ECCV2020 | SNE-RoadSeg:一种基于表面法向量提取的道路可行驶区域分割方法
点击上方“AI算法修炼营”,选择“星标”公众号
精选作品,第一时间送达

这篇文章收录于ECCV2020,是一篇关于无碰撞空间区域分割的文章,整体效果很不错。最主要的核心思想是在表面发现估计器的设计,在得到表面法线后将其用于分割网络的编码器环节,并在特征融合部分,借鉴了DenseNet的思想,进行密集连接。网络的计算量和参数量文中并没有比较,应该做不到实时。
论文地址:https://arxiv.org/abs/2008.11351
代码地址:https://github.com/hlwang1124/SNE-RoadSeg
Freespace无碰撞空间检测是自动驾驶汽车视觉感知的重要组成部分。近年来,数据融合data-fusion卷积神经网络CNN架构大大改善了语义场景分割算法的性能。通常,可以将自由空间假设为一个地面平面,在这个平面上,各点具有相似的表面法线。因此,在本文中,首先介绍了一个名为表面法线估计器( surface normal estimator ,SNE)的新型模块,该模块可以从密集的深度/视差图像中高精度和高效率地推断出表面法线信息。此外,提出了一种称为RoadSeg的数据融合CNN架构,该架构可以从RGB图像和推断出的表面法线信息中提取并融合特征,以进行准确的自由空间检测。同时,出于研究目的,我们发布了在不同光照和天气条件下收集的大规模合成自由空间检测数据集,名为Ready-to-Drive(R2D)道路数据集。实验结果表明,本文提出的SNE模块可以使所有最新的CNN架构都可用于自由空间检测,而本文所提出的SNE-RoadSeg可以在不同数据集中获得最佳的整体性能。
简介
自动驾驶汽车是科幻电影和系列电影中的一个常见场景,但由于人工智能的兴起,在您的车库前院挑选一辆这样的汽车的幻想已经变成了现实。驾驶场景下对周围环境的理解是自动汽车的一项重要任务,随着人工智能的最新进展,它有了很大的飞跃。无碰撞空间(Collision-free space,简称freespace)检测是驾驶场景理解的一个基本组成部分。自由空间检测方法一般将RGB或深度/差值图像中的每个像素分类为可驾驶或不可驾驶。这种像素级的分类结果会被自主系统中的其他模块所利用,如轨迹预测和路径规划,以确保自动驾驶汽车能够在复杂的环境中安全航行。
现有的自由空间检测方法可以分类为传统方法或基于机器/深度学习的方法。传统方法通常使用显式几何模型来构造自由空间,并使用优化方法找到其最佳系数。《B-spline modeling of road surfaces with an application to free-space estimation.》是一种典型的传统自由空间检测算法,其中通过将B样条模型拟合到2D视差直方图(通常称为v-视差图像)上的道路视差投影来执行道路分割。随着机器/深度学习最新进展的提出,自由空间检测通常被视为语义驱动场景分割问题,其中使用卷积神经网络(CNN)来学习最佳解决方案。例如,《Monocular semantic occu-pancy grid mapping with convolutional variational encoder–decoder networks.》采用编码器-解码器体系结构在鸟瞰图中分割RGB图像,以进行端到端自由空间检测。最近,许多研究人员已采用数据融合CNN架构来进一步提高语义图像分割的准确性。例如,《Fusenet: Incorporating depth intosemantic segmentation via fusion-based cnn architecture.》通过数据融合CNN架构将深度信息整合到常规语义分割中,极大地提高了驾驶场景分割的性能。
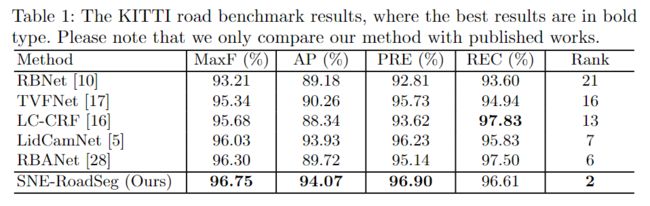
在本文中,首先介绍一种名为表面法线估计器(SNE)的新型模块,该模块可以从密集的视差/深度图像中以高精度和高效率推断出表面法线信息。此外,设计了一种名为RoadSeg的数据融合CNN架构,该架构能够将RGB和表面法线信息合并到语义分割中,以进行准确的自由空间检测。由于现有的具有各种光照和天气条件的自由空间检测数据集既没有视差/深度信息也没有自由空间ground truth,因此本文创建了一个大规模的合成自由空间检测数据集,称为“ Ready-to-Drive(R2D)”道路数据集(包含11430对RGB和深度图像),涵盖了在不同的光照和天气条件下的道路数据,同时R2D道路数据集也可以公开用于研究目的。为了验证引入的SNE模块的可行性和有效性,实验部分使用了三个道路数据集(KITTI 、SYNTHIA [和我们的R2D)训练了十个最新的CNN(六个单模态CNN网络和四个数据融合CNN网络),并且对嵌入或不嵌入SNE模块进行对比。实验表明,本文提出的SNE模块可以使所有这些CNN在自由空间检测任务上有性能提升。同样,SNE-RoadSeg方法在自由空间检测方面也优于其他CNN,其整体性能在KITTI道路基准benchmark上排名第二。
本文方法:SNE-RoadSeg
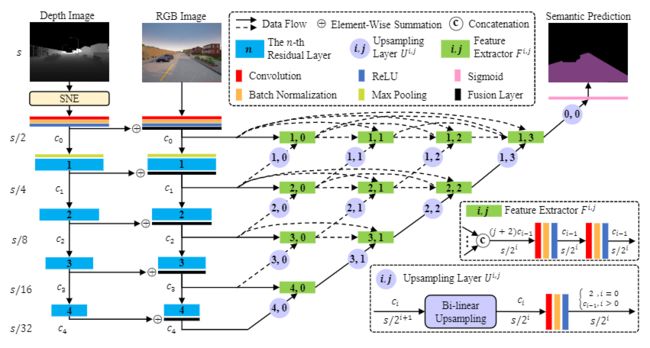
图1:SNE-RoadSeg的网络结构。它由SNE模块,一个RGB编码器,一个表面法线编码器和一个具有紧密连接的skip连接的解码器组成。s代表RGB的输入分辨率和深度图像。cn代表不同级别的特征图通道数。
1、SNE

SNE是基于最近的工作《Three-filters-to-normal: An accurate and ultrafast surface normal estimato》(3F2N)开发出来的。其架构如图2所示。对于透视相机模型,可以使用以下公式将欧几里得坐标系中的3D点与2D图像像素点连接起来:

其中,K是相机内在矩阵,(xo,yo)是图像中心;fx和fy是相机焦距(以像素为单位)。估计P表面的法线向量的方法是:

由上面两个式子可以得出:

对x、y分别求微分可以得到:
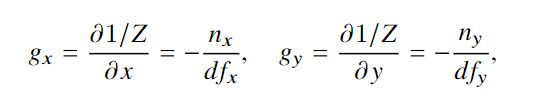
如图2所示,可以分别用水平和垂直图像梯度滤波器对反深度图像1 / Z(或视差图像与深度成反比)进行卷积来分别近似。对上面的式子进行变形,可以得到nx、ny的表达式:
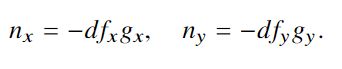
而nz为:

由此,获得的表面法向量为:
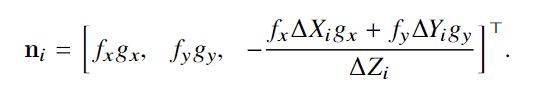
由于任何归一化表面法线都可以投影在中心为(0,0,0)且半径为1的球体上,因此最佳表面法线也可以投影在同一球体上的某个地方,用以下球坐标公式表示:
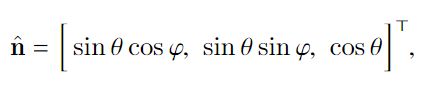
其中,
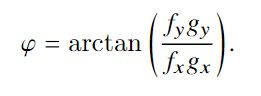

具体推导细节可以参考原文及其代码实现。
2、RoadSeg
U-Net 已经证明了使用跳跃连接来恢复整个空间分辨率的有效性。但是,它的跳跃连接仅在编码器和解码器的相同比例的特征图上强制聚合,作者认为这是不必要的约束。受到DenseNet 的启发,本文提出了RoadSeg,它利用密集连接的跳跃连接在解码器中实现灵活的特征融合。
如图1所示,本文提出的RoadSeg也采用了流行的编解码器架构。采用RGB编码器和表面法线编码器分别从RGB图像和推断的表面法线信息中提取特征图。提取的RGB和表面法线特征图通过逐元素求和进行分层融合。然后通过密集连接的跳跃连接在融合器中再次融合特征图,以恢复特征图的分辨率。在RoadSeg的末尾,使用一个Sigmoid层来生成用于语义驾驶场景分割的概率图。
本文使用ResNet 作为RGB和表面法线编码器的主干网络,它们的结构彼此相同。具体来说,初始块由卷积层,批处理归一化层和ReLU激活函数层组成。然后,依次采用最大池化层和四个残差层,以逐渐降低分辨率并增加特征图通道的数量。ResNet具有五种体系结构:ResNet-18,ResNet-34,ResNet-50,ResNet-101和ResNet-152。RoadSeg对于ResNet-18和ResNet-34,c0-c4的通道数分别为64、64、128,256和512,对于ResNet-50,ResNet-101和ResNet-152,c0-c4的通道数分别为64、256、512、1024和2048。 。
解码器由两类不同的模块组成:特征提取器和上采样层,这两类模块密集连接,实现灵活的特征融合。采用特征提取器从融合后的特征图中提取特征,并保证特征图分辨率不变。采用上采样层来提高分辨率,减少特征图通道。特征提取器中的3个卷积层和上采样层的卷积核大小相同,为3×3,步长相同,padding值相同,为1。
实验与结果
数据集:DIODE dataset 、The KITTI road dataset 、The SYNTHIA road dataset 、本文的R2D road dataset(sites.google.com/view/sne-roadseg)
评价指标:AAE(average angular error)、准确率和召回率、F-score、IoU等

该部分使用这三个数据集来训练10个最先进的CNNs,包括6个单模态CNNs和4个数据融合CNNs。用三种设置来进行单模态CNNs的实验:a)用RGB图像进行训练,b)用深度图像进行训练,c)用表面法线图像(用本文的SNE来从深度图像中生成)进行训练,分别表示为RGB、Depth和SNE-Depth。同样,数据融合CNNs的实验也是使用两种设置进行的:使用RGB-D视觉数据进行训练,有嵌入和没有嵌入SNE,分别表示为RGBD和SNE-RGBD。为了比较提出的RoadSeg和其他最先进的CNNs之间的性能,用与数据融合CNNs相同的设置在三个数据集上训练RoadSeg。此外,还重新训练了SNE-RoadSeg,以便将结果提交给KITTI道路benchmark数据集上。
1、Performance Evaluation of Our SNE
准确度的评价:
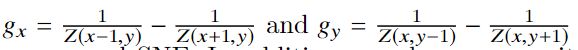
从下图可以看出,在室内和室外场景中,我们提出的SNE均优于SRI和LINE-MOD。
2、Performance Evaluation of Our SNE-RoadSeg




KITTI road benchmark上的对比

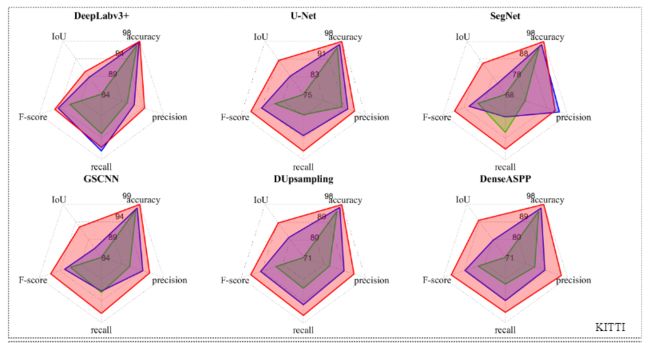
消融实验

更多细节可参考论文原文。

