Hive 安装、配置、数据导入和使用
Hive 安装、配置、数据导入和使用
- Hive 下载
- Hive 的环境
- Hive 配置
- Hive 数据导入
- 总结
Hive 下载
首先到Apache Hive TM下载软件

随便写一个,都比较慢

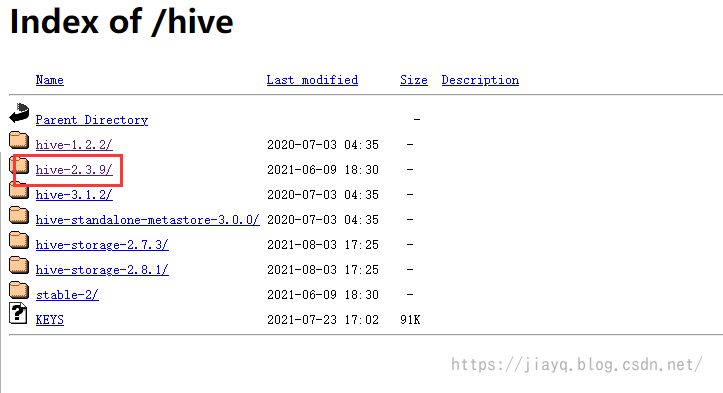
下载二进制文件
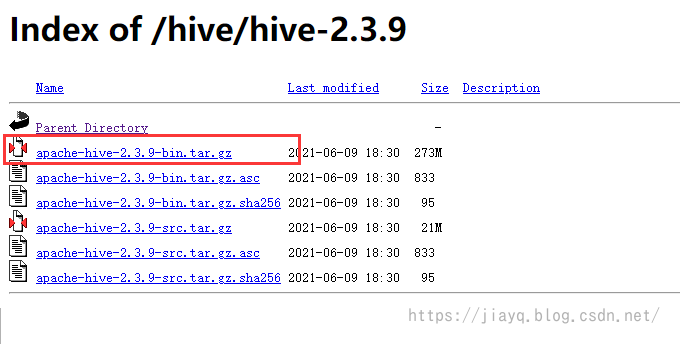
Hive 的环境
首先将下载的压缩包上传到linux中
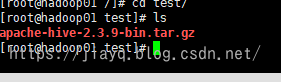
将下载后的压缩包解压到合适的位置tar -zxvf apache-hive-2.3.9-bin.tar.gz
![]()
然后配置环境变量vi ~/.bash_profile
将HIVE_HOME配置到Path中
增加
HIVE_HOME=/hive
export HIVE_HOME
PATH=$PATH:$HIVE_HOME/bin
Hive 配置
此时我们启动hadoop后,就可以直接启动hive了。(如果你的JAVA_HOME,HADOOP_HOME都正确配置)
首先启动hadoophadoop安装_a18792721831的博客-CSDN博客
启动hdfs
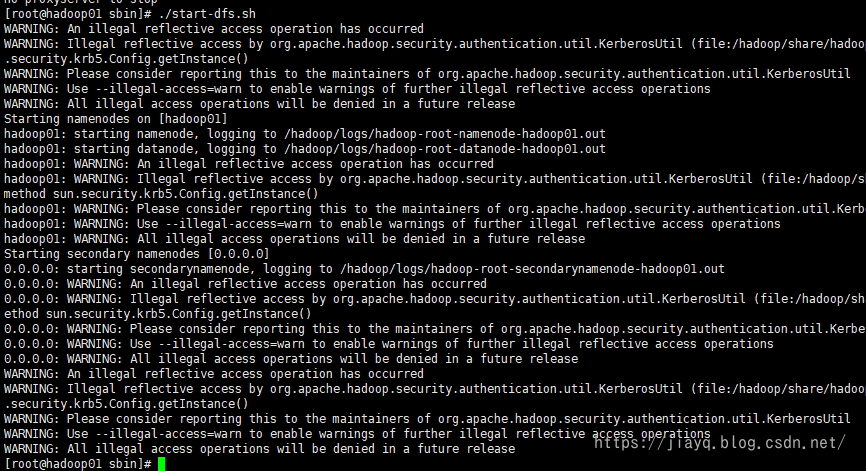
访问hadoop01:9870验证hdfs是否启动成功
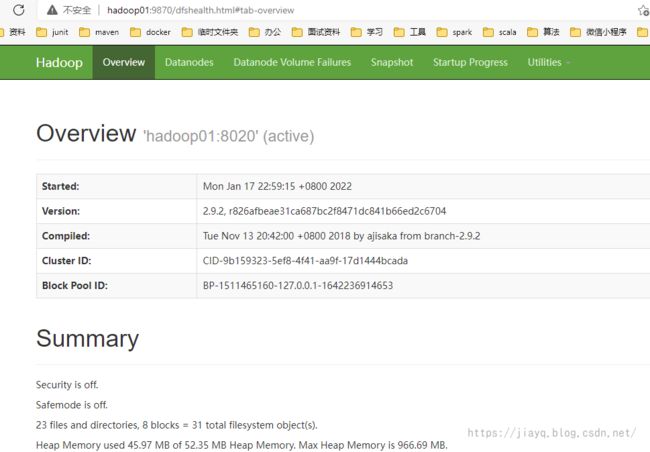
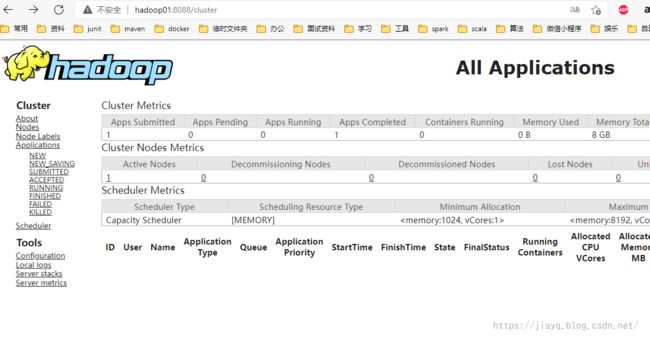
然后启动yarn

在浏览器中验证hadoop01:8088
在hive的conf目录中拷贝hive-default.xml.template文件,并重命名为hive-site.xml
删除原有的配置,并增加如下配置
<property>
<name>javax.jdo.option.ConnectionURLname>
<value>jdbc:mysql://hadoop01:3306/hive?createDatabaseIfNotExist=truevalue>
property>
<property>
<name>javax.jdo.option.ConnectionDriverNamename>
<value>com.mysql.cj.jdbc.Drivervalue>
property>
<property>
<name>javax.jdo.option.ConnectionUserNamename>
<value>rootvalue>
property>
<property>
<name>javax.jdo.option.ConnectionPasswordname>
<value>123456value>
property>
<property>
<name>hive.metastore.schema.verificationname>
<value>falsevalue>
property>
需要在linux中安装mysql,执行yum install -y mariadb-server即可

安装后执行systemctl start mariabd启动,执行systemctl status mariadb查看状态
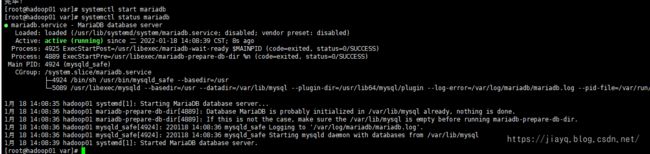
启动mariadb后,初始化root密码,执行mysql_secure_installation

根据提示选择就行,我设置的root密码是123456
设置完成后使用systemctl restart mariadb重启
然后进入mysql,设置root用户允许远程登录
mysql -u root -p登录
然后执行GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY '123456';
我为了防止密码记错,就设置相同的密码
'root'@'%', root表示远端登录使用的用户名,%表示允许任意ip登录,可将指定ip替换掉%, root与%可以自定义
IDENTIFIED BY '123456' 这个123456 是登录时的使用的密码,(方便记忆就用了root,生产环境一定要替换掉)

最后执行flush privileges;刷新
然后使用工具测试一下,root是否可以远程登录
然后在maven仓库下载mysql的连接驱动
并拷贝到hive的lib目录下
要使用hive还需要进行初始化

执行schematool -initSchema -dbType mysql初始化数据库
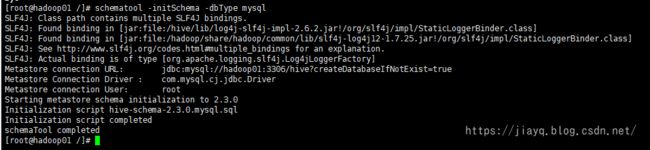
初始化完成后,会在mysql中创建一些元数据相关的表
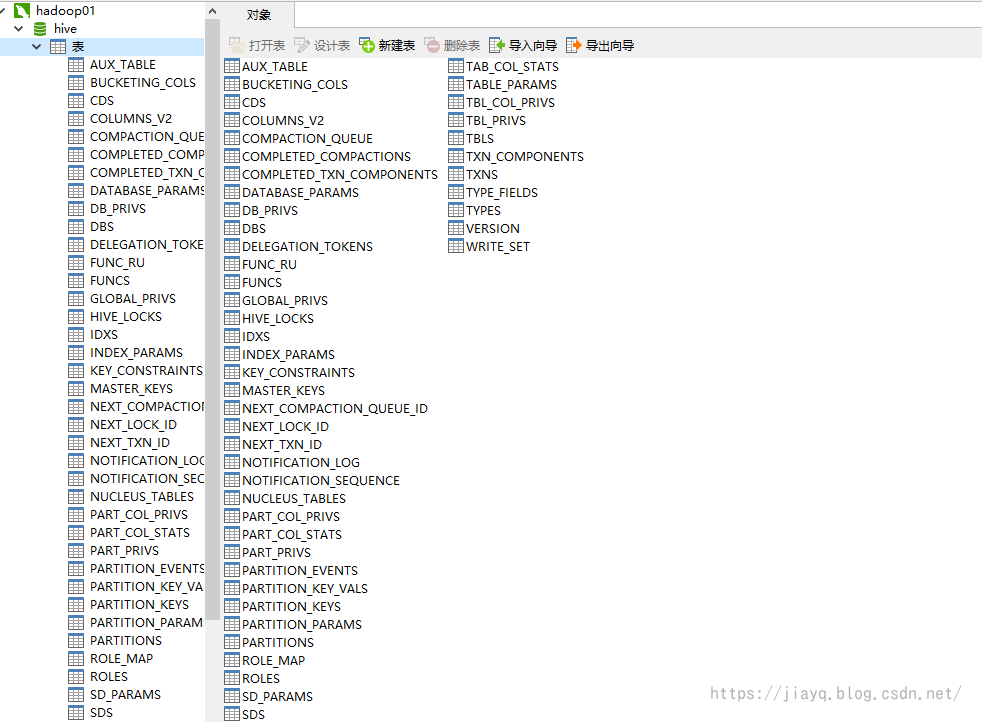
初始化完成后,就可以使用hive了

Hive 数据导入
现在hive中什么数据都没有,我们首先在hive中创建一张表,然后把一些数据导入,这样我们就可以快乐的使用hive ql玩耍了。
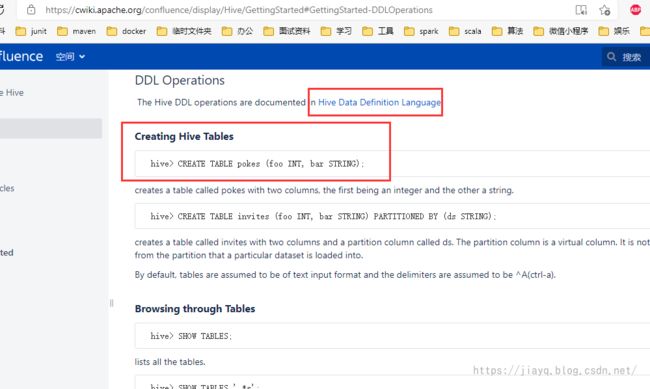
打开GettingStarted - Apache Hive - Apache Software Foundation,在目录中找到DDL

可以看到,DDL很简单,当然我是指简单入门级的使用,很简单,如果深入,那么一定需要一定的时间去研究的。
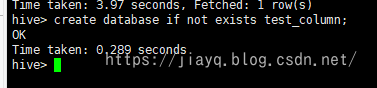
首先创建我们自己玩的数据库

create database if not exists test_column;
然后切换到创建的数据库操作
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-PccRQvgL-1642520963121)(https://gitee.com/jyq_18792721831/blogImages/raw/master/img/20220118212512.png)]
use test_column;
准备的测试数据,其实就是mysql中information_schema数据库中的COLUMNS表
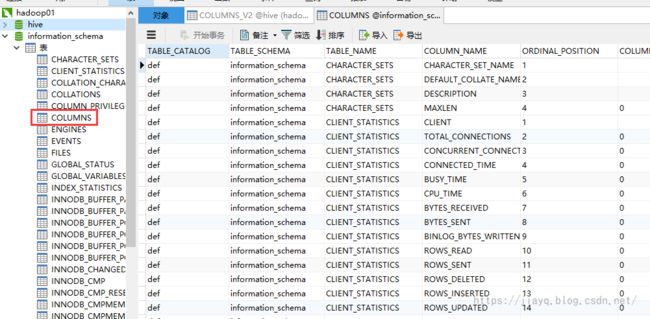
这个表的列很多,正好用来体验hive。
首先是创建表的语句
CREATE TABLE IF NOT EXISTS columns(table_catalog STRING, table_schema STRING, table_name STRING, column_name STRING, ordinal_position INT, column_default STRING, is_nullable STRING, data_type STRING, character_maximum_length INT, character_octet_length INT, numberic_precision INT, numberic_scale INT, dateime_precision STRING, character_set_name STRING, collation_name STRING, column_type STRING, column_key STRING, extra STRING, privileges STRING, column_comment STRING) row format delimited fields terminated by ',';
row format delimited fields terminated by ','意思是行中的每个属性按照逗号分割,对应csv文件。
![]()
接着从navicat中把数据导出来
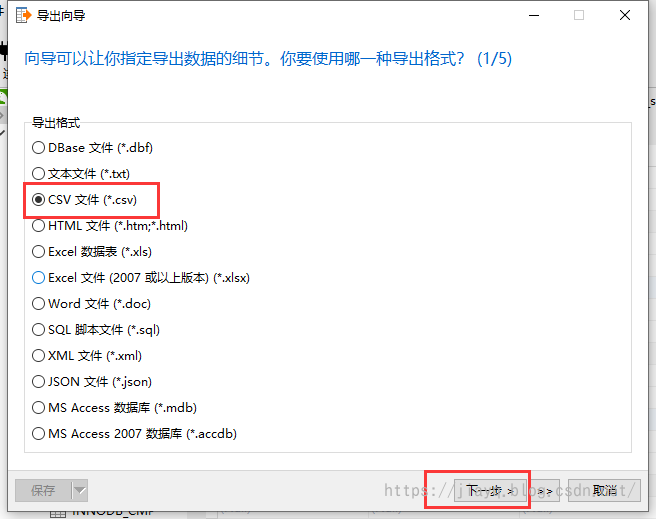
选择csv文件,其实什么文件都一样,大部分文件都支持
查看导出的数据

数据文件上传到服务器中,随便放到哪里
![]()
接着我们就需要操作数据了,还是看官方文档
选择数据导入
我们使用最新版本的命令,注意自己的版本
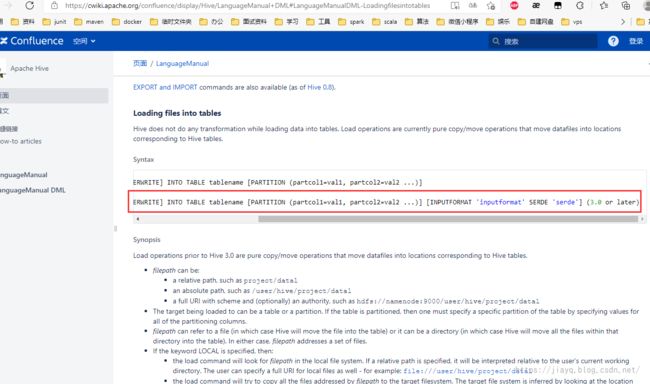
使用如下hive ql:
LOAD DATA LOCAL INPATH '/hive/COLUMNS.csv' INTO TABLE columns;

我们查询下
select count(1) from columns;
执行后会提交一个mapreduce的任务
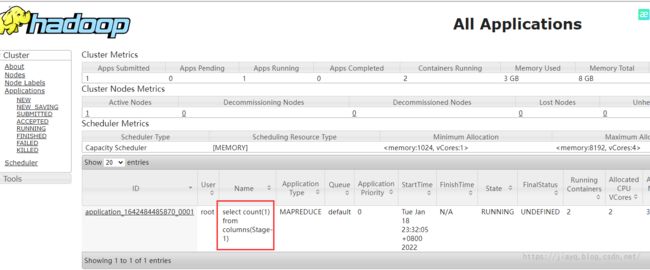
查看任务的信息

这是任务的详情
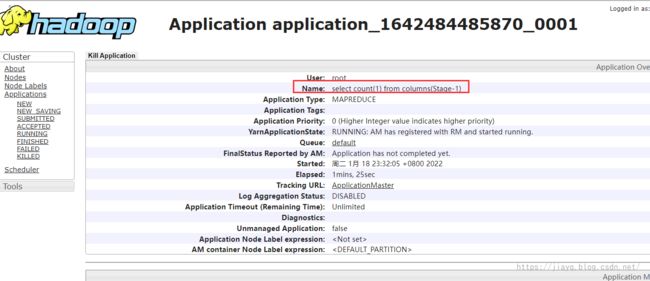
执行完成后,就会返回结果
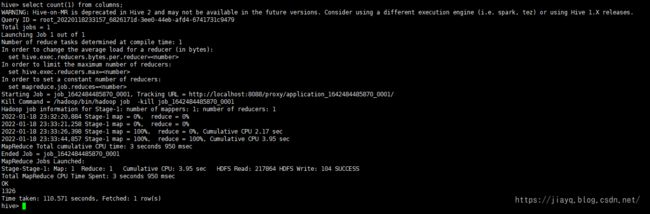
我们可以看下和数据库的对比

是相同的.
其他的一些使用
select * from columns;
比如查询data_type 为varchar的列有多少?
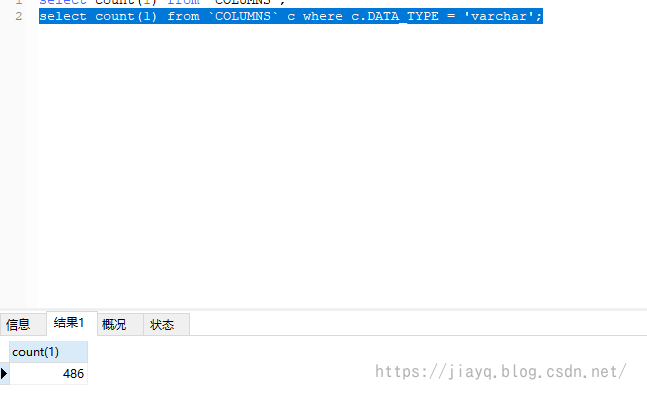
hive : select count(1) from columns c where c.data_type = 'varchar';
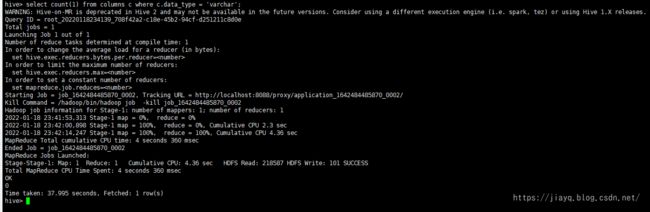
竟然是0,看来是我的脚本写的有问题啊。
总结
虽然看起来hive比mysql慢的多得多了,确实如此,在小数据量的时候,关系型数据库比较快,但是当有非常大的数据量的时候,比如亿,或者更大数据量的时候,hive的能力就体现出来了。因为hive是在hadoop的基础上运行的。
hive将hive ql解析为hadoop的任务,然后使用mapreduce或者spark或者tez的计算引擎进行执行,大大简化了我们直接使用计算的引擎的难度。
说实话,在上面中,用hive和mysql比速度,实际上是用关系型数据库的长处去比hive的短处,特别是在小数据量的情况下。
不管怎么说,到了这里,hive的搭建,以及hive的初步使用,有了一定的体验,至少直观的感受了hive是在大数据生态环境中的作用。