基于教与学优化算法的函数寻优算法
文章目录
- 一、理论基础
-
- 1、“教”阶段
- 2、“学”阶段
- 3、算法流程图
- 二、实验结果及分析
- 三、参考文献
一、理论基础
教与学优化算法(Teaching–Learning-Based Optimization, TLBO)是由Rao等提出的新型群智能算法,受老师指导学生和学生间互助学习的启发而产生,工作过程分为两部分:第一部分为“教阶段”,第二部分为“学阶段”。“教阶段”意味着向教师(当前最优解)学习,“学阶段”意味着通过学习者(所有个体)之间的互动进行学习。
1、“教”阶段
老师为最优适应度个体,学生通过向老师学习提高成绩,其数学表达式为: x n e w i = x o l d i − r i ⋅ ( x t e a c h e r − T F ⋅ x m ) (1) x_{new}^i=x_{old}^i-r_i\cdot(x_{teacher}-TF\cdot x_m)\tag{1} xnewi=xoldi−ri⋅(xteacher−TF⋅xm)(1) x m = 1 n ∑ i = 1 n x i (2) x_m=\frac1n\sum_{i=1}^nx_i\tag{2} xm=n1i=1∑nxi(2)其中, x n e w i x_{new}^i xnewi为第 i i i个更新后的学生个体; x o l d i x_{old}^i xoldi为第 i i i个当前学生个体; r i r_i ri为 [ 0 , 1 ] [0,1] [0,1]间的随机数; T F TF TF为 [ 1 , 2 ] [1,2] [1,2]之间的随机整数; x m x_m xm为种群均值。
2、“学”阶段
学阶段采用随机选择学习对象的方式实现学生间的互助学习以进一步提高成绩,可表示为: x n e w i = { x o l d i − r 1 ⋅ ( x i − x j ) , f ( x i ) < f ( x j ) x o l d i − r 1 ⋅ ( x j − x i ) , f ( x i ) > f ( x j ) (3) x_{new}^i=\begin{dcases}x_{old}^i-r_1\cdot(x^i-x^j),\quad f(x^i)
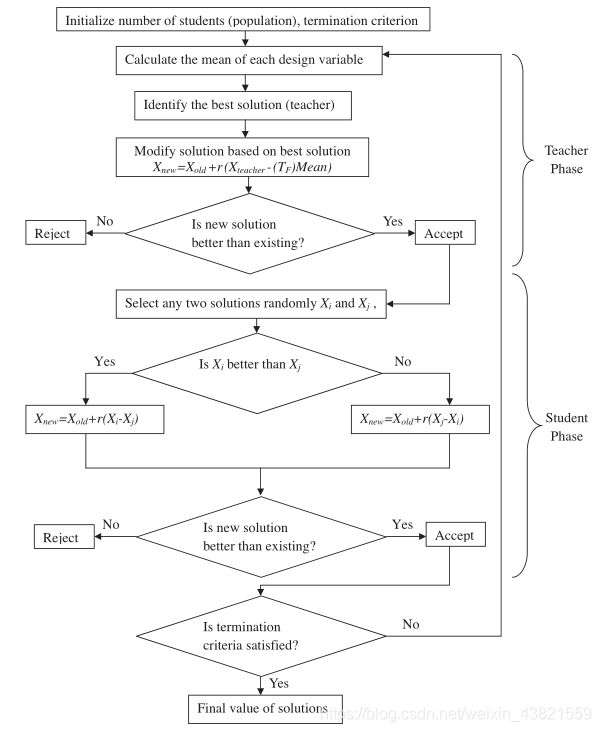
3、算法流程图
TLBO算法流程图如图1所示。
二、实验结果及分析
将TLBO与樽海鞘群算法(SSA)和灰狼优化算法(GWO)进行对比,测试函数如表1所示。设置种群规模为30,最大迭代次数为1000,每个算法独立运算30次。

结果显示如下:



函数:F1
SSA:平均值:1.2871e-08,标准差:2.6866e-09,最差值: 1.808e-08,最优值:8.7744e-09
GWO:平均值:7.0078e-59,标准差:1.9019e-58,最差值: 1.0487e-57,最优值:8.0281e-62
TLBO:平均值:1.6844e-170,标准差:0,最差值: 1.6809e-169,最优值:9.9607e-174
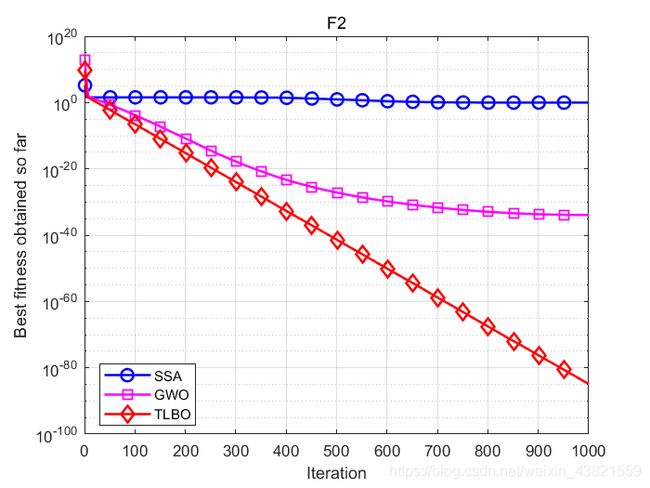
函数:F2
SSA:平均值:0.96884,标准差:0.89007,最差值: 3.2827,最优值:0.064748
GWO:平均值:1.2326e-34,标准差:2.3492e-34,最差值: 1.3183e-33,最优值:9.0007e-36
TLBO:平均值:1.2691e-85,标准差:2.3615e-85,最差值: 1.2337e-84,最优值:6.9339e-87
函数:F3
SSA:平均值:247.8962,标准差:163.9269,最差值: 766.6576,最优值:68.0242
GWO:平均值:1.5514e-14,标准差:8.1361e-14,最差值: 4.4626e-13,最优值:9.3569e-19
TLBO:平均值:1.976e-40,标准差:4.0853e-40,最差值: 1.9064e-39,最优值:3.6016e-44
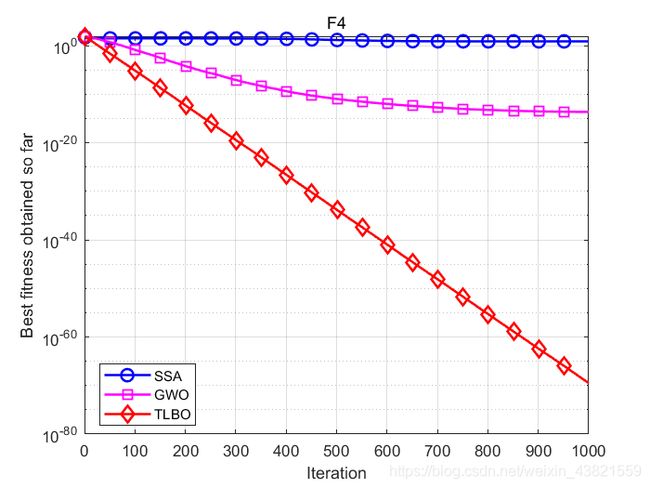
函数:F4
SSA:平均值:7.7903,标准差:3.4597,最差值: 16.155,最优值:3.0924
GWO:平均值:2.3051e-14,标准差:2.9416e-14,最差值: 1.1617e-13,最优值:1.6626e-16
TLBO:平均值:3.2478e-70,标准差:3.329e-70,最差值: 1.2316e-69,最优值:4.2343e-71
函数:F5
SSA:平均值:0.10189,标准差:0.033475,最差值: 0.16509,最优值:0.043386
GWO:平均值:0.00075226,标准差:0.00040731,最差值: 0.0018118,最优值:0.00024967
TLBO:平均值:0.00062077,标准差:0.00023225,最差值: 0.0012836,最优值:0.00023272
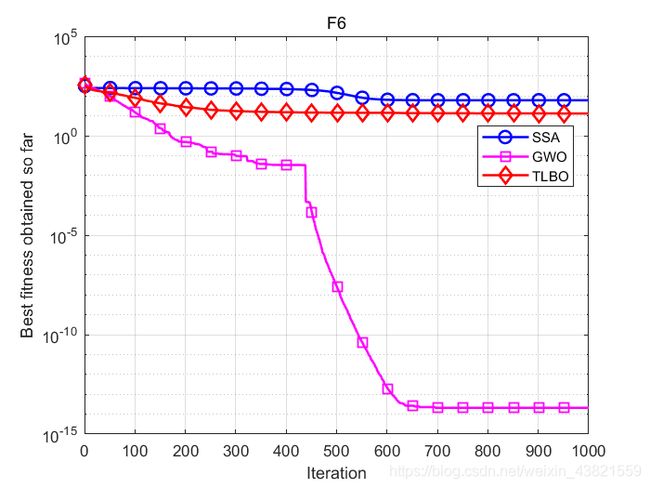
函数:F6
SSA:平均值:60.5266,标准差:19.6333,最差值: 98.5006,最优值:23.879
GWO:平均值:2.0843e-14,标准差:4.597e-14,最差值: 2.2737e-13,最优值:0
TLBO:平均值:13.0691,标准差:6.8883,最差值: 32.7931,最优值:0
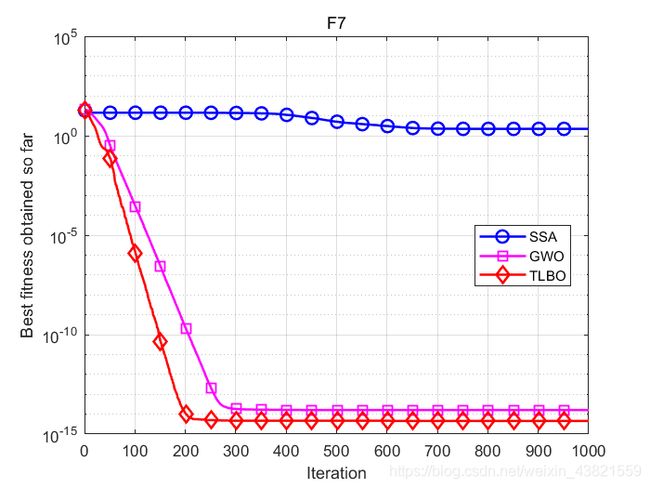
函数:F7
SSA:平均值:2.2055,标准差:1.0388,最差值: 5.9781,最优值:1.9879e-05
GWO:平均值:1.6283e-14,标准差:2.9991e-15,最差值: 2.2204e-14,最优值:1.1546e-14
TLBO:平均值:4.5593e-15,标准差:6.4863e-16,最差值: 7.9936e-15,最优值:4.4409e-15
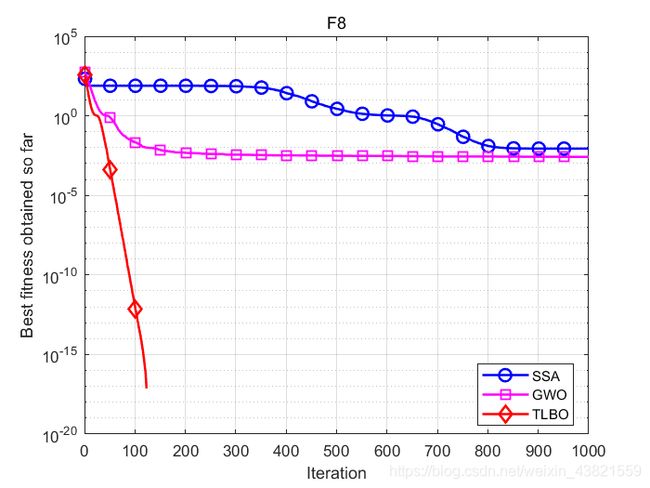
函数:F8
SSA:平均值:0.0086958,标准差:0.010707,最差值: 0.034458,最优值:2.732e-08
GWO:平均值:0.0026423,标准差:0.0057546,最差值: 0.021293,最优值:0
TLBO:平均值:0,标准差:0,最差值: 0,最优值:0
结果表明,TLBO除了在F6表现不佳之外,其余七个测试函数均优于其他智能算法,这说明TLBO算法具有很好的寻优能力。
三、参考文献
[1] Rao R V, Savsani V J, Vakharia D P. Teaching–Learning-Based Optimization: An optimization method for continuous non-linear large scale problems[J]. Information Sciences, 2012, 183(1): 1-15.
[2] 孙凤山, 范孟豹, 曹丙花, 叶波, 刘林. 基于混沌映射与差分进化自适应教与学优化算法的太赫兹图像增强模型[J]. 仪器仪表学报, 2021, 42(4): 92-101.