初学数据挖掘——数据探索(七):python中主要的数据探索函数之常用统计特征函数
前面已经提过:python中主要用于数据探索的库是pandas(数据分析)和matplotlib(数据可视化)。
了解详情可见:Python中的数据可视化工具与方法——常用的数据分析包numpy、pandas、statistics的理解实现和可视化工具matplotlib的使用
pandas中提供了大量统计特征函数和统计绘图函数,因绘图函数依赖于matplotlib,所以往往会与matplotlib结合使用。
pandas常用统计特征函数
1、sum()
计算数据样本的总和(按列计算)
语法:sum(iterable[, start])
其中,iterable – 可迭代对象,如:列表、元组、集合;start – 指定相加的参数,如果没有设置这个值,默认为0。
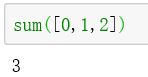
sum([0,1,2])
sum((2, 3, 4), 1) # 元组计算总和后再加 1

sum([0,1,2,3,4], 2) # 列表计算总和后再加 2

2、mean()
计算数据样本的算术平均数;
mean()函数的参数很多,但是常用的就两种:
(1)直接对整个数组求平局;
(2)加上axis参数对不同的轴进行平均运算
注意:mean()函数来自numpy包,需要先安装下载numpy包:
pip install numpy
import numpy as np
ary = np.array([[1, 3], [2, 4]]) #创建一个二维数组
print('ary:\n',ary)
print('所有元素的平均值:',np.mean(ary)) #直接调用mean函数计算所有元素的平均值
print('每一列的平均值:',np.mean(ary, axis=0)) #保留横轴,算每一列的平均值
print('每一行的平均值:',np.mean(ary, axis=1)) #保留纵轴,算每一行的平均值

3、var()
计算数据样本的标准差
4、std()
计算数据样本的标准差
5、corr()
计算数据样本的相关系数矩阵
使用格式:
D.corr(method='pearson')
以上格式中:D(样本)可为DateFrame,返回相关系数矩阵。method参数指定计算方法,支持pearson(皮尔森相关系数,默认选项)、kendall(肯德尔系数)、spearman(斯皮尔曼系数)
S1.corr(S2,method='pearson')
以上格式中:S1、S2均为series(序列),这种格式用于指定计算两个series之间的相关系数。
实例:
计算两个列向量的相关系数,采用spearman方法。
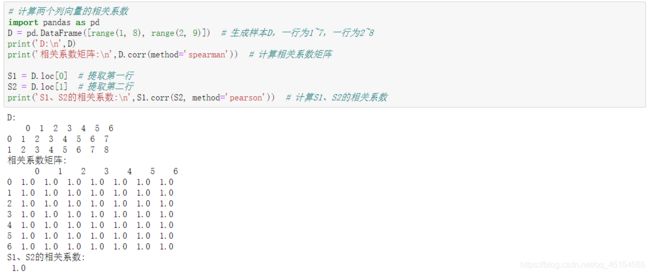
# 计算两个列向量的相关系数
import pandas as pd
D = pd.DataFrame([range(1, 8), range(2, 9)]) # 生成样本D,一行为1~7,一行为2~8
print('D:\n',D)
print('相关系数矩阵:\n',D.corr(method='spearman')) # 计算相关系数矩阵
S1 = D.loc[0] # 提取第一行
S2 = D.loc[1] # 提取第二行
print('S1、S2的相关系数:\n',S1.corr(S2, method='pearson')) # 计算S1、S2的相关系数
6、cov()
计算数据样本的协方差矩阵。
使用格式:
D.cov()
以上格式中:D(样本)可为DateFrame,返回协方差矩阵。
S1.cov(S2)
以上格式中:S1、S2均为series(序列),这种格式用于指定计算两个series之间的协方差。
实例:
计算6*5随机矩阵的协方差矩阵
# 计算6×5随机矩阵的协方差矩阵
import numpy as np
D = pd.DataFrame(np.random.randn(6, 5)) # 产生6×5随机矩阵
print('协方差矩阵:\n',D.cov()) # 计算协方差矩阵
print('S1、S2的协方差:\n',D[0].cov(D[1])) # 计算第一列和第二列的协方差

7、skew()
计算数据样本值的偏度(三阶矩)。
使用格式:
D.skew()
以上格式中:D(样本)可为DateFrame或series,用来计算样本D的偏度(三阶矩)。
实例:
计算6*5随机矩阵的偏度(三阶矩):
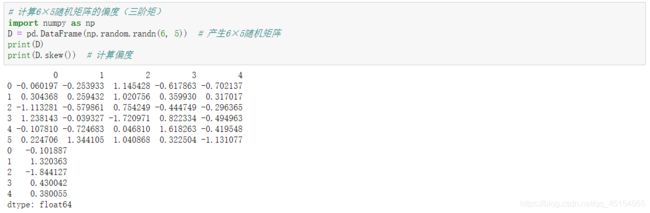
# 计算6×5随机矩阵的偏度(三阶矩)
import numpy as np
D = pd.DataFrame(np.random.randn(6, 5)) # 产生6×5随机矩阵
print(D)
print(D.skew()) # 计算偏度
8、kurt()
计算数据样本值的峰度(四阶矩)
使用格式:
D.skew()
以上格式中:D(样本)可为DateFrame或series,用来计算样本D的峰度(四阶矩)。
实例:
计算6*5随机矩阵的峰度(四阶矩):
# 计算6×5随机矩阵的峰度(四阶矩)
import numpy as np
D = pd.DataFrame(np.random.randn(6, 5)) # 产生6×5随机矩阵
print(D)
print(D.kurt()) # 计算峰度
9、describe()
显示出对样本的基本描述(一些基本统计量),包括均值、标准差、最大值、最小值、分位数等。
使用格式:
D.describe()
以上格式中:D(样本)可为DateFrame或series,用来显示出对样本的基本描述(一些基本统计量)。
D.describe()括号中可以带一些参数,如percentiles = [0.2,0.4,0.6,0.8]就是指定只计算0.2、0.4、0.6、0.8分位数,而不是默认的1/4、1/2、3/4分位数。
实例:
展示6*5随机矩阵的基本统计量:
# 6×5随机矩阵的describe
import numpy as np
D = pd.DataFrame(np.random.randn(6, 5)) # 产生6×5随机矩阵
print(D.describe())
