复习专栏之---设计模式(java)
设计模式(Design Patterns)
——可复用面向对象软件的基础
设计模式是一套被反复使用、多数人知晓的、经过分类编目的、代码设计经验的总结。使用设计模式是为了可重用代码、让代码更容易被他人理解、保证代码可靠性。它不同于框架,只是一种书写代码的习惯,初期刻意使用,受益无穷。
它是由很多程序员总结出来的最佳实践。曾经在刚开始写项目的时候学习过设计模式,在开发过程中,也主动或者被动的使用过。现在写代码虽说不会特意明确在用哪种设计模式,但潜移默化的写出来公认的最佳实践代码,毕竟看的比较清爽。为什么再看一遍设计模式,主要有几个原因:第一,很多优秀的源码基本都使用了设计模式,明确设计模式能够更好的看源码。第二,很多中间件设计理念也是基于设计模式的,还有其他的语言,都有自己的设计最佳实践。对于我来说,设计模式始于java,不止于java。第三,有了这种规范,可以更好的和他人沟通,言简意赅
一、设计模式分类
总体来说设计模式分为三大类:
- 创建型模式,共五种:(简单工厂模式)、工厂方法模式、抽象工厂模式、单例模式、建造者模式、原型模式。
- 结构型模式,共七种:适配器模式、装饰器模式、代理模式、外观模式、桥接模式、组合模式、享元模式。
- 行为型模式,共十一种:策略模式、模板方法模式、观察者模式、迭代子模式、责任链模式、命令模式、备忘录模式、状态模式、访问者模式、中介者模式、解释器模式。
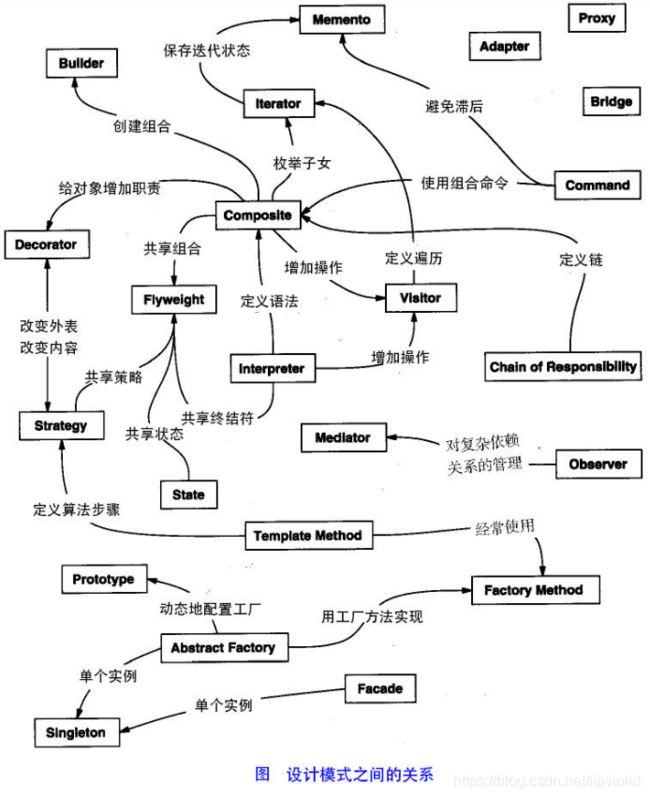
- 其实还有两类:并发型模式和线程池模式。用一个图片来整体描述一下:
二、设计模式七大原则
- 单一职责原则 (Single Responsibility Principle)
- 开放-关闭原则 (Open-Closed Principle)
- 里氏替换原则 (Liskov Substitution Principle)
- 依赖倒转原则 (Dependence Inversion Principle)
- 接口隔离原则 (Interface Segregation Principle)
- 迪米特法则(Law Of Demeter)
- 组合/聚合复用原则 (Composite/Aggregate Reuse Principle)
1.单一职责原则 SRP
单一职责原则表示一个模块的组成元素之间的功能相关性。从软件变化的角度来看,就一个类而言,应该仅有一个让它变化的原因;通俗地说,即一个类只负责一项职责。
假设某个类 P 负责两个不同的职责,职责 P1 和 职责 P2,那么当职责 P1 需求发生改变而需要修改类 P,有可能会导致原来运行正常的职责 P2 功能发生故障。
我们假设一个场景:
有一个动物类,它会呼吸空气,用一个类描述动物呼吸这个场景:
class Animal{
public void breathe(String animal){
System.out.println(animal + "呼吸空气");
}
}
public class Client{
public static void main(String[] args){
Animal animal = new Animal();
animal.breathe("牛");
animal.breathe("羊");
animal.breathe("猪");
}
}
在后来发现新问题,并不是所有的动物都需要呼吸空气,比如鱼需要呼吸水,修改时如果遵循单一职责原则的话,那么需要将 Animal 类进行拆分为陆生类和水生动物类,代码如下:
class Terrestrial{
public void breathe(String animal){
System.out.println(animal + "呼吸空气");
}
}
class Aquatic{
public void breathe(String animal){
System.out.println(animal + "呼吸水");
}
}
public class Client{
public static void main(String[] args){
Terrestrial terrestrial = new Terrestrial();
terrestrial.breathe("牛");
terrestrial.breathe("羊");
terrestrial.breathe("猪");
Aquatic aquatic = new Aquatic();
aquatic.breathe("鱼");
}
}
在实际工作中,如果这样修改的话开销是很大的,除了将原来的 Animal 类分解为 Terrestrial 类和 Aquatic 类以外还需要修改客户端,而直接修改类 Animal 类来达到目的虽然违背了单一职责原则,但是花销却小的多,代码如下:
class Animal{
public void breathe(String animal){
if("鱼".equals(animal)){
System.out.println(animal + "呼吸水");
}else{
System.out.println(animal + "呼吸空气");
}
}
}
public class Client{
public static void main(String[] args){
Animal animal = new Animal();
animal.breathe("牛");
animal.breathe("羊");
animal.breathe("猪");
animal.breathe("鱼");
}
}
可以看得出,这样的修改显然简便了许多,但是却存在着隐患,如果有一天有需要加入某类动物不需要呼吸,那么就要修改 Animal 类的 breathe 方法,而对原有代码的修改可能会对其他相关功能带来风险,也许有一天你会发现输出结果变成了:“牛呼吸水” 了,这种修改方式直接在代码级别上违背了单一职责原则,虽然修改起来最简单,但隐患却最大的。
另外还有一种修改方式:
class Animal{
public void breathe(String animal){
System.out.println(animal + "呼吸空气");
}
public void breathe2(String animal){
System.out.println(animal + "呼吸水");
}
}
public class Client{
public static void main(String[] args){
Animal animal = new Animal();
animal.breathe("牛");
animal.breathe("羊");
animal.breathe("猪");
animal.breathe2("鱼");
}
}
可以看出,这种修改方式没有改动原来的代码,而是在类中新加了一个方法,这样虽然违背了单一职责原则,但是它并没有修改原来已存在的代码,不会对原本已存在的功能造成影响。
那么在实际编程中,需要根据实际情况来确定使用哪种方式,只有逻辑足够简单,才可以在代码级别上违背单一职责原则。
总结:
SRP 是一个简单又直观的原则,但是在实际编码的过程中很难将它恰当地运用,需要结合实际情况进行运用。
单一职责原则可以降低类的复杂度,一个类仅负责一项职责,其逻辑肯定要比负责多项职责简单。
提高了代码的可读性,提高系统的可维护性。
2.开放-关闭原则 OCP
开放-关闭原则表示软件实体 (类、模块、函数等等) 应该是可以被扩展的,但是不可被修改。(Open for extension, close for modification)
如果一个软件能够满足 OCP 原则,那么它将有两项优点:
能够扩展已存在的系统,能够提供新的功能满足新的需求,因此该软件有着很强的适应性和灵活性。
已存在的模块,特别是那些重要的抽象模块,不需要被修改,那么该软件就有很强的稳定性和持久性。
举个简单例子,这里有个生产电脑的公司,根据输入的类型,生产出不同的电脑,代码如下:
interface Computer {}
class Macbook implements Computer {}
class Surface implements Computer {}
class Factory {
public Computer produceComputer(String type) {
Computer c = null;
if(type.equals("macbook")){
c = new Macbook();
}else if(type.equals("surface")){
c = new Surface();
}
return c;
}
}
显然上面的代码违背了开放 - 关闭原则,如果需要添加新的电脑产品,那么修改 produceComputer 原本已有的方法,正确的方式如下:
interface Computer {}
class Macbook implements Computer {}
class Surface implements Computer {}
interface Factory {
public Computer produceComputer();
}
class AppleFactory implements Factory {
public Computer produceComputer() {
return new Macbook();
}
}
class MSFactory implements Factory {
public Computer produceComputer() {
return new Surface();
}
}
正确的方式应该是将 Factory 抽象成接口,让具体的工厂(如苹果工厂,微软工厂)去实现它,生产它们公司相应的产品,这样写有利于扩展,如果这是需要新增加戴尔工厂生产戴尔电脑,我们仅仅需要创建新的电脑类和新的工厂类,而不需要去修改已经写好的代码。
总结:
OCP 可以具有良好的可扩展性,可维护性。
不可能让一个系统的所有模块都满足 OCP 原则,我们能做到的是尽可能地不要修改已经写好的代码,已有的功能,而是去扩展它。
3.里氏替换原则 LSP
在编程中常常会遇到这样的问题:有一功能 P1, 由类 A 完成,现需要将功能 P1 进行扩展,扩展后的功能为 P,其中P由原有功能P1与新功能P2组成。新功能P由类A的子类B来完成,则子类B在完成新功能P2的同时,有可能会导致原有功能P1发生故障。
里氏替换原则告诉我们,当使用继承时候,类 B 继承类 A 时,除添加新的方法完成新增功能 P2,尽量不要修改父类方法预期的行为。
里氏替换原则的重点在不影响原功能,而不是不覆盖原方法。
继承包含这样一层含义:父类中凡是已经实现好的方法(相对于抽象方法而言),实际上是在设定一系列的规范和契约,虽然它不强制要求所有的子类必须遵从这些契约,但是如果子类对这些非抽象方法任意修改,就会对整个继承体系造成破坏。而里氏替换原则就是表达了这一层含义。
举个例子,我们需要完成一个两数相减的功能:
class A{
public int func1(int a, int b){
return a-b;
}
}
后来,我们需要增加一个新的功能:完成两数相加,然后再与100求和,由类B来负责。即类B需要完成两个功能:
两数相减
两数相加,然后再加100
由于类A已经实现了第一个功能,所以类B继承类A后,只需要再完成第二个功能就可以了,代码如下:
class B extends A{
public int func1(int a, int b){
return a+b;
}
public int func2(int a, int b){
return func1(a,b)+100;
}
}
我们发现原来原本运行正常的相减功能发生了错误,原因就是类 B 在给方法起名时无意中重写了父类的方法,造成了所有运行相减功能的代码全部调用了类 B 重写后的方法,造成原来运行正常的功能出现了错误。在实际编程中,我们常常会通过重写父类的方法来完成新的功能,这样写起来虽然简单,但是这样往往也增加了重写父类方法所带来的风险。
里氏替换原则通俗的来讲就是:子类可以扩展父类的功能,但不能改变父类原有的功能。
4.依赖倒转原则 DIP
定义:高层模块不应该依赖低层模块,二者都应该于抽象。进一步说,抽象不应该依赖于细节,细节应该依赖于抽象。
举个例子, 某天产品经理需要添加新的功能,该功能需要操作数据库,一般负责封装数据库操作的和处理业务逻辑分别由不同的程序员编写。
封装数据库操作可认为低层模块,而处理业务逻辑可认为高层模块,那么如果处理业务逻辑需要等到封装数据库操作的代码写完的话才能添加的话讲会严重拖垮项目的进度。
正确的做法应该是处理业务逻辑的程序员提供一个封装好数据库操作的抽象接口,交给低层模块的程序员去编写,这样双方可以单独编写而互不影响。
依赖倒转原则的核心思想就是面向接口编程,思考下面这样一个场景:母亲给孩子讲故事,只要给她一本书,她就可照着书给孩子讲故事了。代码如下:
class Book{
public String getContent(){
return "这是一个有趣的故事";
}
}
class Mother{
public void say(Book book){
System.out.println("妈妈开始讲故事");
System.out.println(book.getContent());
}
}
public class Client{
public static void main(String[] args){
Mother mother = new Mother();
mother.say(new Book());
}
}
假如有一天,给的是一份报纸,而不是一本书,让这个母亲讲下报纸上的故事,报纸的代码如下:
class Newspaper{
public String getContent(){
return "这个一则重要的新闻";
}
}
然而这个母亲却办不到,应该她只会读书,这太不可思议,只是将书换成报纸,居然需要修改 Mother 类才能读,假如以后需要换成了杂志呢?原因是 Mother 和 Book 之间的耦合度太高了,必须降低他们的耦合度才行。
我们可以引入一个抽象接口 IReader 读物,让书和报纸去实现这个接口,那么无论提供什么样的读物,该母亲都能读。代码如下:
interface IReader{
public String getContent();
}
class Newspaper implements IReader {
public String getContent(){
return "这个一则重要的新闻";
}
}
class Book implements IReader{
public String getContent(){
return "这是一个有趣的故事";
}
}
class Mother{
public void say(IReader reader){
System.out.println("妈妈开始讲故事");
System.out.println(reader.getContent());
}
}
public class Client{
public static void main(String[] args){
Mother mother = new Mother();
mother.say(new Book());
mother.say(new Newspaper());
}
}
这样修改之后,以后无论提供什么样的读物,只要去实现了 IReader 接口之后就可以被母亲读。实际情况中,代表高层模块的 Mother 类将负责完成主要的业务逻辑,一旦需要对它进行修改,引入错误的风险极大。所以遵循依赖倒转原则可以降低类之间的耦合性,提高系统的稳定性,降低修改程序造成的风险。
依赖倒转原则的核心就是要我们面向接口编程,理解了面向接口编程,也就理解了依赖倒转。
5.接口隔离原则 ISP
接口隔离原则,其 “隔离” 并不是准备的翻译,真正的意图是 “分离” 接口(的功能)
接口隔离原则强调:客户端不应该依赖它不需要的接口;一个类对另一个类的依赖应该建立在最小的接口上。
我们先来看一张图:
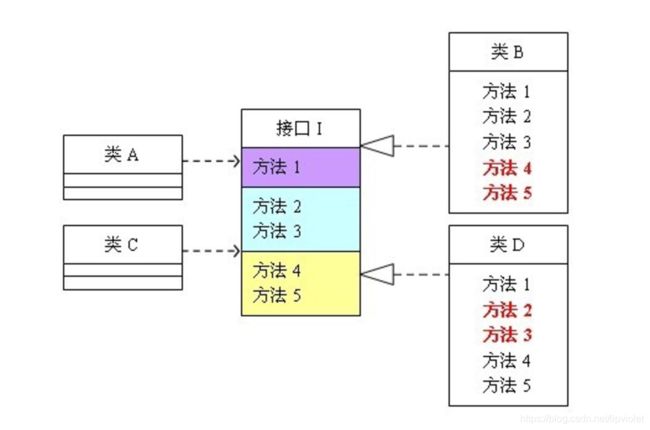
从图中可以看出,类 A 依赖于 接口 I 中的方法 1,2,3 ,类 B 是对类 A 的具体实现。类 C 依赖接口 I 中的方法 1,4,5,类 D 是对类 C 的具体实现。对于类B和类D来说,虽然他们都存在着用不到的方法(也就是图中红色字体标记的方法),但由于实现了接口I,所以也必须要实现这些用不到的方法。
用代码表示:
interface I {
public void method1();
public void method2();
public void method3();
public void method4();
public void method5();
}
class A{
public void depend1(I i){
i.method1();
}
public void depend2(I i){
i.method2();
}
public void depend3(I i){
i.method3();
}
}
class B implements I{
// 类 B 只需要实现方法 1,2, 3,而其它方法它并不需要,但是也需要实现
public void method1() {
System.out.println("类 B 实现接口 I 的方法 1");
}
public void method2() {
System.out.println("类 B 实现接口 I 的方法 2");
}
public void method3() {
System.out.println("类 B 实现接口 I 的方法 3");
}
public void method4() {}
public void method5() {}
}
class C{
public void depend1(I i){
i.method1();
}
public void depend2(I i){
i.method4();
}
public void depend3(I i){
i.method5();
}
}
class D implements I{
// 类 D 只需要实现方法 1,4,5,而其它方法它并不需要,但是也需要实现
public void method1() {
System.out.println("类 D 实现接口 I 的方法 1");
}
public void method2() {}
public void method3() {}
public void method4() {
System.out.println("类 D 实现接口 I 的方法 4");
}
public void method5() {
System.out.println("类 D 实现接口 I 的方法 5");
}
}
public class Client{
public static void main(String[] args){
A a = new A();
a.depend1(new B());
a.depend2(new B());
a.depend3(new B());
C c = new C();
c.depend1(new D());
c.depend2(new D());
c.depend3(new D());
}
}
可以看出,如果接口定义的过于臃肿,只要接口中出现的方法,不管依赖于它的类是否需要该方法,实现类都必须去实现这些方法,这就不符合接口隔离原则,如果想符合接口隔离原则,就必须对接口 I 如下图进行拆分:
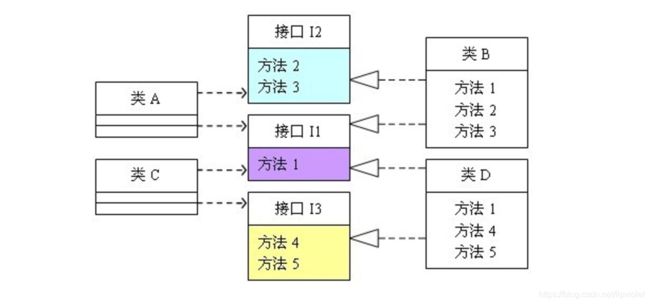
代码可修改为如下:
interface I1 {
public void method1();
}
interface I2 {
public void method2();
public void method3();
}
interface I3 {
public void method4();
public void method5();
}
class A{
public void depend1(I1 i){
i.method1();
}
public void depend2(I2 i){
i.method2();
}
public void depend3(I2 i){
i.method3();
}
}
class B implements I1, I2{
public void method1() {
System.out.println("类 B 实现接口 I1 的方法 1");
}
public void method2() {
System.out.println("类 B 实现接口 I2 的方法 2");
}
public void method3() {
System.out.println("类 B 实现接口 I2 的方法 3");
}
}
class C{
public void depend1(I1 i){
i.method1();
}
public void depend2(I3 i){
i.method4();
}
public void depend3(I3 i){
i.method5();
}
}
class D implements I1, I3{
public void method1() {
System.out.println("类 D 实现接口 I1 的方法 1");
}
public void method4() {
System.out.println("类 D 实现接口 I3 的方法 4");
}
public void method5() {
System.out.println("类 D 实现接口 I3 的方法 5");
}
}
总结:
- 接口隔离原则的思想在于建立单一接口,尽可能地去细化接口,接口中的方法尽可能少
- 但是凡事都要有个度,如果接口设计过小,则会造成接口数量过多,使设计复杂化。所以一定要适度。
6.迪米特法则 LOD
迪米特法则又称为 最少知道原则,它表示一个对象应该对其它对象保持最少的了解。通俗来说就是,只与直接的朋友通信。
首先来解释一下什么是直接的朋友:每个对象都会与其他对象有耦合关系,只要两个对象之间有耦合关系,我们就说这两个对象之间是朋友关系。耦合的方式很多,依赖、关联、组合、聚合等。其中,我们称出现成员变量、方法参数、方法返回值中的类为直接的朋友,而出现在局部变量中的类则不是直接的朋友。也就是说,陌生的类最好不要作为局部变量的形式出现在类的内部。
对于被依赖的类来说,无论逻辑多么复杂,都尽量的将逻辑封装在类的内部,对外提供 public 方法,不对泄漏任何信息。
举个例子,家人探望犯人
家人:家人只与犯人是亲人,但是不认识他的狱友
public class Family {
public void visitPrisoner(Prisoners prisoners) {
Inmates inmates = prisoners.helpEachOther();
imates.weAreFriend();
}
}
犯人:犯人与家人是亲人,犯人与狱友是朋友
public class Prisoners {
private Inmates inmates = new Inmates();
public Inmates helpEachOther() {
System.out.println("家人说:你和狱友之间应该互相帮助...");
return inmates;
}
}
狱友: 犯人与狱友是朋友,但是不认识他的家人
public class Inmates {
public void weAreFriend() {
System.out.println("狱友说:我们是狱友...");
}
}
场景类:发生在监狱里
public class Prison {
public static void main(String args[])
{
Family family = new Family();
family.visitPrisoner(new Prisoners());
}
}
运行结果会发现:
家人说:你和狱友之间应该互相帮助...
狱友说:我们是狱友...
家人和狱友显然是不认识的,且监狱只允许家人探望犯人,而不是随便谁都可以见面的,这里家人和狱友有了沟通显然是违背了迪米特法则,因为在 Inmates 这个类作为局部变量出现在了 Family 类中的方法里,而他们不认识,不能够跟直接通信,迪米特法则告诉我们只与直接的朋友通信。所以上述的代码可以改为:
public class Family {
//家人探望犯人
public void visitPrisoner(Prisoners prisoners) {
System.out.print("家人说:");
prisoners.helpEachOther();
}
}
public class Prisoners {
private Inmates inmates = new Inmates();
public Inmates helpEachOther() {
System.out.println("犯人和狱友之间应该互相帮助...");
System.out.print("犯人说:");
inmates.weAreFriend();
return inmates;
}
}
public class Inmates {
public void weAreFriend() {
System.out.println("我们是狱友...");
}
}
public class Prison {
public static void main(String args[]) {
Family family = new Family();
family.visitPrisoner(new Prisoners());
}
}
运行结果
家人说:犯人和狱友之间应该互相帮助...
犯人说:我们是狱友...
这样家人和狱友就分开了,但是也表达了家人希望狱友能跟犯人互相帮助的意愿。也就是两个类通过第三个类实现信息传递, 而家人和狱友却没有直接通信。
7.组合/聚合复用原则 CRP
组合/聚合复用原则就是在一个新的对象里面使用一些已有的对象,使之成为新对象的一部分; 新的对象通过向这些对象的委派达到复用已有功能的目的。
在面向对象的设计中,如果直接继承基类,会破坏封装,因为继承将基类的实现细节暴露给子类;如果基类的实现发生了改变,则子类的实现也不得不改变;从基类继承而来的实现是静态的,不可能在运行时发生改变,没有足够的灵活性。于是就提出了组合/聚合复用原则,也就是在实际开发设计中,尽量使用组合/聚合,不要使用类继承。
举个简单的例子,在某家公司里的员工分为经理,工作者和销售者。如果画成 UML 图可以表示为:
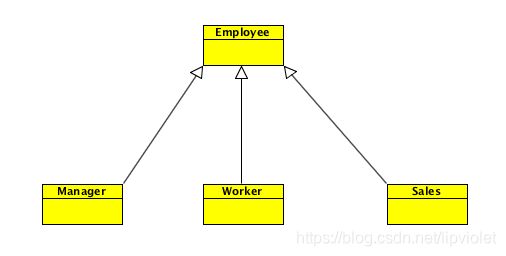
但是这样违背了组合聚合复用原则,继承会将 Employee 类中的方法暴露给子类。如果要遵守组合聚合复用原则,可以将其改为:
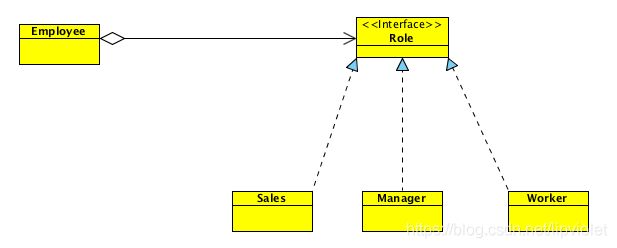
这样做降低了类与类之间的耦合度,Employee 类的变化对其它类造成的影响相对较少。
总结:
- 总体说来,组合/聚合复用原则告诉我们:组合或者聚合好过于继承。
- 聚合组合是一种 “黑箱” 复用,因为细节对象的内容对客户端来说是不可见的。
三、创建型模式
java是一门面向对象的语言,任何需求都离不开创建对象,new 一个对象,然后 set 相关属性,而对象的创建依赖于类。
创建者模式就是为了用优雅的方式创建我们使用的类。比如,在很多场景下,我们需要给客户端提供更加友好的创建对象的方式,尤其是那种我们定义了类,但是需要提供给其他开发者用的时候。
-
简单工厂模式
interface People { String create(); } class China implements People{ @Override public String create() { return "I am Chinese"; } } class English implements People{ @Override public String create() { return "I am English"; } } class PeopleFactory { static People create(String name){ if(name.equals("China")){ return new China(); }else if (name.equals("English")) { return new English(); }else { return null; } } public static void main(String[] args) { // People englinsh = new Englinsh(); // People china = new China(); People china = PeopleFactory.create("China"); People english = PeopleFactory.create("Enginsh"); System.out.println(english.create()); System.out.println(china.create()); } }总结
- 关于@Override,该标注的意思是该方法为重写方法,此时有个疑问,接口实现类并不是重写,为什么标注,疑问的不错,答:JDK1.5时,继承一个类,并对其中的方法重写的时,需要加这个注释,而实现接口的时候不能加,加上idea编译报错;而 JDK1.6时,继承类重写方法,或者实现接口的时候,都会带上@Override。
- People为什么作为一个接口,而不是类,答:接口的方法不需要实现,可以没有实现体,若定义成类,则必须有实现体,而我们的初衷只是定义一个方法名而已,因此用接口。
- 无论是类还是接口,它要想扩展都是需要被继承或者被实现,创建对象时就会用到多态,其实不用工厂模式而直接new同样也可以创建自己想要的对象,但是对于其他不了解每个类的人就会很繁琐,并且代码维护和扩展会受限,这样代码结构清晰,并且没有new,显得更高级。
- 接口+定义方法–实现类+实现接口方法–工厂类+返回类型为接口的静态方法–批量创建对象。
- 场景:强调职责单一原则,一个类只提供一种功能,PeopleFactory的功能就是只要负责生产各种 People。作为一个工厂,告诉你我要什么东西,你造好了给我就行。
-
工厂模式
interface PeopleFactory{ //接口中无法定义静态方法,因为静态方法需要方法体。而此处我们无法写方法体 People Create(String name); } class ChinaFactory implements PeopleFactory{ @Override public People Create(String name) { if (name.equals("beijing")) { return new ChinaBeijing(); } else if (name.equals("nanjing")) { return new ChinaNanjing(); } else { return null; } } } class EnglishFactory implements PeopleFactory{ @Override public People Create(String name) { if (name.equals("London")) { return new EnginshLondon(); } else if (name.equals("Birmingham")) { return new EnglishBirmingham(); } else { return null; } } } class EasyFactory { public static void main(String[] args) { //第一步,挑选工厂,不同工厂创造不同的产品 PeopleFactory peopleFactory = new ChinaFactory(); //根据创建的工厂,创建想要的对象,不同工厂的不同对象 People beijing = peopleFactory.Create("beijing"); } }总结
- 工厂模式就是简单工厂模式的进阶,实际上就是将工厂继续细分,无设计上的本质区别,只有一个工厂就是简单工厂模式,超过一个便成了工厂模式,因为很多设计模式中对这两个未细分。
- 使用上的唯一区别就是工厂模式需要先new一个工厂,工厂选定之后和简单工厂模式便再无区别。
-
抽象工厂模式
-
当涉及到产品族的时候,就需要引入抽象工厂模式了。
-
一个经典的例子是造一台电脑。我们先不引入抽象工厂模式,看看怎么实现。
-
因为电脑是由许多的构件组成的,我们将 CPU 和主板进行抽象,然后 CPU 由 CPUFactory 生产,主板由 MainBoardFactory 生产,然后,我们再将 CPU 和主板搭配起来组合在一起,如下图:
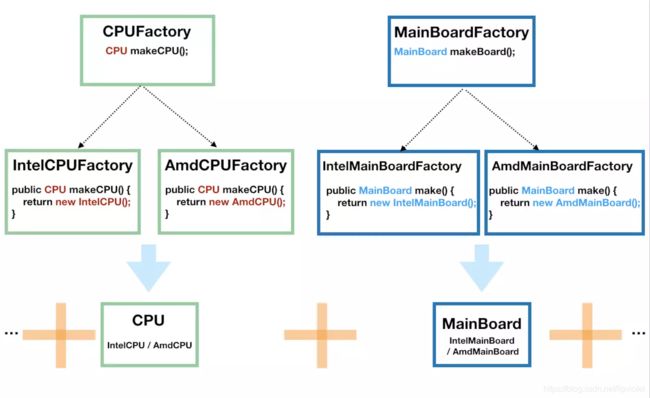
-
这时候创建对象时这样使用:
// 得到 Intel 的 CPU CPUFactory cpuFactory = new IntelCPUFactory(); CPU cpu = intelCPUFactory.makeCPU(); // 得到 AMD 的主板 MainBoardFactory mainBoardFactory = new AmdMainBoardFactory(); MainBoard mainBoard = mainBoardFactory.make(); // 组装 CPU 和主板 Computer computer = new Computer(cpu, mainBoard); -
单独看 CPU 工厂和主板工厂,它们分别是前面我们说的工厂模式。这种方式也容易扩展,因为要给电脑加硬盘的话,只需要加一个 HardDiskFactory 和相应的实现即可,不需要修改现有的工厂。
-
但是,这种方式有一个问题,那就是如果Intel 家产的 CPU 和 AMD 产的主板不能兼容使用,那么这代码就容易出错,因为客户端并不知道它们不兼容,也就会错误地出现随意组合。
-
因此,当涉及到这种产品族的问题的时候,就需要抽象工厂模式来支持了。我们不再定义 CPU 工厂、主板工厂、硬盘工厂、显示屏工厂等等,我们直接定义电脑工厂,每个电脑工厂负责生产所有的设备,这样能保证肯定不存在兼容问题。
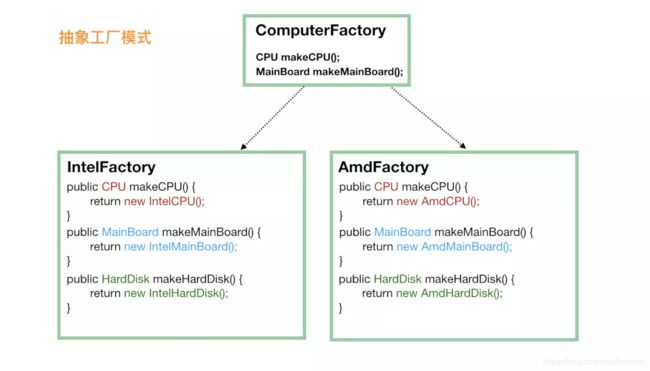
-
这个时候,创建对象时,不再需要单独挑选 CPU厂商、主板厂商、硬盘厂商等,直接选择一家品牌工厂,品牌工厂会负责生产所有的东西,而且能保证肯定是兼容可用的。
public static void main(String[] args) { // 第一步就要选定一个“大厂” ComputerFactory cf = new AmdFactory(); // 从这个大厂造 CPU CPU cpu = cf.makeCPU(); // 从这个大厂造主板 MainBoard board = cf.makeMainBoard(); // 从这个大厂造硬盘 HardDisk hardDisk = cf.makeHardDisk(); // 将同一个厂子出来的 CPU、主板、硬盘组装在一起 Computer result = new Computer(cpu, board, hardDisk); }
总结
- 抽象工厂模式的应用场景就是产品簇,可以看做是工厂模式的进阶,三种工厂模式理念相同,就是工厂的个数和功能越来越全面完善。
- 不过,抽象工厂的问题也是显而易见的,比如我们要加个显示器,就需要修改所有的工厂,给所有的工厂都加上制造显示器的方法。这有点违反了对修改关闭,对扩展开放这个设计原则。
-
-
单例模式
//饿汉子式 class Window{ // 将构造块用private修饰,意味着该对象无法用new的方式创建,这就是为什么要有这一句的原因,思考了很久,终于真相了。 private Window(){} // 创建私有静态实例,意味着这个类第一次使用的时候就会进行创建 private static Window win = new Window(); //创建静态方法,因为它要用到静态成员,并且被调用更方便 public static Window getWin(){ return win; } public static void main(String[] args) { Window win1 = Window.getWin(); Window win2 = Window.getWin(); System.out.println(win1); //Window@f2a0b8e System.out.println(win2); //Window@f2a0b8e } } class test{ public static void main(String[] args) { //直接报错:'Window()' has private access in 'com.li.test.Window' Window win = new Window(); } }//饱汉子式 class Window{ //同样,将创建对象的new模式堵死 private Window(){} //和饿汉模式相比,这边不需要先实例化出来,注意这里的 volatile,它是必须的 private static volatile Window win; { System.out.println("我是构造块儿"); } public static Window getWin(){ if(win == null) { //加锁 synchronized (Window.class) { // 这一次判断也是必须的,不然会有并发问题 if (win == null) { win = new Window(); } } } return win; } public static void main(String[] args) { Window win1 = Window.getWin(); Window win2 = Window.getWin(); System.out.println(win1); System.out.println(win2); } } //双重检查,指的是两次检查 instance 是否为 null。 //volatile 在这里是需要的,希望能引起读者的关注。 //volatile详解:这在JVM 1.2之前,Java的内存模型实现总是从主存读取变量,是不需要进行特别的注意的。 //而随着JVM的成熟和优化,现在在多线程环境下volatile关键字的使用变得非常重要,在当前的Java内存模型下,线程可以把变量保存在本地内存(比如机器的寄存器)中,而不是直接在主存中进行读写。这就可能造成一个线程在主存中修改了一个变量的值,而另外一个线程还继续使用它在寄存器中的变量值的拷贝,造成数据的不一致。 //要解决这个问题,只需要像在本程序中的这样,把该变量声明为volatile(不稳定的)即可,这就指示JVM,这个变量是不稳定的,每次使用它都到主存中进行读取。一般说来,多任务环境下各任务间共享的标志都应该加volatile修饰。 //Volatile修饰的成员变量在每次被线程访问时,都强迫从共享内存中重读该成员变量的值。而且,当成员变量发生变化时,强迫线程将变化值回写到共享内存。这样在任何时刻,两个不同的线程总是看到某个成员变量的同一个值。 //Java语言规范中指出:为了获得最佳速度,允许线程保存共享成员变量的私有拷贝,而且只当线程进入或者离开同步代码块时才与共享成员变量的原始值对比。 //而volatile关键字就是提示VM:对于这个成员变量不能保存它的私有拷贝,而应直接与共享成员变量交互。 //使用建议:在两个或者更多的线程访问的成员变量上使用volatile。当要访问的变量已在synchronized代码块中,或者为常量时,不必使用。 //由于使用volatile屏蔽掉了VM中必要的代码优化,所以在效率上比较低,因此一定在必要时才使用此关键字。 //很多人不知道怎么写,直接就在 getInstance() 方法签名上加上 synchronized,这就不多说了,性能太差。//嵌套类最经典,以后可以试试 public class Singleton3 { private Singleton3() {} // 主要是使用了 嵌套类可以访问外部类的静态属性和静态方法 的特性 private static class Holder { private static Singleton3 instance = new Singleton3(); } public static Singleton3 getInstance() { return Holder.instance; } } //很多人都会把这个嵌套类说成是静态内部类,严格地说,内部类和嵌套类是不一样的,它们能访问的外部类权限也是不一样的。 //最后,一定有人跳出来说用枚举实现单例,是的没错,枚举类很特殊,它在类加载的时候会初始化里面的所有的实例,而且 JVM 保证了它们不会再被实例化,所以它天生就是单例的。不说了,读者自己看着办吧,不建议使用。总结
- 单例模式设计到java的基础知识,构造器和构造块,对象之所以可以创建是有一个固定语法,A a = new A();该语法就是触发构造器,构造器的语法 public A(){ },因此创建对象也是调用方法。不写构造器编译器会默认创建一个无参构造器,写了编译器便不会再默认创建。
- 构造块即直接在类中写一个{},作用:解决多个构造器重载时,代码冗余的问题。
- 成员变量初始化(new 类())过程:1.默认初始化; 2.声明处初始化;3.构造块初始化;4.构造器初始化;(其中2,3执行顺序取决于代码书写顺序)。构造器和构造块只有创建对象(new)时才会触发,因此调用类中的静态方法或变量时不会触发
- 无论是饿汉子还是饱汉子:构造器必须写且用private修饰+静态实例成员变量+静态获取对象方法。
- 原理:之所以能在类中创建对象,就是因为构造器的存在,创建一次便调用一次,如果不调用构造器就不会出现新地址,也就是说如果可以做到只调用一次构造器就可以保证无论创造多少对象始终是这个地址,最终达成该类中只有一个对象的目的,原因在于类加载器无论创建多少次都只会加载一次
- 其实单例模式有很多种形式,最佳实践应该是两重判断,保证只new出来一个。单例可以说是非常普遍的设计模式了。只要能保证在服务容器的生命周期中只能有这么一个即可。
- 场景:比如说Servlet、Spring中注入的Bean等等都是单例的。
- 饿汉子式线程比较安全,饱汉子式线程不安全。
-
建造者模式
经常碰见的 XxxBuilder 的类,通常都是建造者模式的产物。建造者模式其实有很多的变种,但是对于客户端来说,我们的使用通常都是一个模式的://这种方法就是将UserBulid()类从User类中取出来独立存在,但是此时User的构造器便不能是private了,只是调用好看。 User user = new UserBuilder().a().b().c().Build(); //常用格式,书写也比较流畅美观,进入静态方法Builder(),赋值完最后再Build()。 User user = User.Builder().a().b().c().Build(); //应该也比较常用,也挺美观,原来创建对象还可以这样用,直接创建内部类。只有内部类可以这样用,内部类无法从外部直接创建。即使public修饰。 User user = new User.UserBuilder().a().b().c().Build();先来一个中规中矩的建造者模式
class User { // 下面是“一堆”的属性 private String name; private String password; private String nickName; private int age; // 构造方法私有化,不然客户端就会直接调用构造方法了 private User(String name, String password, String nickName, int age) { this.name = name; this.password = password; this.nickName = nickName; this.age = age; } // 静态方法,用于生成一个 Builder,这个不一定要有,不过写这个方法是一个很好的习惯, // 有些代码要求别人写 new User.UserBuilder().a()...build() 看上去就没那么好 public static UserBuilder builder() { return new UserBuilder(); } public static class UserBuilder { // 下面是和 User 一模一样的一堆属性 private String name; private String password; private String nickName; private int age; private UserBuilder() { } // 链式调用设置各个属性值,返回 this,即 UserBuilder public UserBuilder name(String name) { this.name = name; return this; } public UserBuilder password(String password) { this.password = password; return this; } public UserBuilder nickName(String nickName) { this.nickName = nickName; return this; } public UserBuilder age(int age) { this.age = age; return this; } // build() 方法负责将 UserBuilder 中设置好的属性“复制”到 User 中。 // 当然,可以在 “复制” 之前做点检验 public User build() { if (name == null || password == null) { throw new RuntimeException("用户名和密码必填"); } if (age <= 0 || age >= 150) { throw new RuntimeException("年龄不合法"); } // 还可以做赋予”默认值“的功能 if (nickName == null) { nickName = name; } return new User(name, password, nickName, age); } } } //客户端调用 class APP { public static void main(String[] args) { User d = User.builder() .name("foo") .password("pAss12345") .age(25) .build(); } }建造者模式其实代码很多,如果使用lombok就会简洁很多,但是初期还是手写会好,便于深刻理解与升华
@Builder //使用 lombok,用了 lombok 以后,上面的一大堆代码会变成如下这样: class User { private String name; private String password; private String nickName; private int age; }高级用法(第二个例子):将一个复杂对象分布创建。如果一个超大的类的属性特别多,我们可以把属性分门别类,不同属性组成一个稍微小一点的类,再把好几个稍微小点的类窜起来。比方说一个电脑,可以分成不同的稍微小点的部分CPU、主板、显示器。CPU、主板、显示器分别有更多的组件,不再细分。

总结
- 读源码时建造者模式随处可见,显然这种方式是很有好处的,其便利显然需要深耕才可以慢慢体会
- 该方法的核心其实就是链式调用,现将属性赋值到UserBuilder类中,最后使用build() 方法再传回User类。
- 说实话,建造者模式的链式写法很吸引人,但是,多写了很多“无用”的 builder 的代码,感觉这个模式没什么用。不过,当属性很多,而且有些必填,有些选填的时候,这个模式会使代码清晰很多。我们可以在 Builder 的构造方法中强制让调用者提供必填字段,还有,在 build() 方法中校验各个参数比在 User 的构造方法中校验,代码要优雅一些。
- 如果你只是想要链式写法,不想要建造者模式,有个很简单的办法,User 的 getter 方法不变,所有的 setter 方法都让其 *return this 就可以了,然后就可以像下面这样调用:User user = new User().setName("").setPassword("").setAge(20);
- 第一个例子只是建造者模式的初级代码体现,第二个截图例子则是高级一些的用法。设计模式一般使用时不会单独使用的,尤其是源码,写的真的很优雅。
-
原型模式
@Data @Builder class Apple implements Cloneable{ String name; int age; @Override protected Apple clone() throws CloneNotSupportedException { return new Apple( this.name,this.age); } } class test{ public static void main(String[] args) throws CloneNotSupportedException { User user = User.Builder().name("l asd ").Build(); Apple apple = new Apple("like",32); System.out.println(apple); apple.setAge(222); Apple apple1 = apple.clone(); apple.setAge(2222222); System.out.println(apple1); }总结
- 原型模式很简单:有一个原型实例,基于这个原型实例产生新的实例,也就是“克隆”了。Object 类中有一个 clone() 方法,它用于生成一个新的对象,当然,如果我们要调用这个方法,java 要求我们的类必须先实现 Cloneable 接口,此接口没有定义任何方法,但是实现该接口后便可以重写clone()方法。
protected native Object clone() throws CloneNotSupportedException; - 无论是重写clone方法还是主程序中使用clone方法,都需要抛异常“throws CloneNotSupportedException”
- java 的克隆是浅克隆,碰到对象引用的时候,克隆出来的对象和原对象中的引用将指向同一个对象。通常实现深克隆的方法是将对象进行序列化,然后再进行反序列化。但是这个克隆好像是深克隆啊,因为地址不一样了。
- 原型模式很简单:有一个原型实例,基于这个原型实例产生新的实例,也就是“克隆”了。Object 类中有一个 clone() 方法,它用于生成一个新的对象,当然,如果我们要调用这个方法,java 要求我们的类必须先实现 Cloneable 接口,此接口没有定义任何方法,但是实现该接口后便可以重写clone()方法。
四、创建型模式总结
-
创建型模式总体上比较简单,它们的作用就是为了产生实例对象,算是各种工作的第一步了,因为我们写的是面向对象的代码,所以我们第一步当然是需要创建一个对象了。
-
简单工厂模式最简单;工厂模式在简单工厂模式的基础上增加了选择工厂的维度,需要第一步选择合适的工厂;抽象工厂模式有产品族的概念,如果各个产品是存在兼容性问题的,就要用抽象工厂模式。单例模式就不说了,为了保证全局使用的是同一对象,一方面是安全性考虑,一方面是为了节省资源;建造者模式专门对付属性很多的那种类,为了让代码更优美;原型模式用得最少,了解和 Object 类中的 clone() 方法相关的知识即可。
五、结构型模式
创建型模式介绍的创建对象的一些设计模式,下面的结构型模式是描述对象关系之间的模型,旨在通过改变代码结构来达到解耦的目的,使得我们的代码容易维护和扩展。
-
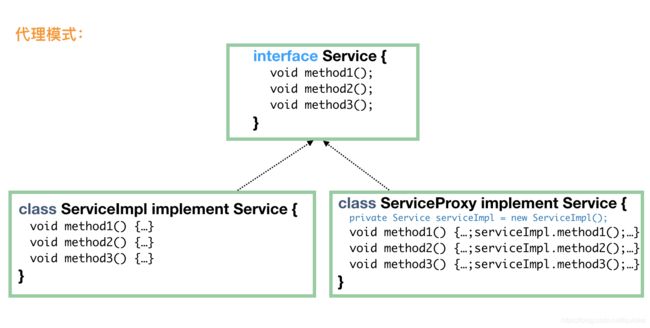
代理模式
代理模式是最常使用的模式之一了,用一个代理来隐藏具体实现类的实现细节,通常还用于在真实的实现的前后添加一部分逻辑。
既然说是代理,那就要对客户端隐藏真实实现,由代理来负责客户端的所有请求。当然,代理只是个代理,它不会完成实际的业务逻辑,而是一层皮而已,但是对于客户端来说,它必须表现得就是客户端需要的真实实现。
示例一:Spring的AOP用的是动态代理,何为动态不看了,用过Spring的小伙伴都知道吧。单纯看一下最基础代理模式是什么样的。代理就是,一个对象辅助另一个对象去做某件事,同时还可以增加一点辅助功能。例如,你买车,的确是你花钱把车买到了,但是你不可能直接去和厂家谈吧,你应该通过4S店购买,同时4S店帮助你入保险扣税等操作,最终你才得到了你想要的车。
//先定义一个接口,真正使用者(被代理者)实现此方法,代理者也实现此方法,实质上代理者重写方法时是在被代理者的基础上重写的 interface Buy{ public void buy(); } // class People implements Buy{ @Override public void buy() { System.out.println("get a car!"); } } class ProxyPeople implements Buy{ //这是我最开始的写法,最终也是得到一个poeple对象,只是用了多态的写法而已,实际没区别 //private Buy people = new People(); private People people = new People(); //还有一种写法,上面的写法是直接创建一个对象,以下写法是从构造器中新建对象 /* private People people; public ProxyPeople(People people){ this.people = people } */ //在被代理者实现方法的基础上继续实现 @Override public void buy() { System.out.println("上税哦"); people.buy(); System.out.println("恭喜你"); } } class test{ //客户端调用时,是代理者的实体对象进行执行 public static void main(String[] args){ Buy buy = new ProxyPeople(); buy.buy(); } } //输出 上税哦 get a car! 恭喜你示例二:规范代码示例,有点像springboot的代码书写习惯,更容易理解代理模式
public interface FoodService { Food makeChicken(); Food makeNoodle(); } public class FoodServiceImpl implements FoodService { public Food makeChicken() { Food f = new Chicken() f.setChicken("1kg"); f.setSpicy("1g"); f.setSalt("3g"); return f; } public Food makeNoodle() { Food f = new Noodle(); f.setNoodle("500g"); f.setSalt("5g"); return f; } } // 代理要表现得“就像是”真实实现类,所以需要实现 FoodService public class FoodServiceProxy implements FoodService { // 内部一定要有一个真实的实现类,当然也可以通过构造方法注入 private FoodService foodService = new FoodServiceImpl(); public Food makeChicken() { System.out.println("我们马上要开始制作鸡肉了"); // 如果我们定义这句为核心代码的话,那么,核心代码是真实实现类做的, // 代理只是在核心代码前后做些“无足轻重”的事情 Food food = foodService.makeChicken(); System.out.println("鸡肉制作完成啦,加点胡椒粉"); // 增强 food.addCondiment("pepper"); return food; } public Food makeNoodle() { System.out.println("准备制作拉面~"); Food food = foodService.makeNoodle(); System.out.println("制作完成啦") return food; } } // 客户端调用,也就是创建对象,实质上是创建的代理者,但是执行的核心还是被代理者! // 这里用代理类来实例化 FoodService foodService = new FoodServiceProxy(); foodService.makeChicken();总结
- 代理,即对客户端隐藏真实实现,由代理来负责客户端的所有请求。当然,代理只是个代理,它不会完成实际的业务逻辑,而是一层皮而已,但是对于客户端来说,它必须表现得就是客户端需要的真实实现。用一个代理来隐藏具体实现类的实现细节,这就是代理,只要理解了“代理”二字,便理解了代理模式
- 由于代理模式一般在代理类的实现中添加一部分逻辑,所以代理模式又叫 “方法包装” 或做 “方法增强”。在面向切面编程中,算了还是不要吹捧这个名词了,在 AOP 中,其实就是动态代理的过程。比如 Spring 中,我们自己不定义代理类,但是 Spring 会帮我们动态来定义代理,然后把我们定义在 @Before、@After、@Around 中的代码逻辑动态添加到代理中。
- 说到动态代理,又可以展开说 …… Spring 中实现动态代理有两种,一种是如果我们的类定义了接口,如 UserService 接口和 UserServiceImpl 实现,那么采用 JDK 的动态代理,感兴趣的读者可以去看看 java.lang.reflect.Proxy 类的源码;另一种是我们自己没有定义接口的,Spring 会采用 CGLIB 进行动态代理,它是一个 jar 包,性能还不错。
-
适配器模式
总结
- 适配器(adapter),顾名思义,是让两个不兼容的东西可以一起工作。例如插座的电源是220V,手机充电则需要充电器,充电器的作用就是适配,将电压变小,交流电变成直流电。除了这种需要改变属性的操作(比较好说,不举例子了)
- 将这种思想引入到编程中,适配器便用于在接口继承方面。假设一个顶级接口有一大堆方法需要实现类实现,我新写了个类只是想实现其中的某一两个接口,其他方法不需要,但是如果直接实现接口的话你就必须全部实现,这种情况下就出现了适配器类,适配器类impl此接口,然后空实现(单纯实现,不进行任何逻辑操作)所有方法,然后我的新类只需要继承适配器类不再实现接口就可以实现自己想要的方法并且不用写一些无意义的空实现。
- 适配器模式的核心思想就是,将实现顶级接口编程继承顶级类(适配器类),使我们可以只重写自己想要的方法,而不用写无意义的空实现,代码清晰
- 更深入一点形容,那就是有一个接口需要实现,但是我们现成的对象都不满足,需要加一层适配器来进行适配。
- 配器模式总体来说分三种:默认适配器模式、对象适配器模式、类适配器模式
默认适配器模式(Default Adapter)
//用 Appache commons-io 包中的 FileAlterationListener 做例子,此接口定义了很多的方法,用于对文件或文件夹进行监控,一旦发生了对应的操作,就会触发相应的方法。 public interface FileAlterationListener { void onStart(final FileAlterationObserver observer); void onDirectoryCreate(final File directory); void onDirectoryChange(final File directory); void onDirectoryDelete(final File directory); void onFileCreate(final File file); void onFileChange(final File file); void onFileDelete(final File file); void onStop(final FileAlterationObserver observer); } //此接口的一大问题是抽象方法太多了,如果我们要用这个接口,意味着我们要实现每一个抽象方法,如果我们只是想要监控文件夹中的文件创建和文件删除事件,可是我们还是不得不实现所有的方法,很明显,这不是我们想要的。 //所以,我们需要下面的一个适配器,它用于实现上面的接口,但是所有的方法都是空方法,这样,我们就可以转而定义自己的类来继承下面这个类即可。 public class FileAlterationListenerAdaptor implements FileAlterationListener { public void onStart(final FileAlterationObserver observer) { } public void onDirectoryCreate(final File directory) { } public void onDirectoryChange(final File directory) { } public void onDirectoryDelete(final File directory) { } public void onFileCreate(final File file) { } public void onFileChange(final File file) { } public void onFileDelete(final File file) { } public void onStop(final FileAlterationObserver observer) { } } //实现类 public class FileMonitor extends FileAlterationListenerAdaptor { public void onFileCreate(final File file) { // 文件创建 doSomething(); } public void onFileDelete(final File file) { // 文件删除 doSomething(); } }对象适配器模式
//以下是《Head First 设计模式》中的一个例子,稍微修改了一下,看看怎么将鸡适配成鸭,这样鸡也能当鸭来用。因为,现在鸭这个接口,我们没有合适的实现类可以用,所以需要适配器。 //接口类 public interface Duck { public void quack(); // 鸭的呱呱叫 public void fly(); // 飞 } public interface Cock { public void gobble(); // 鸡的咕咕叫 public void fly(); // 飞 } public class WildCock implements Cock { public void gobble() { System.out.println("咕咕叫"); } public void fly() { System.out.println("鸡也会飞哦"); } } //鸭接口有 fly() 和 quare() 两个方法,鸡 Cock 如果要冒充鸭,fly() 方法是现成的,但是鸡不会鸭的呱呱叫,没有 quack() 方法。这个时候就需要适配了: // 毫无疑问,首先,这个适配器肯定需要 implements Duck,这样才能当做鸭来用 public class CockAdapter implements Duck { Cock cock; // 构造方法中需要一个鸡的实例,此类就是将这只鸡适配成鸭来用 public CockAdapter(Cock cock) { this.cock = cock; } // 实现鸭的呱呱叫方法 @Override public void quack() { // 内部其实是一只鸡的咕咕叫 cock.gobble(); } @Override public void fly() { cock.fly(); } } //客户端调用 public static void main(String[] args) { // 有一只野鸡 Cock wildCock = new WildCock(); // 成功将野鸡适配成鸭 Duck duck = new CockAdapter(wildCock); ... }到这里,大家也就知道了适配器模式是怎么回事了。无非是我们需要一只鸭,但是我们只有一只鸡,这个时候就需要定义一个适配器,由这个适配器来充当鸭,但是适配器里面的方法还是由鸡来实现的。
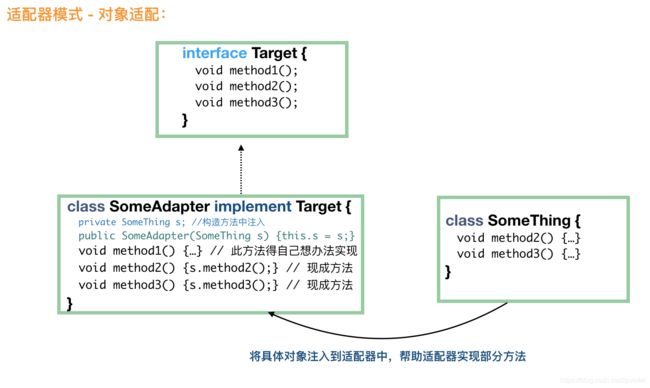
类适配器模式
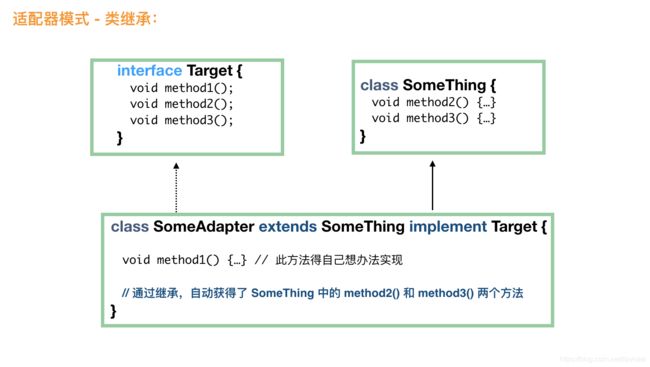
通过继承的方法,适配器自动获得了所需要的大部分方法。这个时候,客户端使用更加简单,直接 Target t = new SomeAdapter(); 就可以了。
异同- 类适配和对象适配的异同:一个采用继承,一个采用组合;类适配属于静态实现,对象适配属于组合的动态实现,对象适配需要多实例化一个对象,总体来说,对象适配用得比较多。
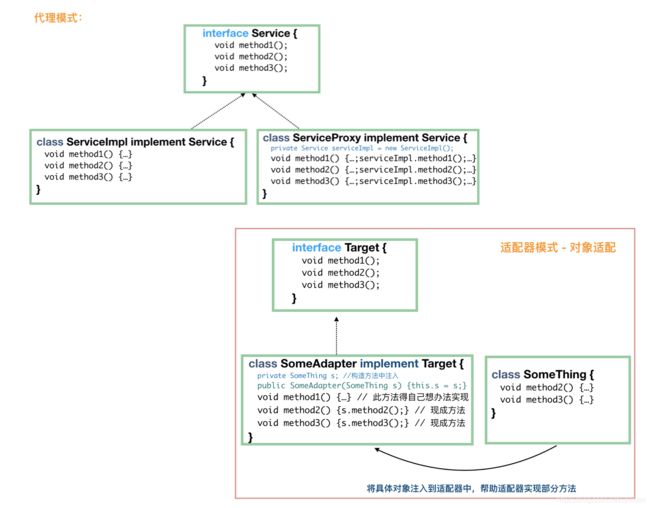
- 适配器模式和代理模式的异同
比较这两种模式,其实是比较对象适配器模式和代理模式,在代码结构上,它们很相似,都需要一个具体的实现类的实例。但是它们的目的不一样,代理模式做的是增强原方法的活;适配器做的是适配的活,为的是提供“把鸡包装成鸭,然后当做鸭来使用”,而鸡和鸭它们之间原本没有继承关系。
-
桥梁(桥接)模式
桥梁模式用于抽象化和实现化的解耦。又是解耦,综其根本,设计模式其实就是教我们1. 优雅的解耦,2. 提高代码拓展性,3. 实现代码动态切换。//首先造一个桥梁,也就是定义一个接口,实现想要的方法 //(勾画API) public interface DrawAPI { public void draw(int radius, int x, int y); } //一系列实现类,均实现接口做不同的事情 //(各种颜色的笔) public class RedPen implements DrawAPI { @Override public void draw(int radius, int x, int y) { System.out.println("用红色笔画图,radius:" + radius + ", x:" + x + ", y:" + y); } } public class GreenPen implements DrawAPI { @Override public void draw(int radius, int x, int y) { System.out.println("用绿色笔画图,radius:" + radius + ", x:" + x + ", y:" + y); } } public class BluePen implements DrawAPI { @Override public void draw(int radius, int x, int y) { System.out.println("用蓝色笔画图,radius:" + radius + ", x:" + x + ", y:" + y); } } //定义一个抽象类,此类的实现类都需要使用 DrawAPI //(形状) public abstract class Shape { protected DrawAPI drawAPI; protected Shape(DrawAPI drawAPI){ this.drawAPI = drawAPI; } public abstract void draw(); } //定义抽象类的子类(形状-圆形、长方形、正方形、、、) // 圆形 public class Circle extends Shape { private int radius; public Circle(int radius, DrawAPI drawAPI) { super(drawAPI); this.radius = radius; } public void draw() { drawAPI.draw(radius, 0, 0); } } // 长方形 public class Rectangle extends Shape { private int x; private int y; public Rectangle(int x, int y, DrawAPI drawAPI) { super(drawAPI); this.x = x; this.y = y; } public void draw() { drawAPI.draw(0, x, y); } } //客户端使用 public static void main(String[] args) { Shape greenCircle = new Circle(10, new GreenPen()); Shape redRectangle = new Rectangle(4, 8, new RedPen()); greenCircle.draw(); redRectangle.draw(); } //不断学习:抽象类和接口都是可以实例化的,只是实例化的都是其实现类或者子类,其实就是多态的写法!!!总结
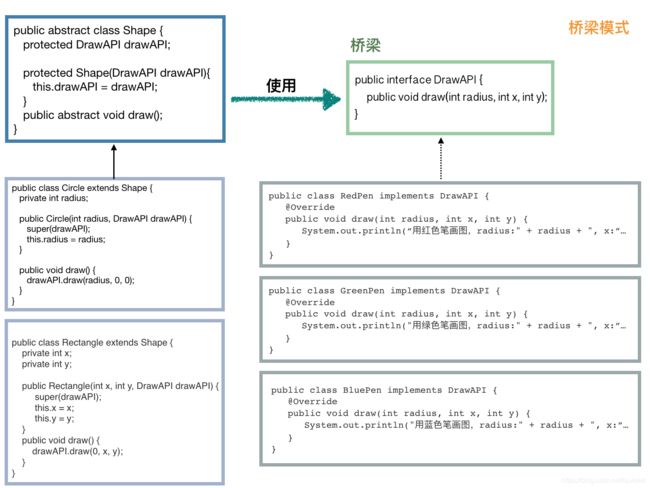
-
装饰模式
先看一个简单的图,看这个图的时候,了解下层次结构就可以了
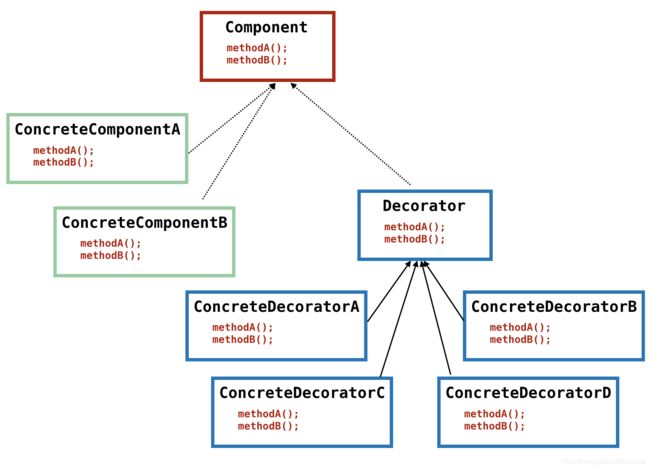
从图中可以看到,接口 Component 其实已经有了 ConcreteComponentA 和 ConcreteComponentB 两个实现类了,但是,如果我们要增强这两个实现类的话,我们就可以采用装饰模式,用具体的装饰器来装饰实现类,以达到增强的目的。所有的具体装饰者们 ConcreteDecorator* 都可以作为 Component 来使用,因为它们都实现了 Component 中的所有接口。它们和 Component 实现类 ConcreteComponent* 的区别是,它们只是装饰者,起装饰作用,也就是即使它们看上去牛逼轰轰,但是它们都只是在具体的实现中加了层皮来装饰而已。
此时,我们可以从理论上梳理一下代理模式和装饰模式的区别:
一个装饰类,在原来类的基础上增加一点功能。是不是和代理模式很像,甚至可以将整个代码搬过来照样可以说的通的。这两个模式意思上有点差别,代理模式是原对象做不了那件事,必须让代理对象去做,主导侧重于代理对象,比如说买车,缴税等只能4s店做。
装饰模式是说,就是让原对象直接去做这件事,只是功能上增强一点,主导在于原对象。比如说炒菜的时候撒点盐。
下面先看一个小例子,先把装饰模式弄清楚最近大街上流行起来了“快乐柠檬”,我们把快乐柠檬的饮料分为三类:红茶、绿茶、咖啡,在这三大类的基础上,又增加了许多的口味,什么金桔柠檬红茶、金桔柠檬珍珠绿茶、芒果红茶、芒果绿茶、芒果珍珠红茶、烤珍珠红茶、烤珍珠芒果绿茶、椰香胚芽咖啡、焦糖可可咖啡等等,每家店都有很长的菜单,但是仔细看下,其实原料也没几样,但是可以搭配出很多组合,如果顾客需要,很多没出现在菜单中的饮料他们也是可以做的。
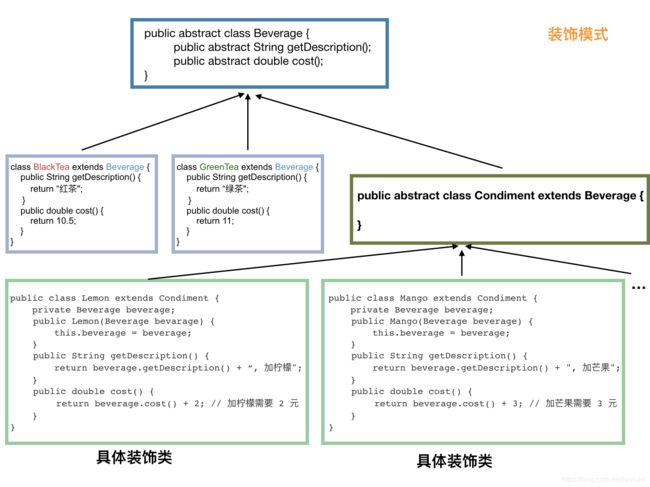
在这个例子中,红茶、绿茶、咖啡是最基础的饮料,其他的像金桔柠檬、芒果、珍珠、椰果、焦糖等都属于装饰用的。当然,在开发中,我们确实可以像门店一样,开发这些类:LemonBlackTea、LemonGreenTea、MangoBlackTea、MangoLemonGreenTea…但是,很快我们就发现,这样子干肯定是不行的,这会导致我们需要组合出所有的可能,而且如果客人需要在红茶中加双份柠檬怎么办?三份柠檬怎么办?万一有个变态要四份柠檬,所以这种做法是给自己找加班的。//首先,定义饮料抽象基类 public abstract class Beverage { // 返回描述 public abstract String getDescription(); // 返回价格 public abstract double cost(); } //然后是三个基础饮料实现类,红茶、绿茶和咖啡: public class BlackTea extends Beverage { public String getDescription() { return "红茶"; } public double cost() { return 10; } } public class GreenTea extends Beverage { public String getDescription() { return "绿茶"; } public double cost() { return 11; } } ...// 咖啡省略 //定义调料,也就是装饰者的基类,此类必须继承自 Beverage: // 调料 public abstract class Condiment extends Beverage { } //定义柠檬、芒果等具体的调料,它们属于装饰者,毫无疑问,这些调料肯定都需要继承 Condiment 类: public class Lemon extends Condiment { private Beverage beverage; // 这里很关键,需要传入具体的饮料,如需要传入没有被装饰的红茶或绿茶, // 当然也可以传入已经装饰好的芒果绿茶,这样可以做芒果柠檬绿茶 public Lemon(Beverage beverage) { this.beverage = beverage; } public String getDescription() { // 装饰 return beverage.getDescription() + ", 加柠檬"; } public double cost() { // 装饰 return beverage.cost() + 2; // 加柠檬需要 2 元 } } public class Mango extends Condiment { private Beverage beverage; public Mango(Beverage beverage) { this.beverage = beverage; } public String getDescription() { return beverage.getDescription() + ", 加芒果"; } public double cost() { return beverage.cost() + 3; // 加芒果需要 3 元 } } ...// 给每一种调料都加一个类 //客户端调用 public static void main(String[] args) { // 首先,我们需要一个基础饮料,红茶、绿茶或咖啡 Beverage beverage = new GreenTea(); // 开始装饰 beverage = new Lemon(beverage); // 先加一份柠檬 beverage = new Mango(beverage); // 再加一份芒果 //此处肯定会怀疑为什么没有调用方法就把装饰品加入了,因为方法是链式调用的,用的是return beverage.getDescription(),会逐步向传入的参数上溯,最后再输出。 System.out.println(beverage.getDescription() + " 价格:¥" + beverage.cost()); //"绿茶, 加柠檬, 加芒果 价格:¥16" } //如果我们需要芒果珍珠双份柠檬红茶: Beverage beverage = new Mongo(new Pearl(new Lemon(new Lemon(new BlackTea()))));代码其实并不是很清晰,看图会更容易理清逻辑
上面已经了解了什么是装饰模式,jdk的源码中也是存在装饰模式的, java IO 就是,看下图 InputStream 派生出来的部分类:
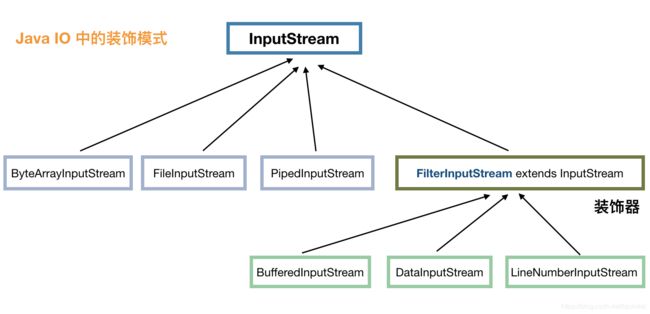
我们知道 InputStream 代表了输入流,具体的输入来源可以是文件(FileInputStream)、管道(PipedInputStream)、数组(ByteArrayInputStream)等,这些就像前面奶茶的例子中的红茶、绿茶,属于基础输入流。FilterInputStream 承接了装饰模式的关键节点,其实现类是一系列装饰器,比如 BufferedInputStream 代表用缓冲来装饰,也就使得输入流具有了缓冲的功能,LineNumberInputStream 代表用行号来装饰,在操作的时候就可以取得行号了,DataInputStream 的装饰,使得我们可以从输入流转换为 java 中的基本类型值。
当然,在 java IO 中,如果我们使用装饰器的话,就不太适合面向接口编程了,如:
InputStream inputStream = new LineNumberInputStream(new BufferedInputStream(new FileInputStream("")));这样的结果是,InputStream 还是不具有读取行号的功能,因为读取行号的方法定义在 LineNumberInputStream 类中。
我们应该像下面这样使用:
DataInputStream is = new DataInputStream( new BufferedInputStream( new FileInputStream("")));所以说嘛,要找到纯的严格符合设计模式的代码还是比较难的。
总结
- 接口和抽象类的区别:1. 抽象类是对一种事物的抽象,是对整个类整体进行抽象,包括属性、行为;接口中也可以含有变量和方法,但是,接口中的变量会被隐式地指定为public static final。而方法会被隐式地指定为public abstract方法且只能是public abstract方法。因此,严格来说接口是抽象类的另一种写法,但是通常只需要定义方法而不实现时便会定义为接口。2. 对于一个父类,如果它的一个方法在父类中实现没有任何意义,必须根据子类的实际需求来进行不同的实现,那么就可以将这个方法声明为abstract方法,此时这个类也就成为了abstract抽象类。
- 接口和抽象类的相同:1. 无论是接口还是抽象类都是用来声明一个新的类型,并且作为一个类型的等级结构的起点。其内部含有的方法都是没有实体,目的就是为了让实现类进行实现,这种存在就是为了让实现类继承或者实现,如果一个接口或者抽象类没有实现,那么毫无意义
- 接口和抽象类的区别与联系:
(1).抽象类是对一种事物的抽象,即对类抽象,而接口是对行为的抽象。
(2).抽象类是对整个类整体进行抽象,包括属性、行为,但是接口却是对类局部(行为)进行抽象。
(3). 继承是一个 “是不是”的关系,而 接口 实现则是 “有没有”的关系。如果一个类继承了某个抽象类,则子类必定是抽象类的种类,而接口实现则是有没有、具备不具备的关系。
(4).接口只给出方法的声明,不给出方法的实现。抽象类中可以有抽象方法的一般方法。如果是抽象方法的话,只有方法的声明。如果是一般方法的话,既有方法的声明,也有方法的实现。 - 使用接口的原因:
(1).没有接口,可插入性就没有保证。因为Java是单继承的。
(2).在一个类等级结构中的任何一个类都可以实现一个接口,如果这个类实现了这个接口那么将会影响到此类的所有子类,但是不会影响到此类的所有父类。
(3).一个类最多有一个父类,但是可以同时实现几个接口。
-
外观(门面)模式
//*************************不用门面模式******************************* //定义一个接口 public interface Shape { void draw(); } //实现类 public class Circle implements Shape { @Override public void draw() { System.out.println("Circle::draw()"); } } public class Rectangle implements Shape { @Override public void draw() { System.out.println("Rectangle::draw()"); } } //实例化对应的实现类进行使用方法 public static void main(String[] args) { // 画一个圆形 Shape circle = new Circle(); circle.draw(); // 画一个长方形 Shape rectangle = new Rectangle(); rectangle.draw(); } //*************************使用门面模式******************************** //定义一个门面 public class ShapeMaker { private Shape circle; private Shape rectangle; private Shape square; public ShapeMaker() { circle = new Circle(); rectangle = new Rectangle(); square = new Square(); } /** * 下面定义一堆方法,具体应该调用什么方法,由这个门面来决定 */ public void drawCircle(){ circle.draw(); } public void drawRectangle(){ rectangle.draw(); } public void drawSquare(){ square.draw(); } } //客户端调用 public static void main(String[] args) { ShapeMaker shapeMaker = new ShapeMaker(); // 客户端调用现在更加清晰了 shapeMaker.drawCircle(); shapeMaker.drawRectangle(); shapeMaker.drawSquare(); } //不用:我们需要画圆就要先实例化圆,画长方形就需要先实例化一个长方形,然后再调用相应的 draw() 方法。 //使用:门面模式的优点显而易见,客户端不再需要关注实例化时应该使用哪个实现类,直接调用门面提供的方法就可以了,因为门面类提供的方法的方法名对于客户端来说已经很友好了。总结
- 门面模式其实并不复杂,他的核心意义就是想让客户端的调用更加友好(无脑),在许多源码中有使用,比如 slf4j 就可以理解为是门面模式的应用,一个操作无需让对象知道其内部实现的复杂度,尽量让用户感知到是非常简单的
- 这就是为什么我们controller层尽量(或者说一定)少些业务逻辑,让controller层只是起到一个传参和通用性参数校验的功能,剩下的全交给service去做吧。我们还需要在代码中不断将“长得”特别长的代码封装成一个方法,“让处处都有好看的外观”。看一下我们曾写过的代码,这里只起到了传参的作用,究竟这个足球是怎么创建出来的,客户端不必担心。
-
组合模式
组合模式是将存在某种包含关系的数据组织在一起,也可以说是具有层次结构的数据,使得我们对单个对象和组合对象的访问具有一致性。典型的例子就是树状结构。
例子一:例如菜单功能,一个菜单除了自己该有的属性,还可能包含子菜单,创建的时候可以使用递归的方法
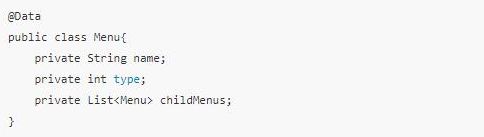
例子二:每个员工都有姓名、部门、薪水这些属性,同时还有下属员工集合(虽然可能集合为空),而下属员工和自己的结构是一样的,也有姓名、部门这些属性,同时也有他们的下属员工集合。public class Employee { private String name; private String dept; private int salary; private List<Employee> subordinates; // 下属 public Employee(String name,String dept, int sal) { this.name = name; this.dept = dept; this.salary = sal; subordinates = new ArrayList<Employee>(); } public void add(Employee e) { subordinates.add(e); } public void remove(Employee e) { subordinates.remove(e); } public List<Employee> getSubordinates(){ return subordinates; } public String toString(){ return ("Employee :[ Name : " + name + ", dept : " + dept + ", salary :" + salary+" ]"); } }总结
- 在我看来,一个类中其中某一属性是一个集合,而这个集合也是一个类或者类本身。那他大概率就是一个组合模式
- 通常,组合模式这种类需要定义 add(node)、remove(node)、getChildren() 这些方法。
-
享元模式
享元模式(英文名称:Flyweight Pattern),尽可能的让用户复用已经有的对象,从而避免造成反复创建对象的资源浪费。首先就会想到数据库连接池还有String常量池,延伸一下,几乎所有和缓存有关的代码,多少都会用到享元模式。
享元模式要求大部分的对象可以外部化。这边要说两个概念,享元模式对象的属性可以分为两个部分,内部状态和外部状态,内部状态是指不会随环境而改变的值,比如说个人信息,外部状态是指随环境改变的值,不能进行共享的信息,如某大学生选修的课程。import java.util.HashMap; abstract class Flyweight { //内部状态 private String name; private int age; //外部状态 private final String subject; //需要被子类继承,那么就不可以定义成private,否则子类无法调用父类构造器, protected Flyweight(String subject){ this.subject = subject; } //行为,和接口中的方法写法一致,没有方法体,只有名字和参数 public abstract void exam(); public String getSubject() { return subject; } } class RealFlyweight extends Flyweight{ //因为父类中的构造器修改过,没有了默认构造器,所以子类中也需要重写构造器 public RealFlyweight(String subject){ //Super就是超级,超类,也就是父类的意思。 在子类中想要调用父类的方法就需要用到Super。 Super()是调用父类的构造方法 super(subject); } @Override public void exam() { System.out.println(this.getSubject()+"is examing..."); } } public class FlyweightFactory{ //定义一个池子,其实就是一个hashmap private static HashMap<String,Flyweight> pool = new HashMap(); public static Flyweight GetFlyweight(String subject){ Flyweight flyweight; if(pool.containsKey(subject)){ flyweight = pool.get(subject); }else{ flyweight = new RealFlyweight(subject); pool.put(subject,flyweight); } return flyweight; } public static void main(String[] args) { System.out.println(pool.size()); //0 GetFlyweight("math"); GetFlyweight("math"); System.out.println(pool.size()); //1 GetFlyweight("math1"); GetFlyweight("math2"); System.out.println(pool.size()); //3 } }总结
- 其实用一个实体类继承一个抽象类的写法并不是必须的,但是为了代码的可读性和规范性,尽量这样写,其实单纯写一个实体类是完全可行的。
- 复用对象而不每次需要就新建一个对象的场景其实有很多,目的就是为了节约资源,因此反过来看需要节约资源的场景大多都会用到享元模式,最简单的就是用一个hashmap存储对象。
六、结构型模式总结
-
前面,我们说了代理模式、适配器模式、桥梁模式、装饰模式、门面模式、组合模式和享元模式。在说到这些模式的时候,心中是否有一个清晰的图或处理流程在脑海里呢?
-
代理模式是做方法增强的,适配器模式是把鸡包装成鸭这种用来适配接口的,桥梁模式做到了很好的解耦,装饰模式从名字上就看得出来,适合于装饰类或者说是增强类的场景,门面模式的优点是客户端不需要关心实例化过程,只要调用需要的方法即可,组合模式用于描述具有层次结构的数据,享元模式是为了在特定的场景中缓存已经创建的对象,用于提高性能。
七、 行为型模式
创建了对象,对象之间有了结构关系,就要看下怎么更加优雅的相互作用了。
因此,各个类之间的相互作用,将职责划分清楚,使得我们的代码更加地清晰。做好这些就是行为型模式。
-
策略模式
最常用的,也是最简单的,直接看代码即可。
//首先,先定义一个策略接口 public interface Strategy { public void draw(int radius, int x, int y); } //然后我们定义具体的几个策略 public class RedPen implements Strategy { @Override public void draw(int radius, int x, int y) { System.out.println("用红色笔画图,radius:" + radius + ", x:" + x + ", y:" + y); } } public class GreenPen implements Strategy { @Override public void draw(int radius, int x, int y) { System.out.println("用绿色笔画图,radius:" + radius + ", x:" + x + ", y:" + y); } } public class BluePen implements Strategy { @Override public void draw(int radius, int x, int y) { System.out.println("用蓝色笔画图,radius:" + radius + ", x:" + x + ", y:" + y); } } //使用策略的类 public class Context { private Strategy strategy; public Context(Strategy strategy){ this.strategy = strategy; } public int executeDraw(int radius, int x, int y){ return strategy.draw(radius, x, y); } } //客户端演示 public static void main(String[] args) { Context context = new Context(new BluePen()); // 使用绿色笔来画 context.executeDraw(10, 0, 0); }总结
- 其实跟桥梁模式很像,只是比桥梁模式更简单一些,复杂度更低,耦合更深。可以看下面的对比图
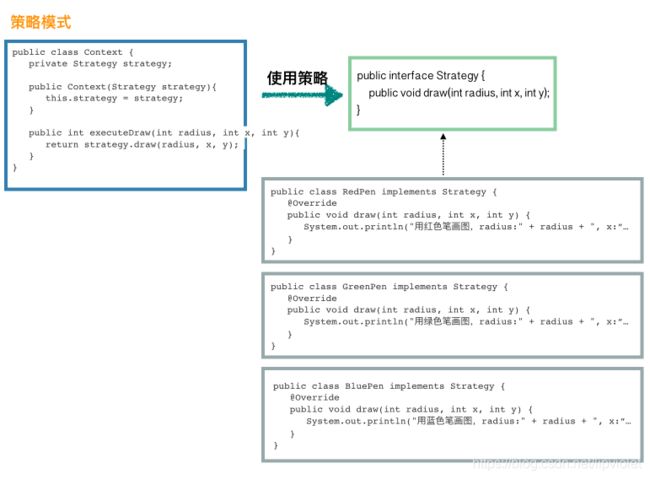
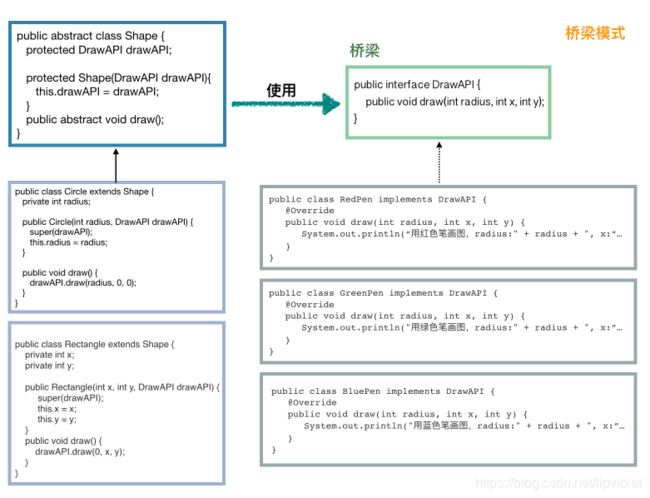
- 其实跟桥梁模式很像,只是比桥梁模式更简单一些,复杂度更低,耦合更深。可以看下面的对比图
-
观察者模式
观察者模式说白了就两点:观察者订阅自己关心的主题;主题有数据变化后通知观察者们。(像不像使用kafka)
//首先,需要定义主题,每个主题需要持有观察者列表的引用,用于在数据变更的时候通知各个观察者 public class Subject { private List<Observer> observers = new ArrayList<Observer>(); private int state; public int getState() { return state; } public void setState(int state) { this.state = state; // 数据已变更,通知观察者们 notifyAllObservers(); } public void attach(Observer observer){ observers.add(observer); } // 通知观察者们 public void notifyAllObservers(){ for (Observer observer : observers) { observer.update(); } } } //定义观察者接口 //其实如果只有一个观察者类的话,接口都不用定义了,不过,通常场景下,既然用到了观察者模式,我们就是希望一个事件出来了,会有多个不同的类需要处理相应的信息。比如,订单修改成功事件,我们希望发短信的类得到通知、发邮件的类得到通知、处理物流信息的类得到通知等。 //我们来定义具体的几个观察者类 public abstract class Observer { protected Subject subject; public abstract void update(); } public class BinaryObserver extends Observer { // 在构造方法中进行订阅主题 public BinaryObserver(Subject subject) { this.subject = subject; // 通常在构造方法中将 this 发布出去的操作一定要小心 this.subject.attach(this); } // 该方法由主题类在数据变更的时候进行调用 @Override public void update() { String result = Integer.toBinaryString(subject.getState()); System.out.println("订阅的数据发生变化,新的数据处理为二进制值为:" + result); } } public class HexaObserver extends Observer { public HexaObserver(Subject subject) { this.subject = subject; this.subject.attach(this); } @Override public void update() { String result = Integer.toHexString(subject.getState()).toUpperCase(); System.out.println("订阅的数据发生变化,新的数据处理为十六进制值为:" + result); } } //客户端使用 public static void main(String[] args) { // 先定义一个主题 Subject subject1 = new Subject(); // 定义观察者 new BinaryObserver(subject1); new HexaObserver(subject1); // 模拟数据变更,这个时候,观察者们的 update 方法将会被调用 subject.setState(11); } //输出 订阅的数据发生变化,新的数据处理为二进制值为:1011 订阅的数据发生变化,新的数据处理为十六进制值为:B //扩展 当然,jdk 也提供了相似的支持,具体的大家可以参考 java.util.Observable 和 java.util.Observer 这两个类。 实际生产过程中,观察者模式往往用消息中间件来实现,如果要实现单机观察者模式,笔者建议读者使用 Guava 中的 EventBus,它有同步实现也有异步实现,本文主要介绍设计模式,就不展开说了总结
- 主题中:成员变量有list<观察者>和随时变化的属性;方法有增加观察者(毕竟不是kafka因此没有取消订阅等复杂方法)和通知观察者;通过set属性方法传递给观察者
- 观察者:成员变量只有主题是必须的;方法只有收到通知到之后的动作是必须的,构造器用来订阅主题(当然也可以另写方法订阅主题)
- 其实就是一种一对多的依赖关系,当一个对象(被观察者)状态改变的时候,所有依赖于该对象的观察者都会被通知,从而进行相关操作。很多中间件都依赖于观察者模式,例如RabbitMQ,还有那些事件驱动模型(好像node就是)。
- 核心就是一个类(主题)中包含另一个类的实例对象(观察者),遇到固定操作时实例对象进行某些操作。
-
责任链模式
责任链通常需要先建立一个单向链表,然后调用方只需要调用头部节点就可以了,后面会自动流转下去。比如流程审批就是一个很好的例子,只要终端用户提交申请,根据申请的内容信息,自动建立一条责任链,然后就可以开始流转了。
有这么一个场景,用户参加一个活动可以领取奖品,但是活动需要进行很多的规则校验然后才能放行,比如首先需要校验用户是否是新用户、今日参与人数是否有限额、全场参与人数是否有限额等等。设定的规则都通过后,才能让用户领走奖品。
如果产品给你这个需求的话,我想大部分人一开始肯定想的就是,用一个 List 来存放所有的规则,然后 foreach 执行一下每个规则就好了。不过,读者也先别急,看看责任链模式和我们说的这个有什么不一样?
//先定义一个基类,所有的责任链都是继承于此,也是一个抽象类 public abstract class RuleHandler { // 后继节点 protected RuleHandler successor; //一开始看了很久不知道这个Context是什么东西,其实是jdk内置的一个类,似乎是环境背景什么的,不影响理解责任链模式 public abstract void apply(Context context); public void setSuccessor(RuleHandler successor) { this.successor = successor; } public RuleHandler getSuccessor() { return successor; } } //接下来一次定义不同的节点 //检验用户是否是新用户 public class NewUserRuleHandler extends RuleHandler { public void apply(Context context) { if (context.isNewUser()) { // 如果有后继节点的话,传递下去 if (this.getSuccessor() != null) { this.getSuccessor().apply(context); } } else { throw new RuntimeException("该活动仅限新用户参与"); } } } //检验用户所在地区是否可以参与 public class LocationRuleHandler extends RuleHandler { public void apply(Context context) { boolean allowed = activityService.isSupportedLocation(context.getLocation); if (allowed) { if (this.getSuccessor() != null) { this.getSuccessor().apply(context); } } else { throw new RuntimeException("非常抱歉,您所在的地区无法参与本次活动"); } } } //检验奖品是否还有剩余 public class LimitRuleHandler extends RuleHandler { public void apply(Context context) { int remainedTimes = activityService.queryRemainedTimes(context); // 查询剩余奖品 if (remainedTimes > 0) { if (this.getSuccessor() != null) { this.getSuccessor().apply(userInfo); } } else { throw new RuntimeException("您来得太晚了,奖品被领完了"); } } } //客户端调用 public static void main(String[] args) { //依次将节点实例化 RuleHandler newUserHandler = new NewUserRuleHandler(); RuleHandler locationHandler = new LocationRuleHandler(); RuleHandler limitHandler = new LimitRuleHandler(); // 假设本次活动仅校验地区和奖品数量,不校验新老用户 locationHandler.setSuccessor(limitHandler); locationHandler.apply(context); //其实,上面的不检验新老用户的代码看了很久没看懂,这里写的有些瑕疵,本来就不同意理解它还这样写,如果连续依次检验,就会跟容易理解了 //全部检验时如下:依次赋值好节点,否则是不会形成链条的! newUserHandler.setSuccessor(locationHandler); locationHandler.setSuccessor(limitHandler); newUserHandler.apply(context); }总结
- 其实就是手动形成一个链条,示例省略了一步,理解起来费劲了,可以看看下面的简短示例
其实跟自己修正过的很像,这就是责任链。手动成链。public class ResponsibilityTest { public static void main(String[] args) { LeaveRequest request = LeaveRequest.builder().leaveDays(20).name("小明").build(); AbstractLeaveHandler directLeaderLeaveHandler = new DirectLeaderLeaveHandler("县令"); DeptManagerLeaveHandler deptManagerLeaveHandler = new DeptManagerLeaveHandler("知府"); GManagerLeaveHandler gManagerLeaveHandler = new GManagerLeaveHandler("京兆尹"); directLeaderLeaveHandler.setNextHandler(deptManagerLeaveHandler); deptManagerLeaveHandler.setNextHandler(gManagerLeaveHandler); directLeaderLeaveHandler.handlerRequest(request); } } - 至于它和我们前面说的用一个 List 存放需要执行的规则的做法有什么异同,留给读者自己琢磨吧。
- 其实就是手动形成一个链条,示例省略了一步,理解起来费劲了,可以看看下面的简短示例
-
模板方法模式
一个抽象类公开定义了执行它的方法的方式/模板。它的子类可以按需要重写方法实现,但调用将以抽象类中定义的方式进行。SpringBoot为用户封装了很多继承代码,都用到了模板方式,例如那一堆XXXtemplate。
//一般都会定义一个抽象类,包含多个抽像方法和一个模板方法,其中只有模板方法是定义好的,其他的抽象方法都交给子类去实现 abstract class DBTemplate{ //需要子类实现的抽象方法。 abstract void open(); abstract void select(); abstract void close(); //定好的模板方法 public final void template(){ open(); select(); close(); } } public class MysqlDB extends DBTemplate { //子类实现抽象方法 @Override void open() { System.out.println("开始..."); } @Override void select() { System.out.println("选择..."); } @Override void close() { System.out.println("关闭..."); } public static void main(String[] args) { MysqlDB mysqlDB = new MysqlDB(); //只有模板方法直接调用 mysqlDB.template(); } }总结
- 在含有继承结构的代码中,模板方法模式是非常常用的,这也是在开源代码中大量被使用的
- 抽象类中定义多个抽象方法和一个模板方法,并且模板方法中包含这些抽象方法,且有一定顺序。
-
状态模式
简单来说,就是一个对象有不同的状态,根据状态不同,可能有不同的行为。
下面以一简单的例子来说明吧,商品库存中心有个最基本的需求是减库存和补库存,我们看看怎么用状态模式来写。
//核心在于,我们的关注点不再是 Context 是该进行哪种操作,而是关注在这个 Context 会有哪些操作。 //定义状态接口 public interface State { public void doAction(Context context); } //定义减库存的状态 public class DeductState implements State { public void doAction(Context context) { System.out.println("商品卖出,准备减库存"); context.setState(this); //... 执行减库存的具体操作 } public String toString(){ return "Deduct State"; } } //定义补库存状态 public class RevertState implements State { public void doAction(Context context) { System.out.println("给此商品补库存"); context.setState(this); //... 执行加库存的具体操作 } public String toString() { return "Revert State"; } } //前面用到了 context.setState(this),我们来看看怎么定义 Context 类 public class Context { private State state; private String name; public Context(String name) { this.name = name; } public void setState(State state) { this.state = state; } public void getState() { return this.state; } } //客户端调用 public static void main(String[] args) { // 我们需要操作的是 iPhone X Context context = new Context("iPhone X"); // 看看怎么进行补库存操作 State revertState = new RevertState(); revertState.doAction(context); // 同样的,减库存操作也非常简单 State deductState = new DeductState(); deductState.doAction(context); // 如果需要我们可以获取当前的状态 // context.getState().toString(); } //在上面这个例子中,如果我们不关心当前 context 处于什么状态,那么 Context 就可以不用维护 state 属性了,那样代码会简单很多。 //不过,商品库存这个例子毕竟只是个例,我们还有很多实例是需要知道当前 context 处于什么状态的。总结
- 其实感觉就是定义一个接口,然后分别按照不同的功能实现,其实主要就是利用抽象类和借口进行解耦。或者通过实现类将代码更优雅。
-
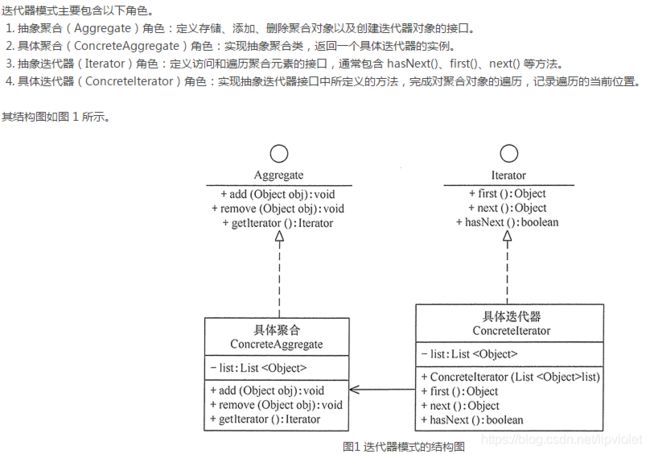
迭代器模式
提供一个方法,可以顺序访问一个对象内部的各个元素,不需要知道内部构造。现在基本很少自己实现迭代器了,基本成熟的框架或者强大的JDK都会给出访问的方法,比如说java中iterator。这样做主要是进一步封装对象内部的结构,让行为和结构想耦合。这个不举例子了,用过iterator这个的小伙伴应该都清楚,就是不停的next,去访问下一个元素。
在日常开发中,我们几乎不会自己写迭代器。除非需要定制一个自己实现的数据结构对应的迭代器,否则,开源框架提供的 API 完全够用。不过此处我们为了学习设计模式,还是写一个简单的示例吧。
import java.util.*; //迭代器模式的实现代码如下 public class IteratorPattern { public static void main(String[] args) { Aggregate ag = new ConcreteAggregate(); ag.add("中山大学"); ag.add("华南理工"); ag.add("韶关学院"); System.out.print("聚合的内容有:"); Iterator it = ag.getIterator(); while (it.hasNext()) { Object ob = it.next(); System.out.print(ob.toString() + "\t"); } Object ob = it.first(); System.out.println("\nFirst:" + ob.toString()); } } //抽象聚合 interface Aggregate { public void add(Object obj); public void remove(Object obj); public Iterator getIterator(); } //具体聚合 class ConcreteAggregate implements Aggregate { private List<Object> list = new ArrayList<Object>(); public void add(Object obj) { list.add(obj); } public void remove(Object obj) { list.remove(obj); } public Iterator getIterator() { return (new ConcreteIterator(list)); } } //抽象迭代器 interface Iterator { Object first(); Object next(); boolean hasNext(); } //具体迭代器 class ConcreteIterator implements Iterator { private List<Object> list = null; private int index = -1; public ConcreteIterator(List<Object> list) { this.list = list; } public boolean hasNext() { if (index < list.size() - 1) { return true; } else { return false; } } public Object first() { index = 0; Object obj = list.get(index); ; return obj; } public Object next() { Object obj = null; if (this.hasNext()) { obj = list.get(++index); } return obj; } } //输出 聚合的内容有:中山大学 华南理工 韶关学院 First:中山大学总结
- 迭代器目前确实很少自己写了,都是拿来即用,设计模式大多如此,可以深究其理论逻辑和场景,但是实际用时有时没必要自己写,但是常见于源码,多理解设计模式,对阅读源码事半功倍。
-
命令模式
命令模式是将请求以命令的形式包裹在对象中,并传递给对象,调用对象寻找到处理该命令的合适的对象,并将该命令传递给相应的对象,该对象执行。
简单点说就是不同请求都封装成一个对象,不同的请求调用不同的执行者。用一个简单的例子说明:用命令模式实现客户去餐馆吃早餐的实例

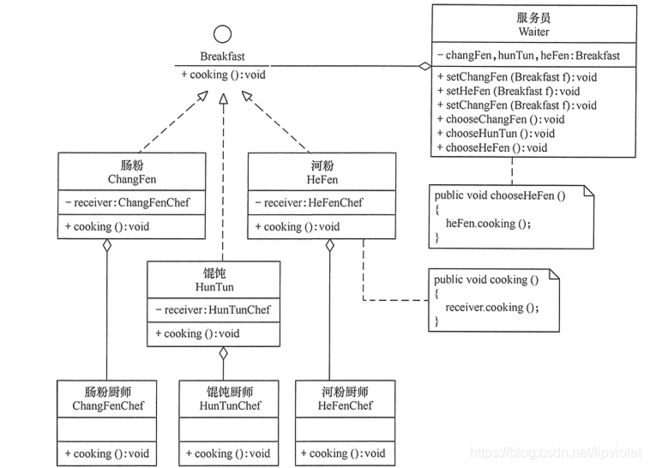
//其实就是一个命令者出发不同的命令执行不同的操作 import javax.swing.*; public class CookingCommand { public static void main(String[] args) { Breakfast food1 = new ChangFen(); Breakfast food2 = new HunTun(); Breakfast food3 = new HeFen(); Waiter fwy = new Waiter(); fwy.setChangFen(food1);//设置肠粉菜单 fwy.setHunTun(food2); //设置河粉菜单 fwy.setHeFen(food3); //设置馄饨菜单 fwy.chooseChangFen(); //选择肠粉 fwy.chooseHeFen(); //选择河粉 fwy.chooseHunTun(); //选择馄饨 } } //调用者:服务员 class Waiter { private Breakfast changFen, hunTun, heFen; public void setChangFen(Breakfast f) { changFen = f; } public void setHunTun(Breakfast f) { hunTun = f; } public void setHeFen(Breakfast f) { heFen = f; } public void chooseChangFen() { changFen.cooking(); } public void chooseHunTun() { hunTun.cooking(); } public void chooseHeFen() { heFen.cooking(); } } //抽象命令:早餐 interface Breakfast { public abstract void cooking(); } //具体命令:肠粉 class ChangFen implements Breakfast { private ChangFenChef receiver; ChangFen() { receiver = new ChangFenChef(); } public void cooking() { receiver.cooking(); } } //具体命令:馄饨 class HunTun implements Breakfast { private HunTunChef receiver; HunTun() { receiver = new HunTunChef(); } public void cooking() { receiver.cooking(); } } //具体命令:河粉 class HeFen implements Breakfast { private HeFenChef receiver; HeFen() { receiver = new HeFenChef(); } public void cooking() { receiver.cooking(); } } //接收者:肠粉厨师 class ChangFenChef extends JFrame { private static final long serialVersionUID = 1L; JLabel l = new JLabel(); ChangFenChef() { super("煮肠粉"); l.setIcon(new ImageIcon("src/command/ChangFen.jpg")); this.add(l); this.setLocation(30, 30); this.pack(); this.setResizable(false); this.setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE); } public void cooking() { this.setVisible(true); } } //接收者:馄饨厨师 class HunTunChef extends JFrame { private static final long serialVersionUID = 1L; JLabel l = new JLabel(); HunTunChef() { super("煮馄饨"); l.setIcon(new ImageIcon("src/command/HunTun.jpg")); this.add(l); this.setLocation(350, 50); this.pack(); this.setResizable(false); this.setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE); } public void cooking() { this.setVisible(true); } } //接收者:河粉厨师 class HeFenChef extends JFrame { private static final long serialVersionUID = 1L; JLabel l = new JLabel(); HeFenChef() { super("煮河粉"); l.setIcon(new ImageIcon("src/command/HeFen.jpg")); this.add(l); this.setLocation(200, 280); this.pack(); this.setResizable(false); this.setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE); } public void cooking() { this.setVisible(true); } }总结
1.记住三个对象就可以:命令人;命令;执行命令。其中命令和执行命令都有多种,因此一般设置为抽象类进行子类继承。 -
备忘录模式
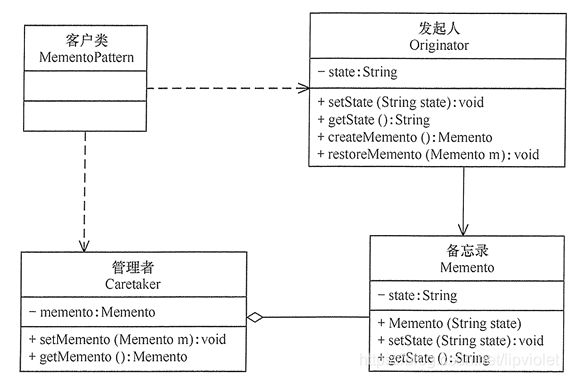
备忘录(Memento)模式的定义:在不破坏封装性的前提下,捕获一个对象的内部状态,并在该对象之外保存这个状态,以便以后当需要时能将该对象恢复到原先保存的状态。该模式又叫快照模式。
备忘录模式的核心是设计备忘录类以及用于管理备忘录的管理者类,当然还必须有一个发起者(也就是需调用备忘录的对象类)
- 发起人(Originator)角色:记录当前时刻的内部状态信息,提供创建备忘录和恢复备忘录数据的功能,实现其他业务功能,它可以访问备忘录里的所有信息。
- 备忘录(Memento)角色:负责存储发起人的内部状态,在需要的时候提供这些内部状态给发起人。
- 管理者(Caretaker)角色:对备忘录进行管理,提供保存与获取备忘录的功能,但其不能对备忘录的内容进行访问与修改。
import java.util.ArrayList; import java.util.List; //备忘录 class Memento{ private String state; public Memento(String state) { this.state = state; } public void setState(String state) { this.state = state; } public String getState() { return state; } } //发起人(使用备忘录的类,可以是任意一对象) class Originator{ private String state; public void setState(String state) { this.state = state; } public String getState() { return state; } public Memento createMemento() { return new Memento(state); } public void restoreMemento(Memento m) { this.setState(m.getState()); } } //备忘录管理类 class Caretaker{ public List<Memento> mementoList = new ArrayList<Memento>(); public void add(Memento memento){ mementoList.add(memento); } public Memento get(int index){ return mementoList.get(index); } } public class Demo001 { public static void main(String[] args) { Caretaker caretaker = new Caretaker(); Originator originator = new Originator(); originator.setState("likewei #1"); caretaker.add(originator.createMemento()); originator.setState("zhangwuji #2"); caretaker.add(originator.createMemento()); originator.setState("chenshimei #3"); caretaker.add(originator.createMemento()); for(Memento a :caretaker.mementoList){ System.out.println(a.getState()); } } } //输出 likewei #1 zhangwuji #2 chenshimei #3 //发起人和备忘录类其实很想,成员变量是相同的,只是发起人类中包含createMemento和restoreMemento方法 //备忘录管理类的成员变量也可以是非列表,只是这样就只能存储一条快照,不能存储多个。理论上依旧是备忘录模式。总结
- 这里需要注意的是,对象不与备忘录本身耦合,而是跟备忘录管理类耦合(就是List<备忘录>),因为,快照不一定只有一个,一般也都是多个。如果不用list则只能存储一个快照。
- 其实很多应用软件都提供了这项功能,如 Word、记事本、Photoshop、Eclipse 等软件在编辑时按 Ctrl+Z 组合键时能撤销当前操作,使文档恢复到之前的状态;还有在 IE 中的后退键、数据库事务管理中的回滚操作、玩游戏时的中间结果存档功能、数据库与操作系统的备份操作、棋类游戏中的悔棋功能等都属于这类。
-
访问者模式
当对特定角色进行访问的时候,需要通过访问者进行访问。一个对象不太方便被你直接访问的时候,你需要将自己的引用交给访问者,通过访问者去访问该对象。比如说,化学课,想看一个细胞结构,由于肉眼无法直接看到微观世界的玩意,需要通过显微镜间接访问。
或者,被处理的数据元素相对稳定而访问方式多种多样的数据结构。例如,公园中存在多个景点,也存在多个游客,不同的游客对同一个景点的评价可能不同;医院医生开的处方单中包含多种药元素,査看它的划价员和药房工作人员对它的处理方式也不同,划价员根据处方单上面的药品名和数量进行划价,药房工作人员根据处方单的内容进行抓药。
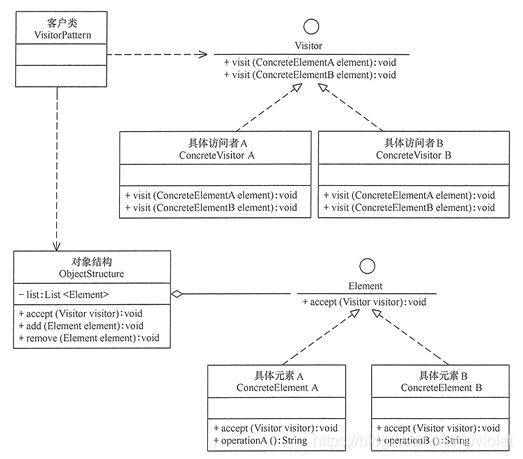
因此:访问者(Visitor)模式的定义是将作用于某种数据结构中的各元素的操作分离出来封装成独立的类,使其在不改变数据结构的前提下可以添加作用于这些元素的新的操作,为数据结构中的每个元素提供多种访问方式。它将对数据的操作与数据结构进行分离,是行为类模式中最复杂的一种模式。
import java.util.*; //访问者模式包含以下主要角色: //抽象访问者(Visitor)角色:定义一个访问具体元素的接口,为每个具体元素类对应一个访问操作 visit() ,该操作中的参数类型标识了被访问的具体元素。 //具体访问者(ConcreteVisitor)角色:实现抽象访问者角色中声明的各个访问操作,确定访问者访问一个元素时该做什么。 //抽象元素(Element)角色:声明一个包含接受操作 accept() 的接口,被接受的访问者对象作为 accept() 方法的参数。 //具体元素(ConcreteElement)角色:实现抽象元素角色提供的 accept() 操作,其方法体通常都是 visitor.visit(this) ,另外具体元素中可能还包含本身业务逻辑的相关操作。 //对象结构(Object Structure)角色:是一个包含元素角色的容器,提供让访问者对象遍历容器中的所有元素的方法,通常由 List、Set、Map 等聚合类实现。 //抽象访问者 interface Visitor { void visit(ConcreteElementA element); void visit(ConcreteElementB element); } //具体访问者A类 class ConcreteVisitorA implements Visitor { public void visit(ConcreteElementA element) { System.out.println("具体访问者A访问-->" + element.operationA()); } public void visit(ConcreteElementB element) { System.out.println("具体访问者A访问-->" + element.operationB()); } } //具体访问者B类 class ConcreteVisitorB implements Visitor { public void visit(ConcreteElementA element) { System.out.println("具体访问者B访问-->" + element.operationA()); } public void visit(ConcreteElementB element) { System.out.println("具体访问者B访问-->" + element.operationB()); } } //抽象元素类 interface Element { void accept(Visitor visitor); } //具体元素A类 class ConcreteElementA implements Element { public void accept(Visitor visitor) { visitor.visit(this); } public String operationA() { return "具体元素A的操作。"; } } //具体元素B类 class ConcreteElementB implements Element { public void accept(Visitor visitor) { visitor.visit(this); } public String operationB() { return "具体元素B的操作。"; } } //对象结构角色 class ObjectStructure { private List<Element> list = new ArrayList<Element>(); public void accept(Visitor visitor) { Iterator<Element> i = list.iterator(); while (i.hasNext()) { ((Element) i.next()).accept(visitor); } } public void add(Element element) { list.add(element); } public void remove(Element element) { list.remove(element); } } public class Demo002 { public static void main(String[] args) { ObjectStructure os = new ObjectStructure(); os.add(new ConcreteElementA()); os.add(new ConcreteElementB()); Visitor visitor = new ConcreteVisitorA(); os.accept(visitor); System.out.println("------------------------"); visitor = new ConcreteVisitorB(); os.accept(visitor); } } //输出如下: 具体访问者A访问-->具体元素A的操作。 具体访问者A访问-->具体元素B的操作。 ------------------------ 具体访问者B访问-->具体元素A的操作。 具体访问者B访问-->具体元素B的操作。总结
- 访问者(Visitor)模式实现的关键是如何将作用于元素的操作分离出来封装成独立的类.
- 一般来说,其结构图一般来说就像下面
-
中介者模式
在现实生活中,常常会出现好多对象之间存在复杂的交互关系,这种交互关系常常是“网状结构”,它要求每个对象都必须知道它需要交互的对象。例如,每个人必须记住他(她)所有朋友的电话;而且,朋友中如果有人的电话修改了,他(她)必须让其他所有的朋友一起修改,这叫作“牵一发而动全身”,非常复杂。
如果把这种“网状结构”改为“星形结构”的话,将大大降低它们之间的“耦合性”,这时只要找一个“中介者”就可以了。如前面所说的“每个人必须记住所有朋友电话”的问题,只要在网上建立一个每个朋友都可以访问的“通信录”就解决了。这样的例子还有很多,例如,你刚刚参加工作想租房,可以找“房屋中介”;或者,自己刚刚到一个陌生城市找工作,可以找“人才交流中心”帮忙。
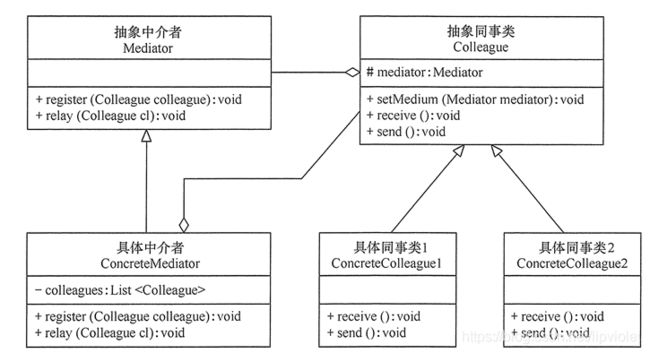
在软件的开发过程中,这样的例子也很多,例如,在 MVC 框架中,控制器(C)就是模型(M)和视图(V)的中介者;还有大家常用的 QQ 聊天程序的“中介者”是 QQ 服务器。所有这些,都可以采用“中介者模式”来实现,它将大大降低对象之间的耦合性,提高系统的灵活性。
//------下面举一个同事之间沟通的例子------ //中介者模式实现的关键是找出“中介者” //中介者模式包含以下主要角色。 //抽象中介者(Mediator)角色:它是中介者的接口,提供了同事对象注册与转发同事对象信息的抽象方法。 //具体中介者(Concrete Mediator)角色:实现中介者接口,定义一个 List 来管理同事对象,协调各个同事角色之间的交互关系,因此它依赖于同事角色。 //抽象同事类(Colleague)角色:定义同事类的接口,保存中介者对象,提供同事对象交互的抽象方法,实现所有相互影响的同事类的公共功能。 //具体同事类(Concrete Colleague)角色:是抽象同事类的实现者,当需要与其他同事对象交互时,由中介者对象负责后续的交互。 import java.util.ArrayList; import java.util.List; //抽象中介者 abstract class Mediator { public abstract void register(Colleague colleague); public abstract void relay(Colleague cl); //转发 } //具体中介者 class ConcreteMediator extends Mediator { private List<Colleague> colleagues = new ArrayList<Colleague>(); public void register(Colleague colleague) { if (!colleagues.contains(colleague)) { colleagues.add(colleague); colleague.setMedium(this); } } public void relay(Colleague cl) { for (Colleague ob : colleagues) { if (!ob.equals(cl)) { ((Colleague) ob).receive(); } } } } //抽象同事类 abstract class Colleague { protected Mediator mediator; public void setMedium(Mediator mediator) { this.mediator = mediator; } public abstract void receive(); public abstract void send(); } //具体同事类 class ConcreteColleague1 extends Colleague { public void receive() { System.out.println("具体同事类1收到请求。"); } public void send() { System.out.println("具体同事类1发出请求。"); mediator.relay(this); //请中介者转发 } } //具体同事类 class ConcreteColleague2 extends Colleague { public void receive() { System.out.println("具体同事类2收到请求。"); } public void send() { System.out.println("具体同事类2发出请求。"); mediator.relay(this); //请中介者转发 } } public class Demo003 { public static void main(String[] args) { Mediator md = new ConcreteMediator(); Colleague c1, c2; c1 = new ConcreteColleague1(); c2 = new ConcreteColleague2(); md.register(c1); md.register(c2); c1.send(); System.out.println("-------------"); c2.send(); } }总结
- 上述是一个比较复杂的例子,其结构图可以参考下面。
- 可以看下下面更简单的例子,一个聊天室。

- 我感觉就是隐藏方法实现细节,让外部直接调用。
- 上述是一个比较复杂的例子,其结构图可以参考下面。
-
解释器模式
构建一种翻译方式,将某种语言或描述翻译成我们很好理解的语言或者描述。这里很好理解的意思是看得懂,看的快。
往大的说,编译器(JVM虚拟机)就是解释器模式,将底层语言甚至机械语言解释成我们使用的高级编程语言;往下的说,其实Map就可以看作一个很好的编译器,key你可以存放一个非常小的字符串,value理论上你可以存放任何东西。
下面实践一个简单的例子:用解释器模式设计一个“韶粵通”公交车卡的读卡器程序。说明:假如“韶粵通”公交车读卡器可以判断乘客的身份,如果是“韶关”或者“广州”的“老人” “妇女”“儿童”就可以免费乘车,其他人员乘车一次扣 2 元。
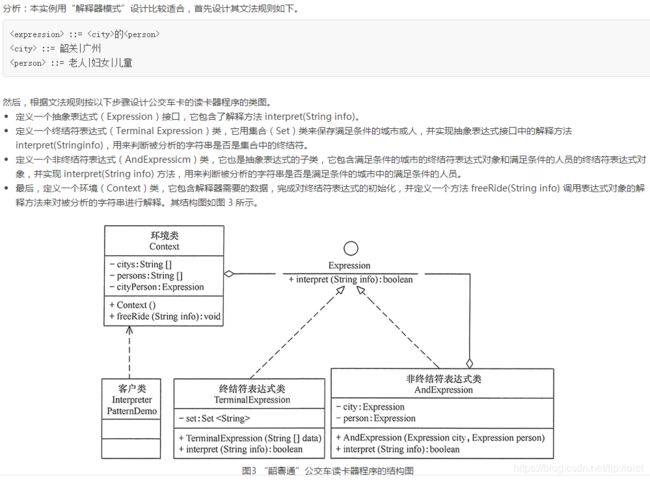
import java.util.*; /*文法规则::= public class InterpreterPatternDemo { public static void main(String[] args) { Context bus = new Context(); bus.freeRide("韶关的老人"); bus.freeRide("韶关的年轻人"); bus.freeRide("广州的妇女"); bus.freeRide("广州的儿童"); bus.freeRide("山东的儿童"); } } //抽象表达式类 interface Expression { public boolean interpret(String info); } //终结符表达式类 class TerminalExpression implements Expression { private Set<String> set = new HashSet<String>(); public TerminalExpression(String[] data) { for (int i = 0; i < data.length; i++) set.add(data[i]); } public boolean interpret(String info) { if (set.contains(info)) { return true; } return false; } } //非终结符表达式类 class AndExpression implements Expression { private Expression city = null; private Expression person = null; public AndExpression(Expression city, Expression person) { this.city = city; this.person = person; } public boolean interpret(String info) { String s[] = info.split("的"); return city.interpret(s[0]) && person.interpret(s[1]); } } //环境类 class Context { private String[] citys = {"韶关", "广州"}; private String[] persons = {"老人", "妇女", "儿童"}; private Expression cityPerson; public Context() { Expression city = new TerminalExpression(citys); Expression person = new TerminalExpression(persons); cityPerson = new AndExpression(city, person); } public void freeRide(String info) { boolean ok = cityPerson.interpret(info); if (ok) System.out.println("您是" + info + ",您本次乘车免费!"); else System.out.println(info + ",您不是免费人员,本次乘车扣费2元!"); } } //程序运行结果如下: 您是韶关的老人,您本次乘车免费! 韶关的年轻人,您不是免费人员,本次乘车扣费2元! 您是广州的妇女,您本次乘车免费! 您是广州的儿童,您本次乘车免费! 山东的儿童,您不是免费人员,本次乘车扣费2元!的 ::= 韶关|广州 ::= 老人|妇女|儿童 */ 总结
- 应用场景:1)当语言的文法较为简单,且执行效率不是关键问题时。2)当问题重复出现,且可以用一种简单的语言来进行表达时。3)当一个语言需要解释执行,并且语言中的句子可以表示为一个抽象语法树的时候,如 XML 文档解释
- 解释器模式在实际的软件开发中使用比较少,因为它会引起效率、性能以及维护等问题。如果碰到对表达式的解释,在 Java 中可以用 Expression4J 或 Jep 等来设计。
八、行为型模式总结
- 行为型模式(Behavioral Pattern)是对在不同的对象之间划分责任和算法的抽象化,它是 GoF 设计模式中最为庞大的一类模式,包含以下 11 种:模板方法(Template Method)模式、策略(Strategy)模式、命令(Command)模式、职责链(Chain of Responsibility)模式、状态(State)模式、观察者(Observer)模式、中介者(Mediator)模式、迭代器(Iterator)模式、访问者(Visitor)模式、备忘录(Memento)模式、解释器(Interpreter)模式。
- 行为型模式用于描述程序在运行时复杂的流程控制,即描述多个类或对象之间怎样相互协作共同完成单个对象无法单独完成的任务,它涉及算法与对象间职责的分配。
- 按照其显示方式的不同,行为型模式可分为类行为模式和对象行为模式,其中类行为型模式使用继承关系在几个类之间分配行为,主要通过多态等方式来分配父类与子类的职责;对象行为型模式则使用对象的组合或聚合关联关系来分配行为,主要是通过对象关联等方式来分配两个或多个类的职责。由于组合关系或聚合关系比继承关系耦合度低,满足“合成复用原则”所以对象行为模式比类行为模式具有更大的灵活性。
九、终章
学习设计模式的目的是为了让我们的代码更加的优雅、易维护、易扩展。
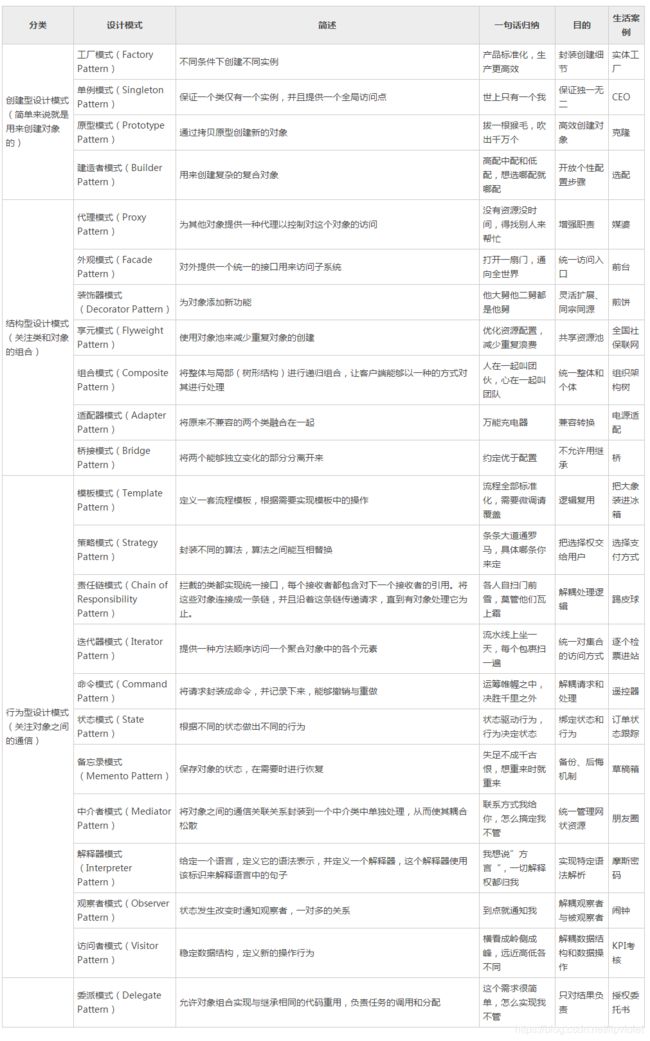
下面,用一句话来总结每个设计模式
参考:https://blog.csdn.net/u010439466/article/details/89472302
详解:http://c.biancheng.net/view/1317.html