【Pytorch学习笔记】MNIST数据集的训练及简单应用(一)
零、简单介绍
pytorch是一个开源的深度学习的框架。其本质是一个基于Python的科学计算包,能提供最大的灵活性和效率。
MNIST数据集包含70,000张手写数字的图像及标签。其中 60,000张用于训练,10,000张用于测试。图像是灰度的,28x28像素,并且居中的,以减少预处理和加快运行。如下图所示:

CNN卷积神经网络,参见这个介绍。一个简单的卷积神经网络可包括卷积层,池化层,和全连接层。就是说,训练好之后,给这个网络输入一张手写数字的图片,经过这些个层之后,就可以输出这个数字。训练的过程就是不断根据训练集中的具体的图片及其对应的标签(即数字),来不断调整网络中的各参数以更新优化这个网络,使其能达到不错的准确率的过程。
OpenCV,功能强大的数字图像处理库,这个网上的介绍就太多了。
一、效果展示

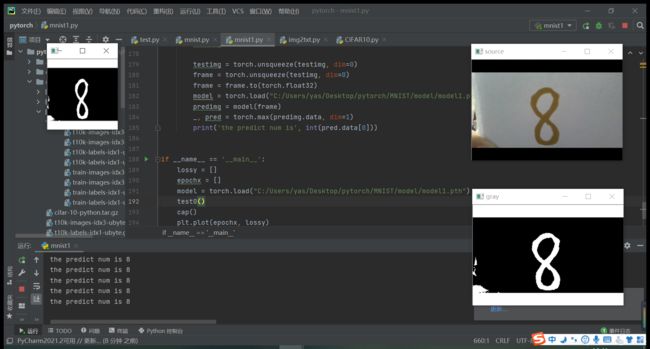
其中:右上角的窗口展示的是通过笔记本摄像头捕获的原图像;右下角窗口展示的是预处理之后,即转换为灰度图,滤波,反向二值化之后的图像;左上角展示的是即将输入进模型中的图像;下方窗口输出的predicted number即是模型输出的预测结果,是不断刷新的。
二、功能实现
整体分为两个大的部分:1.训练模型;2.使用模型。
首先是训练模型:参照的这个教程
第一步:导入需要的包
import torch
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision import transforms
import torch.nn.functional as F
#import cv2
#import os
import matplotlib.pyplot as plt其中torch用于实现深度学习,pyplot实现绘图以可视化训练结果
第二步:准备数据集(包括训练集和测试集)
batch_size = 64 #设置batch大小
transform = transforms.Compose([
transforms.ToTensor(), #转换为张量
transforms.Normalize((0.1307,), (0.3081,)) #设定标准化值
])
#训练集
train_dataset = datasets.MNIST(
root='./data',
train=True,
transform=transform,
download=True)
#测试集
test_dataset = datasets.MNIST(
root='./data',
train=False,
transform=transform,
download=True)
#训练集加载器
train_loader = DataLoader(dataset=train_dataset,
batch_size=batch_size,
shuffle=True)
#测试集加载器
test_loader = DataLoader(dataset=test_dataset,
batch_size=batch_size,
shuffle=False)
首先,设定batch大小(几句话搞懂什么是batch);定义transform操作。这个操作的目的是对原始图像进行预处理,主要是要将其转换为张量,才能送进神经网络中。
其次,定义训练集,测试集。这里dataset的目的是定义MNIST数据集,使用提供的detasets.MNIST()函数。里边需要指定路径,是否为训练集,transform操作(就是刚才定义好的),是否自动从网上下载等。
然后,定义训练集、测试集的加载器。类似一个集合(?),将训练集,测试集准备好放在里边。需要设定的参数有数据来源(即刚才的dataset),batch大小,是否需要打乱顺序等。
第三步:设计模型
# 设计模型 CNN
class CNN(torch.nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.conv1 = torch.nn.Conv2d(1, 10, kernel_size=(5,5)) #卷积层1
self.conv2 = torch.nn.Conv2d(10, 20, kernel_size=(5,5)) #卷积层2
self.pooling = torch.nn.MaxPool2d(2) #池化层
self.fc1 = torch.nn.Linear(320, 256) #全连接层1
self.fc2 = torch.nn.Linear(256, 128) #全连接层2
self.fc3 = torch.nn.Linear(128, 10) #全连接层3
def forward(self, x):
batch_size = x.size(0)
x = F.relu(self.pooling(self.conv1(x))) #卷积层1->池化层->激活函数Relu
x = F.relu(self.pooling(self.conv2(x))) #卷积层2->池化层->激活函数Relu
x = x.view(batch_size, -1) #改变张量的维度
x = self.fc1(x) #全连接层1
x = self.fc2(x) #全连接层2
x = self.fc3(x) #全连接层3
return x
model = CNN() #实例化(?)模型为model定义了2个卷积层和3个全连接层。

整体如上图所示,(其中池化层和激活函数的顺序交换了一下)
第四步:构造损失和优化函数
# 构造损失函数和优化函数
# 损失
criterion = torch.nn.CrossEntropyLoss()
# 优化
optimizer = torch.optim.SGD(model.parameters(), lr=0.1, momentum=0.5)
损失函数使用交叉熵损失,适用于多分类问题
优化函数使用随机梯度下降算法SGD,学习率设置为0.1
第五步:定义训练函数
def train(epoch):
running_loss = 0.0 #每一轮训练重新记录损失值
for batch_idx, data in enumerate(train_loader, 0): #提取训练集中每一个样本
inputs, target = data
optimizer.zero_grad() #将梯度归零
#print(inputs.shape)
outputs = model(inputs) #代入模型
loss = criterion(outputs, target) #计算损失值
loss.backward() #反向传播计算得到每个参数的梯度值
optimizer.step() #梯度下降参数更新
running_loss += loss.item() #损失值累加
if batch_idx % 300 == 299: #每300个样本输出一下结果
print('[%d,%5d] loss: %.3f' % (epoch + 1, batch_idx + 1, running_loss / 300))
running_loss = 0.0 # (训练轮次, 该轮的样本次, 平均损失值)
return running_loss
第六步:定义测试函数
def test():
correct = 0
total = 0
with torch.no_grad(): #执行计算,但不希望在反向传播中被记录
for data in test_loader: #提取测试集中每一个样本
images, labels = data
outputs = model(images) #带入模型
_, pred = torch.max(outputs.data, dim=1) #获得结果中的最大值
total += labels.size(0) #测试数++
correct += (pred == labels).sum().item() #将预测结果pred与标签labels对比,相同则正确数++
"""
print("imageshape", images.shape)
print("outputshape", outputs.shape)
print("_ is", _.shape, _)
print("pred is", pred.shape, pred)
print("label is", labels)
"""
print('%d %%' % (100 * correct / total)) #输出正确率
简单定义一下主函数
if __name__ == '__main__':
lossy = [] #定义存放纵轴数据(损失值)的列表
epochx = [] #定义存放横轴数据(训练轮数)的列表
#path = "C:/Users/yas/Desktop/pytorch/MNIST/model/model1.pth"
for epoch in range(10): #训练10轮
epochx.append(epoch) #将本轮轮次存入epochy列表
lossy.append(train(epoch)) #执行训练,将返回值loss存入lossy列表
test() #每轮训练完都测试一下正确率
#torch.save(model, path)
#model = torch.load("C:/Users/yas/Desktop/pytorch/MNIST/model/model1.pth")
#可视化一下训练过程
plt.plot(epochx, lossy)
plt.grid()
plt.show()
到这就可以开始进行训练了。
输出如图:
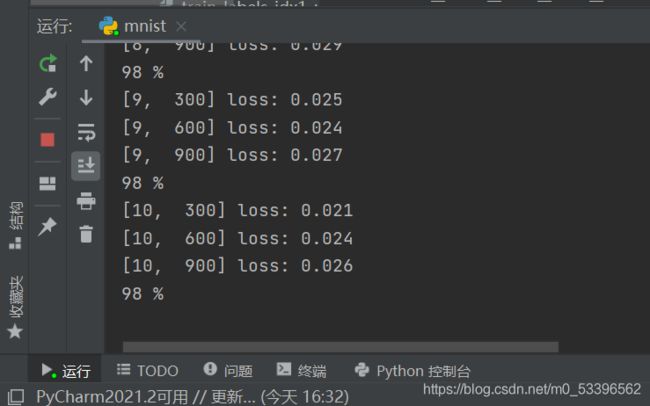
训练过程如图:

因为训练轮数太少,看不出有收敛的迹象
先写这么多
谢谢阅读!
下篇在这里