复习笔记5-nginx、rabbitmq、redis、jenkins、Docker、ELK、日志、Hadoop
ActiveMQ RabbitMQ Kafka(大数据) RocketMQ(支持分布式)
参考 E:\work\资料\MQ
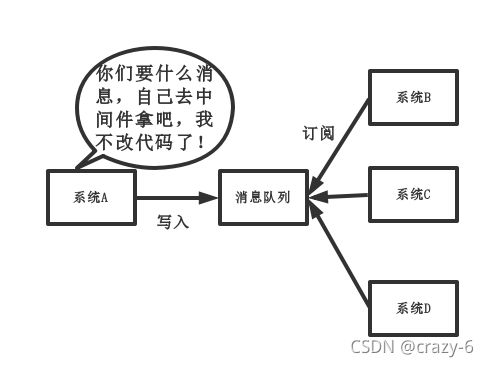
消息队列使用场景:核心的有 3 个:解耦、异步、削峰。
解耦:BCD 都要从 A 拿数据,A 代码写死调用 BCD,如果新来 E 系统,E 也要 A 中数据,那么A 要改代码,用消息队列即可解决,让他们自己从队列中取
异步: 用户注册要短信邮件通知,可以用队列来不用等短信和邮件的结果,异步处理高效
削峰: 并发量大的时候,所有的请求直接怼到数据库,造成数据库崩掉,可以放队列慢慢处理
缺点:增加了一个系统,复杂性提高、消息重复消费问题,分布式事务问题
参考 E:\work\资料\MQ\RabbitMQ\day09_RabbitMQ.docx
参考 D:\6.在职加薪基础01\学成在线项目\5.消息中间件RabbitMQ\讲义\学成在线-RabbitMQ研究v1.1.pdf
1.RabbitMq 几种工作模式
http://127.0.0.1:15672 guest/guest
消费模式
1、自动模式-消费者从消息队列获取消息后,服务端就认为该消息已经成功消费。
2、手动模式(ack机制)-消费者从消息队列获取消息后,服务端并没有标记为成功消费,消费者成功消费后需要将状态返回到服务端
routing key :生产者发送消息时绑定了的 key
binding key:消费者的队列和交换机的绑定的 key
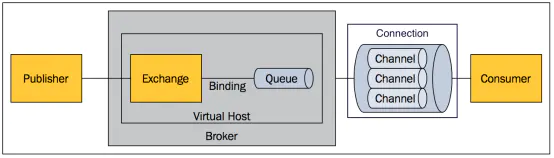
消息发布接收流程:
-----发送消息-----
1、生产者和 Broker 建立TCP连接。
2、生产者和 Broker 建立通道。
3、生产者通过通道消息发送给 Broker,由Exchange 将消息进行转发。
4、Exchange 将消息转发到指定的Queue(队列)
----接收消息-----
1、消费者和 Broker 建立TCP连接
2、消费者和 Broker 建立通道
3、消费者监听指定的 Queue(队列)
4、当有消息到达 Queue 时 Broker 默认将消息推送给消费者。
5、消费者接收到消息
总结:
1、简单模式和 work 模式的消息只能被一个消费者消费,且不用交换机
2、订阅模式、路由模式、主题模式,需要交换机且消息可被多个消费者消费
3、订阅模式不用路由键,且所有绑定的队列都可以收到消息
4、路由模式有路由键,消息中的 RoutingKey(路由键)和交换器与队列之间的BindingKey(绑定键)完全匹配时,消息才发给队列
5、主题模式:模糊匹配,将消息路由到路由键与绑定键相匹配的队列中,* 号匹配一个单词,# 号可以匹配0个或者多个词
rabbitmq 结构
下图红色为队列、蓝色为交换机
1、简单模式

一个生产者,一个消费者(声明队列,往里面塞值取值即可)
2、work 模式

一个生产者,多个消费者,每个消费者获取到的消息唯一。(声明队列,往里面塞值取值即可)
简单模式和 work 模式都是一个消息只能被消费一次
1、一条消息只会被一个消费者接收;
2、rabbit 轮询将消息平均发送给消费者的;
3、消费者在处理完某条消息后,才会收到下一条消息。
注意:交换机种类分为 扇型交换机(fanout)、直连交换机(direct)、主题交换机(topic),
3、发布/订阅模式 Publish/Subscribe(fanout 分列)

1、每个消费者监听自己的队列。
2、生产者将消息发给交换机,交换机将消息转发到绑定此交换机的所有队列,每个绑定交换机的队列都将接收
到消息,【一条消息可被多个消费者消费】
1、publish/subscribe (发布订阅)与 work queues 的区别
1、work queues 不用定义交换机,而 publish/subscribe 需要定义交换机。
2、发布订阅模式 的生产方是面向交换机发消息,work queues 的生产方面向队列发送消息【底层用默认交机】。
3、发布订阅模式 需要设置队列和交换机的绑定,work queues不用,实质上 work queues 将队列绑定到默认的交换机
相同点:
所以两者实现的发布/订阅的效果是一样的,多个消费端监听同一个队列不会重复消费消息。
实际工作一般用 publish/subscribe,发布订阅模式比工作队列模式更强大,且发布订阅模式可以指定自己专用的交换机。
4、路由模式(direct)

1、每个消费者监听自己的队列,并且设置 routingkey。
2、生产者将消息发给交换机,由交换机根据 routingkey 来转发消息到指定的队列。
Routing模式和Publish/subscibe有啥区别?
路由模式要求队列在绑定交换机时要指定 routingkey ,消息会转发到符合 routingkey 的队列
5、主题模式(topic)

死信队列
死信队列&死信交换器:DLX 全称(Dead-Letter-Exchange),称之为死信交换器,当消息变成一个死信之后,如果这个消息所在的队列存在 x-dead-letter-exchange 参数,那么它会被发送到 x-dead-letter-exchange 对应值的交换器上,这个交换器就称之为死信交换器,与这个死信交换器绑定的队列就是死信队列。
死信消息:
消息被拒绝(Basic.Reject或Basic.Nack)并且设置 requeue 参数的值为 false
消息过期了
队列达到最大的长度
过期消息:
1.对队列进行设置,这种设置后,该队列中所有的消息都存在相同的过期时间,
2.通过对消息本身进行设置,每条消息的过期时间都不一样。如同时使用这2种方法,以时间小的那个数值为准。
当消息达到过期时间还没有被消费,就成为了一个 死信消息。
队列设置:在队列申明的时候使用 x-message-ttl 参数,单位为 毫秒
单个消息设置:是设置消息属性的 expiration 参数的值,单位为 毫秒
延时队列
rabbitmq 中不存在延时队列,但可以通过设置消息的过期时间和死信队列来模拟出延时队列。消费者监听死信交换器绑定的队列,而不要监听消息发送的队列。
应用场景: 用户在系统中创建一个订单,如果 10s 后,用户没有进行支付,那么自动取消订单
消息丢失问题
1.生产者弄丢数据
主流 MQ 有确认机制或者事务机制,保证生产者将消息送到 MQ 服务器。RabbitMQ 有事务模式和 confirm 模式。
2.消息队列弄丢数据
一般只要开启 MQ 的持久化磁盘配置就能解决这个问题
3.消费者弄丢数据
消费者丢数据一般是因为采用了【自动确认】消息模式。MQ 收到确认消息后会删除消息,如果这时消费者异常了,那消息就没了。
可以改用【手动确认 ack机制】来解决,其实 ack 机制也引出了下面的重复消费问题(幂等性解决)!
重复消费问题
参考消息幂等性解决方案
1.防重复表,表主键唯一重复插入报错
2. token 机制 实现需配合 redis,redis中有代表未请求过,可以正常操作,操作完删除,redis中没有就代表以及请求过
3. 状态机 如订单的待提交,待支付,已支付,取消这些机制,假设当前状态是已支付,这时候如果支付接口又接收到了支付请求,更新则会抛异常或拒绝此次处理。
顺序消费问题
一句话,主动去分配队列,单个消费者。消息体通过 hash 分派到队列里,同一组的任务会分配到同一个队列里,每个队列【只能】有一个 worker 来消费,这样避免同一个队列多个消费者消费时,乱序的可能
1、每个消费者监听自己的队列,并且设置带统配符的 routingkey
2、生产者将消息发给 broker,由交换机根据 routingkey 来转发消息到指定的队列
消息队列选项
ActiveMQ:早期的消息队列,社区比较成熟,但是性能已经有点落后了,更新也慢,不建议用
RabbitMQ:处理大量数据不及 RocketMQ 、kafka,基于 erlang 开发,并发能力强,性能好,延时低,达到微秒级,
并发量不是很大的话,只有十来万,百万以内,优先考虑
RocketMQ:阿里开源项目,虽然性能也很好,但是阿里哪天不想要它了,那你估计也难受了。
kafka:特点明显,功能很少,但吞吐量极高,毫秒级别延迟。唯一缺点就是可能出现重复消费情况,概率很小,
对超大数量的信息处理,这可以忽略掉。就像打印上千万行日志消息,你会在意中间漏了一条日志么
2.Nginx
Nginx 概念
1.是一个 Web 服务器
2.反向代理服务器,实现负载均衡
nginx 常用命令
-s 向正在运行的 nginx 主进程发送信号,值有 stop, quit, reopen, reload
-c 一般为指定配置文件的意思(conf)
-v 一般是查询版本(version)
-h 一般是帮助(help)
-t 测试配置文件是否存在语法错误(test)
启动 nginx
停止 nginx -s stop
重载配置 ./sbin/nginx -s reload(平滑重启)
重载指定配置文件 .nginx -c /usr/local/nginx/conf/nginx.conf
查看 nginx 版本 nginx -v 。
检查配置文件是否正确 nginx -t 。
显示帮助信息 nginx -h 。
正向代理和反向代理
正向代理: 在客户端和服务器之间通过跳板(代理服务器)连接,客户端向代理发送一个请求并指定目标(原始服务器),然后代理向原始服务器转交请求并将获得的内容返回给客户端。【客户端必须要进行一些特别的设置才能使用正向代理,解决访问限制问题】。
反向代理: 代理服务器来接受网络上的连接请求,然后将请求转发给内部网络上的服务器,并将服务器上得到的结果返回给请求连接的客户端,此时代理服务器对外就表现为一个反向代理服务器。【客户端无需做任何配置,提供负载均衡、安全防护(隐藏源服务器的存在和特征)】。
区别:
【正向代理其实是客户端的代理,反向代理则是服务器的代理。】
正向代理中,服务器并不知道真正的客户端到底是谁;而在反向代理中,客户端也不知道真正的服务器是谁。
用Nginx服务器解释-s的目的是什么
用于运行Nginx -s参数的可执行文件。
负载均衡策略
1、轮询(默认)round_robin
每个请求按时间顺序逐一分配到不同的后端服务器,如果后端服务器 down 掉,能自动剔除。
2.权重方式,在轮询策略的基础上指定轮询的几率。
weight参数用于指定轮询几率,weight的默认值为1,权重越高分配到需要处理的请求越多。
3、IP 哈希 ip_hash
每个请求按访问 ip 的 hash 结果分配,这样每个访客固定访问一个后端服务器,可以解决 session 共享的问题。实际场景下,一般不考虑使用 ip_hash 解决 session 共享。
4、最少连接 least_conn
下一个请求将被分派到活动连接数量最少的服务器
3.Redis
redis:数据缓存、分布式锁(秒杀)、消息队列(lpush存、rpop取)
Redis 支持多个数据库,且每个数据库的数据是隔离不共享,单机有16个数据库,集群只有一个 db0
redis 集群不支持 【事务 和 发布订阅 】等一批命令
注意 redis 事务(multi )和分布式锁(setnx)的实现方式
Redis适合的场景
会话缓存(共享)(Session Cache)、分布式锁(秒杀)、全页缓存、发布/订阅、实时计数器(string)、
排行榜/计数器(zset)、消息队列(list)、共同关注喜好(set交集并集)、
用户信息商品信息(前提是该对象没嵌套其他的对象)(hash)
redis 是事务可以看做是乐观锁
redis 锁可以
秒杀思路
1.商品 id 及库存 以 key value 存在 redis 中
2.秒杀前加载这些信息
3.秒杀成功的把用户、商品信息、时间等通过 mq 形式发送,后续消费这些信息来更新数据库,或把订单信息入库
4.秒杀失败直接返回,或者客户端也可以轮询来查看自己的秒杀结果
秒杀实现
一、库存信息放到列表中(list),可以利用 redis 单线程特性,,假设有 10 件库存,就往列表中 push 10个数(对象),
该数没有实际意义,仅代表一件件库存。抢购开始后,请求一次,就从列表中 pop 一个数,表示用户抢购成功。
列表为空,则表示已抢完。列表的 pop 操作是原子的,这个过程无需经过加锁操作!
二、库存信息用一个 key-value 形式存储,抢购时先给 redis 加锁,成功后修改库存,释放锁,框架 redission 简单调用
Redis支持五种数据类型(value)
string(字符串),list(列表),set(集合),zset(sorted set:有序集合),hash(哈希或称散列)
1.string 是 redis 最基本的类型。可包含任何数据如 jpg 或序列化对象,值最大存512M。一个键对应一个值,
常规计数:微博数,粉丝数等。
2.list(列表)列表是简单的字符串列表,按插入顺序(有序可重)。可将元素插到列表头(左)或尾(右边)。
键对应的【值】为list(有序可重、先进先出)当消息队列,生产者消费者,lrange 命令可做 redis 分页
3.set(集合)是 string 类型的 list(无序唯一集合),通过哈希表实现的,增删查的复杂度都是 O(1)。
应用:微博中把用户关注的人存一个集合(set),其粉丝存一个集合。用交、并、差集等实现共同关注、共同粉丝、共同喜好、独有喜好。
4.Hash(哈希或称散列)是一个键值(key=>value)对集合,适合存储对象。类似微缩版redis,一个键对应的值为map(无序,key 唯一)value 存放的是结构化的对象。
应用:单点登录的时候,存用户信息,以 cookieId 作为 key,设置30分钟缓存过期时间,能模拟出类似session
的效果。hash 特别适合用于存储对象,后续操作的时候,可直接仅仅修改这个对象中的某个字段的值。 比如可以 Hash 数据结构来存储用户信息,商品信息等等。
5.zset(sorted set 有序集合)的每个元素都会关联 double 类型的分数。通过这个分数来为集合中的成员进行从小到大的排序。分数(score)可重复。
1.理解为 set,一个键对应的值为list,但 list 每个元素都关联double 分数来排序,
2.理解为 zset 类似于hash散列,一个键对应的值为 map,但是map里面的值为double类型的分数,来排序)
应用:可以做排行榜应用,取TOP N 操作。(有序不重复),直播系统中,实时排行信息包含直播间在线用户列表,
各种礼物排行榜,弹幕消息(可以理解为按消息维度的消息排行榜)等信息,适合使用 Redis 中的 SortedSet 结构进行存储。
Redis如何做内存优化
尽可能使用散列表(hash),散列表使用的内存非常小,尽可能的将数据模型抽象到一个散列表里面。比如一个用户对象,不要为这个用户的名称,姓氏,邮箱设置单独的key,而把用户的所有信息存储到一张散列表里面。
redis持久化有两种方式 (RDB 和 AOF)
RDB(RedisDatabase快照持久化)和AOF(append only file) 当两种方式同时开启时,数据恢复Redis会优先选择AOF恢复,在redis.conf配置文件中配置。Redis的所有数据都是保存到内存中。Redis 开始支持 RDB 和 AOF 的混合持久化(默认关闭,可以通过配置项 aof-use-rdb-preamble 开启)。如果把混合持久化打开,AOF 重写的时候就直接把 RDB 的内容写到 AOF 文件开头。好处是可以结合两者的优点,快速加载同时避免丢失过多的数据。缺点是 AOF 里面的 RDB 部分是压缩格式不再是 AOF 格式,可读性较差。通过持久化机制把内存中的数据同步到硬盘文件来保证数据持久化。重启后通过把硬盘文件重新加载到内存恢复数据
RDB:该持久化默认开启,在指定的时间间隔内将内存中的数据集快照写入磁盘,实际操作过程是fork一个子进程,先将数据集写入临时文件,写入成功后,再替换之前的文件,用二进制压缩存储。一次性把redis中全部的数据保存一份存储在硬盘中,如果数据非常多(10-20G)就不适合频繁操作该持久化操作。(宕机时,可能丢失上次备份的宕机时的数据)
save 900 1 #900 秒内如果超过 1 个 key 被修改,则发起快照保存
save 300 10 #300秒超过10个key被修改,发起快照
save 60 10000 #60秒超过10000个key被修改,发起快照
AOF:记录每次对服务器写的操作,当服务器重启的时候会重新执行这些命令来恢复原始的数据。Redis 提供了 bgrewriteaof 指令用于对 AOF 日志进行瘦身。其原理就是开辟一个子进程对内存进行遍历转换成一系列 Redis 的操作指令,序列化到一个新的 AOF 日志文件中。 序列化完毕后再将操作期间发生的增量 AOF 日志追加到这个新的 AOF 日志文件中,追加完毕后就立即替代旧的 AOF 日志文件了,瘦身工作就完成了。(可能只丢失一秒的数据 appendfsync everysec)
appendonly yes #开启AOF模式
appendfilename "appendonly.aof"
# appendfsync always 一写指令就备份一次。虽然安全但系统性能会降低。不推荐使用(不丢失任何数据)
appendfsync everysec 每秒备份一次。不管一秒变化了多少key,只备一次,性能得到保护。推荐用。(可能丢失一秒数据)
# appendfsync no # 操作系统自己决定,看服务器状态,状态良好就进行备份(随机)。备份数据是没有保证
性能:always<everysec<no,而数据安全:always>everysec>no。
Redis 事务
使用场景:也可以做秒杀
Redis 通过 MULTI、EXEC、discard、WATCH 等命令来实现事务(transaction)功能。事务将多个命令请求打
包,然后一次性、按顺序地执行多个命令的机制,且在事务执行期间,服务器不会中断事务而改去执行其他客户端的命
令请求,它会将事务中的所有命令都执行完毕,然后才去处理其他客户端的命令请求。
multi 开启一个事务,类比 begin transaction
exec 提交事务,类比 commit(如果 exec 前 watch 了某值,监控是否被改,被改 exec 会返回 nil,不提交)
discard 取消事务,未执行可以取消,如果是中途出现异常,已执行的不会回滚
watch 监控一个或者多个键,当被监控的键值被修改后,阻止之后的一个事务的执行。【watch 不能阻止其它客户端修改这一键值】
注意:执行完事务的 exec 命令之后,watch 就会取消对所有键值的监控
unwatch 取消监控
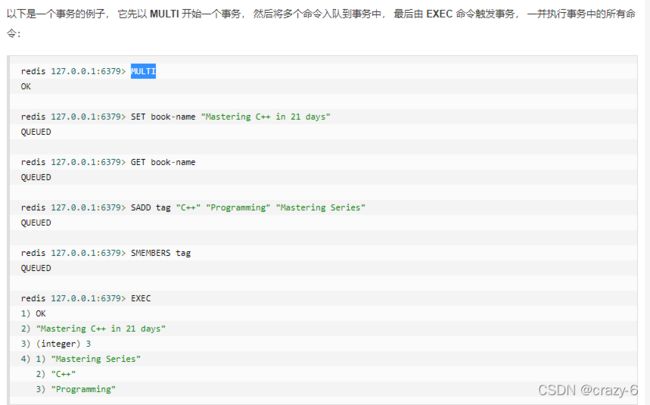
注意:redis 事务遇到异常不会回滚已执行的命令!!!!
秒杀实(伪代码) 参考 java基于redis事务的秒杀实现
while(true){
watch(库存);
if(库存<0){
return 已售罄
}
multi; // 开启事务
库存-1; // 减库存
result = exec; // 提交,如果 watch 的库存变动会返回失败
if(result){
成功并退出;
}else{
失败继续循环
}
}
分布式锁
参考 https://www.cnblogs.com/sunshijia1993/p/11590645.html
参考 https://zhuanlan.zhihu.com/p/129886269?ivk_sa=1024320u
- 互斥性:在任意时刻只有一个客户端可以获取锁。
- 防死锁:假如 A 在持有锁时,崩溃未释放锁,那么别的客户端无法获得锁,造成死锁。Redis 中设置锁的过期时间来保证不会发生死锁。
- 持锁人解锁:加锁和解锁必须是同一个客户端
- 可重入
Redis 实现分布式锁的重要命令
setnx:用法是 setnx key value,【SET if Not eXists】(如果不存在,则 SET)的简写,设置成功会返回 1,否则返回 0
setex:用法 setex key seconds value。以【秒】为单位设置过期时间,如果 key 已经存在,setex 将覆写旧值
该命令类似于以下两个命令,但这两步动作是原子性的,会在同一时间完成
SET key value # 设置值
EXPIRE key seconds # 设置生存时间
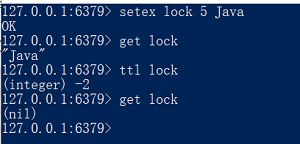
psetex:用法 psetex key milliseconds value ,这个命令和 setex 命令相似,以【毫秒】为单位设置 key 的生存时间
从redis 2.6.12 版本开始,SET 命令可以通过参数来实现和 SETNX、SETEX、PSETEX 三个命令相同的效果。
redission 框架封装加锁过程:内部会生成一个类似 uuid 的唯一标识来代表客户端,后续锁释放锁也用该 id来释放,【持锁人解锁】
set key value NX EX seconds
加上NX、EX参数后,效果就相当于SETEX,这也是Redis获取锁写法里面最常见的。
释放锁:就是删除 key,1.检查是否自己持有锁(判断唯一标识)2.删除锁。解锁也是两步,同样也要保证解锁的原子性,把两步合为一步,需依靠 Lua 脚本来实现。(redission 框架内部也是写了 lua 脚本实现这步)
线程锁:主要用来给方法、代码块加锁。当某个方法或代码使用锁,在同一时刻仅有一个线程执行该方法或该代码段。
线程锁只在同一JVM中有效果,因为线程锁的实现在根本上是依靠线程之间共享内存实现的,如synchronized 是
共享对象头,显示锁 Lock 是共享某个变量(state)。
进程锁:为了控制同一操作系统中多个进程访问某个共享资源,因为进程具有独立性,各个进程无法访问其他进程的资源,因此无法通过 synchronized 等线程锁实现进程锁。
分布式锁:当多个进程不在同一个系统中(如在多机器上),用分布式锁控制多个进程对资源的访问。
public class RedisDistributedLock implements Lock {
//上下文,保存当前锁的持有人id
private ThreadLocal<String> lockContext = new ThreadLocal<String>();
//默认锁的超时时间
private long time = 100;
//可重入性
private Thread ownerThread;
public RedisDistributedLock() {}
public void lock() {
while (!tryLock()){
try {
Thread.sleep(100);
}catch (InterruptedException e){
e.printStackTrace();
}
}
}
public boolean tryLock() {
return tryLock(time,TimeUnit.MILLISECONDS);
}
public boolean tryLock(long time, TimeUnit unit){
String id = UUID.randomUUID().toString(); //每一个锁的持有人都分配一个唯一的id
Thread t = Thread.currentThread();
Jedis jedis = new Jedis("127.0.0.1",6379);
//只有锁不存在的时候加锁并设置锁的有效时间
if("OK".equals(jedis.set("lock",id, "NX", "PX", unit.toMillis(time)))){
//持有锁的人的id
lockContext.set(id); ①
//记录当前的线程
setOwnerThread(t); ②
return true;
}else if(ownerThread == t){
//因为锁是可重入的,所以需要判断当前线程已经持有锁的情况
return true;
}else {
return false;
}
}
private void setOwnerThread(Thread t){
this.ownerThread = t;
}
public void unlock() {
String script = null;
try{
Jedis jedis = new Jedis("127.0.0.1",6379);
script = inputStream2String(getClass().getResourceAsStream("/Redis.Lua"));
if(lockContext.get()==null){
//没有人持有锁
return;
}
//删除锁 ③
jedis.eval(script, Arrays.asList("lock"), Arrays.asList(lockContext.get()));
lockContext.remove();
}catch (Exception e){
e.printStackTrace();
}
}
/**
* 将InputStream转化成String
* @param is
* @return
* @throws IOException
*/
public String inputStream2String(InputStream is) throws IOException {
ByteArrayOutputStream baos = new ByteArrayOutputStream();
int i = -1;
while ((i = is.read()) != -1) {
baos.write(i);
}
return baos.toString();
}
public void lockInterruptibly() throws InterruptedException {
}
public Condition newCondition() {
return null;
}
}
如何解决 Redis 的并发竞争 Key 问题
所谓 Redis 的并发竞争 Key 的问题也就是多个系统同时对一个 key 进行操作,但是最后执行的顺序和我们期望的顺序不同,导致结果的不同!推荐分布式锁(zookeeper 和 redis 都可以实现分布式锁)
如果不存在 Redis 的并发竞争 Key 问题,不要使用分布式锁,这样会影响性能
加锁:1.setnx 命令加锁,用到 Redis 的命令 setnx(set if not exists),setnx 的含义就是只有锁不存在的情况下才会设置成功。2.设置锁的有效时间,防止死锁 expire,Redis3.0 已经把这两个指令合在一起成为一个新的指令。
解锁:1.检查是否自己持有锁(判断唯一标识) 2.删除锁。解锁也是两步,保证解锁原子性,将两步合一。无法借助于 Redis,要依靠 Lua 脚本实现。
其他分布式锁的对比(秒杀场景)
基于数据库的分布式锁
1)实现方式 --获取锁的时候插入一条数据,解锁时删除数据。
2)缺点 --数据库如果挂掉会导致业务系统不可用。无法设置过期时间,会造成死锁。
基于 zookeeper 的分布式锁
0) 大致流程为:每个客户端对某个方法加锁时,在zookeeper上与【该方法对应的】指定节点的目录下,生成一个
唯一的瞬时有序节点。 判断是否获取锁的方式很简单,只需要判断有序节点中序号最小的一个。 释放锁的时候,
将该瞬时节点删除即可。可避免服务宕机导致锁无法释放产生的死锁问题。业务结束后,删除对应的子节点释放锁。
1)实现方式 --加锁时在指定节点的目录下创建一个新节点(瞬时有序),释放锁的时候删除该临时节点。
因为有心跳检测,所以不会发生死锁,更加安全。基于 zookeeper 临时有序节点可以实现的分布式锁。
2)缺点 --性能一般,没 Redis 高效。
在实践中,如果可靠性第一考虑 Zookeeper。
从性能角度: Redis > zookeeper > 数据库
从可靠性(安全)性角度: zookeeper > Redis > 数据库
本文从锁的基本概念出发,提出多线程访问共享资源会出现的线程安全问题,然后通过加锁的方式去解决线程安全的问题,这个方法会性能会下降,需要通过:缩短锁的持有时间、减小锁的粒度、锁分离三种方式去优化锁。
分布式锁的4个特点: 互斥性、防死锁、加锁人解锁、可重入性
1)互斥性(在任意时刻只有一个客户端可以获取锁。这个很容易理解,所有的系统中只能有一个系统持有锁)
2)防死锁(假如一个客户端在持有锁的时候崩溃了,没有释放锁,那么别的客户端无法获得锁,则会造成死锁,所以要保证客户端一定会释放锁。Redis中我们可以设置锁的过期时间来保证不会发生死锁)
3)持锁人解锁(解铃还须系铃人,加锁和解锁必须是同一个客户端,客户端A的线程加的锁必须是客户端A的线程来解锁,客户端不能解开别的客户端的锁)
4)可重入(当一个客户端获取对象锁之后,这个客户端可以再次获取这个对象上的锁)
Jedis 和 Redisson
Jedis 是Java 实现的Redis 客户端,它的API提供了全面的类似于Redis 原生命令的支持。相比于其他Redis 封装框架更加原生。
Redisson是一个在Redis的基础上实现的Java驻内存数据网格(In-Memory Data Grid)。它不仅提供了一系列的分布式的Java常用对象,还提供了许多【分布式服务】。其中包括Bitset, Set, MultiMap, SortedSet, Map,List, Queue, BlockingQueue, Deque, BlockingDeque, Semaphore, Lock, AtomicLong, CountDownLatch, Publish/Subscribe, Bloom filter, Remote service, Spring cache, Executor service, Live Object service, Scheduler service。
Redisson提供了使用Redis的最简单和最便捷的方法。Redisson的宗旨是促进使用者对Redis的关注分离(Separation of Concern),从而让使用者能够将精力更集中地放在处理业务逻辑上
功能需求不多,上 Jedis 即可,功能需求复杂使用Redisson,虽然臃肿但是功能齐全
pub/sub: 功能是订阅发布功能,可以用作简单的消息队列。
在第一个 redis-cli 客户端输入 SUBSCRIBE runoobChat,意思是订阅 runoobChat 频道。
在第二个 redis-cli 客户端输入 PUBLISH runoobChat “Redis PUBLISH test” 往 runoobChat 频道发送消息,这个时候在第一个 redis-cli 客户端就会看到由第二个 redis-cli 客户端发送的测试消息。
Pipeline:可以批量执行一组指令,一次性返回全部结果,可以减少频繁的请求应答。
Lua:Redis 支持提交 Lua 脚本来执行一系列的功能。
布隆过滤器(Bloom Filter)
使用场景:1、判断一个手机号是否在10亿集合中;2、爬虫已经爬过的 url 不爬
优势:布隆过滤器使用 exists() 来判断某个元素是否存在于自身结构中。判断某值不存在时,该值一定不存在;判定某值存在时,该值极可能存在;误判率约在 1% 。
优缺点
优点
1、节省内存空间和查询时间;存的不是完整的数据,是二进制向量,节省大量内存,时间复杂度方面,根据映射函数查询,假设有K个映射函数,那么时间复杂度就是O(K)。
2、保密性;存的不是元素本身,而是二进制向量,在一些对保密性要求严格的场景有一定优势
缺点
1、存在一定的误判。存进布隆过滤器里的元素越多,误判率越高。
2、不能删除布隆过滤器里的元素。随使用的时间拉长,存的元素越来越多,占用内存增多多,误判率越提高,最后不得不重置
Redis 实现布隆过滤器的底层是通过 bitmap 这种数据结构
判断一个元素是否在一个集合中,一般想到的是将集合中所有元素保存起来,然后通过比较确定。链表、树、散列表(又叫哈希表,Hash table)等等数据结构都是这种思路。但是随着集合中元素的增加,我们需要的存储空间越来越大,检索速度也越来越慢。
Bloom Filter 是一种空间效率很高的随机数据结构,Bloom filter 看做是对 bit-map 的扩展, 原理如下:
当一个元素被加入集合时,通过 K 个 Hash 函数将这个元素映射成一个位阵列(Bit array)中的 K 个点,把它们置为 1。检索时,我们只要看看这些点是不是都是 1 就(大约)知道集合中有没有它了:
如果这些点有任何一个 0,则被检索元素一定不在;如果都是 1,则被检索元素很可能在。
package com.ys.rediscluster.bloomfilter.redisson;
import org.redisson.Redisson;
import org.redisson.api.RBloomFilter;
import org.redisson.api.RedissonClient;
import org.redisson.config.Config;
public class RedissonBloomFilter {
public static void main(String[] args) {
Config config = new Config();
config.useSingleServer().setAddress("redis://192.168.14.104:6379");
config.useSingleServer().setPassword("123");
//构造Redisson
RedissonClient redisson = Redisson.create(config);
RBloomFilter<String> bloomFilter = redisson.getBloomFilter("phoneList");
//初始化布隆过滤器:预计元素为100000000L,误差率为3%
bloomFilter.tryInit(100000000L,0.03);
//将号码10086插入到布隆过滤器中
bloomFilter.add("10086");
//判断下面号码是否在布隆过滤器中
System.out.println(bloomFilter.contains("123456"));//false
System.out.println(bloomFilter.contains("10086"));//true
}
}
guava 工具包(谷歌开源的Java库)里面也提供了布隆过滤器的实现
package com.ys.rediscluster.bloomfilter;
import com.google.common.base.Charsets;
import com.google.common.hash.BloomFilter;
import com.google.common.hash.Funnel;
import com.google.common.hash.Funnels;
public class GuavaBloomFilter {
public static void main(String[] args) {
BloomFilter<String> bloomFilter = BloomFilter.create(Funnels.stringFunnel(Charsets.UTF_8),100000,0.01);
bloomFilter.put("10086");
System.out.println(bloomFilter.mightContain("123456"));
System.out.println(bloomFilter.mightContain("10086"));
}
}
缓存雪崩
例如:缓存同一时间大面积的失效(1.redis挂了导致的 2.因为设置缓存时采用了相同的过期时间),所以,后面的请求都会落到数据库上,造成数据库短时间内承受大量请求而崩掉。
解决办法:
大多数系统设计者考虑用加锁( 最多的解决方案)或者队列的方式保证来保证不会有大量的线程对数据库一次性进行读写,从而避免失效时大量的并发请求落到底层存储系统上。还有一个简单方案就时讲缓存失效时间分散开。
事前:尽量保证整个 redis 集群的高可用性,发现机器宕机尽快补上。选择合适的内存淘汰策略;事中:本地ehcache缓存 + hystrix限流&降级,避免MySQL崩掉;事后:利用 redis 持久化机制保存的数据尽快恢复缓存
预防和解决缓存雪崩问题,可以从以下三个方面进行着手:
①保证缓存层服务高可用性。设计成集群。
②依赖隔离组件为后端限流并降级。
在实际项目中,我们需要对重要的资源(例如Redis、MySQL、HBase、外部接口)都进行隔离,让每种资源都单独运行在自己的线程池中,即使个别资源出现了问题,对其他服务没有影响。但是线程池如何管理,比如如何关闭资源池、开启资源池、资源池阀值管理,这些做起来还是相当复杂的。
③提前演练。在项目上线前,演练缓存层宕掉后,应用以及后端的负载情况以及可能出现的问题,在此基础上做一些预案设定。
缓存穿透
缓存穿透是指用户查询的数据,在数据库没有,在缓存中也不会有。查询的时候,先在缓存中找不到,每次都去数据库再查询,相当于进行了两次无用的查询。请求就绕过缓存直接查数据库,这也是经常提的缓存命中率问题
解决办法;
最常见的则是采用布隆过滤器,将所有可能存在的数据(查询条件,查询值)哈希到一个足够大的 bitmap 中,一个一定不存在的数据会被这个 bitmap 拦截掉,从而避免了对底层存储系统的查询压力。
另外也有一个更为简单粗暴的方法,如果一个查询返回的数据为空(不管是数据不存在,还是系统故障),我们仍然把这个空结果进行缓存,但它的过期时间会很短,最长不超过五分钟。通过这个直接设置的默认值存放到缓存,
这样第二次到缓冲中获取就有值了,而不会继续访问数据库,这种办法最简单粗暴。

5TB的硬盘上放满了数据,请写一个算法将这些数据进行排重。如果这些数据是一些32bit大小的数据该如何解决?如果是64bit的呢
对于空间的利用到达了一种极致,那就是Bitmap和布隆过滤器(Bloom Filter)。
Bitmap: 典型的就是哈希表
缺点是,Bitmap对于每个元素只能记录1bit信息,如果还想完成额外的功能,恐怕只能靠牺牲更多的空间、时间来完成了。
Memecache 和 redis
Memecache把数据全部存在内存之中,断电后会挂掉,数据不能超过内存大小。 Redis有部份存在硬盘上,且可以持久化,memcached值均是简单的字符串,redis支持更为丰富的数据类型 ,提供list,set,zset,hash等数据结构的存储
redis 集群
参考 E:\work\资料\redis\Redis集群.docx
参考 https://blog.csdn.net/miss1181248983/article/details/90056960/
集群避免了 redis 单点故障
1.主从模式
主数据库(master)和从数据库(slave)
- 一主可以多从
- 主数据只写,从数据库只读
- 主挂了以后,集群的从只能提供读服务,【不会】在 slave 从节点中重新选 master
工作原理
当slave启动后,主动向master发送SYNC命令。master接收到SYNC命令后在后台保存快照(RDB持久化)和缓存保存快照这段时间的命令,然后将保存的快照文件和缓存的命令发送给slave。slave接收到快照文件和命令后加载快照文件和缓存的执行命令。
复制初始化后,master每次接收到的写命令都会同步发送给slave,保证主从数据一致性。

2.哨兵(sentinel)模式
发音 森特脑
哨兵的作用就是对Redis的系统的运行情况的监控,它是【一个独立进程】。功能如下:
1、监控主数据库和从数据库是否运行正常;
2、主数据出现故障后自动将从数据库转化为主数据库;
3、如有多个哨兵,不仅监控主从数据库,且哨兵间互为监控 (哨兵也可能会挂,最好有哨兵集群)
当 master 挂了以后,sentinel 会在 slave 中选择一个做为 master,并修改其他 slave 的配置文件,比如slaveof 属性会指向新的 master,当 master 重启后,成为 slave 接收新的 master 的同步数据
当使用 sentinel 模式时,客户端不要直连 Redis,而是连 sentinel 的ip和port,由sentinel来提供具体的可提供服务的Redis实现,这样当master节点挂掉以后,sentinel就会感知并将新的master节点提供给使用者。
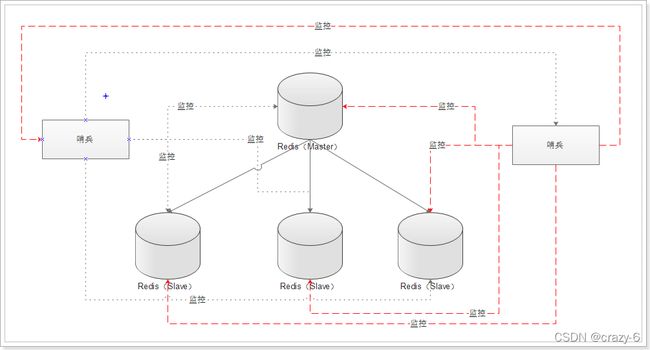
3.集群(Cluster)模式 分片集群
发音 克拉四特
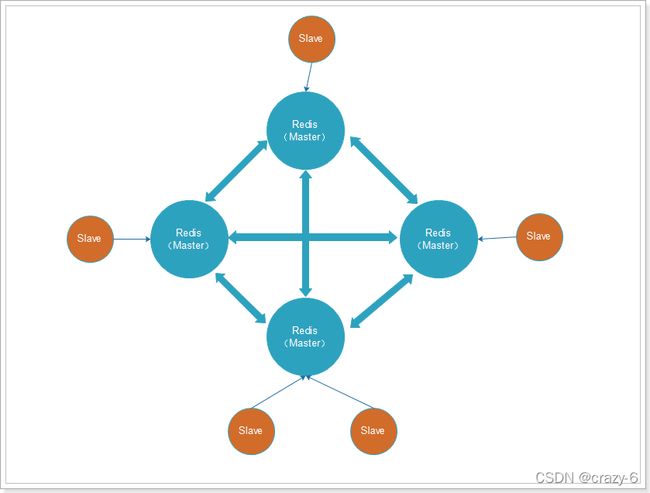
cluster 模式的出现就是为了解决单机 Redis 容量有限的问题,将Redis的数据根据一定的规则分配到多台机器。
- 至少六个实例(三主三从),其中【从不提供服务】,仅作为备用
- 不支持同时处理多个key(如MSET/MGET),因为 redis 需要把 key 均匀分布在各个节点上,
- 客户端可以连接任何一个主节点进行读写
- 支持在线增加、删除节点
所有的 redis 节点彼此互联(PING-PONG机制),内部使用二进制协议优化传输速度和带宽.
注意:
1.redis cluster 集群是去中心化的,每个节点都是平等的,连接哪个节点都可以获取和设置数据。
2.springboot 整合 redis 集群时需要在配置文件中写所有的节点(包括slave),集群是一个整体,具体访问由集群决定
# redis集群
#最大连接数据库连接数,设 0 为没有限制
spring.redis.jedis.pool.maxActive=50
#最大建立连接等待时间 如果超过此时间将接到异常 设为-1表示无限制 单位为 ms
spring.redis.jedis.pool.max-wait = 5000
#最大最大空闲数,设 0 为没有限制
spring.redis.jedis.pool.max-Idle = 5
#连接超时时间
spring.redis.timeout = 10
#所有节点地址
spring.redis.cluster.nodes = 192.168.56.129:7000,192.168.56.129:7001,192.168.56.129:7002,192.168.56.129:7003,192.168.56.129:7004,192.168.56.129:7005
#连接失败最大重连次数
spring.redis.cluster.max-redirects=5
4.jenkins
CI/CD实现持续集成与交付
CI 持续集成(Continuous Integration)
CD 持续交付(Continuous Delivery)
CD 持续部署(Continuous Deployment)
1.配置 GitLab SSH 访问公钥,使得我们可以直接通过 SSH 拉取或推送代码到 GitLab。
2.将代码通过 SSH 上传到 GitLab。
3.在 Jenkins 创建构建任务,使得 Jenkins 可以成功拉取 GitLab 的代码并进行构建。
4.配置代码变更自动构建流程,使得代码变更可以触发自动构建 Docker 镜像。
5.配置自动部署流程,使得镜像构建完成后自动将镜像发布到测试或生产环境。
jenkins 配置 自动化部署大致步骤
参考 https://www.cnblogs.com/wfd360/p/11314697.html
1.jenkins 配置 github 仓库地址及账号信息
2.jenkins 创建触发器(回调地址)当前项目的回调地址为:如 http://localhost:8080/job/jenkinsDemo/build?token=123
只要执行这个地址即在浏览器上访问该地址,该项目就会发起一次构建项目,拉取代码打包部署操作
3.jenkins 配置构建(maven打包)及构建完成后的后操作如:
配置 maven 指令:clean install (先清理 后打包)
配置 服务器相关信息:jar 打包后要发到哪,完成后的启动等(即配置服务器账号信息、上传路径、启停脚本)
4.GitHub 配置,设置 webhooks(钩子) 回调 jenkins 上述配置地址,这样代码提交后就可回调触发 jenkins 的一系列操作了
gitee 也有付费功能 gitee go 来完成 CICD 操作,而不需要 jenkins
SonarQube与SonarLint的区别和联系
SonarQube
是一种自动代码审查工具,用于检测代码仓库中(git、svn等)的错误,漏洞和代码味,作为质量门禁,并进行 UI 展示,也可以集成 checkstyle
SonarLint
是 IDE 插件,可以在IDE 中实时检查和反馈项目的代码问题,也可以通过插件配置或者 maven 配置连接到 SonrarQube 平台 ,在网页管理端对代码库扫描的结果进行 UI 展示
5.Docker
Docker是:Build once,Run anywhere “一次封装,到处运行”,他决绝了应用环境的问题,安装了 docker 的平台就能跑 “docker包”,这样就决绝了“开发环境能跑,一上线就崩”的尴尬。
Docker和传统虚拟化技术的对比
Docker资源占用少,启动更快,很大的方便了项目的部署和运维。
Docker是【在操作系统层面上】实现虚拟化,依赖且复用本地主机的操作系统,传统方式是在硬件的基础上,虚拟出多个操作系统,然后在系统上部署相关的应用。
常用命令
create push pull run
命令 作用
docker image ls 查询所有的镜像
docker pull 下载镜像
docker rmi 删除镜像
docker build 创建一个自定义的镜像
docker create 创建容器
docker ps 查询所有的容器
docker start 启动容器
docker stop 停止容器
docker logs 查看容器的运行日志记录
docker run 创建并运行一个容器
docker cp 将文件复制到容器中
docker diff 查看容器文件的变化
docker exec 在容器中运行命令
docker commit 将修改的容器创建为镜像
docker tag 为镜像分配一个标记
docker login docker logout 从镜像仓库中登录或注销
docker push 将镜像发布到仓库中
docker inspect 查看容器的详细配置
docker 的整个生命周期有三部分组成:镜像(image)+容器(container)+仓库(repository);
可以把镜像看作类,把容器看作类实例化后的对象。也可以说镜像是文件, 容器是进程。 容器是基于镜像创建的, 即容器中的进程依赖于镜像中的文件, 这里的文件包括进程运行所需要的可执行文件, 依赖软件, 库文件, 配置文件等等
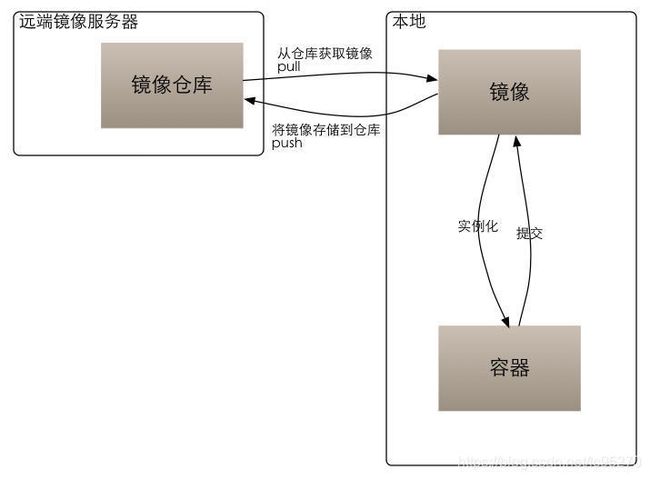
Dockerfile 记录单个镜像的构建过程
docker-compose:是 docker 官方的开源项目,使用 python 编写,实现上调用了 Docker 服务的 API 进行容器管理。定义和运行多个 Docker 容器的应用
很多时候,一个项目需要多个镜像合作才能启动,比如要 nginx , 数据库 mysql, 邮件服务等等,如果把所有这些都弄到一个镜像里去,但这样做就无法复用了。更常见的是, nginx, mysql, smtp 都分别是个镜像,然后这些镜像合作,共同服务一个项目。
docker-compose 就是解决这个问题的。你的项目需要哪些镜像,每个镜像怎么配置,要挂载哪些 volume, 等等信息都包含在 docker-compose.yml 里。
启动服务:docker-compose up ,停止服务 docker-compse stop/down
简而言之, Dockerfile 记录单个镜像的构建过程, docker-compose.yml 记录一个项目(project, 一般是多个镜像)的构建过程。
有些教程用了 dockerfile+docker-compose, 是因为 docker-compose.yml 本身没有镜像构建的信息,如果镜像是从 docker registry 拉取下来的,那么 Dockerfile 就不需要;如果镜像是需要 build 的,那就需要提供 Dockerfile.
6.容器化管理工具 Kubernetes
官方中文文档 https://www.kubernetes.org.cn/docs
Google 在2014年发布的开源项目,用于自动化容器化应用程序的部署、扩展和管理。通常结合 docker容器工作,并且整合多个运行着 docker 容器的主机集群
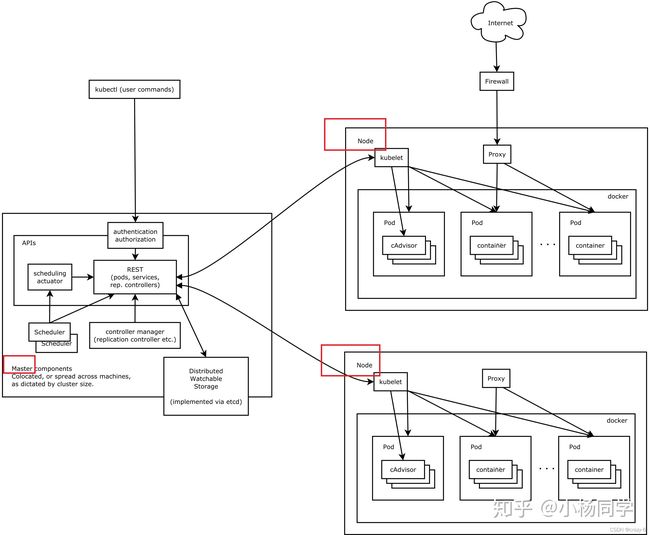
k8s集群由 Master 节点和 Node(Worker)节点组成。
Master节点
Master节点指的是集群控制节点,管理和控制整个集群,基本上 k8s 的所有控制命令都发给它,它负责具体的执行过程。
node节点
Kubernetes 节点 有运行应用容器必备的服务,而这些都是受Master的控制。
node 节点上当然都要运行 Docker。Docker 来负责所有具体的映像下载和容器运行。
Kubernetes主要由以下几个核心组件组成:
- etcd保存了整个集群的状态;
- apiserver提供了资源操作的唯一入口,并提供认证、授权、访问控制、API注册和发现等机制;
- controller manager负责维护集群的状态,比如故障检测、自动扩展、滚动更新等;
- scheduler负责资源的调度,按照预定的调度策略将Pod调度到相应的机器上;
- kubelet负责维护容器的生命周期,同时也负责Volume(CVI)和网络(CNI)的管理;
- Container runtime负责镜像管理以及Pod和容器的真正运行(CRI);
- kube-proxy负责为Service提供cluster内部的服务发现和负载均衡;
除了核心组件,还有一些推荐的Add-ons:
- kube-dns负责为整个集群提供DNS服务
- Ingress Controller为服务提供外网入口
- Heapster提供资源监控
- Dashboard提供GUI
- Federation提供跨可用区的集群
- Fluentd-elasticsearch提供集群日志采集、存储与查询
7.jfrog(杰蛙) 和 nexus
都是仓库管理器,Sonatype Nexus 和 JFrog Artifactory 对比如下

8.Elastic Stack
ELK:旧称呼,三款软件的简称,Elasticsearch、Logstash、Kibana
Elastic Stack:新称,加入了 Beats 的加入
Beats(监控node并推送数据)
Beats 是 elastic 公司开源的一款采集系统监控数据的代理 agent,在被监控服务器上以客户端形式运行,直接把数据发送给 Elasticsearch 或通过 Logstash 发送给Elasticsearch,然后进行后续的数据分析活动。分类如下:
1、Packetbeat
用于【监控收集网络流量】信息,Packetbeat嗅探服务器之间的流 量,解析应用层协议,并关联到消息的处理,
支持 ICMP (v4 and v6)、DNS、HTTP、Mysql、PostgreSQL、Redis、MongoDB、Memcache 等协议;
2、Filebeat
用于监控、【收集服务器日志文件】,取代 logstash forwarder;
3、Metricbeat
定期获取外部系统的监控指标信息,其可以监控、收集 Apache、HAProxy、MongoDB、MySQL、Nginx、
PostgreSQL、Redis、System、Zookeeper 等服务;
4、Winlogbeat
用于监控、收集Windows系统的日志信息;
5、Heartbeat
健康检查。
ELK 大致使用流程
beats非必须
1、启动 Elasticsearch、Logstash、Kibana 三个应用(三个端口)
2、业务系统日志配置文件(xml),设置输出到 LogStash 的地址 (ip+端口)
3、LogStash 将数据清洗后推送到 Elasticsearch (ip+端口,需要在LogStash 配置文件中设置)
4、Kibana 展示从 Elasticsearch 读取的数据信息
ELK 的安装参考 http://www.macrozheng.com/#/deploy/mall_deploy_windows?id=elasticsearch
SpringBoot 应用整合 ELK 实现日志收集参考 http://www.macrozheng.com/#/technology/mall_tiny_elk
Logstash (收集、清洗、过滤数据)
Logstash 基于 java,是一个开源的用于【收集、分析、存储】日志的工具。
Elasticsearch (搜索、存储)
Elasticsearch 基于 java,是个开源分布式【搜索引擎】,可以存储数据,它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful 风格接口,多数据源,自动搜索负载等。
Elasticsearch 对外提供的是 index 的概念,可以类比为 DB,用户查询是在 index 上完成的,每个 index由若干个shard组成,以此来达到分布式可扩展的能力。比如下图是一个由10个shard组成的index。
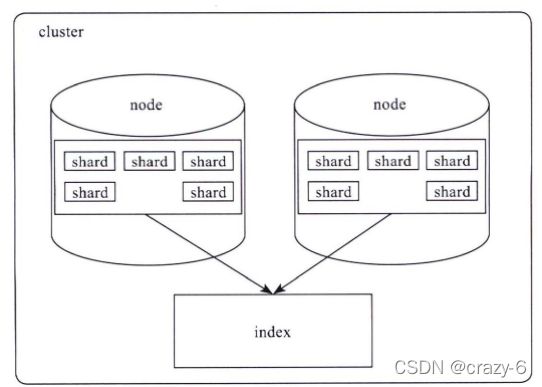
shard是Elasticsearch数据存储的最小单位,index的存储容量为所有shard的存储容量之和。Elasticsearch集群的存储容量则为所有index存储容量之和。
一个shard就对应了一个lucene的library。对于一个shard,Elasticsearch增加了translog的功能,类似于HBase WAL,是数据写入过程中的中间数据,其余的数据都在lucene库中管理的。
所以Elasticsearch索引使用的存储内容主要取决于lucene中的数据存储。
Kibana(web页面展示)
Web 界面,Kibana 基于 nodejs,也是一个开源和免费的工具,为 Logstash 和 ElasticSearch 提供的日志分析友好的页面展现 ,可以汇总、分析和搜索重要数据日志。
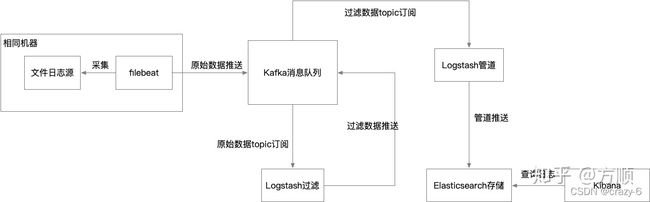
Elastic Stack 整合 kafka 消息队列
日志(log4j 和 Logback)
日志框架slf4j log4j logback之间的关系
简答的讲就是 slf4j 是一系列的日志接口,而 log4j 和 logback 是具体实现了的日志框架。logback 的作者也是 log4j 开源前的作者

springboot 使用 log4j
Spring Boot 依赖的 spring-boot-starter,其中包含了 spring-boot-starter-logging,该依赖默认的日志框架为 Logback,所以我们在引入log4j之前,要先排除(exclusion)该包的依赖,再引入 log4j 的依赖
配置文件,log4j.properties 是默认名字,要改名要在 application.properties 里进行配置。
#log4j 配置
#log4j定义了8个级别的log优先级从高到低依次为:OFF、FATAL、ERROR、WARN、INFO、DEBUG、TRACE、 ALL。
#CONSOLE前面的DEBUG是控制台需要打印什么DEBUG级别以上的日志的信息
log4j.rootLogger=DEBUG, CONSOLE, ERROR, WARN, INFO, DEBUG, ALL
#-----------------------------------------------------------------------------------------------------
#输出信息到控制台CONSOLE
log4j.appender.CONSOLE = org.apache.log4j.ConsoleAppender
log4j.appender.CONSOLE.Target = System.out
log4j.appender.CONSOLE.layout = org.apache.log4j.PatternLayout
log4j.appender.CONSOLE.layout.ConversionPattern = [%-5p] %d{yyyy-MM-dd HH:mm:ss,SSS} method:%l%n%m%n
#-----------------------------------------------------------------------------------------------------
#输出ERROR 级别以上的日志到error.log
log4j.logger.ERROR=ERROR
log4j.appender.ERROR = org.apache.log4j.DailyRollingFileAppender
log4j.appender.ERROR.File =logs/error/error.log
log4j.appender.file.DatePattern ='.'yyyy-MM-dd
log4j.appender.ERROR.Threshold = ERROR
log4j.appender.ERROR.Append = true
log4j.appender.ERROR.layout = org.apache.log4j.PatternLayout
log4j.appender.ERROR.layout.ConversionPattern = %-d{yyyy-MM-dd HH:mm:ss} [ %t:%r ] - [ %p ] %m%n
#-----------------------------------------------------------------------------------------------------
#输出WARN 级别以上的日志到warn.log
log4j.logger.WARN=WARN
log4j.appender.WARN = org.apache.log4j.DailyRollingFileAppender
log4j.appender.WARN.File =logs/warn/warn.log
log4j.appender.file.DatePattern ='.'yyyy-MM-dd
log4j.appender.WARN.Threshold = WARN
log4j.appender.WARN.Append = true
log4j.appender.WARN.layout = org.apache.log4j.PatternLayout
log4j.appender.WARN.layout.ConversionPattern = %-d{yyyy-MM-dd HH:mm:ss} [ %t:%r ] - [ %p ] %m%n
#-----------------------------------------------------------------------------------------------------
#输出INFO级别以上的内容到info.log中
log4j.logger.INFO=INFO
log4j.appender.INFO = org.apache.log4j.DailyRollingFileAppender
log4j.appender.INFO.File = logs/info/info.log
log4j.appender.file.DatePattern ='.'yyyy-MM-dd
log4j.appender.INFO.Threshold = INFO
log4j.appender.INFO.Append = true
log4j.appender.INFO.layout = org.apache.log4j.PatternLayout
log4j.appender.INFO.layout.ConversionPattern = %-d{yyyy-MM-dd HH:mm:ss} [ %t:%r ] - [ %p ] %m%n
#-----------------------------------------------------------------------------------------------------
#输出DEBUG 级别以上的日志到debugger.log
log4j.logger.DEBUG=DEBUG
log4j.appender.DEBUG = org.apache.log4j.DailyRollingFileAppender
log4j.appender.DEBUG.File = logs/debugger/debugger.log
log4j.appender.file.DatePattern ='.'yyyy-MM-dd
log4j.appender.DEBUG.Threshold = DEBUG
log4j.appender.DEBUG.Append = true
log4j.appender.DEBUG.layout = org.apache.log4j.PatternLayout
log4j.appender.DEBUG.layout.ConversionPattern = %-d{yyyy-MM-dd HH:mm:ss} [ %t:%r ] - [ %p ] %m%n
#-----------------------------------------------------------------------------------------------------
#输出ALL级别的日志到all.log
log4j.logger.ALL=ALL
log4j.appender.ALL = org.apache.log4j.DailyRollingFileAppender
log4j.appender.ALL.File = logs/all/all.log
log4j.appender.file.DatePattern ='.'yyyy-MM-dd
log4j.appender.ALL.Threshold = ALL
log4j.appender.ALL.Append = true
log4j.appender.ALL.layout = org.apache.log4j.PatternLayout
log4j.appender.ALL.layout.ConversionPattern = %-d{yyyy-MM-dd HH:mm:ss} [ %t:%r ] - [ %p ] %m%n
springboot 使用 默认的 Logback
日志配置 参考 https://blog.csdn.net/white_ice/article/details/85065219
1.简单配置 可在 application.properties 中设置 logging.file 或 logging.path 属性
注:二者不能同时使用,如若同时使用,则只有logging.file生效
logging.file=文件名
logging.path=日志文件路径
logging.level.包名=指定包下的日志级别
logging.pattern.console=日志打印规则
2.复杂配置(自定义配置),需要建 xml 文件
Spring Boot官方推荐优先使用带有-spring 的文件名作为你的日志配置(如使用 logback-spring.xml),将xml 放至 src/main/resource下面
具体使用:
- 方式一(普通)
private final Logger log = LoggerFactory.getLogger(this.getClass());
log.info("启动成功---------");
- 方式二(@Slf4j)
1.先在类名上使用注解@Slf4j
2.方法中直接用 log.info("启动成功---------");
9.Hadoop概念
Hadoop 就是存储海量数据和分析海量数据的工具
Hadoop是由 java 语言编写的,在分布式服务器集群上存储海量数据并运行分布式分析应用的开源框架,其**核心部件是 HDFS 与 MapReduce **,HDFS为海量的数据提供了存储,则 MapReduce 为海量的数据提供了计算。
HDFS:是一个分布式文件系统:引入存放文件元数据信息的服务器Namenode和实际存放数据的服务器Datanode,对数据进行分布式储存和读取。
MapReduce:是一个分布式计算框架:MapReduce的核心思想是把计算任务分配给集群内的服务器里执行。通过对计算任务的拆分(Map计算/Reduce计算)再根据任务调度器(JobTracker)对任务进行分布式计算。
Hadoop能干什么
大数据存储:分布式存储
日志处理:擅长日志分析
ETL:数据抽取到 oracle、mysql、DB2、mongdb 及主流数据库
机器学习:比如 Apache Mahout项目
搜索引擎:Hadoop + lucene 实现
数据挖掘:目前比较流行的广告推荐,个性化广告推荐
Hadoop 是专为离线和大规模数据分析而设计的,并不适合那种对几个记录随机读写的在线事务处理模式。
实际应用:
(1)Flume + Logstash + Kafka + Spark Streaming 进行实时日志处理分析
Hive
1)hive 是sql语言,通过数据库的方式来操作hdfs文件系统,为了简化编程,底层计算方式为 mapreduce。
2)hive 是面向行存储的数据库。
3)Hive 本身不存储和计算数据,它完全依赖于HDFS 和 MapReduce ,Hive 中的表纯逻辑。
Spark
Spark,是分布式计算平台,是一个用scala语言编写的计算框架,基于内存的快速、通用、可扩展的大数据分析引擎,
(1)Spark 相当于 Hadoop 中的计算模块 MR(MapReduce ) ,但是速度和效率比 MR 要快得多;
(2)Spark 没有提供文件管理系统,不能存储数据,所以,它必须和其他的分布式文件系统进行集成才能运作
(3)Spark 可以使用 Hadoop 的 HDFS 或者其他云数据平台进行数据存储,但是一般使用HDFS;