大数据项目实战数仓4——总纲
文章目录
-
- 一、数据仓库的概述
- 二、项目需求及架构设计
-
- 1.项目需求分析
- 2.项目框架
-
- 2.1技术选型
- 2.2系统数据流程设计
- 2.3框架发行版本选型
- 2.4服务器选型
- 2.5集群资源规划设计
- 三、相关命令
-
- 可视化报表Superset
- 即席查询Kylin
- 集群监控Zabbix
- 全流程调度Azkaban
- 权限管理Ranger
- 元数据管理Atlas
- 四、全流程调度+数据质量可视化
一、数据仓库的概述
数据仓库(Data Warehouse),是为企业制度决策,提供数据支持的。

二、项目需求及架构设计
1.项目需求分析
1.用户行为数据采集平台搭建
2.业务数据采集平台搭建
3.数据仓库维度建模
4.分析,设备、会员、商品、地区、活动等电商核心主题,统计的报表指标近100个
5.采用即席查询工具,随时进行指标分析
6.对集群性能进行监控,发生异常进行报警
7.元数据管理
8.质量监控
9.权限管理
2.项目框架
2.1技术选型
考虑因素:数据量大小、业务需求、行业内经验、技术成熟度、开发维护成本、总成本预算
数据采集传输:Flume,Kafka,Sqoop
数据存储:MySQL,HDFS,HBase
数据计算:Hive,Tez,Spark
数据查询:Presto,Kylin
数据可视化:Echarts,Superset
任务调度:Azkaban
集群监控:Azbbix
元数据管理:Atlas
权限管理:Ranger
2.2系统数据流程设计

2.3框架发行版本选型
Apache

2.4服务器选型
这里选择阿里云主机,Centos7配置如下:

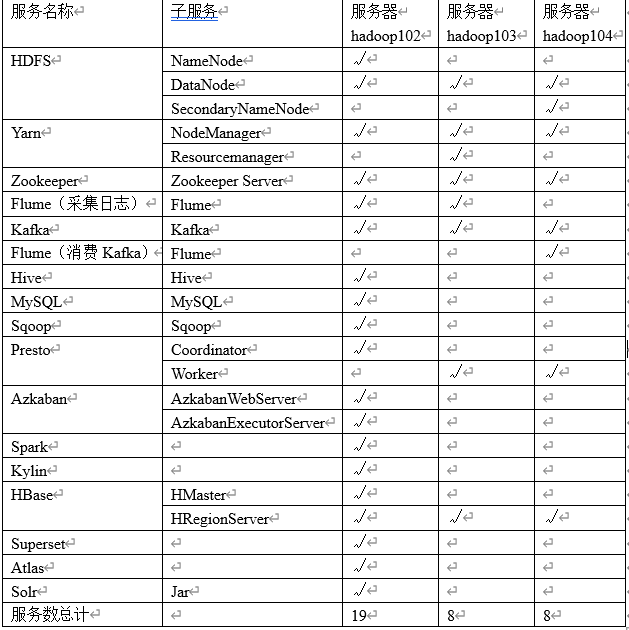
2.5集群资源规划设计
(1)消耗内存的分开
(2)数据传输数据比较紧密的放在一起(Kafka、Zookeeper)
(3)客户端尽量放在一到两台服务器上,方便外部访问
(4)有依赖关系的尽量放到同一台服务器(例如:Hive和Azkaban Executor)
三、相关命令
可视化报表Superset
1)切换到yingzi用户
su yingzi
2)启动superset.sh脚本
/home/yingzi/bin/superset.sh start
Web UI界面:http://hadoop102:8787
用户名:yingzi
密码:000000
即席查询Kylin
依赖于Hadoop、Hive、Zookeeper、HBase
1)启动hadoop
/home/yingzi/bin/hdp.sh start
2)启动zoookeeper
/home/yingzi/bin/zk.sh start
3)启动hbase
sudo -i -u hbase start-hbase.sh
4)启动Kylin
在kylin用户下认证为hive主体
sudo -i -u kylin kinit -kt /etc/security/keytab/hive.keytab hive
以kylin用户的身份启动kylin
sudo -i -u kylin /opt/module/kylin/bin/kylin.sh start
Web UI:http://hadoop102:7070/kylin
用户名:ADMIN
密码:KYLIN
日志:/opt/module/kylin/logs/kylin.log
集群监控Zabbix
hadoop102启动
sudo systemctl start zabbix-server zabbix-agent httpd rh-php72-php-fp
sudo systemctl enable zabbix-server zabbix-agent httpd rh-php72-php-fpm
hadoop103、104启动
sudo systemctl start zabbix-agent
sudo systemctl enable zabbix-agent
全流程调度Azkaban
1)在三台主机上启动Executor
sudo -i -u azkaban bash -c "cd /opt/module/azkaban/azkaban-exec;bin/start-exec.sh"
2)任选一台节点激活
curl http://hadoop102:12321/executor?action=activate
3)启动Web Server
sudo -i -u azkaban bash -c "cd /opt/module/azkaban/azkaban-web;bin/start-web.sh"
Web UI:http://hadoop102:8081/
账号:yingzi
密码:123456
权限管理Ranger
1)启动ranger-admin
sudo -i -u ranger ranger-admin start
Web UI:http://hadoop102:6080
账号:admin
密码:yingzi123
2)启动ranger-usersync(开机自启)
sudo -i -u ranger ranger-usersync start
元数据管理Atlas
1)在三台主机上启动solr集群
sudo -i -u solr /opt/module/solr/bin/solr start
Web UI:http://hadoop102:8983
2)启动Atlas,依赖于Hadoop、Zookeeper、Kafka、Hbase、Solr
/home/yingzi/bin/hdp.sh start
/home/yingzi/bin/zk.sh start
/home/yingzi/bin/kf.sh start
sudo -i -u hbase start-hbase.sh
sudo -i -u solr /opt/module/solr/bin/solr start(三台都需要)
/opt/module/atlas/bin/atlas_start.py
Web UI:http://hadoop102:21000
账号:admin
密码:admin
四、全流程调度+数据质量可视化
1)启动日志采集通道
/opt/module/yingzi/bin/hdp.sh start
/opt/module/yingzi/bin/zk.sh start
/opt/module/yingzi/bin/kf.sh start
/opt/module/yingzi/bin/f1.sh start
/opt/module/yingzi/bin/f2.sh start
2)准备业务数据
修改hadoop102,hadoop103两台节点的/opt/module/applog/application.yml文件,修改业务日期
vim /opt/module/applog/application.yml
#业务日期
mock.date: "2020-**-**"
执行生成日志的脚本(执行完后可看hdfs上是否有相应数据)
/home/yingzi/bin/lg.sh
将数据消费,存入数据库,修改/opt/module/db_log/application.properties
vim /opt/module/db_log/application.properties
#业务日期
mock.date=2020-**-**
cd /opt/module/db_log
java -jar gmall2020-mock-db-2021-01-22.jar
此时可以看数据库中是否有2020-??-??的数据
3)启动azkaban
为了减轻内存压力,可先释放一些进程
/home/yingzi/bin/f1.sh stop
/home/yingzi/bin/f2.sh stop
启动Executor Server(三台主机都需要)
sudo -i -u azkaban bash -c "cd /opt/module/azkaban/azkaban-exec;bin/start-exec.sh"
激活Executor Server,任选一台节点执行
curl http://hadoop102:12321/executor?action=activate
启动Web Server
sudo -i -u azkaban bash -c "cd /opt/module/azkaban/azkaban-web;bin/start-web.sh"
Web UI:http://hadoop102:8081/
账号:yingzi
密码:123456
4)分别启动gmall,data_supervisor的工作流程
在gmall上填入参数:dt,useExecutor
在data_supervisor上填入参数:dt,useExecutor,alert
5)可视化
sudo -i -u yingzi /opt/module/yingzi/bin/superset.sh start
Web UI页面:http://hadoop102:8787
用户名:yingzi
密码:000000