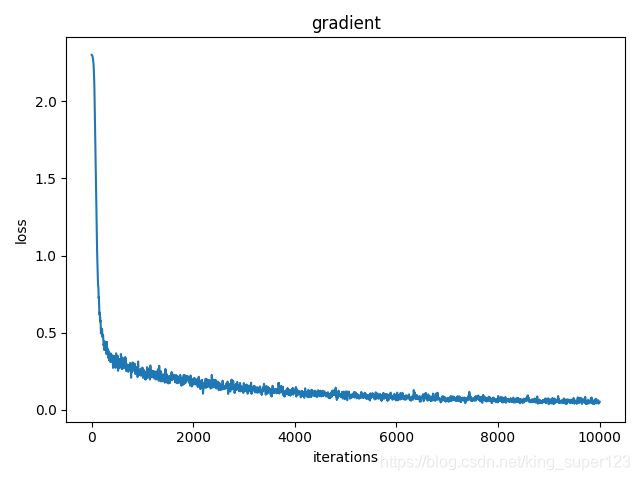
- 以下为实验结果,可以看到整个代码的运行时间只要21.7s,速度比数值微分求梯度的时间快了不知道多少倍(反正用数值微分求梯度的运行时间在我目前这台机器上我是没跑出来。)说明用反向传播的方法更优。

经过1万次学习之后,损失值减小了许多,接近0了。
二、与学习相关的技巧
1.关于参数的更新
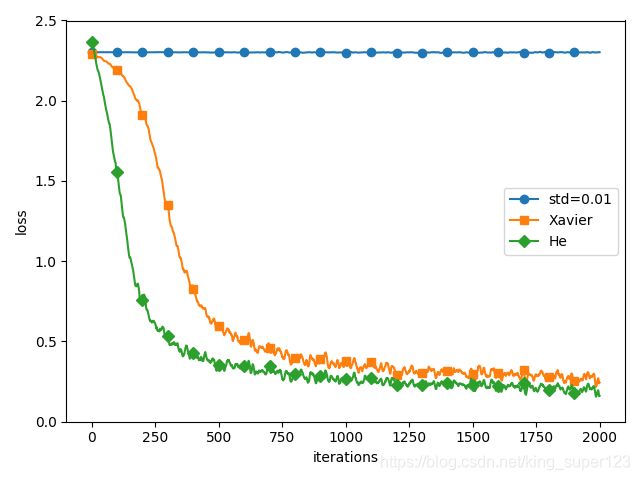
- 这里介绍了SGD、Momentum、AdaGrad、Adam四种optimizer方式,首先来看一下这四种跟新参数的优化方式在mnist数据集上的实验结果。
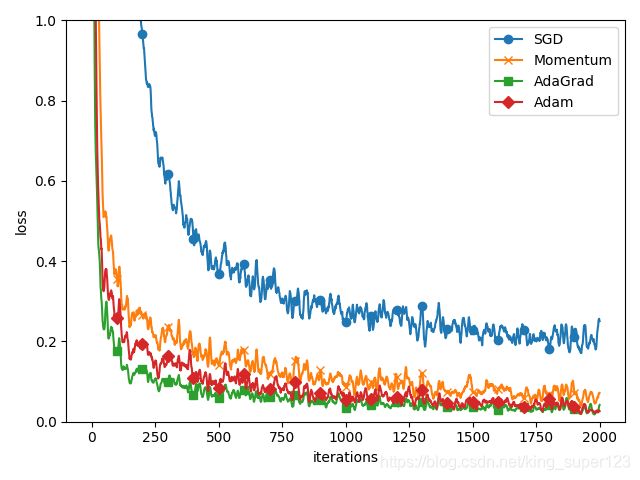
我们可看到SGD在一千次学习之后,损失函数的值保持在0.2-0.3之间,损失函数下降得慢且保持一种"之"字型的形状在下降,这就使SGD的学习效率变得很低。思考SGD为什么会呈"之"字型?
-> 因为SGD在某一个方向上下降得很快(比如y方向上),在另一个方向上下降得很慢(比如x轴),这就会造成SGD参数的更新造成一定的波动,进而会影响损失函数的更新。 - 对于其它三种优化算法,这里不作太多的说明,有兴趣可以了解Adam详解
2.权重的初始值
- 思考一个问题? -> 可以将权重初识值设为0?或者可以将所有权重值设成一样的值吗?
–>>>答案显示然是不能的,因为假如所有的权重都是一样的,在正向传播中,传递给下一层的值都是相同的,这就意味着在反向传播中,同一层的权重会更新相同的值,那么就使神经网络拥有许多不同的权重丧失了意义。(防止权重"权重均一化",随机生成初始值) - 第二个问题?->什么样的权重分布才能使神经网络的学习不会出现梯度消失?看下面的这照实验图片。这个是使用了sigmoid激活函数,且权重的标准差为0.01.
w = np.random.randn(node_num, node_num) * 1

从上图中可以看出大多数数据会偏向0和1的情况,所以随着学习的不断进行,反向传播的值会不断减小,最终会消失,这个就叫做梯度消失?->怎么样解决梯度消失,更换激活函数或者更改权重的标准差
若改变上面语句为
w = np.random.randn(node_num, node_num) * np.sqrt(2.0 / node_num)
实验结果就为如下图所示,这里做了仅仅是将权重的初始值使用标准差为1/(根号n)的高斯分布进行初始化。
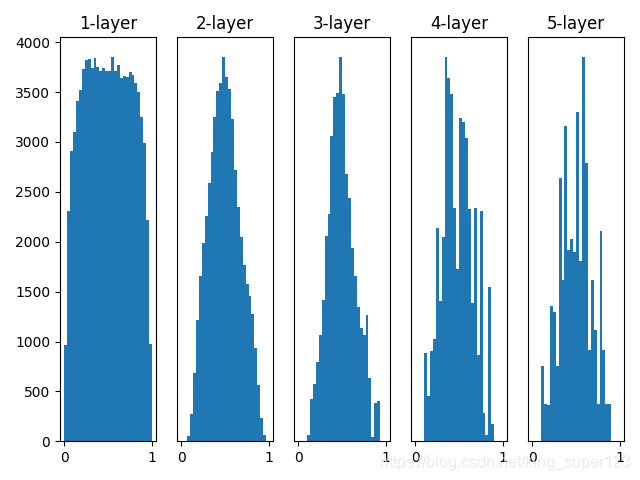
下面,这里展示基于std=0.01,Xavier初始值、he初始值(激活函数使用ReLU函数、标准差为根号2/n)的训练数据比较。
3、其它与之相关的学习技巧
- Batch Normalization
Batch Normalization 是通过在Affine层之后强制的调整激活之的分布,使激活值拥有适当的广度。
优点:
1.不仅仅极大提升了训练速度,收敛过程大大加快;
2.还能增加分类效果,一种解释是这是类似于Dropout的一种防止过拟合的正则化表达方式,所以不用Dropout也能达到相当的效果;
3.另外调参过程也简单多了,对于初始化要求没那么高,而且可以使用大的学习率等
用数学式表达如下:

- 过拟合
原因:
-
训练集的数量级和模型的复杂度不匹配。训练集的数量级要小于模型的复杂度;
-
训练集和测试集特征分布不一致;
-
样本里的噪音数据干扰过大,大到模型过分记住了噪音特征,反而忽略了真实的输入输出间的关系;
-
权值学习迭代次数足够多(Overtraining),拟合了训练数据中的噪声和训练样例中没有代表性的特征
方法-> 权值衰减(在学习的过程中对打的权重进行惩罚)
- Dropout(作为抑制过拟合的方法)

三、总结
通过前六章的学习,大致明白了神经网络的学习层次,以及各种优化的方法,最后得出一个结论是应该多动手去算,最底层就是数学推导的过程,多想想为什么?换一种方式可不 可以?